Процессор Pentium II построен на основе семи базовых модулей (рис. 4.10) — Fetch/Decode Unit (модуль загрузки/декодирования инструкций), Dispatch/Execute Unit (модуль диспетчеризации/исполнения инструкций), Retire Unit (модуль завершения и удаления инструкций). Instruction Pool (пул инструкций, его также называют Reorder Buffer — буфер переупорядочивания инструкций). Bus Interface Unit (модуль внешнего интерфейса), LI ICache (L1-кэш для инструкций) и LI DCache (L1-кэш для данных).
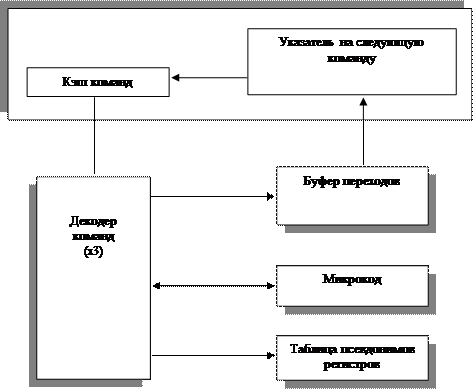
Fetch/Decode Unit предназначен для приема входного потока инструкций исполняемой программы, поступающего из L1-кэша инструкций, и их последующего декодирования в поток микроопераций (рис. 4.11).
Этот модуль работает следующим образом. Прежде всего, блок Next_IP вычисляет индекс (порядковый номер) инструкции, содержащейся в L1-кэше инструкций, которая должна быть обработана следующей — то есть извлечена из L1-кэша инструкций и передана для последующего декодирования.
Индекс этой инструкции вычисляется блоком Next_IP на основе поступающей в него информации о прерываниях, которые были переданы в процессор для обработки, возможных предсказанных переходах (предсказание выполняется блоком Branch Target Buffer), и сообщениях о неправильно предсказанных переходах (branch-misprediction), которые поступают от целочисленных вычислительных ресурсов, расположенных в модуле Dispatch/Execute Unit. После вычисления индекса следующей обрабатываемой инструкции Li-кэш инструкций извлекает две строки кэшированных данных (cache line) — ту, которая соответствует вычисленному индексу, и следующую за ней, — а затем передает для декодирования извлеченные 16 байт, которые содержат IA-инструкции (Intel Architecture). Начало и конец IA-инструкций маркируются.
Далее маркированный поток байт обрабатывается сразу тремя параллельно работающими декодерами, которые отыскивают в нем IA-инструкции. Каждый декодер преобразует найденную IA-инструкцию в набор триадных микроопераций (uops) — триадных в том смысле, что микрооперация проводится над двумя исходными логическими операндами, а в результате ее выполнения получается только один логический результат. Микрооперация — это примитивная инструкция, которая может быть выполнена одним из вычислительных ресурсов, расположенных в модуле Dispatch/Execute Unit.
Из трех декодеров два — простые, которые могут преобразовывать только IA-инструкций, требующие выполнения одной микрооперации, а третий декодер — более совершенный; он может преобразовывать IA-инструкции, требующие выполнения от одной до четырех микроопераций. Таким образом, за один такт работы процессора все три декодера могут в сумме сгенерировать максимум шесть микроопераций. Для преобразования еще более сложных IA-инструкций используется микрокод, который содержится в блоке Microcode Instruction Sequencer и представляет собой набор предварительно запрограммированных последовательностей обычных микроопераций.
Устройство выборки/декодирования
от интерфейса шины
Полученные таким образом микрооперации передаются в блок Register Alias Table Allocate, где все содержащиеся в микрооперациях адреса lA-регистров преобразуются в адреса внутренних физических регистров процессора семейства Р6 — тем самым IA-архитектура и Рб-архитекура оказываются развязанными. Это существенно увеличивает возможности работы процессора при вычислениях, так как, во-первых, отпадает необходимость следить за целостностью содержимого IA-регистров при исполнении инструкций, во-вторых, адресное пространство перестает быть ограниченным возможностями IA-архитектуры и может быть значительно расширено, что приводит к росту скорости вычислений, и, в-третьих, такая переадресация обеспечивает возможность спекулятивного исполнения инструкций — далее все вычисления ведутся во внутренней Р6-архитектуре процессора, а IA-архитектура снова появляется "на сцене" только на этапе завершения инструкций в модуле Retire Unit.
На этом же этапе к каждой микрооперации как информационной единице добавляются флаги состояния, в которые записывается информация об ее статусе. После этого микрооперации передаются в пул инструкций.
Instruction Pool (Reorder Buffer). Основное назначение этого модуля — предоставить возможность исполнения микроопераций в произвольном порядке; в том числе, отличном от порядка их генерации.
В тот момент, когда микрооперации попадают в пул инструкций, порядок их следования в потоке соответствует тому порядку, в котором они были сгенерированы в результате декодирования IA-инструкций, поступивших на вход модуля Fetch/Decode Unit, — никакого изменения порядка следования пока не произошло. Пул инструкций представляет собой последовательный массив инструкций; при этом любая из этих инструкций может быть в любой момент времени обработана модулем Dispatch/Execute Unit или Retire Unit — то есть порядок обработки инструкций может быть произвольным и не зависит от первоначального порядка, в котором инструкции поступили в пул. Именно поэтому пул инструкций иногда называют еще буфером переупорядочивания инструкций (Reorder Buffer).
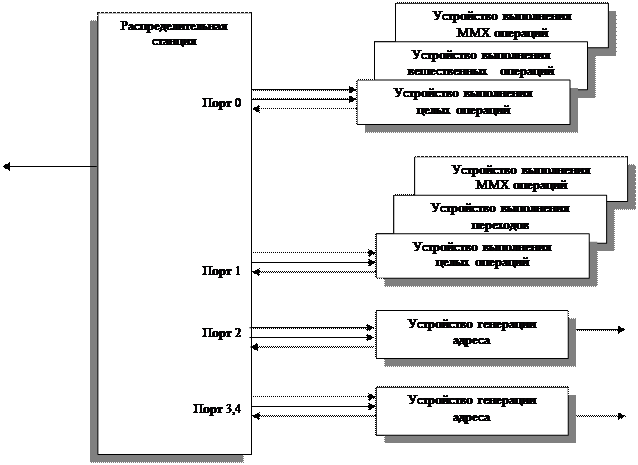
Dispatch/Execute Unit. Этот модуль проверяет состояние микроопераций, содержащихся в пуле инструкций, исполняет их, если есть такая возможность, и записывает полученные результаты обратно в пул инструкций (рис. 4.12).
Reservation Station — основной управляющий блок модуля Dispatch/Execute Unit. Именно он планирует порядок исполнения и занимается диспетчеризацией (распределением между вычислительными ресурсами) микроопераций. Этот блок последовательно просматривает пул инструкций в поисках микроопераций, которые готовы к исполнению — таковыми считаются микрооперации, у которых готовы (т.е. вычислены/загружены) исходные операнды, — и передает (распределяет, диспетчеризует) их на исполнение свободным вычислительными ресурсам, которые могут исполнить микрооперацию. Результаты исполнения микрооперации записываются в пул инструкций и хранятся там вместе с самой микрооперацией до тех пор, пока последняя не будет завершена — этим занимается уже модуль Retire Unit.
Следует подчеркнуть, что жесткого, заранее предопределенного порядка исполнения микроопераций не существует — они исполняются сразу же, как только бывают готовы их операнды и свободен соответствующий вычислительный ресурс. В том случае, если одному и тому же ресурсу может быть одновременно передано на исполнение более одной микрооперации, последние исполняются по принципу псевдо-FIFO (First In First Out) — первой исполняется та микрооперация, которая раньше попала в пул инструкций.
Reservation Station имеет пять портов, через которые организуется обмен данными с пятью вычислительными ресурсами. Поэтому Dispatch/Execute Unit может за один такт исполнить максимум пять микроопераций. Однако при реальной работе с постоянной равномерной нагрузкой на процессор наиболее типична ситуация, когда за один такт исполняется три микрооперации.
Структура устройства диспетчирования/выполнения
Обмен с
пулом
команд
Загрузка в регистры
Запись в память
Retire Unit — модуль (рис. 4.14), который знает как и когда завершить (commit) временные внутренние спекулятивные вычисления, выполненные в Р6-архитектуре, преобразовать их и вернуть окончательный результат в IA-архитектуре.
Retire Unit постоянно сканирует содержимое пула инструкций и проверяет статус хранящихся в нем микроопераций. Как только находится исполненная и готовая к удалению из пула микрооперация. Retire Unit преобразует результаты ее исполнения, хранящиеся во внутреннем представлении процессора (то есть во внутренних регистрах, в контексте Р6-архитектуры), к представлению в IA-архитектуре и записывает результат исполнения в оперативную память и/или в IA-регистры. После этого микрооперация удаляется из пула инструкций.