В случае когда регрессионная функция линейна, множество всех возможных функций разбиения (F) можно представить в виде: , где w0,w1,...,wn - коэффициенты при независимых переменных. Задача заключается в отыскании таких коэффициентов w, чтобы разница между предсказанным и известным значением зависимой переменной была минимальна. Также задачу можно сформулировать как минимизация суммы квадратов разностей рассчитанных и известных значений зависимой переменной.
Нелинейные модели лучше классифицируют объекты, однако их построение более сложно. Задача также сводится к минимизации выражения . При этом множество F содержит нелинейные функции. В простейшем случае построение таких функций сводится к построению линейных моделей. Для этого исходное пространство объектов преобразуется к новому. В новом пространстве строится линейная функция, которая в исходном пространстве является нелинейной. Для использования построенной функции выполняется обратное преобразование в исходное пространство. Если объекты их обучающей выборки отобразить графически (откладывая по одной оси значение одной из независимых переменных, а по другой оси значение зависимой переменной), то может получиться картина, когда объекты одного класса будут сгруппированы в центре, а объекты другого рассеяны вокруг этого центра. В этом случае применение линейных методов не поможет. Выходом из этой ситуации является перевод объектов в другое пространство. Можно возвести координату каждой точки в квадрат, тогда распределение может получиться таким, что станет возможным применение линейных методов. Описанный подход имеет один существенный недостаток. Процесс преобразования достаточно сложен с точки зрения вычислений, причём вычислительная сложность растёт с увеличением числа данных. Если учесть, что преобразование выполняется два раза (прямое и обратное), то такая зависимость не является линейной. В связи с этим построение нелинейных моделей с таким подходом будет неэффективным. Альтернативой ему может служить метод Support Vector Machines (SVM), не выполняющий отдельных преобразований всех объектов, но учитывающий это в рассчётах.
Основная идея метода опорных векторов – перевод исходных векторов в пространство более высокой размерности и поиск максимальной разделяющей гиперплоскости в этом пространстве.
Каждый объект данных представлен, как вектор (точка в p-мерном пространстве (последовательность p чисел)). Рассмотрим случай бинарной классификации - когда каждая из этих точек принадлежит только одному их двух классов.
Нас интересует, можем ли мы разделить эти точки какой-либо прямой так, чтобы с одной стороны были точки одного класса, а с другой - другого. Такая прямая называется гиперплоскостью размерностью "p−1". Она описывается уравнением где - скалярное произведение векторов.
Тогда для того, чтобы разделить точки прямой, надо, чтобы выполнялось:
-> yi = 1 (принадлежит к одному классу)
-> yi = − 1 (принадлежит к другому классу)
Для улучшения классификации попробуем найти такую разделяющую гиперплоскость, чтобы она максимально отстояла от точек каждого класса (фактически, разделим не прямой, а полосой).
-> yi = 1 (принадлежит к одному классу)
-> yi = − 1 для некоторого ε > 0
Домножим эти уравнения на константу так, чтобы для граничных точек - ближайших к гиперплоскости - выполнялось:
Это можно сделать, так как для оптимальной разделяющей гиперплоскости все граничные точки лежат на одинаковом от нее расстоянии. Разделим тогда неравенства на ε и выберем ε = 1. Тогда:
, если yi = 1 , если yi = − 1
(Рисунок полосы)
Ширина разделительной полосы тогда равна . Нам нужно, чтобы ширина полосы была как можно большей ( )(чтобы классификация была точнее) и при этом (так как ). Это задача квадратичной оптимизации.
Это в том случае, если классы линейно разделимы (разделимы гиперплоскостью). В том случае, если есть точки, которые лежат по "неправильные" стороны гиперплоскости, то мы считаем эти точки ошибками. Но их надо учитывать:
, ξi - ошибка xi, если ξi = 0 - ошибки нет, если 0 < ξi < 1, то объект внутри разделительной полосы, но классифицируется правильно, если ξi > 1 - это ошибка.
Тогда нам надо минимизировать сумму , C - параметр, позволяющий регулировать, что нам важнее - отсутствие ошибок или выразительность результата (ширина разделительной полосы), мы его выбираем сами .
Как известно, чтобы найти минимум, надо исследовать производную. Однако у нас заданы еще и границы, в которых этот минимум искать! Это решается при помощи метода Лагранжа: Лагранж доказал (для уравнений в общем и неравенств в частности), что в той точке, где у функции F(x) условный (ограниченный условиями) минимум, в той же точке у функции
F(x) −
∑
λiGi
i
(для фиксированного набора λi,Gi - условия ограничений) тоже минимум, но уже безусловный, по всем x. При этом либо λi = 0 и соответственно ограничение Gi не активно, либо , тогда неравенство Gi превращается в уравнение.
Тогда алгоритм поиска минимума следующий:
Взять все производные
F(x) −
∑
λiGi
i
по х и приравнять их к нулю.
С помощью полученных уравнений выразить x через λ1..λn.
Подставить выраженные x в неравенства ограничений, сделав их уравнениями. Получим систему из n уравнений с n неизвестными λ. Она решается.
Тогда можно нашу задачу ( минимизировать при условиях , ) сформулировать при помощи метода лагранжа следующим образом:
Необходимо найти минимум по w, b и ξi и максимум по λi функции при условиях .
Возьмем производную лагранжианы по w, приравняем ее к нулю и из полученного выражения выразим w:
w =
∑
λiyixi
i
Следовательно, вектор w - линейная комбинация учебных векторов xi, причем только таких, для которых . Именно эти вектора называются опорными и дали название метода.
Взяв производную по b, получим
∑
λiyi = 0
i
.
Подставим w в лагранжиану и получим новую (двойственную) задачу:
при
∑
λiyi = 0
i
,
Это финальная задача, которую нам надо решить. Обратите внимание, что в итоге все свелось к скалярному произведению двух векторов - xi и xj. Это произведение называется Ядром.
Эта задача решается методом последовательных оптимизации (благодаря тому, что коэффициенты при λiλj положительны -> функция выпуклая -> локальный максимум яявляется глобальным):
Задаем набор λi, удовлетворяющий условиям;
Выбираем из набора первую пару улучшаемых λiλj;
При фиксированных остальных λ и имеющихся ограничениях находим пару таких λi,λj, при которых (мини-оптимизация);
Переходим на шаг 2 до тех пор, пока прирост функции будет меньше некого достаточно малого ε. Если функция расти перестала, мы нашли нужные нам λ.
Результирующий алгоритм похож на алгоритм линейной классификации, с той лишь разницей, что каждое скалярное произведение в приведенных выше формулах заменяется нелинейной функцией ядра (скалярным произведением в пространстве с большей размерностью). В этом пространстве уже может существовать оптимальная разделяющая гиперплоскость. Так как размерность получаемого пространства может быть больше размерности исходного, то преобразование, сопоставляющее скалярные произведения, будет нелинейным, а значит функция, соответсвующая в исходном пространстве оптимальной разделяющей гиперплоскости будет также нелинейной.
Стоит отметить, что если исходное пространство имеет достаточно высокую размерность, то можно надеяться, что в нём выборка окажется линейно разделимой.

 ,
,
 где
где 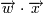 - скалярное произведение векторов.
- скалярное произведение векторов.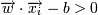 -> yi = 1 (принадлежит к одному классу)
-> yi = 1 (принадлежит к одному классу)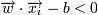 -> yi = − 1 (принадлежит к другому классу)
-> yi = − 1 (принадлежит к другому классу)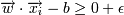 -> yi = 1 (принадлежит к одному классу)
-> yi = 1 (принадлежит к одному классу)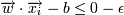 -> yi = − 1 для некоторого ε > 0
-> yi = − 1 для некоторого ε > 0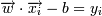
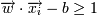 , если yi = 1
, если yi = 1  , если yi = − 1
, если yi = − 1 . Нам нужно, чтобы ширина полосы была как можно большей (
. Нам нужно, чтобы ширина полосы была как можно большей ( 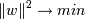 )(чтобы классификация была точнее) и при этом
)(чтобы классификация была точнее) и при этом 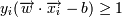 (так как
(так как  ). Это задача квадратичной оптимизации.
). Это задача квадратичной оптимизации.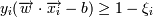 , ξi - ошибка xi, если ξi = 0 - ошибки нет, если 0 < ξi < 1, то объект внутри разделительной полосы, но классифицируется правильно, если ξi > 1 - это ошибка.
, ξi - ошибка xi, если ξi = 0 - ошибки нет, если 0 < ξi < 1, то объект внутри разделительной полосы, но классифицируется правильно, если ξi > 1 - это ошибка.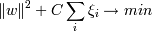 , C - параметр, позволяющий регулировать, что нам важнее - отсутствие ошибок или выразительность результата (ширина разделительной полосы), мы его выбираем сами .
, C - параметр, позволяющий регулировать, что нам важнее - отсутствие ошибок или выразительность результата (ширина разделительной полосы), мы его выбираем сами .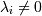 , тогда неравенство Gi превращается в уравнение.
, тогда неравенство Gi превращается в уравнение.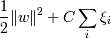 при условиях
при условиях 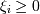 ,
, 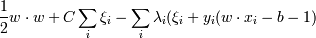 при условиях
при условиях 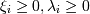 .
.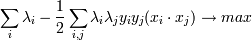 при
при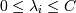
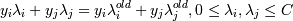 находим пару таких λi,λj, при которых
находим пару таких λi,λj, при которых 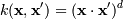
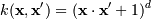
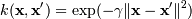 , для γ > 0
, для γ > 0 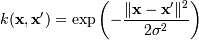
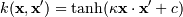 , для почти всех κ > 0 и c < 0
, для почти всех κ > 0 и c < 0