Пусть имеется выборка (х1,....,хn) – таблица наблюденных значений из генеральной совокупности с признаком Х.
Для того чтобы получить первое представление об этом распределении составляют гистограмму (рис. 2.5). Производят разбиение оси на определенное число граничащих друг с другом интервалов D1,...,Dk. Затем подсчитывают число mi выборочных значений, лежащих в Di (1 £ i £ k). Эти числа называют групповыми частотами. Над Diрисуют прямоугольники высоты mi/n(относительные частоты попадания в интервал). Полученный ступенчатый график называют гистограммой выборки.
Рис .2.5. Гистограмма
Удобным способом получить представление о распределении Х является построение эмпирической функции распределения. Для этого подсчитывают число выборочных значений меньших x. Обозначим это число . Ступенчатая функция называется эмпирической функцией распределения выборки (х1,...,xn)(рис. 2.6).
Рис. 2.6. Эмпирическая кривая распределения
Характеристики выборки:
среднее значение (математическое ожидание) ;
разброс (среднее квадратичное отклонение) .
Для проверки соответствия наблюдений какому-либо закону, выдвигают гипотезу.
Например, анализ гистограммы, показанной на рис. 2.5, позволяет выдвинуть гипотезу о том, что анализируемая случайная величина имеет нормальное распределение (рис. 2.7).
Рис. 2.7. Гистограмма и гипотетическая кривая плотности нормального распределения
Для данной выборки среднее значение = 5,928, разброс s = 2,092.
Для проверки гипотезы используются критерии согласия.
Критерий согласия c2 служит для проверки степени совпадения (согласия) эмпирического (реального) распределения случайной величины с ее гипотетическим (теоретическим) распределением (рис. 2.7).
, где pi – ожидаемая (теоретическая) вероятность попадания случайной величины в i-й интервал; mi – фактическая частота попадания в выделенные n интервалов. Критерием служит соотношение расчетной величины c2 и ее максимального значения , определяемого по таблицам или расчетом, где a – уровень значимости, определяющий надежность оценки. Если , гипотеза принимается.
Для рассматриваемого примера получено значение критерия согласия (MathCad) равное 0,988 [3].
Вероятность ошибки при принятии гипотезы мала, т.е. с вероятностью близкой к 1, можно считать распределение нормальным.
Не существует общего критерия, который позволял бы решить, когда выборка может считаться большой (достаточной), а когда малой (недостаточной). В то время как распределение одной функции выборки уже при n=30 может считаться очень хорошим приближением, для другой – и при n=100 это еще невозможно.
Поэтому уровень доверия результатам статистической обработки каждой конкретной оценивается индивидуально.
Решение данной задачи, обычно связывается с назначением доверительных интервалов для среднего значения, т.е., оценки того, что данное среднее значение с заданным уровнем доверия (доверительной вероятности) равно .
Зададимся несколькими уровнями доверия, например, 90%, 95% и 99%. Доверительные интервалы вычисляют на основании критерия Стьюдента.
Величина доверительного интервала , где n – количество измерений случайной величины; p0 – доверительная вероятность; – коэффициент Стьюдента, принимаемый по таблицам или рассчитываемый; s– оценка среднеквадратичного отклонения.
В результате вычислений для рассматриваемого примера были получены значения доверительных интервалов:
Доверительная вероятность
90%
95%
99%
Способы
5,928±0,144
5,928±0,185
5,928±0,262
представления
5,784ё6,072
5,743ё6,213
5,666ё6,190
Для большинства технических приложений доверительный интервал равный половине величины среднеквадратического отклонения sсчитается приемлемым.
Для определения количества экспериментов, обеспечивающих получение статистических зависимостей с требуемым уровнем доверия и величиной доверительного интервала, рассчитаем таблицу значений величины множителя, на который умножается оценка среднеквадратического отклонения при определении доверительного интервала:
Количество величин s
Доверительная вероятность
в доверительном интервале
0,95
0,99
0,995
1,5
0,5
0,25
0,1
Как видно из таблицы при количестве опытов 20-35 (для рассматриваемого примера), величина доверительного интервала достигает половины величины среднеквадратичного отклонения s, что вполне приемлемо для большинства технических приложений.
Для обеспечения большего уровня доверия, например 0,999 (такой уровень доверия обычно считается соответствующим практической достоверности для технических приложений) требуется увеличить число опытов. Уменьшение величины доверительного интервала также требует увеличения числа опытов.
2.2. Сортировка [4]
Сортировка – процесс перегруппировки заданного множества (массива) объектов в некотором определенном порядке (например, по алфавиту, в порядке убывания и т.п.). Цель сортировки – облегчить последующий поиск объектов в таком отсортированном множестве.
Каждый элемент массива должен иметь свое имя. В зависимости от критерия, которым будет использоваться при сортировке массива, нужно определить и некоторую характеристику элементов массива (ключ).
При сортировке массивов чисел с использованием числовых критериев, например, в порядке убывания или возрастания – имя и ключ совпадают и соответствуют значению элемента массива.
При выборе метода сортировки массива важнейшим фактором (как и во всех других случаях) является его экономичность, то есть время его работы. Мерой эффективности может быть C – число необходимых сравнений ключей и M – число необходимых перестановок элементов. Естественно, что эти величины функционально зависят от n – числа сортируемых элементов. Простые методы требуют порядка n2 сравнений ключей, тогда как улучшенные методы (более сложные) позволяют сократить это число до .
Сортировка с помощью прямого включения. В процессе сортировки с помощью данного метода в массиве поочередно выбираются элементы, начиная со второго. Элемент сравнивается с предыдущим и в зависимости от результата сравнения, либо остается на прежнем месте, либо перемещается влево. Процесс такой сортировки можно назвать просеиванием. Среднее число сравнений и перестановок:
При n =1000, С =250250, M =252250.
Сортировка с помощью прямого выбора. Процесс сортировки с помощью данного метода можно представить как последовательность следующих действий:
1. Из массива выбирается элемент с наименьшим значением.
2. Он меняется местами с первым элементом.
3. Затем этот процесс повторяется с оставшимися элементами и так до тех пор, пока не останется один самый большой элемент.
Число сравнений не зависит от изначального порядка элементов:
.
Среднее число перестановок:
где g = 0.577216 – константа Эйлера.
При n = 1000, С = 499500, M = 7485.
Сортировка с помощью прямого обмена.Алгоритмпрямого обмена основывается на сравнении и смене мест для пары соседних элементов и продолжении этого процесса до тех пор, пока не будут упорядочены все элементы. Как и в методе прямого выбора, повторяются проходы по массиву, каждый раз сдвигая наименьший элемент оставшейся последовательности к левому краю массива.
Если рассматривать массивы как вертикальные, то элементы можно представить как пузырьки в сосуде с водой. Причем вес каждого из них соответствует его значению. В этом случае каждый пузырек как бы поднимается до уровня, соответствующего его весу. Такой метод широко известен как "пузырьковая сортировка".
При этом данный метод – самый неэффективный. Число сравнений не зависит от начального порядка элементов: .
Среднее число перестановок: .
При n =1000, С =499500, M =749250.
Улучшенные методы сортировки призваны сократить число необходимых сравнений и перестановок. Этого удается добиться, усложняя алгоритмы методов, основываясь на их специфических особенностях.
Рассмотрим улучшенный метод "пузырьковой сортировки". Если учесть, что пузырьковая сортировка является самым неэффективным методом прямой сортировки, то всего лишь некоторое его улучшение (Ч. Хоар) приводит к самому быстрому из известных в данный момент методу сортировки массивов данных. Это метод «быстрой сортировкой» (Quicksort).
Алгоритм быстрой сортировки сводится к следующим действиям:
1. Выберем наугад какой-либо элемент массива (лучше, если это будет медиана или среднее значение массива). Назовем его Х.
2. Будем просматривать массив слева до тех пор, пока не обнаружим элемент меньше Х (ai<X). Затем будем просматривать массив справа, пока не встретим элемент больше Х (aj>X).
3. Поменяем местами найденные элементы.
4. Продолжим процесс просмотра и обмена, пока оба просмотра не встретятся где-то в середине массива.
В результате массив окажется разбитым на две части: левую с элементами меньше (или равными) Х и правую – больше (или равными) Х.
5. Изложенный выше алгоритм применяется к получившимся двум его частям, затем к частям частей и так до тех пор, пока каждая из частей не будет состоять только из одного элемента.
Если в качестве границы все время выбирать медиану, то число сравнений равно , а число обменов . При n =1000, С = 6908, M =1151. (При пузырьковой сортировке С = 499500, M = 749250).
Для оценки эффективности усовершенствованных методов нет сколько-нибудь осмысленных и точных формул. В общем случае затраты времени составляют , где с – эмпирический коэффициент определяемый опытным путем. Если в алгоритме Quicksort в качестве контрольной величины всегда выбирать медиану с = 1.
2.3. Интерполяция табличных зависимостей
Часто приходится рассматривать (и моделировать) функции, заданные в виде таблицы (массива, матрицы). При этом могут потребоваться значения этих функций при промежуточных, не входящих в таблицу, значениях независимой переменной (задача интерполяции) или при значениях переменной, лежащих за пределами таблицы (задача экстраполяции) [4].


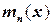 . Ступенчатая функция
. Ступенчатая функция  называется эмпирической функцией распределения выборки (х1,...,xn)(рис. 2.6).
называется эмпирической функцией распределения выборки (х1,...,xn)(рис. 2.6).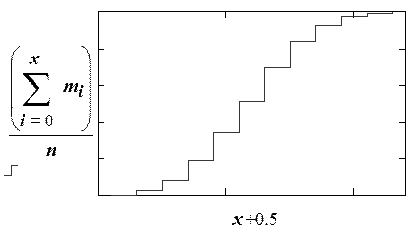
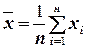 ;
;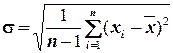 .
.
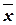 = 5,928, разброс s = 2,092.
= 5,928, разброс s = 2,092.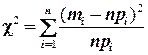 , где pi – ожидаемая (теоретическая) вероятность попадания случайной величины в i-й интервал; mi – фактическая частота попадания в выделенные n интервалов. Критерием служит соотношение расчетной величины c2 и ее максимального значения
, где pi – ожидаемая (теоретическая) вероятность попадания случайной величины в i-й интервал; mi – фактическая частота попадания в выделенные n интервалов. Критерием служит соотношение расчетной величины c2 и ее максимального значения 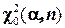 , определяемого по таблицам или расчетом, где a – уровень значимости, определяющий надежность оценки. Если
, определяемого по таблицам или расчетом, где a – уровень значимости, определяющий надежность оценки. Если 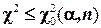 , гипотеза принимается.
, гипотеза принимается.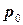 равно
равно 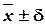 .
.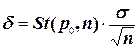 , где n – количество измерений случайной величины; p0 – доверительная вероятность;
, где n – количество измерений случайной величины; p0 – доверительная вероятность; 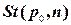 – коэффициент Стьюдента, принимаемый по таблицам или рассчитываемый; s– оценка среднеквадратичного отклонения.
– коэффициент Стьюдента, принимаемый по таблицам или рассчитываемый; s– оценка среднеквадратичного отклонения.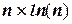 .
.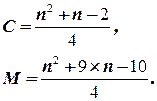
 .
.
 .
. .
. , а число обменов
, а число обменов  . При n =1000, С = 6908, M =1151. (При пузырьковой сортировке С = 499500, M = 749250).
. При n =1000, С = 6908, M =1151. (При пузырьковой сортировке С = 499500, M = 749250).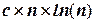 , где с – эмпирический коэффициент определяемый опытным путем. Если в алгоритме Quicksort в качестве контрольной величины всегда выбирать медиану с = 1.
, где с – эмпирический коэффициент определяемый опытным путем. Если в алгоритме Quicksort в качестве контрольной величины всегда выбирать медиану с = 1.