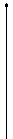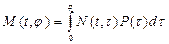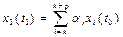За многие тысячелетия существования человечества огромное число людей погибло от различных эпидемий. Для того чтобы иметь возможность бороться с эпидемиями, то есть своевременно применять те или иные медицинские мероприятия (карантины, вакцинации и т.д.), необходимо уметь сравнивать эффективность этих мероприятий. Сравнить же их можно лишь в том случае, если есть возможность предсказать, как при том или ином мероприятии будет меняться ход эпидемии, прежде всего число больных. Отсюда возникает необходимость в построении моделей, которые могли бы служить целям прогноза.
Сначала рассмотрим модель «естественного» хода эпидемии (без медицинского вмешательства). Понятно, что модель эпидемии может включать в себя влияние факторов самых различных уровней. Так, можно было бы учесть законы, управляющие деятельностью бактериальных клеток, степень восприимчивости к инфекции отдельных людей, вероятности встречи носителей инфекции с ещё здоровыми людьми и многие другие факторы. Так как нашей целью является лишь создание иллюстративной модели, то мы абстрагируемся от многих факторов.
Пусть имеется N здоровых людей, и в момент времени t = 0 в эту группу попадает один заболевший человек (источник инфекции). Предположим, что никакого удаления заболевших из группы не происходит (нет ни выздоровления, ни гибели, ни изоляции). Будем считать также, что человек становится источником инфекции сразу же после того, как он сам заразится.
Обозначим число заболевших в момент времени t через x(t), а число здоровых – через y(t) (очевидно, что x(t)+y(t)=N+1 в любой момент времени).
При t = 0 выполняется условие х(0) = 1.
Рассмотрим интервал времени t+dt, где dt – малый промежуток времени. Необходимо определить, сколько новых больных появится за этот промежуток времени. Можно предположить, что их число будет пропорционально величине dt, а также числу встреч здоровых и заболевших людей, то есть произведению величин x×y:
dx=a∙x×y×dt, где a – коэффициент пропорциональности (коэффициент передачи инфекции).
y = N + 1 – x →
Решение этого уравнения:
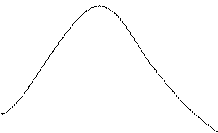
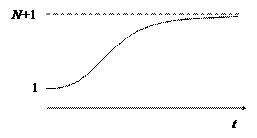
Прогноз – форма зависимости числа больных в группе от времени представлен на рисунке.
Задача. Оценить количество больных через 6 суток и сколько людей заболеет за 6-й день, если a = 0,001, а N + 1 = 1101 чел.?
Для получения ответов следует использовать решение уравнения.
Можно усложнить модель, предположив, например, что в момент времени t болен не 1 человек, а несколько (b). Кроме того, предположим, что через небольшой промежуток времени больной выздоравливает и получает иммунитет. Тогда z(t) – это число переболевших и выздоровевших к моменту t.
x + y + z = N + b
где gх – число выздоровевших.
Тогда прогноз числа заболевших будет иметь форму, представленную на рисунке.
Конкретный вид кривой зависит от N, b, α, γ.
В модели можно учесть смертность от болезни, передачу болезни через переносчика (грызуны) и т.д.
2.6. Моделидинамикивозрастныхгрупп
Рассмотрим ситуацию, когда вес каждой особи популяции меняется в течение жизни и необходимо сделать прогноз не численности, а биомассы всей популяции или ее «молодой» части через определенное время (t).
Пусть t - возраст особи;
N(t, t) – численность всех особей популяции, имеющих в момент времени t возраст t;
Р(t) – средний вес особи возраста t;
Тогда биомасса всех особей возраста t равна N(t, t) Р(t)
Обозначим через М(t, j) интересующую нас биомассу всех особей популяции, имеющих в момент времени t возраст не более j.
Тогда
Зависимость Р от t иногда известна, например, из научной литературы. Гораздо труднее определить N(t, t). Она зависит от многих факторов как внешних (температура, влажность, питание и т.д.), так и от видовых особенностей (плодовитость, жизнеспособность и т.д.).
Иногда для моделирования численности N(t, t) удобно отказаться от непрерывного времени и перейти от дифференциальных уравнений к дискретным моделям, прогнозирующим процесс по «шагам», то есть в дискретные моменты. Рассмотрим дискретную «шаговую» модель динамики возрастной структуры популяции в зависимости от времени. Эта модель широко используется в научных исследованиях по экологии, сельскому хозяйству, демографии и т.д.
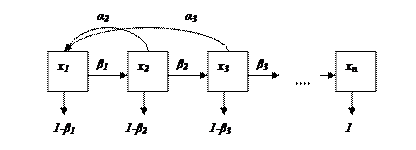
Популяцию условно разбивают на n возрастных групп. В начальный момент времени t0 известна численность особей каждой (i – ой) возрастной группы, которая обозначается хi(t0), i = 1…n (рисунок).
Из всех возрастных групп выделяют те, которые производят потомство. Пусть их номера будут k, k+1, k+2, … , k+p. Предположим, что следующий момент времени t1 выбран так, что за промежуток от t0 до t1 (1 «шаг») особи i-ой группы переходят в группу i+1, от групп k, k+1, k+2, … , k+p появляется потомство, и часть особей каждой группы погибает. Например, первая группа – особи от 0 до 1 года, вторая – от 1 до 2-х лет и т.д. «Шаг» прогноза также 1 год. Пусть ai - коэффициент рождаемости в i – ой группе; bi - коэффициент выживаемости в i – ой группе (смертность будет определяться, как 1 – bi). 0 < bi< 1 для всех групп, кроме последней (n-ой), где bn= 0 (все погибают).
Тогда численность особей первой возрастной группы в момент времени t1 - это численность особей, родившихся в промежуток от t0до t1. Она равна сумме потомств от всех возрастных групп, производящих потомство. Понятно, что численность потомства от отдельной группы будет тем больше, чем больше родителей, то есть чем больше xi(t0). Точнее потомство от i – ой группы за один временной «шаг» будет равно aj.xi(t0), а все потомство, появившееся в промежуток от t0 до t1 будет равно:
Теперь определим численность второй возрастной группы в момент времени t1. За время от t0 до t1особи, находящиеся в момент t0 в первой возрастной группе перейдут во вторую. При этом часть из них может погибнуть. Поэтому численность второй возрастной группы в момент времени t1:
x2(t1) = b1 .x1(t0).
Аналогично рассчитываются и численность каждой (i-ой) группы через 1 «шаг».
xi(t1) = bi-1 .xi-1(t0)., где 0 < bi-1 < 1.
Построив прогноз на 1 «шаг» вперед, принимают новые численности за исходные и повторяют процедуру, получая прогнозы xi(t2) – на 2 «шага» и т.д. вперёд. Эти модели можно использовать не только для прогноза на несколько шагов вперед, но и для подбора схемы «сбора» биомассы, обеспечивающей, например, максимальную прибыль за определенный промежуток времени (за несколько «шагов»).
Задача. На птицеферме всех птиц можно отнести к четырем возрастным группам с «шагом» в 1 год. Начальная численность первой возрастной группы – 300 особей, второй – 100 особей, третьей и четвертой – по 50 особей. Коэффициент естественной выживаемости для первой и второй возрастной группы – 0,9, для третьей – 0,8. Давать потомство могут только особи второй и третьей возрастных групп. Коэффициент рождаемости для второй возрастной группы т.е. среднее число потомков от одной особи за год равно 3, а для третьей – 2.
Рассмотрим два варианта ежегодной продажи:
1. Продаём всю четвёртую возрастную группу. Цена 1 кг особей этой возрастной группы 30 руб, а средний вес 4 кг.
2. Продаём всю четвёртую возрастную группу, а также 30% из второй возрастной группы и 40% из третьей возрастной группы. Средний вес особи второй возрастной группы 2 кг при цене 40 руб за 1 кг. Цена 1 кг особей 3-ей возрастной группы 35 руб, а средний вес 3 кг.
Определить прибыль от первого и второго варианта продажи и построить прогноз численности всех возрастных групп на 1 шаг вперёд (через год).
Решение.
Рассмотрим ситуацию, когда продажу осуществляем в начале года, до того как особи 2 и 3-ей возрастной группы дадут потомство.
Тогда прибыль от 1-го варианта продажи составит:
П = 50шт.×30руб.×4кг = 6000 руб.
Построим прогноз численности на 1 «шаг» вперёд.
С учётом рождаемости численность особей 1-ой возрастной группы через 1 год составит: х1(t1)=3·100+2·50 = 400 шт.
Далее определяем численности 2-ой, 3-ей и 4-ой возрастных групп через год.
х2(t1) = 300×0,9 = 270 шт.
х3(t1) = 100×0,9 = 90 шт.
х4(t1) = 50×0,8 = 40 шт.
Теперь определим прибыль от второго варианта продажи.
Число особей, продаваемых из второй возрастной группы составляет: х2(t0) = 100×0,3 = 30 шт. Значит во второй возрастной группе остаётся 100 – 30 = 70 особей.
Определим численность всех возрастных групп на 1 «шаг» вперёд.
х1(t1) = 70шт.×3 + 30шт.×2 = 270 шт.
х2(t1) = 300шт.×0,9 = 270 шт.
х3(t1) = 70шт.×0,9 = 63 шт.
х4(t1) = 30шт.×0,8 = 24 шт.
Хотя прибыль во втором варианте больше, но численности всех групп изменились по сравнению с первым вариантом. Это приведёт к снижению прибыли в следующие годы, что можно прогнозировать с помощью той же модели.
Подобные модели используют также в демографии для прогноза ожидаемой численности разных возрастных групп людей на несколько «шагов» (на 5, 10, 15 и т.д. лет) вперёд.
Вопросы:
1. Приведите уравнение (модель) для описания прогрессии размножения, когда нет никаких ограничений на N. Как изменится эта модель, если ввести ограничение – предельную численность популяции Кmax?
2. Поясните понятие популяционных волн и их классификацию. От чего зависит форма волн численности?
3. Из каких частей состоит уравнение - модель для описания изменений численности популяций хищника и жертвы в их ограниченном ареале совместного обитания?
4. Какие предположения используются для построения модели роста дерева?
5. Какова генетическая основа биологического метода борьбы с нежелательным видом? Составьте модель для описания изменений численностей нормальных и стерильных самцов.
6. Приведите модель естественного хода эпидемии при х(0)=1. Как изменится эта модель, если в момент времени t болен не один человек, а несколько и через небольшой промежуток времени больные выздоравливают и получают иммунитет?
7. В чём сложность построения модели для определения биомассы определённых возрастных групп?
8. Сформулируйте демографическую задачу, которая может быть решена с использованием дискретной «шаговой» модели динамики возрастной структуры популяции в зависимости от времени.
3. Вероятностные модели.
Все рассмотренные выше модели были детерминистическими, то есть в них не учитывались случайности и их влияние на изучаемые процессы, например, на численность популяции.
Существуют несколько причин, по которым детерминистические модели не всегда служат достаточно точным отражением реальности в биологии и в других областях знаний. Во-первых, они предполагают большую численность популяции. Настолько большую, что можно опираться на закон больших чисел, который включает в себя несколько фундаментальных теорем.
Одно из следствий этого закона используется в генетике: при достаточно большом объеме выборки из большой популяции F2, полученной из F1 (АА х аа → F1), соотношение особей с доминантным и рецессивным проявлениями признака близко к 3:1. Это удачная детерминистическая модель – закон Менделя, который, кроме прочих предположений, требует большой объём выборки в F2. В реальных экспериментах, всегда ограниченных по объёму, уже по этой причине наблюдается отклонение от модели 3:1.
Теория вероятностей и основанная на ней математическая статистика представляют не только упрощенные детерминистические, но и так называемые стохастические варианты моделей и методов. Они, в частности, позволяют ответить на вопрос: можно ли считать отклонение от детерминистической модели 3:1, обнаруженное в ограниченной выборке, чисто случайным, естественным или, всё-таки, отклонение вызвано другими генетическими причинами (отбор, миграция и т.п.). Ответ всегда дается в вероятностной форме. Например, с помощью известного критерия χ2 можно получить вывод: с вероятностью (Р) менее 0,05 (5%) обнаруженное отклонение от 3:1 вызвано случайной ошибкой выборочности. Значит отклонение в действительности вызвано какими-то особыми, неслучайными факторами.
Вторая причина, по которой необходимо применять стохастические модели, особенно в сельском хозяйстве, это влияние на моделируемые процессы (системы), например, растения, неконтролируемых случайных колебаний условий выращивания. Часто влияние этих колебаний даже перекрывает влияние на урожай самих генотипов сравниваемых сортов. Для генетиков, селекционеров, сортоиспытателей крайне важно грамотно применять стохастические модели и методы.
Рассмотрим пример. Оценим вероятность случайной мутации гена, который определяет группу крови. Пусть таких генов три (В, С, Е). Вероятности спонтанных мутаций отдельных нуклеотидов: А ↔ Т; Ц ↔ Г и т. д. одинаковы и равны ≈10-1. Аллель В отличается от С всего по десяти нуклеотидам, а “промежуточные” мутации нежизнеспособны. Если мутации возникают независимо, то вероятность мутации от В к С Р(В→С) ≈10-10. Для реализации такой ничтожно малой вероятности нужны огромные популяции и очень длинная череда поколений. Значит, если новый вид содержит все три аллеля (В, С, Е), то они были получены от вида – предка, а не образовались в результате новых мутаций.

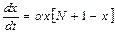
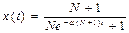
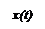 Прогноз – форма зависимости числа больных в группе от времени представлен на рисунке.
Прогноз – форма зависимости числа больных в группе от времени представлен на рисунке.
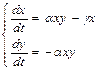
 Тогда прогноз числа заболевших будет иметь форму, представленную на рисунке.
Тогда прогноз числа заболевших будет иметь форму, представленную на рисунке.