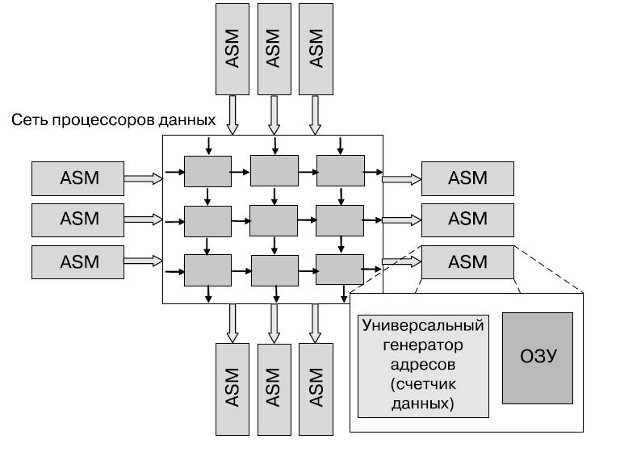
Методология GAG непоследовательна, а потому обладает такими достоинствами, как возможность работы с двумерными адресами, что дает неоспоримые преимущества при работе с видеоданными и при выполнении параллельных вычислений. Счетчик данных (data counter) — альтернатива счетчику команд в машине фон Неймана; его содержимым управляет Flowware. Для новой методологии придумано и новое название — twin.paradigm; оно отражает симбиоз вычислительных ядер двух классов как обычных центральных процессоров, построенных по фон-неймановской схеме, так и процессоров данных, реализующих антимашины.
Рис.25.1. Антимашина
Главные отличия антимашины от машины фон Неймана в том, что антимашина по природе своей параллельна и к тому же нестатична — ее нужно программировать индивидуально, а не просто загружать различные программы в универсальную машину. Существуют наработки, которые хотя бы могут дать представление о том, как и из чего можно собрать антимашину. Реализовать ее можно средствами реконфигурируемого компьютинга.
Теоретически возможно существование трех подходов к созданию реконфигурируемых процессоров.
Специализированные процессоры (Application-Specific Standard Processor). Процессоры, имеющие набор команд, адаптированный к определенным приложениям.
Конфигурируемые процессоры (Configurable Processor). Своего рода "заготовки" для создания специализированных процессоров, содержат в себе необходимый набор компонентов, адаптируемый к требованиям приложений. В таком случае проектирование специализированного процессора оказывается проще, чем с чистого листа.
Динамические реконфигурируемые процессоры (Dynamically Reconfigurable Processor). Процессоры, содержащие стандартное ядро и расширяющее его возможности устройство, которое может быть запрограммировано в процессе исполнения; обычно это бывает программируемая логическая матрица (Field Programmable Gate-Array, FPGA).
В качестве еще одного пути развития вычислительных средств, сочетающего в себе и переход к параллельным системам и процессорам, и управление данными, можно назвать постепенный переход к системам на базе или с применением искусственного интеллекта. Действительно, если рассмотреть традиционное сравнение характеристик систем искусственного интеллекта с традиционными программными системами, видно, что в них подразумевается и адаптивность структуры, и высокий уровень параллелизма — таким образом, есть потенциальная возможность наиболее полно использовать возможности многоядерных архитектур.
Также следует отметить, что интерес к системам на базе искусственного интеллекта (ИИ) возрос — это связано отчасти и с успехами в области полупроводниковой техники, позволяющими получать достаточно компактные устройства, которые имеют достаточно ресурсов для поддержания приложений ИИ. Одним из направлений ИИ, близкого по структуре к параллельным системам, являются искусственные нейронные сети, которые обладают рядом свойств, делающих их незаменимыми во многих приложениях. Применительно к задачам — это способность к обобщению, выявлению скрытых закономерностей, способность настраиваться на задачу, отсутствие необходимости выстраивать аналитические модели. Применительно к организации вычислений — нейросети позволяют наиболее полно использовать аппаратные ресурсы системы (в частности, для параллельной системы возможна наиболее полная загрузка вычислительных ядер).
25.2. Сферы применения многоядерных процессоров и многопроцессорных вычислительных систем
Широкое внедрение многоядерных технологий позволяет по-новому взглянуть на вычислительные возможности компьютеров и порождает всплеск творческой активности по созданию инновационных решений. Разработчики клиентских приложений могут исследовать новые способы применения многозадачности, которые в прошлом не имели практического значения или были сложны в реализации. Например, важные системные задачи теперь могут выполняться постоянно — непрерывный и упреждающий поиск вирусов, автоматическое резервное копирование, гарантирующее сохранение всех рабочих файлов, интеллектуальная система мониторинга потоков работ, способная прогнозировать потребности пользователя и выдавать информацию в реальном времени по запросу. С ростом распространения многоядерных клиентских ПК список полезных приложений, которые могут непрерывно выполняться в фоновом режиме, будет постоянно расти.
Можно выделить несколько классов приложений, которые требуют значительных вычислительных ресурсов и могут быть соотнесены с термином "HPC-приложения".
Приложения, обрабатывающие большие файлы данных:
2D/3D САПР;
системы моделирования, средства работы с анимацией;
средства обработки цифровых изображений;
электронные издательские системы;
средства видеомонтажа/рендеринга;
компьютерные игры (на клиентских компьютерах и серверах);
средства поиска/индексирования;
системы потокового мультимедиа;
средства защиты и криптографии.
Приложения, нуждающиеся в увеличенном адресном пространстве ОЗУ:
финансовое моделирование;
научные и технические расчеты;
исполняющиеся на сервере приложения, обслуживающие множество пользователей настольных машин, или тонких клиентов.
Приложения, работающие с большими массами транзакций/пользователей:
СУБД;
веб-серверы;
серверы электронной почты.
Было показано, что многоядерные процессоры позволяют существенно снизить потребление энергии при сохранении производительности. Это, в свою очередь, открывает новые области применения:
компактные высокопроизводительные устройства с низким тепловым излучением;
серверные помещения, позволяющие снизить расход электроэнергии и требования к кондиционированию воздуха;
решения для мобильных ПК с увеличенным временем автономной работы батарей;
решения для дома и офиса, реализация которых раньше была физически невозможна при использовании процессоров предыдущих поколений.
Обеспечение энергосберегающей производительности, основа которой — переход на многоядерные вычисления, принесет выгоды практически для всех платформ.
По мере появления дополнительных вычислительных возможностей перед разработчиками откроются перспективы, лежащие далеко за пределами простого повышения быстродействия приложений. Голосовое управление, IP-телефония и видеотелефония, новые электронные секретари, доступ к информации в реальном времени, расширенные возможности управления через IP, многоуровневые функции поиска и извлечения данных, — вот лишь несколько примеров преимуществ, которые могут получить пользователи мощных вычислительных систем с быстрым реагированием.
Многопроцессорные вычислительные системы (МВС)могут существовать в различных конфигурациях. Наиболее распространенными типами МВС являются:
системы высокой надежности;
системы для высокопроизводительных вычислений;
многопоточные системы.
Отметим, что границы между этими типами МВС до некоторой степени размыты, и часто система может иметь такие свойства или функции, которые выходят за рамки перечисленных типов. Более того, при конфигурировании большой системы, используемой как система общего назначения, приходится выделять блоки, выполняющие все перечисленные функции.
МВС являются идеальной схемой для повышения надежности информационно-вычислительной системы. Благодаря единому представлению, отдельные узлы или компоненты МВС могут незаметно для пользователя заменять неисправные элементы, обеспечивая непрерывность и безотказную работу даже таких сложных приложений как базы данных.
Катастрофоустойчивые решения создаются на основе разнесения узлов многопроцессорной системы на сотни километров и обеспечения механизмов глобальной синхронизации данных между такими узлами.
МВС для высокопроизводительных вычислений предназначены для параллельных расчетов. Имеется много примеров научных расчетов, выполненных на основе параллельной работы нескольких недорогих процессоров, обеспечивающих одновременное проведение большого числа операций.
МВС для высокопроизводительных вычислений обычно собраны из многих компьютеров. Разработка таких систем – процесс сложный, требующий постоянного согласования таких вопросов как инсталляция, эксплуатация и одновременное управление большим числом компьютеров, технических требований параллельного и высокопроизводительного доступа к одному и тому же системному файлу (или файлам), межпроцессорной связи между узлами и координации работы в параллельном режиме. Эти проблемы проще всего решаются при обеспечении единого образа операционной системы для всего кластера. Однако реализовать подобную схему удается далеко не всегда, и обычно она применяется лишь для небольших систем.
Многопоточные системы используются для обеспечения единого интерфейса к ряду ресурсов, которые могут со временем произвольно наращиваться (или сокращаться). Типичным примером может служить группа web-серверов.
Главной отличительной особенностью многопроцессорной вычислительной системы является ее производительность, т.е. количество операций, производимых системой за единицу времени. Различают пиковую и реальную производительность. Под пиковой понимают величину, равную произведению пиковой производительности одного процессора на число таких процессоров в данной машине. При этом предполагается, что все устройства компьютера работают в максимально производительном режиме. Пиковая производительность компьютера вычисляется однозначно, и эта характеристика является базовой, по которой производят сравнение высокопроизводительных вычислительных систем. Чем больше пиковая производительность, тем (теоретически) быстрее пользователь сможет решить свою задачу. Пиковая производительность есть величина теоретическая и, вообще говоря, недостижимая при запуске конкретного приложения. Реальная же производительность, достигаемая на данном приложении, зависит от взаимодействия программной модели, в которой реализовано приложение, с архитектурными особенностями машины, на которой приложение запускается.
Существует два способа оценки пиковой производительности компьютера. Один из них опирается на число команд, выполняемых компьютером за единицу времени. Единицей измерения, как правило, является MIPS (Million Instructions Per Second). Производительность, выраженная в MIPS, говорит о скорости выполнения компьютером своих же инструкций. Но, во-первых, заранее не ясно, в какое количество инструкций отобразится конкретная программа, а во-вторых, каждая программа обладает своей спецификой, и число команд от программы к программе может меняться очень сильно. В связи с этим данная характеристика дает лишь самое общее представление о производительности компьютера.
Другой способ измерения производительности заключается в определении числа вещественных операций, выполняемых компьютером за единицу времени. Единицей измерения является Flops (Floating point operations per second) – число операций с плавающей точкой, производимых компьютером за одну секунду. Такой способ является более приемлемым для пользователя, поскольку ему известна вычислительная сложность программы, и, пользуясь этой характеристикой, пользователь может получить нижнюю оценку времени ее выполнения.
Однако пиковая производительность получается только в идеальных условиях, т.е. при отсутствии конфликтов при обращении к памяти при равномерной загрузке всех устройств. В реальных условиях на выполнение конкретной программы влияют такие аппаратно-программные особенности данного компьютера как: особенности структуры процессора, системы команд, состав функциональных устройств, реализация ввода/вывода, эффективность работы компиляторов.
Одним из определяющих факторов является время взаимодействия с памятью, которое определяется ее строением, объемом и архитектурой подсистем доступа в память. В большинстве современных компьютеров в качестве организации наиболее эффективного доступа к памяти используется так называемая многоуровневая иерархическая память. В качестве уровней используются регистры и регистровая память, основная оперативная память, кэш-память, виртуальные и жесткие диски, ленточные роботы. При этом выдерживается следующий принцип формирования иерархии: при повышении уровня памяти скорость обработки данных должна увеличиваться, а объем уровня памяти – уменьшаться. Эффективность использования такого рода иерархии достигается за счет хранения часто используемых данных в памяти верхнего уровня, время доступа к которой минимально. А поскольку такая память обходится достаточно дорого, ее объем не может быть большим. Иерархия памяти относится к тем особенностям архитектуры компьютеров, которые имеют огромное значение для повышения их производительности.
Для того чтобы оценить эффективность работы вычислительной системы на реальных задачах, был разработан фиксированный набор тестов. Наиболее известным из них является LINPACK – программа, предназначенная для решения системы линейных алгебраических уравнений с плотной матрицей с выбором главного элемента по строке. LINPACK используется для формирования списка Top500 – пятисот самых мощных компьютеров мира. Однако LINPACK имеет существенный недостаток: программа распараллеливается, поэтому невозможно оценить эффективность работы коммуникационного компонента суперкомпьютера.
В настоящее время большое распространение получили тестовые программы, взятые из разных предметных областей и представляющие собой либо модельные, либо реальные промышленные приложения. Такие тесты позволяют оценить производительность компьютера действительно на реальных задачах и получить наиболее полное представление об эффективности работы компьютера с конкретным приложением.
Наиболее распространенными тестами, построенными по этому принципу, являются: набор из 24 Ливерморских циклов (The Livermore Fortran Kernels, LFK) и пакет NAS Parallel Benchmarks (NPB), в состав которого входят две группы тестов, отражающих различные стороны реальных программ вычислительной гидродинамики. NAS тесты являются альтернативой LINPACK, поскольку они относительно просты и в то же время содержат значительно больше вычислений, чем, например, LINPACK или LFK.
25.3. Классификация архитектур вычислительных систем по степени параллелизма обработки данных
Чтобы дать более полное представление о многопроцессорных вычислительных системах, помимо высокой производительности необходимо назвать и другие отличительные особенности. Прежде всего, это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.).
Понятие архитектурывысокопроизводительной системы является достаточно широким, поскольку под архитектурой можно понимать и способ параллельной обработки данных, используемый в системе, и организацию памяти, и топологию связи между процессорами, и способ исполнения системой арифметических операций. Попытки систематизировать все множество архитектур впервые были предприняты в конце 60-х годов и продолжаются по сей день.
В 1966 г. М.Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В его основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
SISD = Single Instruction Single Data
MISD = Multiple Instruction Single Data
SIMD = Single Instruction Multiple Data
MIMD = Multiple Instruction Multiple Data
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняет несвязанные потоки инструкций, что делает такие системы комплексами SISD-систем, действующих на разных пространствах данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. В случае векторных систем векторный поток данных следует рассматривать как поток из одиночных неделимых векторов. Примерами компьютеров с архитектурой SISD могут служить большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems.
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, создано не было. В качестве аналога работы такой системы, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Поскольку база данных одна, а команд много, мы имеем дело с множественным потоком команд и одиночным потоком данных.
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров, от 1024 до 16384, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Примерами SIMD-машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. Когда данные обрабатываются посредством векторных модулей, результаты могут быть выданы на один, два или три такта генератора тактовой частоты (такт генератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа являются, например, компьютеры Hitachi S3600.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от упомянутых выше многопроцессорных SISD-машин, команды и данные связаны, потому что они представляют различные части одной и той же задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач с целью сокращения времени выполнения основной задачи. Большое разнообразие попадающих в данный класс систем делает классификацию Флинна не полностью адекватной. Действительно, и четырехпроцессорный SX-5 компании NEC, и тысячепроцессорный Cray T3E попадают в этот класс. Это заставляет использовать другой подход к классификации, иначе описывающий классы компьютерных систем. Основная идея такого подхода может состоять, например, в следующем. Будем считать, что множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD-компьютерах, которые обычно называют конвейерными или векторными, вторая – в параллельных компьютерах. В основе векторных компьютеров лежит концепция конвейеризации, т.е. явного сегментирования арифметического устройства на отдельные части, каждая из которых выполняет свою подзадачу для пары операндов. В основе параллельного компьютера лежит идея использования для решения одной задачи нескольких процессоров, работающих сообща, причем процессоры могут быть как скалярными, так и векторными.
Классификация архитектур вычислительных систем нужна для того, чтобы понять особенности работы той или иной архитектуры, но она не является достаточно детальной, чтобы на нее можно было опираться при создании МВС, поэтому следует вводить более детальную классификацию, которая связана с различными архитектурами ЭВМ и с используемым оборудованием.
25.4. Архитектуры SMP, MPP и NUMA
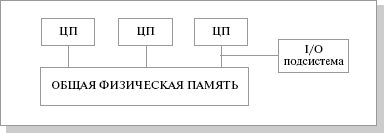
SMP (symmetric multiprocessing) – симметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP является наличие общей физической памяти, разделяемой всеми процессорами
( рис.25.2).
Рис.25.2. Схематический вид SMP архитектуры
Память служит, в частности, для передачи сообщений между процессорами, при этом все вычислительные устройства при обращении к ней имеют равные права и одну и ту же адресацию для всех ячеек памяти. Поэтому SMP-архитектура называется симметричной. Последнее обстоятельство позволяет очень эффективно обмениваться данными с другими вычислительными устройствами. SMP-система строится на основе высокоскоростной системной шины (SGI PowerPath, Sun Gigaplane, DEC TurboLaser), к слотам которой подключаются функциональные блоки типов: процессоры (ЦП), подсистема ввода/вывода (I/O) и т. п. Для подсоединения к модулям I/O используются уже более медленные шины (PCI, VME64). Наиболее известными SMP-системами являются SMP-cерверы и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.) Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы по процессорам, но иногда возможна и явная привязка.
Основные преимущества SMP-систем:
простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают независимо друг от друга. Однако можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти. Для SMP-систем существуют довольно эффективные средства автоматического распараллеливания;
простота эксплуатации. Как правило, SMP-системы используют систему кондиционирования, основанную на воздушном охлаждении, что облегчает их техническое обслуживание;
относительно невысокая цена.
Недостатки:
системы с общей памятью плохо масштабируются.
Этот существенный недостаток SMP-систем не позволяет считать их по-настоящему перспективными. Причиной плохой масштабируемости является то, что в данный момент шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти. Вычислительные элементы начинают друг другу мешать. Когда произойдет такой конфликт, зависит от скорости связи и от количества вычислительных элементов. В настоящее время конфликты могут происходить при наличии 8-24 процессоров. Кроме того, системная шина имеет ограниченную (хоть и высокую) пропускную способность (ПС) и ограниченное число слотов. Все это очевидно препятствует увеличению производительности при увеличении числа процессоров и числа подключаемых пользователей. В реальных системах можно задействовать не более 32 процессоров. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры. При работе с SMP-системами используют так называемую парадигму программирования с разделяемой памятью (shared memory paradigm).
MPP (massive parallel processing) – массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), коммуникационные процессоры (рутеры) или сетевые адаптеры, иногда – жесткие диски и/или другие устройства ввода/вывода. По сути, такие модули представляют собой полнофункциональные компьютеры (рисю25.3). Доступ к банку ОП из данного модуля имеют только процессоры (ЦП) из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами. Используются два варианта работы операционной системы (ОС) на машинах MPP-архитектуры. В одном полноценная операционная система (ОС) работает только на управляющей машине (front-end), на каждом отдельном модуле функционирует сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения. Во втором варианте на каждом модуле работает полноценная UNIX-подобная ОС, устанавливаемая отдельно.
Рис.25.3. Схематический вид архитектуры с раздельной памятью
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодня устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (ASCI Red, ASCI Blue Pacific).
Недостатки:
отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами. Требуется специальная техника программирования для реализации обмена сообщениями между процессорами;
каждый процессор может использовать только ограниченный объем локального банка памяти;
вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально использовать системные ресурсы. Именно этим определяется высокая цена программного обеспечения для массивно-параллельных систем с раздельной памятью.
Системами с раздельной памятью являются суперкомпьютеры МВС-1000, IBM RS/6000 SP, SGI/CRAY T3E, системы ASCI, Hitachi SR8000, системы Parsytec.
Машины последней серии CRAY T3E от SGI, основанные на базе процессоров Dec Alpha 21164 с пиковой производительностью 1200 Мфлопс/с (CRAY T3E-1200), способны масштабироваться до 2048 процессоров.
При работе с MPP-системами используют так называемую Massive Passing Programming Paradigm – парадигму программирования с передачей данных (MPI, PVM, BSPlib).
NUMA (nonuniform memory access)- гибридная архитектура.
Главная особенность – неоднородный доступ к памяти.
Гибридная архитектура совмещает достоинства систем с общей памятью и относительную дешевизну систем с раздельной памятью. Суть этой архитектуры – в особой организации памяти, а именно: память физически распределена по различным частям системы, но логически она является общей, так что пользователь видит единое адресное пространство. Система построена из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной. По существу, архитектура NUMA является MPP (массивно-параллельной) архитектурой, где в качестве отдельных вычислительных элементов берутся SMP (cимметричная многопроцессорная архитектура) узлы. Доступ к памяти и обмен данными внутри одного SMP-узла осуществляется через локальную память узла и происходит очень быстро, а к процессорам другого SMP-узла тоже есть доступ, но более медленный и через более сложную систему адресации.
Структурная схема компьютера с гибридной сетью: четыре процессора связываются между собой при помощи кроссбара в рамках одного SMP-узла. Узлы связаны сетью типа "бабочка" (Butterfly) (рис.25.4).