Такого рода регулятор должен обладать способностью приобретать знания о поведении объекта и системы и на их основе вырабатывать управление, при котором ошибка регулирования не превышает допустимой величины. В процессе обучения, помимо регулятора, участвует модель объекта, которая также должна приобретать знания и настраиваться на меняющиеся условия функционирования объекта. Указанным требованиям и описанию регулятора и объекта управления в достаточно полной мере удовлетворяет нечеткая TS-модель со структурой пятислойной нейронной сети прямого действия, известной под именем ANFIS (Adaptive-Network-based Fuzzy Inference Systems).
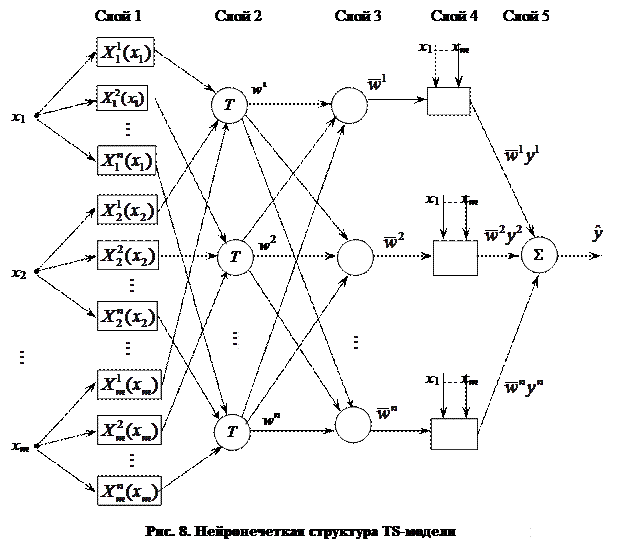
Нейронечеткая структура обобщенной TS-модели с n правилами и m входами, реализующая механизм вывода у, изображена на рис. 8.
В первом слое при , вычисляются степени функций принадлежности, а во втором слое они обрабатываются Т-оператором минимизации или произведения. В третьем слое (N) определяются нормализованные веса , на которые в четвертом слое умножаются соответствующие значения уq, найденные по линейным уравнениям
Пятый слой – суммирование и получение итогового значения .
Приобретение TS-моделью знаний об объекте заключается в определении коэффициентов уравнений , параметров функций принадлежности , и числа правил n, при которых выходы модели и объекта у совпадают или становятся близкими.
Если число правил n фиксировано, функции принадлежности непрерывны относительно параметров d и обрабатываются Т-оператором произведения ( ), то TS-модели можно обучать методом обратного распространения ошибки BP (Back Propagation). Он заключается в минимизации квадратической ошибки градиентным методом
, (22)
где с = (b, d) – вектор параметров; h – рабочий шаг.
На основании цепного правила определения частных производных по
и по
без промежуточных выкладок запишем их аналитические выражения
,
В качестве функции принадлежности обычно выбираются сигмоидные ,
или радиально-базисные функции,
дифференцируемые по d, d1и d2.
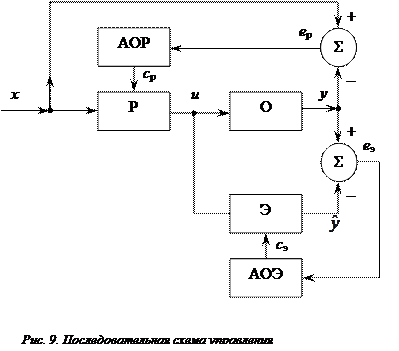
Приведем постановку задачи обучения нейронечеткого регулятора Р прямого действия, т.е. соединенного последо-вательно с объектом О (рис. 9).
Пусть объект управления с одним выходом описывается дискретным уравнением
в которой обеспечивается требуемая близость к u(t) при соответствующих входах и которая предлагается в качестве регулятора. Обучение регулятора алгоритмом АОР управлению с минимальной квадратической ошибкой
в последовательной схеме (см. рис. 9) связано с вычислением выражения
,
в котором не определено значение производной . Его можно легко найти с помощью нейронечеткой модели объекта, именуемой эмулятором
,
вычисляя вместо . Обучение эмулятора Э алгоритмом АОЭ, обеспечивающим минимальную квадратическую ошибку
,
также как и регулятора, осуществляется ВР-методом.
Все основные недостатки первых обучаемых систем управления связаны с применением ВР-метода, а именно: локальный характер поиска и частое «зацикливание», присущие градиентным методам; требование непрерывности и дифференцируемости функций принадлежности; не определяются порядок (r, s) и количество правил n.
Для устранения “зацикливания” рекомендуется генетическим алгоритмом менять (встряхивать) размер рабочего шага h в формуле градиентов (22) и компоненты вектора с. Для целей обучения достаточно применять только генетические алгоритмы, позволяющие преодолеть первые два недостатка ВР-метода.
Наибольший эффект был достигнут при гибридном обучении, осуществляемом генетическим алгоритмом, уточняющим параметры функций принадлежности d, совместно с многошаговым методом наименьших квадратов (17), (18) для нахождения вектора b и другими алгоритмами, определяющими порядок r, s и число правил n в ТS-модели. При таком подходе удалось в значительной мере устранить все недостатки ВР-метода.
Обучаемые нечеткие регуляторы и системы управления относятся к классу наиболее перспективных. Они сохраняют высокую работоспособность в условиях помех и погрешностей измерения и достаточно быстро настраиваются на меняющиеся условия производства, снижая тем самым потери от неэффективного управления.
Вместе в тем, в ряде случаев и ЛЛР показывают высокую работоспособность. Так, в системах управления достаточно простыми объектами ЛЛР могут успешно конкурировать с обучаемыми регуляторами.

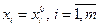 , вычисляются степени функций принадлежности, а во втором слое они обрабатываются Т-оператором минимизации или произведения. В третьем слое (N) определяются нормализованные веса
, вычисляются степени функций принадлежности, а во втором слое они обрабатываются Т-оператором минимизации или произведения. В третьем слое (N) определяются нормализованные веса 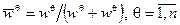 , на которые в четвертом слое умножаются соответствующие значения уq, найденные по линейным уравнениям
, на которые в четвертом слое умножаются соответствующие значения уq, найденные по линейным уравнениям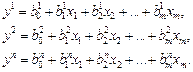
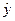 .
.
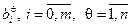 , параметров функций принадлежности
, параметров функций принадлежности  , и числа правил n, при которых выходы модели
, и числа правил n, при которых выходы модели 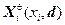 непрерывны относительно параметров d и обрабатываются Т-оператором произведения (
непрерывны относительно параметров d и обрабатываются Т-оператором произведения ( 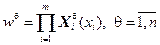 ), то TS-модели можно обучать методом обратного распространения ошибки BP (Back Propagation). Он заключается в минимизации квадратической ошибки
), то TS-модели можно обучать методом обратного распространения ошибки BP (Back Propagation). Он заключается в минимизации квадратической ошибки  градиентным методом
градиентным методом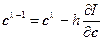 , (22)
, (22)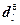

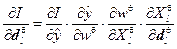
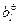
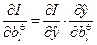
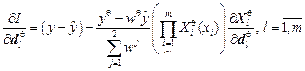 ,
,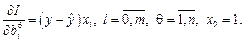
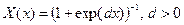 ,
, или радиально-базисные
или радиально-базисные 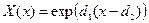 функции,
функции, , инверсная уравнению (23):
, инверсная уравнению (23):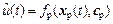 ,
,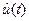 к u(t) при соответствующих входах и которая предлагается в качестве регулятора. Обучение регулятора алгоритмом АОР управлению с минимальной квадратической ошибкой
к u(t) при соответствующих входах и которая предлагается в качестве регулятора. Обучение регулятора алгоритмом АОР управлению с минимальной квадратической ошибкой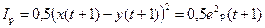
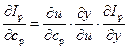 ,
, . Его можно легко найти с помощью нейронечеткой модели объекта, именуемой эмулятором
. Его можно легко найти с помощью нейронечеткой модели объекта, именуемой эмулятором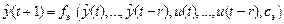 ,
,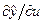 вместо
вместо 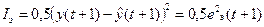 ,
,