Одной из наиболее распространённых задач анализа данных является определение часто встречающихся наборов объектов в большом множестве наборов. Впервые это задача была предложена поиска ассоциативных правил для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
Пусть имеется база данных, состоящая из покупательских транзакций. Каждая транзакция – это набор товаров, купленных покупателем за один визит. Такую транзакцию еще называют рыночной корзиной.
Пусть I = {ii,i2,...,ij,...,in} – множество (набор) товаров (объектов) общим числом n. Пусть D – множество транзакций D = {T1,T2,Tr,...,Tm}, где каждая транзакция T – это набор элементов из I. .
Решение задачи поиска ассоциативных правил, как и любой задачи, сводится к обработке исходных данных и получению результатов. Результаты, получаемые при решении данной задачи принято представлять в виде ассоциативных правил. В связи с этим в их поиске выделяю два этапа:
нахождение всех частых наборов объектов:
генерация ассоциативных правил из найденных частых наборов объектов.
Ассоциативные правила имеют следующий вид:
если (условие), то (результат),
где условие - обычно не логическое выражение (как в классификационных правилах), а набор объектов из множества I, с которым связаны (ассоциированы) объекты, включенные в результат данного правила. Например, ассоциативное правило: "если (молоко, масло), то (хлеб)" означает, что если потребитель покупает молоко и масло, то он покупает и хлеб. Основным достоинством ассоциативных правил является их лёгкое восприятие человеком и простая интерпретация языками программирования. Однако, они не всегда полезны. Выделяют три вида правил:
полезные правила - содержат действительную информацию, которая ранее была неизвестна, но имеет логическое объяснение. Такие правила могут быть использованы для принятия решений, приносящих выгоду;
тривиальные правила - содержат действительную и легко объяснимую информацию, которая уже известна. Такие правила не могут принести пользу, т.к. отражают или известные законы в исследуемой области, или результаты прошлой деятельности. Иногда такие правила могут использоваться для проверки выполнения решений, принятых на основании предыдущего анализа;
непонятные правила - содержат информацию, которая не может быть объяснена. Такие правила могут быть получены на основе аномальных значений, или сугубо скрытых знаний. Напрямую такие правила нельзя использовать для принятия решений, т.к. их необъяснимость может привести к непредсказуемым результатам. Для лучшего понимания требуется дополнительный анализ.
Ассоциативные правила строятся на основе частых наборов. Так правила, построенные на основании набора F, являются возможными комбинациями объектов, входящих в него. Таким образом, количество ассоциативных правил может быть очень большим и трудновоспринимаемым для человека. К тому же, не все из построенных правил несут в себе полезную информацию. Для оценки их полезности вводятся следующие величины: Поддержка(support) - показывает, какой процент транзакций поддерживает данное правило. Так как правило строится на основании набора, то, значит, правило X=>Y имеет поддержку, равную поддержке набора F, который составляют X и Y: . Очевидно, что правила, построенные на основании одного и того же набора, имеют одинаковую поддержку, например, поддержка Supp(если (вода, масло), то (орехи) = Supp(вода, масло, орехи) = 0,5.Достоверность(confidence) - показывает вероятность того, что из наличия в транзакции набора X следует наличие в ней набора Y. Достоверностью правила X=>Y является отношение числа транзакций, содержащих X и Y, к числу транзакций, содержащих набор Х: . Очевидно, что чем больше достоверность, тем правило лучше, причем у правил, построенных на основании одного и того же набора, достоверность будет разная.
К сожалению, достоверность не позволяет определить полезность правила. Если процент наличия в транзакциях набора Y при условии наличия в нем набора Х меньше, чем процент безусловного наличия набора Y, т.е.: . Это значит, что вероятность случайно угадать наличие в транзакции набора Y больше, чем предсказать это с помощью правила X=>Y. Для исправления такой ситуации вводится мера - улучшение. Улучшение(improvement) - показывает, полезнее ли правило случайного угадывания. Улучшение правила является отношением числа транзакций, содержащих наборы X и Y, к произведению количества транзакций, содержащих набор Х, и количества транзакций, содержащих набор Y: . Например, impr(если (вода, масло), то (орехи) = 0,5/(0,5*0,5) = 2. Если улучшение больше единицы, то это значит, что с помощью правила предсказать наличие набора Y вероятнее, чем случайное угадывание, если меньше единицы, то наоборот. В последнем случае можно использовать отрицательное правило, т.е. правило, которое предсказывает отсутствие набор Y: X => не Y. Правда, на практике такие правила мало применимы. Например, правило: "если (вода, масло), то не (молоко)" мало полезно, т.к. слабо выражает поведение покупателя. Данные оценки используются при генерации правил. Аналитик при поиске ассоциативных правил задает минимальные значения перечисленных величин. В результате те правила, которые не удовлетворяют этим условиям, отбрасываются и не включаются в решение задачи. С этой точки зрения нельзя объединять разные правила, хотя и имеющие общую смысловую нагрузку. Например, следующие правила:
X = i1,i2 = > Y = i3,
X = i1,i2 = > Y = i4,
нельзя объединить в одно:
X = i1,i2 = > Y = i3,i4,
т.к. достоверности их будут разные, следовательно, некоторые из них могут быть исключены, а некоторые - нет.

 .
.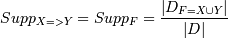 .
.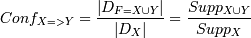 .
.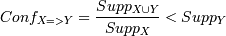 .
.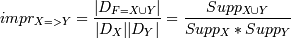 .
.