Тонкость этой процедуры заключается в том, что результаты исполнения микроопераций должны быть возвращены в контексте IA-архитектуры в том же порядке, в каком эти микрооперации были сгенерированы в модуле Fetch/Decode Unit при декодировании входного потока инструкций исполняемой программы.
Ситуация усложняется еще тем, что все это происходит на фоне непрекращающегося потока всевозможных прерываний, точек останова, ошибок предсказания переходов, а также внештатных ситуаций в работе процессора, которые нужно успевать обрабатывать.
Retire Unit процессора Pentium II способен завершить и удалить до трех микроопераций за один такт работы процессора.
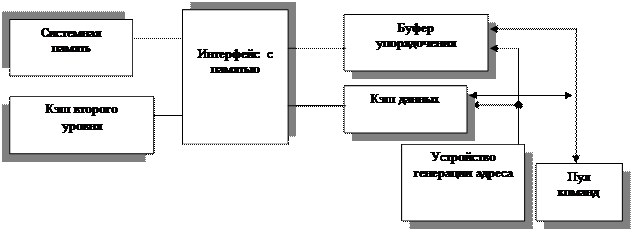
Bus Interface Unit. Этот модуль (рис. 4.15) отвечает за обмен данными между Ll-кэшом инструкций, L1-кэшом данных, системной шиной и L2-кэшом.
При чтении из памяти должны быть заданы адрес памяти, размер блока считываемых данных и регистр-назначение. Команда чтения кодируется одной микрокомандой.
При записи надо задать адрес памяти, размер блока записываемых данных и сами данные. Поэтому команда записи кодируется двумя микрокомандами: первая генерирует адрес, вторая готовит данные. Эти микрокоманды планируются независимо и могут выполняться параллельно; они могут переупорядочиваться в буфере записи.
Запись в память никогда не выполняется опережающим образом, так как нет эффективного способа организации отката в случае неверного предсказания. Разные команды записи никогда не переупорядочиваются друг относительно друга. Буфер записи инициирует запись, только когда сформированы и адрес, и данные, и нет ожидающих выполнения более ранних команд записи.
При изучении вопроса о возможности и целесообразности переупорядочения доступа к памяти инженеры "Intel" пришли к следующим выводам.
Команда записи не должна обгонять идущую впереди команду записи, так как это может лишь незначительно увеличить производительность.
Можно запретить командам записи обгонять команды чтения из памяти, так как это приведет лишь к незначительной потере производительности.
Запрет командам чтения обгонять другие команды чтения или команды записи может повлечь существенные потери в производительности.
Поэтому была реализована архитектура подсистемы памяти, позволяющая командам чтения опережать команды записи и другие команды чтения.
Буфер упорядочения памяти служит в качестве распределительной станции и буфера переупорядочивания. В нем хранятся отложенные команды чтения и записи, и он осуществляет их повторное диспетчирование, когда блокирующее условие (зависимость по данным или недоступность ресурсов) исчезает.
В процессоре AMD-K6-2 реализована так называемая "Enhanced RISC86"-микроархитектура. Напомним, что RISC — это аббревиатура от Reduced Instruction Set Computing ("вычисления с сокращенным набором команд"). RISC-процессор обладает меньшим числом команд фиксированной длины. Упрощенная структура позволяет RISC-процессору развивать более высокую скорость. Типичные представители RISC-процессоров — Alpha от DEC, SPARC от SUN, PowerPC от IBM.
В противоположность этому CISC — сокращение от Complex Instruction Set Computing ("вычисления со сложным набором команд"). Все члены семейства х86 — типичные представители CISC-процессоров со cложными, но удобными наборами команд. Что касается AMD-K6-2, то речь в данном случае идет об объединенной архитектуре на основе преобразования х86-команд в более простые в обращении RISC-инструкции,
Основная ее особенность состоит в том, что внешние х86-инструкции, поступающие на обработку в процессор, преобразуются во внутренние RISC86-инструкции, которые и исполняются процессором. Вместо того чтобы напрямую исполнять сложные х86-инструкции с переменной длиной от 1 до 15 байт, процессор обрабатывает поток простых RISC86-инструкций фиксированной длины.
В состав процессора AMD-K6-2 (рис. 4.16) входят несколько основных модулей; L1-кэш данных (Level-One Dual Port Data Cache), Li-кэш инструкций (Level-One Instruction Cache) с кэшем предварительного декодирования (Predecode Cache), модуль декодирования (Multiple Instruction Decoders), центральный планировщик (Centralized RISC86 Operation Scheduler), вычислительные блоки (Execution Units) и модуль предсказания переходов (Branch Logic).
L1-кэш инструкций и данных, предварительное декодирование. L1-кэш состоит из двух независимых блоков: L1-кэша данных (Level-One Dual Port Data Cache) и L1-кэша инструкций (Level-One Instruction Cache) с кэшем предварительного декодирования (Predecode Cache). L1-кэш данных предназначен только для хранения данных и имеет объем 32 Кбайт- Несколько сложнее обстоит дело с L1-кэшем инструкций: наряду с инструкциями, для хранения которых предназначены 32 Кбайт памяти, в нем хранятся так называемые "биты преддекодирования" (predecode bits) — для них отведено 20 Кбайт памяти. Дело в том, что после загрузки инструкции в L1-кэш инструкций выполняется ее предварительное декодирование (predecoding) — к каждому байту инструкции добавляется пять бит (из этого и следует соотношение 32 Кбайт/20 Кбайт = 8/5), в которые записывается информация о количестве байт, оставшихся до начала следующей инструкции. Эта информация используется на этапе декодирования х86-инструкций в RISС8б-инструкции. После того, как L1 -кэш инструкций полностью заполнится данными, инструкции вместе с преддекодированными битами передаются в буфер инструкций (Instruction Buffer).
Модуль декодирования (Multiple Instruction Decoders), Модуль декодирования извлекает х86-инструкций (до 16 байт данных с инструкциями за один такт) с битами преддекодирования из буфера инструкций (Instruction Buffer), определяет границы инструкций и преобразует их в RISC86-инструкции. Непосредственно преобразованием занимаются четыре декодера; два для декодирования простых (Short Decoder #1, Short Decoder #2) и два для декодирования сложных х86-инструкций (Long Decoder, Vector Decoder). Одновременно могут работать либо два декодера Short Decoder #1 и Short Decoder #2, либо декодер Long Decoder, либо декодер Vector Decoder.