Напомним, что в теории вероятности значок “+” означает “или”, а “·” означает “и”. Если события А и В несовместные, то Р(А+В)=Р(А)+Р(В). Если А и В независимы, то Р(А·В)=Р(А)·Р(В)
Пользуясь только этими формулами можно доказать справедливость закона Менделя (1:2:1) в детерминистической форме.
Рассмотрим гибрид F1 ржи (Rr). Этот гибрид образует мужские и женские гаметы:
Гаметы
♀R
♀r
♂R
♂r
Событие
А
В
С
D
То есть вероятности (доли) образования этих гамет равны Р(А)=Р(В)=Р(С)=Р(D)=1/2.
В процессе перекрёстного опыления с образованием семян F2 происходит случайное объединение гамет. Возможны 4 варианта:
Вариант объединения
(события)
Вероятность объединения гамет
Генотип F2
А и С
Р(АС)=1/2∙1/2=1/4
RR
А и D
Р(АD)=1/2∙1/2=1/4
Rr
В и C
Р(BC)=1/2∙1/2=1/4
rR
В и D
Р(BD)=1/2∙1/2=1/4
rr
Эти вероятности случайного объединения гамет проще оценить с использованием решетки Пеннета.
♂
♀
R(1/2)
r(1/2)
R(1/2)
RR(1/4)
Rr(1/4)
r(1/2)
rR(1/4)
rr(1/4)
Поскольку генотип Rr то же, что и rR, то сумма вероятностей появления этих генотипов в F2: Р(АD)+ Р(BD)=1/4+1/4=1/2.
Теперь можно определить соотношение генотипов в F2.
Генотип F2
RR
Rr
rr
Вероятность образования
1/4
1/2
1/4
Соотношение
В процессе доказательства было использовано тождество вероятностей событий образования гамет: R, r, генотипов RR, Rr, rr и соответствующих им долей генов или генотипов. Это справедливо, так как по теореме Бернулли (одна из теорем закона больших чисел) при увеличении числа испытаний (объёма выборки растений популяции, случайно взятых гамет и зигот – зерен F2) доли зерен с генотипами RR, Rr, rr в F2 приближаются к вероятностям их образования, а значит, их соотношение к 1:2:1. Таким образом, при увеличении выборки (объёма) популяции F2 получаем закон Менделя для соотношения долей. То есть при увеличении выборки стохастическая (вероятностная) модель превращается в детерминистическую модель для долей.
Рассмотрим некоторые простые формулы теории вероятности, которые при решении задач из генетики и селекции могут привести к весьма полезным для практики приложениям теории вероятности.
Если случайные события А1…Аn происходят независимо друг от друга, то
где П – знак произведения.
Поэтому, если проводится n одинаковых испытаний и в каждом вероятность события В равна р, то вероятность того, что событие В ни разу не произошло равна (1 – р)(1 – р)…(1 – р) = qn, где q = 1 – p. Вероятность противоположного события: «хотя бы один раз событие В произошло» равно: 1 – qn.
Рассмотрим пример. Оценить вероятность того, что среди 8 особей потомства F2 от скрещивания белой (сс) и серой (СС) мыши будет хотя бы одна белая (С – доминантный аллель).
Сначала оценим вероятность того, что в F2 не будет ни одной белой мыши. Так как доля серых мышей в F2 составляет ¾ (СС+Сс), то искомая вероятность будет (¾)8 ≈ 0,1. Теперь можно определить вероятность того, что будет хотя бы одна белая: 1 – 0,1 = 0,9. Эта вероятностная модель имеет и детерминистическую формулировку: среди большого числа семей F2 с 8 потомками в 90% семей будет хотя бы одна белая мышь (в 10% таких семей – ни одной белой).
Задача 1. Частота спонтанной мутации - альбинизма у растений 10–5. Сколько зёрен надо высадить, чтобы с вероятностью 0,95 среди них было хотя бы одно альбиносное растение?
Схема решения.
(1 – р)n – вероятность того, что нет ни одного мутанта среди n растений; 1 – (1– р)n = 0,95 – хотя бы одно мутантное растение есть.
Из последнего равенства при р = 10-5 можно найти n. В данном случае оно приблизительно равно 300000.
Задача 2. Вероятность рождения мальчика и девочки равны р = q = 1/2. Сколько нужно планировать детей в семье, чтобы вероятность иметь хотя бы одного мальчика была более 0,9?
Схема решения.
Р = (1/2)n – из n детей все девочки; 1 – (1/2)n > 0,9 – хотя бы один мальчик. Отсюда (1/2)n < 0,1.
Это неравенство справедливо уже при n = 4.
В качестве примера применения этих вероятностных моделей в семеноводстве можно предложить подход к оценке объёма выборки семян.
Пусть сорт – это смесь из N чистых линий (биотипов), содержащихся в сорте с разными долями рi,
Как определить объём минимальной случайной выборки семян (n), чтобы в ней с вероятностью Р≥0,95 было хотя бы по одному зерну каждого биотипа.
Итак n – объём выборки т. е. число выбранных семян (испытаний); N – число биотипов;
(1 – рi)n – вероятность того, что из n испытаний случайно не выберем ни одного семени i-го биотипа;
1 – (1 – рi)n – вероятность того, что из n испытаний возьмем хотя бы одно семя i-го биотипа;
- вероятность того, что из n испытаний случайно возьмём хотя бы одно семя от каждого биотипа. Далее подбираем n – объем выборки семян. Не вдаваясь в подробности отметить, что эта формула верна, если n значительно (в 5 и более раз) превышает N.
3.2. Формула полной вероятности.
Пусть в опыте событие А может наступить только совместно с одним из n несовместных событий В1, В2… Вn, составляющих полную группу событий (то есть Р[В1+ В2+… +Вn] = 1). Тогда так называемая безусловная или полная вероятность реализации события А равна:
,
где – условная вероятность наступления события А совместно с Вi.
Задача.
Из потомства F2 от скрещивания белой (сс) и серой (СС) мышей взяли одну серую и скрестили с белой (C – доминантный аллель). Какова вероятность того, что из трёх мышей – потомков такого скрещивания все три серые?
Схема решения.
Результаты исходных скрещиваний до F2 включительно удобно представить в следующем виде:
Р:
сс
х
СС
↓
F1
Сс
x
Сс
↓
F2
СС
Сс
сс
1/4
1/2
1/4
Серая мышь, взятая из F2 для скрещивания с белой не могла иметь генотип сс, а только СС (событие В1) или Сс (событие В2). Поэтому В1 и В2 – события, составляющие полную группу. Значит, вероятность суммы этих событий равна 1. “Внутри” этой суммы вероятность Сс в два раза больше, чем СС. Следовательно, вероятность того, что взятая из F2 серая мышь имела генотип СС равна Р(В1) = 1/3, а генотип СсР(В2) = 2/3.
Если для скрещивания с белой мышью случайно взяли серую мышь с генотипом СС, то после скрещивания СС х сс в потомстве будут все серые мыши, значит для события В1 условная вероятность появления всех трёх серых мышей в потомстве равна 13. Если же для скрещивания случайно взяли серую мышь с генотипом Сс (событие В2), то после скрещивания Сс х сс в потомстве будет ½ серых (Сс) и ½ белых (сс) мышей, и условная вероятность того, что все три потомка будут серыми, равна (½)3.
Теперь можно оценить искомую полную вероятность Р(А)=1/3∙(1)3+2/3∙(1/2)3=5/12=0,42
Пример. Определим соотношение долей генотипов в F3 после самоопыления популяции F2 пшеницы, полученной из F1 (AA x aa).
По формуле полной вероятности событие А “зерно, случайно взятое из F3, несет генотип АА” имеет вероятность: Р(АА)=1/4∙1+1/2∙1/4+1/4∙0=0,375.
Действительно, событие А может произойти совместно с одним из 3-х событий:
1) В1 – это зерно вызрело на растении F2, имеющем генотип АА;
2) В2 – это зерно вызрело на растении F2, имеющем генотип Аа;
3) В3 – это зерно вызрело на растении F2, имеющем генотип аа.
Р(В1) = 1/4 – вероятность того, что это случайно взятое зерно вызрело на растении АА из F2;
= 1 – вероятность того, что это случайно взятое зерно, образовавшееся в результате самоопыления на растении АА, имеет генотип АА;
Р(В2) = 1/2 – вероятность того, что зерно созрело на растении F2 с генотипом Аа;
= 1/4 – вероятность того, что это зерно с растения Аа имеет генотип АА;
Р(В3) = 1/4 – вероятность того, что зерно взято с растения F2, несущего генотип аа;
= 0 – вероятность того, что случайно взятое зерно с такого растения имеет генотип АА.
В1, В2, В3 – полная группа событий.
Аналогично, вероятности случайно взять из F3 зерно Аа и аа:
Р(Аа) = 1/4∙0+1/2∙1/2+1/4∙0 = 0,25.
Р(аа) = 0,375.
При большом объёме случайной выборки зерен из F3 три оцененные вероятности близки к долям трёх генотипов. Таким образом, в F3 будет следующее соотношение долей генотипов:
АА
Аа
аа
0,375
0,25
0,375
3.3. Теория мишени.
В некоторых областях биологии удобно пользоваться так называемой теорией мишени. Согласно этой модели каждая клетка, организм или ген представляют собой “мишень”, а происходящие с ними изменения – результат случайных ударов (попаданий) при бомбардировке этих мишеней. Такую модель широко применяют для оценки эффективности воздействия индуцированного ионизирующего излучения на живые организмы. Эта теория естественным образом была расширена и для объяснения “спонтанных” вредных изменений, в частности изменений, связанных с процессами старения, а также действия различных факторов помимо ионизирующего излучения. Те же самые математические идеи находят применение и во многих других областях биологии, в частности в экологии.
Предположим, что клетка содержит несколько мишеней (мутирующих генов) и попадание нейтрона в любую из них с известной вероятностью вызывает заметный эффект у потомства (мутацию). Какая доля из клеток популяции после облучения с определенной дозой (бомбардировка нейтронами) будет иметь хотя бы один мутантный ген и какая ни одного?
Рассмотрим примеры:
1. Сперма дрозофилы бомбардируется нейтронами. В хромосомах спермы имеется множество генов (“мишеней”), каждый из которых важен для нормального развития. Существуют методы скрещивания, позволяющие определить по потомству, в какой доле сперматозоидов хотя бы один из этих генов мутировали. Как изменяется эта доля сперматозоидов в зависимости от дозы?
2. Половозрелое гаплоидное насекомое (например, трутень) облучается рентгеновскими лучами. Предположим, что в каждой клетке содержится N генов, каждый из которых существенен для её нормального функционирования. Как зависит от дозы доля клеток, перестающая нормально функционировать в результате облучения, то есть доля клеток с явными мутациями?
В обоих примерах мишенями являются гены.
Уточним математическую модель для оценки доли клеток с мутациями и без. Итак, каждая клетка содержит N мишеней и подвергается действию дозы в k частиц. Пусть вероятность того, что определенная частица “попадет в определенную мишень” (вызовет мутацию гена), равна р. Понятно, что р очень мало. Вероятность того, что данная мишень не будет поражена данной частицей, равна 1 – р.
Следовательно, вероятность того, что данная мишень не будет поражена ни одной из k частиц, равна (1 – р)k. Если р мало, а k – велико, то удачной является следующая приблизительная замена: (1 – р)k » е–kр.
В клетке имеется N мишеней, и вероятность поражения данной мишени не зависит от поражения остальных мишеней. Вероятность того, что не будет поражена ни одна из N мишеней клетки равна S = (е–kр)N = е–Nkр. При большом числе клеток эта вероятность близка к доле клеток без мутаций. Тогда зависимость 1 – S – доли клеток, несущих хотя бы по одной мутации от k – дозы облучения – имеет вид 1 – е –Nkр (рисунок).
Следует напомнить, что любая модель имеет ограничения. В частности полученная зависимость предполагает равную выживаемость клеток. Если же в действительности до оценки доли клеток без мутаций происходит массовая гибель мутантных клеток, то экспериментальная кривая скорее всего отклонится вниз по сравнению с прогнозом по модели (пунктир на рисунке). В подобных случаях следует усложнять модели – учитывать в них дополнительные гипотезы о биологических процессах. Адекватность новой модели косвенно подтвердит справедливость и достаточность всей совокупности гипотез – предположений.
Ряд Пуассона.
Производится серия однотипных испытаний. Любое испытание успешно с вероятностью р и неуспешно с вероятностью q = 1 – p. Необходимо оценить вероятность сложного события А, состоящего в том, что из n испытаний k прошли успешно. Для этого, как известно, используют биноминальное распределение:
Рn(k) = Cnkpkqn – k, где ;
Пример. Соотношение полов 1:1. Определить вероятность того, что в семье с тремя детьми будут 2 девочки.
Решение.
n = 3, k = 2
; .
Рассмотрим видоизмененное биноминальное распределение, широко используемое в биологии. Итак, если вероятность данного события при однократном испытании равна р, то вероятности того, что оно произойдет 0, 1, 2, 3, и т. д. раз в ряду n последовательных испытаний, задаются соответствующими членами ряда:
Попадания 0 1 2 3 …
Вероятность:
Вынесем qn за скобки
Предположим теперь, что р очень мало (q ≈ 1), а n достаточно велико, но так, что величина m = np не является пренебрежимо малой. Тогда можно считать, что n – 1 ≈ n – 2, … ≈ n и, используя замену
(1 – p)n ≈ e–np, последнее выражение можно переписать в виде:
Заметим, что сумма, стоящая в скобках, равна enp, а всё выражение равно единице (e–np · enp). Напомним, что соответствующие члены ряда представляют собой вероятности того, что в последовательности из n испытаний интересующее нас событие произойдёт 0, 1, 2, 3, … раз. Сумма всех вероятностей, естественно, должна быть равна единице.
Этот ряд, удобный для приблизительных экспресс-оценок, называют рядом Пуассона. Его используют во многих областях биологии. Он применим везде, где можно представить себе длинную последовательность независимых испытаний с малой вероятностью “успеха” в каждом испытании. Интуитивно ясно, что среднее число успехов m в последовательности n испытаний равно np. Поэтому, ряд Пуассона даёт вероятности данного числа успехов в последовательности n испытаний, причём в форме, удобной для вычислений.
Число успехов
2 …
r
Вероятность
Докажем, что среднее число успехов, как утверждается выше, равно m = np.
Математическое ожидание числа успехов равно:
При исследовании действия излучения моделирование в рамках теории мишени представляются вполне естественным. Однако этот же математический аппарат можно применять в задачах, в которых аналогия с мишенями и снарядами выражена менее явно. Предположим, например, что большая популяция из N бактерий смешана с популяцией из kN фаговых частиц. Какова будет доля незараженных бактерий, если допустить, что “нападение” фаговой частицы на любую бактерию равновероятно и все фаговые частицы проникают в бактерии? Может быть поставлена и обратная задача: сколько вирусных частиц k приходилось в среднем на одну бактерию, если доля бактерий, оставшихся незараженными равна F?
Если рассматривать бактерии как мишени, а фаговые частицы как снаряды, то вероятность того, что на данную бактерию нападет данная фаговая частица, равна 1/N. При большом числе N доли бактерий, зараженных 0, 1, 2,… фаговыми частицами, задаются членами ряда Пуассона при m = np = kN(1/N) = k:
.
В частности, вероятность того, что данная бактерия вообще избежит заражения, равна e–k. При большом N – это доля незаражённых бактерий.
Аналогичная задача возникает при подсчёте клеток или других микрочастиц под микроскопом с помощью специальной сетки. Предположим, например, что капля крови, содержащая N эритроцитов, размазана по предметному стеклу, разделенному на 400 одинаковых квадратов. Если эритроциты распределены по стеклу случайно, вероятность того, что данный эритроцит попадет в определённый квадрат, равна 1/400, и, следовательно, ожидаемые числа квадратов с 0, 1, 2, … эритроцитами задаются членами ряда Пуассона.
В данном случае m=n×p=N/400. Ожидаемая доля пустых клеток равна e – N / 400; ожидаемое их число 400×e – N/400.
Если, например, подсчитали, что в 61 из 400 квадратов нет ни одного эритроцита, то: 400×e – N/400 ≈ 61. Значит общее число эритроцитов в капле крови на всем стекле N ≈ 752.
Итак, если известно, что эритроциты распределены случайно, то таким способом можно быстро определить их примерное количество, подсчитав под микроскопом лишь число пустых квадратов сетки.
Часто задаются не вероятность р и число испытаний n, а сразу характерное значение параметра m = np, то есть среднее значение наступления события А во всей большой серии испытаний. Это значение m находят заранее при статистической обработке данных.
Пример. В травматологическое отделение в течение каждого часа дневного времени привозят примерно 3 пациентов. Какова вероятность того, что за один час их будет только 1 или ни одного?
В этом случае m = 3 и P(1) = me–m = 3e–3 = 0,15, а Р(0) = е–m = = 0,05. Таким образом, вероятность того, что в течение часа потребуется по крайней мере 1 хирург, равна 1 – Р(0) = 0,95, а что таких хирургов нужно будет не менее 2, равна 1 – Р(0) – Р(1) = 0,8. Как видно, это отделение травматологии нельзя закрывать на обед.
Приложения в экологии.
В экологии ряд Пуассона используют, в частности, для того, чтобы выяснить, действительно ли организмы на обследуемом участке распределены случайно. Для этого участок разбивают на много одинаковых квадратов и подсчитывают число особей данного вида растений или животных в каждом квадрате. Если участок слишком велик, то выбирают наугад несколько квадратов и в каждом из них подсчитывают число особей. В любом случае числа квадратов, на которых обнаружено 0, 1, 2,…k особей, сравнивают (используя критерий χ2) с ожидаемыми при пуассоновском распределении, то есть в предположении, что организмы распределены совершенно случайно.
Критерием χ2 можно пользоваться, если соблюдаются определённые условия: достаточно большой объём выборочной совокупности (например, общее число пересчитанных животных n>50); в каждой рассчитанной группе должно быть не менее пяти наблюдений (например, число квадратов с n животными должно быть не менее пяти); для вычисления χ2 используют только численности, а не проценты или величины, полученные при измерениях или взвешиваниях и т. д. Если наблюдаемые и ожидаемые значения совпадают довольно хорошо (χ2р < χ2т), то можно сделать вывод, что распределение организмов по участку близко к случайному. В противном случае (χ2р > χ2т), есть две возможности:
1. Особи избегают друг друга или же препятствуют пребыванию поблизости от себя других особей. В таких ситуациях если, например, среднее число особей на квадрат равно трём, то квадратов с тремя особями будет слишком много по сравнению с ожидаемым числом. Квадратов же, в которых нет ни одной особи или, наоборот, много особей, будет слишком мало, так как они вынуждены разместиться более равномерно по участку.
2. Особи “скучиваются”, например, потому, что они привлекают друг друга, или потому, что в некоторых местах рассматриваемого участка условия более благоприятны для их существования, чем на других. В этом случае будет слишком много как пустых квадратов, так и квадратов с большим количеством особей.
Задача. На некотором достаточно однородном участке было расставлено 543 разных по конструкции ловушки для мелких млекопитающих. По прошествии некоторого времени в ловушках было обнаружено:
Число животных в ловушке
Число ловушек
Спрашивается – одинаковы ли по эффективности ловушки разных конструкций?
Теперь, используя ряд Пуассона, можно определить ожидаемые доли ловушек с 0, 1, 2, и т. д. животными, в предположении, что все ловушки равно эффективны. После чего находим ожидаемое число ловушек с определенным количеством животных.
Поскольку число ловушек с 4, 5, 7, 8 животными меньше пяти, то их можно объединить в один класс.
Ожидаемая доля ловушек, в которых нет ни одного животного, равна e–m = e–0,26 = 0,77. Ожидаемое число ловушек, в которых нет ни одного животного 0,77·543 ≈ 418,1.
Аналогично определяют ожидаемые доли и число ловушек с 1, 2, 3-мя животными. Ожидаемую долю ловушек с числом животных от 4 до 8 можно определить по формуле 1 – Р(0) – Р(1) – Р(2) – Р(3) =
= 1 – 0,77 – 0,20 – 0,026 – 0,002 = 0,002.
Число животных в ловушке
от 4 до 8
∑
Ожидаемая доля ловушек
0,77
0,20
0,026
0,002
0,002
Ожидаемое число ловушек
418,1
108,6
14,1
1,1
1,1
χ2р
Число степеней свободы df = 5 – 1 = 4.
Для Р = 0,05 χ2т = 9,49
χ2р > χ2т. Следовательно, не все конструкции ловушек равноэффективны.
Итак, случайным (пуассоновским) является распределение объектов (клеток на предметном стекле; сорняков в поле и т.д.) аналогичное тому, которое получается в результате следующего модельного процесса:
1. Рассматриваемую площадь делят на большое число равновеликих квадратов;
2. Объекты помещают один за другим на случайно, независимо выбираемые квадраты. То есть, вероятность выбора данного квадрата совершенно одинакова и не зависит от того, содержит ли уже этот квадрат ноль, один или несколько объектов.
Редкие болезни, редкие признаки.
Многие болезни, к счастью, достаточно редки или становятся таковыми после принятия профилактических и лечебных мер. Однако даже при самых благоприятных условиях в больших популяциях все же встречается некоторое число больных редкими заболеваниями. Распределение Пуассона даёт вероятности таких событий в нормальной ситуации. Если в наблюдаемой популяции, например, в конкретном городе, больные встречаются чаще, чем это прогнозируется рядом Пуассона для всей страны, то это говорит о нарушении условий в данном городе, о необходимости выяснения причин, принять меры и т.д.
Например, при введении вакцины против полиомиелита иммунитет создаётся в 99,99% случаев. Какова вероятность того, что из 10000 вакцинированных детей заболеет 1?
Число «испытаний» n = 10000. Вероятность заболеть р = 0,0001. Поэтому m = np = 1, и по формуле Пуассона имеем Р(1) = е–1 = 0,368.
Аналогично, вероятность, что заболеют 2 ребёнка , а вероятности заболевания 3, 4 и 5 детей соответственно равны ; ; Вероятность того, что хотя бы один ребёнок заболеет равна 1 – Р(0) = 1 – е–1 ≈ 0,632.
Если принять, что 10000 новорождённых – это годовая норма, скажем, крупного районного роддома, то примерно в 73% [Р(0)+Р(1)] таких домов полиомиелитом заболеет не более одного ребенка в год; в 18% – два ребёнка в год; в 6% – три и в 1,5% – четыре ребёнка в год. Если же в каком-то роддоме заболело более 5 детей – то это чрезвычайное происшествие. Вероятность такого события равна 0,001.
Аналогичные расчёты можно провести по детской смертности, врождённым аномалиям и признакам. Например, в среднем по стране 1 из 600 детей рождается с болезнью Дауна. Следовательно, в каждом микрорайоне, где проживает 3000 детей, в среднем будет m=np=3000× ×1/600 = 5 детей, страдающих такой болезнью. При этом вероятность рождения 10 детей с синдромом Дауна в микрорайоне равна
.
Таким образом, подобных микрорайонов должно быть приблизительно 2 из 100.
Вопросы:
1. Чем отличаются вероятностные модели от детерминистических? Пояснить на примерах.
2. Определить соотношение долей генотипов Аа и аа в F3 после самоопыления популяции F2 пшеницы, полученной из F1 (AA x aa).
3. Приведите примеры генетических, микробиологических, экологических и медицинских экспериментов, при анализе которых может быть применена теория мишени.
4. Для каких целей в экологии можно использовать ряд Пуассона? Пояснить на примерах.
4. Исследование операций на основе оптимизационных моделей.
В наше время, которое по справедливости называют эпохой научно-технической революции, наука уделяет всё больше внимания вопросам организации и управления объектами, процессами. Это касается не только промышленности, но и биологии, медицины, сельского хозяйства, экологии и т. д. От науки требуются рекомендации по оптимальному (разумному) управлению процессами. Прошли времена, когда правильное, эффективное управление находилось организаторами «на ощупь», методом «проб и ошибок». Сегодня для выработки такого управления требуется научный подход – слишком велики потери, связанные с ошибками.
Потребности практики вызвали к жизни специальные научные методы, которые удобно объединять под названием «исследование операций». Под этим термином будем понимать применение математических, количественных методов для обоснования решений во всех областях целенаправленной человеческой деятельности.
Поясним, что понимается под «решением». Пусть планируется какое-то мероприятие, направленное к достижению определённой цели. У лица, организующего мероприятие, всегда имеется какая-то свобода выбора: можно организовать его тем или другим способом, например, выбрать образцы техники, которые будут применены, так или иначе распределить средства и т.д. «Решение» - это и есть какой-то выбор из ряда возможностей, имеющихся у организатора.
Исследование операций начинается тогда, когда для обоснования решений применяется та или другая модель и математический аппарат. Исследование операций – это своеобразное математическое «примеривание» будущих решений, позволяющее экономить время, силы и материальные средства, избегать серьёзных ошибок.
Впервые название «исследование операций» появилось в годы второй мировой войны, когда в вооруженных силах некоторых стран (США, Англия) были сформированы специальные группы научных работников (физиков, математиков, инженеров), в задачу которых входила подготовка проектов решений для командующих боевыми действиями. Эти решения касались, главным образом, боевого применения оружия и распределения сил и средств по различным объектам. В дальнейшем, исследование операций расширило область своих применений на самые разные области практики: промышленность, сельское хозяйство, строительство, торговля, здравоохранение, охрана природы и т. д.
Чтобы познакомиться со спецификой этого направления прикладной науки рассмотрим ряд типичных для неё задач.
Продажа сезонных товаров. Для реализации определенной массы сезонных товаров создается сеть временных торговых точек. Требуется выбрать разумным образом: число точек, их размещение, товарные запасы и количество персонала на каждой из них так, чтобы обеспечить максимальную экономическую эффективность распродажи.
Медицинское обследование. Известно, что в каком-то районе обнаружены случаи опасного заболевания. С целью выявления заболевших (или носителей инфекции) организуется медицинское обследование района. На это выделены ограниченные материальные средства, оборудование, медицинский персонал. Требуется разработать такой план обследования (число медпунктов, их размещение, последовательность осмотров специалистами, виды анализов и т.д.), который позволит выявить, по возможности, максимальный процент заболевших и носителей инфекции.
Оптимизация селекционно-генетических исследований. В распоряжении имеется коллекция образцов растений, несущих картированные гены различных признаков: по одному, два, три и более генов (возможно сцепленных) в одном образце. Требуется разработать оптимальную схему выбора части образцов и их скрещиваний, чередующихся с отборами по фенотипу. Цель – вывести новый образец с заранее заданным новым сочетанием генов.
Оптимизация деятельности хозяйства. Как лучше всего организовать деятельность крупного фермерского хозяйства – какие культуры и на каких площадях выращивать, в какой пропорции следует выделять средства для животноводства, птицеводства и т. д. С чего начинать исследование?
Прежде всего, нужно четко выделить факторы, которые существенно влияют на принимаемые решения. В последнем случае к ним относятся: количество земли, имеющейся в распоряжении хозяйства, ожидаемые урожайности культур, которые можно возделывать, возможности для создания животноводческой и птицеводческой продукции (помещения, корм и т. п.), а также ожидаемые потребности рынка в зерне, мясе, молоке, яйцах и многие, многие другие факторы.
Ясно, что, прежде всего, нужно выделить несколько главных факторов, возможно разбив общую деятельность на отдельные блоки. Это само по себе сложно сделать. Опыт и знания, накопленные ранее людьми, позволят выделить главные факторы, влияющие на результат. В этом могут также помочь специальные математические методы.
Допустим, что так или иначе мы выделим существенные факторы. Что делать дальше? Теперь следует описать, каким же образом сказывается влияние этих факторов. Например, расширение помещений для скота позволяет увеличить численность стада. Чем выше урожайность какой – либо культуры, тем больше дохода может быть получено от ее возделывания и т.п. Иными словами, дается качественная оценка факторов. Этого было достаточно для изучения задач с малым числом существенных факторов. В конце XX века положение резко изменилось. Современное высокоразвитое хозяйство требует и более точных экономических рекомендаций. Уже мало сказать, например, что изменение фактора А на 1% даст прирост дохода на 1000 руб., если остальные факторы останутся неизменными. А если они все изменятся, что будет тогда? Может быть, эффект будет еще больше?
Чтобы ответить на эти вопросы, и создаётся математическая модель, выражающая количественные соотношения между существенными факторами (параметрами) и, если снова вернуться к хозяйству, количественное выражение для оценки его деятельности – целевая функция (например, доход за год). Здесь и начинается, собственно, исследование операций.
Операцией называется всякое мероприятие (система действий), объединенное единым замыслом, и направленное к достижению какой‑то цели (все мероприятия, рассмотренные выше, являются «операциями»). Исследование операций ведётся на модели.
Операция есть всегда управляемое мероприятие, то есть от нас зависит, каким способом выбрать некоторые параметры, характеризующие её организацию. «Организация» здесь понимается в широком смысле слова, включая набор технических, финансовых и других средств, применяемых в операции.
Всякий определённый выбор зависящих от нас параметров называется решением. Решения могут быть удачными и неудачными, разумными и неразумными. Оптимальными называются решения, по тем или другим признакам предпочтительные перед другими. Цель исследования операций – предварительное количественное обоснование оптимальных решений.
Иногда (относительно редко) в результате исследования удаётся указать одно – единственное строго оптимальное решение, гораздо чаще – выделить область практически равноценных оптимальных решений – рекомендаций. Окончательный выбор всегда делает человек.
4.1. Линейное программирование.
Пусть из различных видов сырья, имеющегося в количествах, равных соответственно b1, b2, …bm (всего m видов сырья: например, сортов мяса, специй и т.д.), может быть изготовлено n видов продуктов (например, n видов колбасы). Цена единицы j-го вида продукта на рынке равна cj. Для получения единицы j-го продукта необходимо затратить i-й вид сырья в количестве aij единиц. Какие виды продуктов выгоднее всего изготавливать и сколько?
Прежде всего, нужно выяснить, в каком смысле понимаются слова «выгоднее всего». Так как речь идет об очень узко очерченной ситуации, то естественно пытаться добиться наибольшей ценности произведённых продуктов с учётом ограничений на имеющееся сырьё. Обозначим через xi производимое количество j-го продукта. Тогда целевую функцию, максимум которой мы будем искать, можно задать так:
(суммарная ценность произведённых продуктов).
Перейдём теперь к учёту ограничений. Прежде всего понятно, что производимые количества продуктов не могут быть отрицательными, то есть должны выполняться условия x1 ≥ 0, х2 ≥ 0, … хn ≥ 0.
Далее, так как для получения единицы j-го продукта необходимо затратить aijединиц i-го сырья, то понятно, что для выработки xi единиц этого продукта потребуется aijxj единиц i-го сырья. Поскольку один вид сырья может использоваться для производства различных продуктов, то суммарный расход сырья каждого вида не должен превышать имеющиеся ресурсы, то есть
i=1, 2, … , m
Окончательно пришли к следующей оптимизационной задаче: найти числа xj (j = 1, … , n), которые обеспечат
при условиях:
1) xj ≥ 0, j = 1, 2, …, n.
2) i=1, 2, …, m.
Всякий набор значений х1, х2,…хn, удовлетворяющий условиям 1 и 2 будем называть допустимым планом (стратегией, управлением или решением). Нас интересует тот допустимый план, который доставляет максимум целевой функции. Будем называть его оптимальным планом (стратегией, управлением, решением). Приведенная задача имеет весьма простую структуру – и целевая функция, и ограничения линейны относительно xj, то есть задаются функциями простейшего вида. Такая специфика имеет как свои достоинства, так и недостатки. Как установлено, она значительно упрощает процесс решения. Но, с другой стороны, далеко не всегда реальная ситуация хорошо описывается линейными функциями, они могут быть много сложнее по структуре.
Тем не менее, класс ситуаций, достаточно хорошо описываемых линейными моделями, весьма широк. Соответствующие экстремальные задачи получили название задач линейного программирования.
Так формулируется типичная задача линейного программирования для экономики, но, как уже отмечалось, исследование операций и, в частности, линейное программирование применяется широко. Рассмотрим пример с решением из области медицины.
Выбор курса лечения.
Рассмотрим модель, предложенную Р.Ледли и Л.Лестедом.
Имеются две возможности лечения рака – лучевая терапия и химиотерапия, причем эффективность обоих методов выражена экспертом в некоторых общих единицах. Например, лекарственный препарат обладает эффективностью в 1000 единиц на грамм препарата, а облучение – 1000 единиц в минуту. Допустим, что для выздоровления больному требуется не менее 3000 единиц эффективности. Однако оба метода токсичны. Поэтому ни тот, ни другой нельзя применять неограниченно. Пусть токсичность методов также выражена в общих единицах, например, токсичность лекарства равна 400 единицам на грамм, а токсичность облучения 1000 единицам в минуту. Допустим, что конкретный больной не должен получить более 2000 таких единиц.
Наконец, известно, что введение одного грамма лекарственного препарата причиняет больному в три раза большие неудобства, чем облучение в течение одной минуты, и, следовательно, если мы ввели х1 единиц веса лекарств и облучали больного в течение х2 минут, то причинили ему общее неудобство, равное
z=3x1+x2 (1)
Задача состоит в том, чтобы подобрать такое соотношение обоих методов лечения (х1 и х2), которое удовлетворяло бы сформулированным выше ограничениям и в то же время причиняло как можно меньше неудобства больному. Такое соотношение назовем оптимальным.
Переходя на математический язык, мы можем сформулировать задачу следующим образом: в плоскости х1Ох2нужно найти такую точку (х1,х2), чтобы величина z=3x1+x2 была наименьшей, и при этом выполнялись условия:
1000х1+1000х2≥ 3000 (2)
(ограничение на эффективность) и
400х1+1000х2 ≤ 2000 (3)
(ограничение на токсичность).
К этим двум ограничениям следует добавить еще одно:
х1≥ 0 и х2 ≥0, (4),
следующее из того, что х1 и х2по сути задачи не могут принимать отрицательные значения.
Условия (2), (3) и (4) выделяют в плоскости х1Ох2 некоторую область, в которой и находится искомая оптимальная точка. Найдём форму этой области. Прежде всего, из условия (4) следует, что искомая точка лежит в первом квадранте. Далее из ограничения (2) следует, что эта точка находится либо на самой прямой
х1 + х2=3 (5),
либо выше этой прямой. Аналогично из (3) следует, что точка может находиться либо на прямой
2х1+5х2=10 (6),
либо ниже этой прямой. Сопоставляя эти условия, получаем, что искомая точка может находиться либо внутри треугольника АВС (рисунок), либо на его границе.
Итак, из всех возможных точек (х1, х2) треугольника АВС (вместе с его границей) нам нужно найти такую, чтобы величина z =3x1 + x2 была наименьшей.
Уравнение (1) – это уравнение плоскости в пространстве x1, x2, z.
Точка (х1, х2) пробегает все возможные положения в треугольнике АВС. В теории линейного программирования доказано, что z принимает наименьшее значение на границе треугольника, точнее в одной (или нескольких) вершине этого треугольника. Если бы переменных (xi) и ограничений было не 2–3, а больше, то оптимальное решение следовало искать среди вершин многомерной фигуры, а не треугольника.
Таким образом, достаточно найти координаты (х1, х2) вершин А, В, и С, подсчитать в этих вершинах значение величины z = 3x1 + x2, а затем выбрать наименьшее (или равные наименьшие) из этих значений. Координаты точек А и С находятся сразу: А = (3, 0) и С = (5, 0). Найдём координаты точки В. Эта точка лежит на пересечении двух прямых с уравнениями (5) и (6). Следовательно, её координаты должны удовлетворять одновременно обоим уравнениям:
Эта система двух линейных уравнений относительно х1 и х2 легко решается, если, например, первое уравнение умножить на два, а затем вычесть его из второго. Мы получим: х1 = 5/3, х2 = 4/3. Это и есть координаты точки В.
Подсчитаем теперь z в точках А, В, и С. Имеем
zA= 9; zB = 3·5/3 + 1·4/3 = 19/3 ≈ 6,3; zC = 15.
Наименьшее значение z (минимум неудобств больному) принимает в точке В = (5/3, 4/3). Следовательно, координаты этой точки и являются искомым решением. Курс лечения будет оптимальным, если ввести 5/3 грамм лекарственного препарата и провести облучение в течение 4/3 минуты.
Разумеется в приведённом примере ситуация намеренно упрощена. В реальном случае, например, может быть не один, а несколько лекарственных препаратов. В соответствии с этим может возрасти и число всевозможных ограничений. Итак, если функция z, наибольшее (или наименьшее) значение которой требуется отыскать, так же как и в этом примере, линейна по xi(z = a1x1 + a2x2 + … + anxn) и ограничения записываются также с помощью любых линейных равенств или неравенств, то подобные задачи являются задачами линейного программирования.
Линейное программирование позволяет решать внешне очень несходные задачи.
Рациональный «раскрой».
На предприятии из листов металла размером 5х10 м требуется выкраивать заготовки типа А и В, имеющих размеры соответственно 4х1 м и 2х3 м. Известны потребности в этих заготовках – нужно выкроить не менее 1600 заготовок каждого типа. Необходимо предложить такой план раскроя, который позволит выполнить плановое задание с минимальными затратами материала (листов).
Каждый лист может быть раскроен по-разному. Например, из листа можно выкроить одну заготовку А, а оставшуюся часть листа отправить в отходы. Сразу ясно, что такой способ раскроя очень плох, так как в отходы идет материал, из которого еще можно выкраивать заготовки. Поэтому с самого начала сосредоточим внимание только на «разумных» способах раскроя, то есть на таких, где в отходы идет материал, из которого уже нельзя выкроить ни одной заготовки. На рисунке приведены такие способы раскроя.
1 способ раскроя: 2 способ раскроя:
12 заготовок типа А 0 заготовок типа А
0 заготовок типа В 8 заготовок типа В
■ – отходы ■ – отходы
3 способ раскроя: 4 способ раскроя:
8 заготовок типа А 6 заготовок типа А
3 заготовки типа В 4 заготовки типа В
отходов нет ■ – отходы
Обозначим через хi (i = 1, 2, 3, 4) количество листов металла, которые раскраиваем i-м способом. Теперь понятно, что такое «план раскроя» – это набор чисел х1. х2, х3, х4, которые показывают, сколько листов раскраиваются каждым способом. Поскольку мы хотим выполнить план с минимальными затратами материала, целевая функция имеет вид:
min {x1 + x2 + x3 + x4}.
Если один лист раскраивается первым способом, то из него получается 12 заготовок типа А. Если же этот способ применен к х1 листам, то заготовок типа А получится 12х1. Рассуждая аналогично по отношению к другим способам раскроя, можно записать условие выполнения плана по заготовкам типа А:
12х1+0х2+8х3 + 6х4 ≥ 1600 и точно так же по заготовкам типа В:
0х1+8х2+3х3+4х4≥1600.
В каждом уравнении 4 слагаемых – по числу способов раскроя. Кроме того, понятно, что величины xi (i = 1, 2, 3, 4) не должны быть отрицательными, так как нельзя раскроить отрицательное число листов материала.
Окончательная формулировка задачи: найти хi (i = 1 … 4), который обеспечит минимум целевой функции
z = x1 + x2 + x3 + x4
при условиях:
12х1+0х2+8х3 + 6х4 ≥ 1600
0х1+8х2+3х3+4х4≥1600
х1 ≥ 0, х2 ≥ 0, х3 ≥ 0, х4 ≥ 0.
В результате пришли к задаче линейного программирования. С помощью стандартных приёмов получаем решение – оптимальный план раскроя, состоящий в следующем: 125 листов кроятся по второму способу раскроя (х2 = 125), а 200 листов – по третьему способу раскроя (х3 = 200), х1 = х4 = 0, то есть первый и четвертый способы вообще не используются. Получилось ровно по 1600 заготовок типа А и В. Конечно далеко не всегда удается получить раскрой почти без отхода или лишних заготовок, но линейное программирование гарантирует минимум затрат листов. «Вручную» такой план раскроя, особенно при более сложной задаче, получить невозможно.
Подобная формализация задачи пригодна не только для раскроя, но, например, для оптимального размещения заданного числа ящиков нескольких размеров в однотипных складских помещениях.
Определение плана перевозок.
Пусть имеется m предприятий А1, А2, А3, … Аm, производящих один и тот же продукт (одного качества) в количествах, равных соответственно а1, а2, а3, … аm. Есть и n потребителей этого продукта, находящихся в пунктах В1, В2, В3,…Вn, причем потребности их известны и равны b1, b2, b3,…bn. Предполагается, что суммарный объем потребления равен суммарному объему выпуска продукта на всех предприятиях. Перевозка единицы продукта от i-го предприятия к j-му потребителю ведет к затратам, которые составляют cij. В этих условиях требуется определить наилучший план перевозок с min общих затрат.
Построим математическую модель этой ситуации. Через xijобозначим количество продукта, перевозимого с i-го предприятия к j-му потребителю. Выпишем ограничения, которым должны удовлетворять эти величины. Прежде всего, каждый потребитель должен получить ровно столько продукта, сколько ему требуется, то есть
j = 1, 2, … , n.
Так как производится столько же, сколько и потребляется, с каждого предприятия продукт должен вывозиться полностью, то есть
i = 1, 2, … , m.
Понятно также, что перевозимые количества продукта не могут быть отрицательными:
xij ≥ 0, i = 1, 2, … , m; j = 1, 2, … , n.
В качестве целевой функции, подлежащей минимизации, выступают суммарные затраты на перевозку, определяемые формулой
Окончательно приходим к следующей задаче.
Найти xij, которые обеспечат:
При условиях
j = 1, 2, … , n.
i = 1, 2, … , m
xij≥0; i = 1, 2, … , m; j = 1, 2, … , n.
Рассмотрим числовой пример. Пусть объёмы выпуска предприятий равны следующим величинам: а1=145 т, а2=125 т, а3=220 т, а4=135 т. Объемы потребления таковы: b1=120 т, b2=125 т, b3=130, т b4=110 т, b5=140 т. Легко видеть, что задача сбалансирована – объём выпуска равен объёму потребления. Затраты cij (в руб.) на перевозку единицы продукции (1 тонны)от i–го предприятия к j–му потребителю представлены в таблице.
b1(120)
b2(125)
b3(130)
b4(110)
b5(140)
а1(145)
а2(125)
а3(220)
а4(135)
Решение начнём с того, что попробуем подобрать хороший план перевозок, опираясь только на здравый смысл. Будем рассуждать так. Самую дешевую перевозку, по 14 руб. за 1 т продукта, можно осуществить от второго предприятия к третьему потребителю. Поэтому включим ее в план перевозок с наибольшей возможной интенсивностью, то есть планируем перевозку 125 т продукта от второго предприятия к третьему потребителю. Следующая минимальная по дороговизне перевозка может быть осуществлена от третьего предприятия к четвертому потребителю 110 т продукта. Рассуждая аналогично, придём к следующему плану перевозки, представленному в таблице.

 ♂
♀
♂
♀
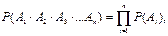
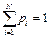
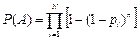 - вероятность того, что из n испытаний случайно возьмём хотя бы одно семя от каждого биотипа. Далее подбираем n – объем выборки семян. Не вдаваясь в подробности отметить, что эта формула верна, если n значительно (в 5 и более раз) превышает N.
- вероятность того, что из n испытаний случайно возьмём хотя бы одно семя от каждого биотипа. Далее подбираем n – объем выборки семян. Не вдаваясь в подробности отметить, что эта формула верна, если n значительно (в 5 и более раз) превышает N.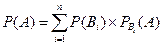 ,
,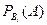 – условная вероятность наступления события А совместно с Вi.
– условная вероятность наступления события А совместно с Вi.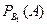 появления всех трёх серых мышей в потомстве равна 13. Если же для скрещивания случайно взяли серую мышь с генотипом Сс (событие В2), то после скрещивания Сс х сс в потомстве будет ½ серых (Сс) и ½ белых (сс) мышей, и условная вероятность
появления всех трёх серых мышей в потомстве равна 13. Если же для скрещивания случайно взяли серую мышь с генотипом Сс (событие В2), то после скрещивания Сс х сс в потомстве будет ½ серых (Сс) и ½ белых (сс) мышей, и условная вероятность 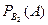 того, что все три потомка будут серыми, равна (½)3.
того, что все три потомка будут серыми, равна (½)3.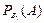 = 1 – вероятность того, что это случайно взятое зерно, образовавшееся в результате самоопыления на растении АА, имеет генотип АА;
= 1 – вероятность того, что это случайно взятое зерно, образовавшееся в результате самоопыления на растении АА, имеет генотип АА;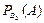 = 1/4 – вероятность того, что это зерно с растения Аа имеет генотип АА;
= 1/4 – вероятность того, что это зерно с растения Аа имеет генотип АА;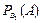 = 0 – вероятность того, что случайно взятое зерно с такого растения имеет генотип АА.
= 0 – вероятность того, что случайно взятое зерно с такого растения имеет генотип АА.



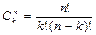 ;
;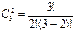 ;
; 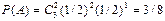 .
.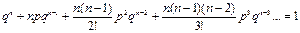
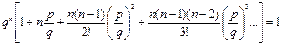
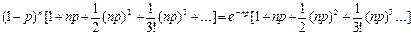
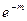
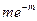
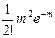
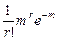
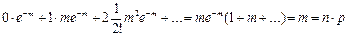
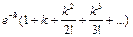 .
.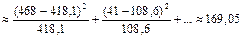
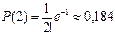 , а вероятности заболевания 3, 4 и 5 детей соответственно равны
, а вероятности заболевания 3, 4 и 5 детей соответственно равны 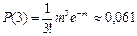 ;
; 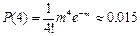 ;
; 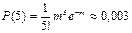 Вероятность того, что хотя бы один ребёнок заболеет равна 1 – Р(0) = 1 – е–1 ≈ 0,632.
Вероятность того, что хотя бы один ребёнок заболеет равна 1 – Р(0) = 1 – е–1 ≈ 0,632.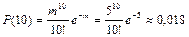 .
. 4. Исследование операций на основе оптимизационных моделей.
4. Исследование операций на основе оптимизационных моделей.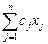 (суммарная ценность произведённых продуктов).
(суммарная ценность произведённых продуктов).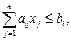 i=1, 2, … , m
i=1, 2, … , m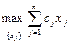
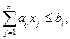 i=1, 2, …, m.
i=1, 2, …, m.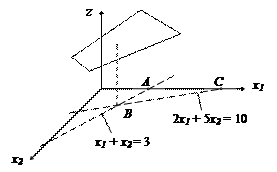
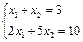
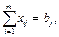 j = 1, 2, … , n.
j = 1, 2, … , n.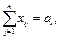 i = 1, 2, … , m.
i = 1, 2, … , m.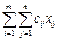
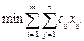
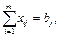 j = 1, 2, … , n.
j = 1, 2, … , n.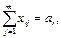 i = 1, 2, … , m
i = 1, 2, … , m


 а1(145)
а1(145)
 а2(125)
а2(125)


 а3(220)
а3(220)
 а4(135)
а4(135)