Выявление часто встречающихся наборов элементов – операция, требующая много вычислительных ресурсов и, соответственно, времени. Примитивный подход к решению данной задачи – простой перебор всех возможных наборов элементов. Это потребует O(2 | I | ) операций, где |I| – количество элементов. Apriori использует одно из свойств поддержки, гласящее: поддержка любого набора элементов не может превышать минимальной поддержки любого из его подмножеств причем обратное не верно.
Это свойство носит название анти-монотонности и служит для снижения размерности пространства поиска. Не имей мы в наличии такого свойства, нахождение многоэлементных наборов было бы практически невыполнимой задачей в связи с экспоненциальным ростом вычислений.
Свойству анти-монотонности можно дать и другую формулировку: с ростом размера набора элементов поддержка уменьшается, либо остается такой же. Из всего вышесказанного следует, что любой k-элементный набор будет часто встречающимся тогда и только тогда, когда все его (k-1)-элементные подмножества будут часто встречающимися.
Все возможные наборы элементов из I можно представить в виде решетки, начинающейся с пустого множества, затем на 1 уровне 1-элементные наборы, на 2-м – 2-элементные и т.д. На k уровне представлены k-элементные наборы, связанные со всеми своими (k-1)-элементными подмножествами.
Рассмотрим рисунок, иллюстрирующий набор элементов I – {A, B, C, D}. Предположим, что набор из элементов {A, B} имеет поддержку ниже заданного порога и, соответственно, не является часто встречающимся. Тогда, согласно свойству анти-монотонности, все его супермножества также не являются часто встречающимися и отбрасываются. Вся эта ветвь, начиная с {A, B}, выделена фоном. Использование этой эвристики позволяет существенно сократить пространство поиска.
Алгоритм Apriori определяет часто встречающиеся наборы за несколько этапов. На i-ом этапе определяются все часто встречающиеся i-элементные наборы. Каждый этап состоит из двух шагов:
формирование кандидатов (candidate generation);
подсчет поддержки кандидатов (candidate counting).
Рассмотрим i-ый этап. На шаге формирования кандидатов алгоритм создает множество кандидатов из i-элементных наборов, чья поддержка пока не вычисляется. На шаге подсчета кандидатов алгоритм сканирует множество транзакций, вычисляя поддержку наборов-кандидатов. После сканирования отбрасываются кандидаты, поддержка которых меньше определенного пользователем минимума, и сохраняются только часто встречающиеся i-элементные наборы. Во время первого этапа выбранное множество наборов-кандидатов содержит все одно-элементные частые наборы. Алгоритм вычисляет их поддержку во время шага подсчёта поддержки кандидатов. Описанный алгоритм можно записать в виде следующего псевдокода:
1. L1 = {часто встречающиеся 1-элементные наборы} 2. для (k=2; Lk-1 <> ; k++) { 3. Ck = Apriorigen(Lk-1) // генерация кандидатов 4. для всех транзакций t T { 5. Ct = subset(Ck, t) // удаление избыточных правил 6. для всех кандидатов c Ct 7. c.count ++ 8. } 9. Lk = { c Ck | c.count >= minsupport} // отбор кандидатов 10. } 11. Результат
Обозначения, используемые в алгоритме:
Lk - множество k-элементных наборов, чья поддержка не меньше заданной пользователем. Каждый член множества имеет набор упорядоченных (ij < ip если j < p) элементов F и значение поддержки набора SuppF > Suppmin:
Lk = {(F1,Supp1),(F2,Supp2),...,(Fq,Suppq)}, где Fj = {i1,i2,...,ik};
Ck - множество кандидатов k-элементных наборов потенциально частых. Каждый член множества имеет набор упорядоченных (ij < ip если j < p) элементов F и значение поддержки набора Supp.
Опишем данный алгоритм по шагам. Шаг 1. Присвоить k = 1 и выполнить отбор всех 1-элементных наборов, у которых поддержка больше минимально заданной пользователем Suppmin. Шаг 2. k = k + 1. Шаг 3. Если не удается создавать k-элементные наборы, то завершить алгоритм, иначе выполнить следующий шаг. Шаг 4. Создать множество k-элементных наборов кандидатов из частых наборов. Для этого необходимо объединить в k-элементные кандидаты (k-1)-элементные частые наборы. Каждый кандидат будет формироваться путём добавления к (k-1)-элементному частому набору - p элемента из другого (k-1)-элементного частого набора - q. Причем добавляется последний элемент набора q, который по порядку выше, чем последний элемент набора p (p.itemk − 1 < q.itemk − 1). При этом все k-2 элемента обоих наборов одинаковы (p.item1 = q.item1,p.item2 = q.item2,...,p.itemk − 2 = q.itemk − 2). Это может быть записано в виде SQL-подобного запроса:
Шаг 5. Для каждой транзакции T из множества D выбрать кандидатов Ct из множества Ck, присутствующих в транзакции T. Для каждого набора из построенного множества Ck удалить набор, если хотя бы одно из его (k-1) подмножеств не является часто встречающимся т.е. отсутствует во множестве Lk − 1. Это можно записать в виде следующего псевдокода:
Для всех наборов выполнить для всех (k-1)-поднаборов s из c выполнить если (), то удалить его из Ck
Шаг 6. Для каждого кандидата из Ck увеличить значение поддержки на единицу. Шаг 7. Выбрать только кандидатов Lk из множества Ck, у которых значение поддержки больше заданной пользователем Suppmin. Вернуться к шагу 2. Результатом работы алгоритма является объединение всех множеств Lk для всех k.


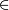 Ck | c.count >= minsupport} // отбор кандидатов 10. } 11. Результат
Ck | c.count >= minsupport} // отбор кандидатов 10. } 11. Результат 
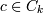 будет формироваться путём добавления к (k-1)-элементному частому набору - p элемента из другого (k-1)-элементного частого набора - q. Причем добавляется последний элемент набора q, который по порядку выше, чем последний элемент набора p (p.itemk − 1 < q.itemk − 1).
будет формироваться путём добавления к (k-1)-элементному частому набору - p элемента из другого (k-1)-элементного частого набора - q. Причем добавляется последний элемент набора q, который по порядку выше, чем последний элемент набора p (p.itemk − 1 < q.itemk − 1). 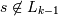 ), то удалить его из Ck
), то удалить его из Ck