Для достижения максимальной производительности Pentium Pro разработчики разместили кэш-память второго уровня на отдельном кристалле, который монтируется в один корпус с чипом центрального процессора. Благодаря тому, что соединения между ними не выходят за пределы корпуса (т. е. имеют минимальную протяженность) и выполнены по схеме точка - точка, инженеры компании смогли использовать в интерфейсе типа процессор - кэш нестандартные уровни сигналов и получить высокую пропускную способность тракта. Чип кэша второго уровня выпускается в двух модификациях: емкостью 256 и 512 Кбайт - и обеспечивает передачу 8 байт за такт даже при рабочей частоте процессора 200 МГц.
Для примера рассмотрим микроархитектуру процессора Pentium II. Основная отличительная черта процессоров семейства Р6 — использование алгоритмов "динамического выполнения команд" (dynamic execution), которые построены на основе трех базовых концепций: предсказании переходов (branch prediction), динамическом анализе потока данных (dynamic data flow analysis) и спекулятивном выполнении инструкций (speculative execution).
Предсказание переходов — это концепция, которая реализована не только в микроархитектуре процессоров семейства Р6, но и в микроархитектуре ряда других высокопроизводительных процессоров (например, процессоров мэйнфреймов). Суть ее заключается в следующем. На вход процессора поступает поток инструкций для их последующего исполнения. Инструкции поступают в том порядке, в котором они содержатся в коде программы, исполняемой в данный момент процессором. Как только на входе процессора появляется очередная порция инструкций для исполнения, ее содержимое анализируется с целью найти точки ветвления в исполняемом потоке инструкций и предсказать наиболее вероятные пути (ветви), по которым пойдет обработка инструкций после этих точек ветвления. Инструкции, принадлежащие ветвям с наибольшей вероятностью выполнения, тут же ставятся в очередь на исполнение.
Основная идея всех этих манипуляций заключается в том, чтобы заставить процессор выполнить инструкции, которые принадлежат ветвям с наибольшей вероятностью выполнения, "вне очереди" — то есть не дожидаться того момента, когда очередь на выполнение дойдет до этих ветвей естественным образом (согласно порядку поступления инструкций на вход процессора и, соответственно, контексту выполняемой программы), а загрузить эти ветви на выполнение раньше этого момента. Таким образом обеспечивается более полная загрузка и, соответственно, более высокая производительность процессора.
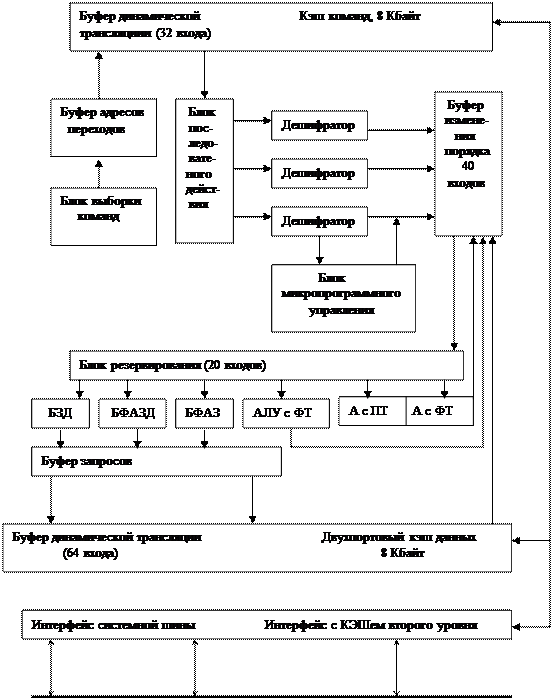
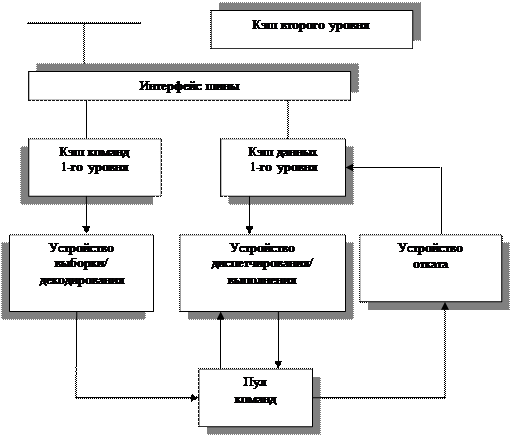
Конечно, такое преждевременное исполнение инструкций может оправдать себя только в том случае, если алгоритм нахождения наиболее вероятных ветвей работает достаточно хорошо. Действительно, если ветвь угадана неверно, то процессору придется исполнить инструкции, принадлежащие как неверно угаданной, так и альтернативной ветви, проделав тем самым двойную работу. Если бы такая ситуация наблюдалась часто, то использование этой методики было бы невыгодно. Судя по тому, что концепция "предсказания переходов" активно используется производителями процессоров, соответствующая алгоритмика развита достаточно хорошо. В\ процессоре Pentium II за предсказание переходов "отвечает" Fetch/Decode Unit (модуль загрузки/декодирования инструкций).
Динамический анализ потока данных включает в себя выполняемый в режиме реального времени анализ зависимости инструкций от исходных данных и значений регистров процессора, а также определение возможности исполнения и непосредственное исполнение инструкций в порядке, отличном от порядка их первоначальной постановки в очередь на исполнение, (out-of-ordere execution).
Dispatch/Execute Unit (модуль диспетчеризации/исполнения инструкций) процессора Pentium II может одновременно следить за ходом исполнения множества инструкций и выполнять их в таком порядке, который позволяет оптимизировать загрузку вычислительных ресурсов процессора. В это же самое время Dispatch/Execute Unit следит за целостностью данных, над которыми проводятся вычисления.
Выполнение инструкций в порядке, отличном от порядка их постановки в очередь на исполнение (out-of-order execution), позволяет избежать простоя вычислительных ресурсов даже в том случае, когда в L1-кэше нет данных, необходимых для исполнения инструкции, или между инструкциями есть зависимость данных, и зависимая инструкция не может быть исполнена. Например, в результате исполнения инструкции "А" получаются данные, которые используются при исполнении инструкции "В"; соответственно, инструкция "В" не может быть исполнена раньше, чем инструкция "А".
Спекулятивное выполнение инструкций — это способность процессора исполнить инструкции в порядке, отличном (как правило, с опережением) от порядка во входном потоке инструкций (что определяется кодом исполняемой программы), но завершить и возвратить (commit) результаты исполнения инструкций в порядке, соответствующем оригинальному входному потоку инструкций.
В процессоре Pentium II спекулятивное выполнение инструкций возможно благодаря тому, что этап "диспетчеризации и выполнения инструкций" (dispatching and executing of instructions) отделен от этапа "завершения и возвращения результатов" (commitment of results).
Используя динамический анализ потока данных, Dispatch/Execute Unit процессора исполняет все инструкции, находящиеся в пуле инструкций (instruction pool) и готовые к исполнению, после чего записывает результаты их исполнения во временные регистры.
В это время Retire Unit (модуль завершения и удаления инструкций) последовательно просматривает пул инструкций и ищет исполненные инструкции, которые не имеют зависящих от них других инструкций, следовательно, могут считаться исполненными и готовыми к извлечению из пула инструкций. Найденные инструкции извлекаются из пула инструкций, в том порядке, в каком они поступили в очередь на исполнение, результаты их исполнения возвращаются (commited), записываются в оперативную память и/или в IA-регистры (Intel Architecture registers — регистры общего назначения процессора) и регистры данных математического сопроцессора (FPU — floating-point unit)), после чего инструкции удаляются из пула инструкций.
Алгоритмика динамического выполнения команд, включающая предсказание переходов, динамический анализ потока данных и спекулятивное выполнение инструкций, снимает ограничения традиционного "линейного" подхода, при котором весь цикл исполнения состоял из двух этапов — загрузки и выполнения инструкций, а сами инструкции обрабатывались в том порядке, в котором они поступали в очередь на исполнение.


 Системная шина
Системная шина