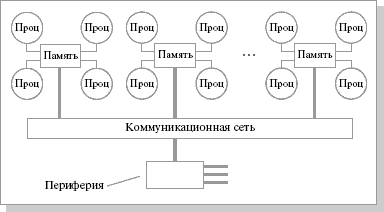
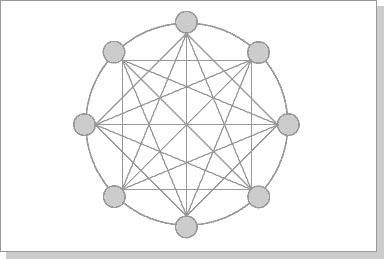
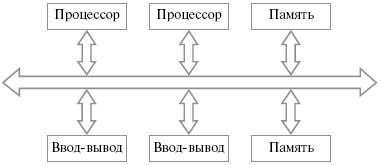
Рис.25.4. Структурная схема компьютера с гибридной сетью
Впервые идею гибридной архитектуры предложил Стив Воллох, он воплотил ее в системах серии Exemplar. Вариант Воллоха – система, состоящая из восьми SMP-узлов. Фирма HP купила идею и реализовала на суперкомпьютерах серии SPP. Идею подхватил Сеймур Крей (Seymour R.Cray) и добавил новый элемент – когерентный кэш, создав так называемую архитектуру cc-NUMA (Cache Coherent Non-Uniform Memory Access), которая расшифровывается как "неоднородный доступ к памяти с обеспечением когерентности кэшей". Он ее реализовал на системах типа Origin.
25.5. Организация когерентности многоуровневой иерархической памяти
Понятие когерентности кэшей описывает тот факт, что все центральные процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Действительно, поскольку кэш-память принадлежит отдельному компьютеру, а не всей многопроцессорной системе в целом, данные, попадающие в кэш одного компьютера, могут быть недоступны другому. Чтобы этого избежать, следует провести синхронизацию информации, хранящейся в кэш-памяти процессоров.
Для обеспечения когерентности кэшей существует несколько возможностей:
использовать механизм отслеживания шинных запросов (snoopy bus protocol), в котором кэши отслеживают переменные, передаваемые к любому из центральных процессоров и при необходимости модифицируют собственные копии таких переменных;
выделять специальную часть памяти, отвечающую за отслеживание достоверности всех используемых копий переменных.
Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях, SGI Origin3000, Sun HPC 15000, IBM/Sequent NUMA-Q 2000. На сегодня максимальное число процессоров в cc-NUMA-системах может превышать 1000 (серия Origin3000). Обычно вся система работает под управлением единой ОС, как в SMP. Возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС. При работе с NUMA-системами, так же, как с SMP, используют так называемую парадигму программирования с общей памятью (shared memory paradigm).
25.6. PVP архитектура
PVP (Parallel Vector Process) – параллельная архитектура с векторными процессорами.
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гбайт/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP-архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дорого стоят, эти машины не могут быть общедоступными.
Наиболее популярны три машины PVP-архитектуры:
CRAY X1, SMP-архитектура. Пиковая производительность системы в стандартной конфигурации может составлять десятки терафлопс.
NEC SX-6, NUMA-архитектура. Пиковая производительность системы может достигать 8 Тфлопс, производительность одного процессора составляет 9,6 Гфлопс. Система масштабируется с единым образом операционной системы до 512 процессоров.
Fujitsu-VPP5000 (vector parallel processing), MPP-архитектура. Производительность одного процессора составляет 9.6 Гфлопс, пиковая производительность системы может достигать 1249 Гфлопс, максимальная емкость памяти – 8 Тбайт. Система масштабируется до 512.
Парадигма программирования на PVP-системах предусматривает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
На практике рекомендуется выполнять следующие процедуры:
производить векторизацию вручную, чтобы перевести задачу в матричную форму. При этом, в соответствии с длиной вектора, размеры матрицы должны быть кратны 128 или 256;
работать с векторами в виртуальном пространстве, разлагая искомую функцию в ряд и оставляя число членов ряда, кратное 128 или 256.
За счет большой физической памяти (доли терабайта) даже плохо векторизуемые задачи на PVP-системах решаются быстрее, чем на машинах со скалярными процессорами.
25.7. Контрольные вопросы
1. Смена приоритетов при разработке процессоров. Преодоление трёх, так называемых "стен".
2. Обобщённая структура Антимашины. Главные отличия антимашины от машины фон Неймана
3. Известные подходы к созданию реконфигурируемых процессоров.
4. Наиболее распространенные типы многопроцессорных вычислительных систем.
5. Способы оценки пиковой производительности компьютера.
6. Классификация архитектур вычислительных систем по степени параллелизма обработки данных.
7. Архитектуры SMP, MPP и NUMA.
8. PVP архитектура.
Лекция 26. Кластерная архитектура
Кластер представляет собой два или более компьютеров (часто называемых узлами), объединяемые при помощи сетевых технологий на базе шинной архитектуры или коммутатора и предстающие перед пользователями в качестве единого информационно-вычислительного ресурса. В качестве узлов кластера могут быть выбраны серверы, рабочие станции и даже обычные персональные компьютеры. Узел характеризуется тем, что на нем работает единственная копия операционной системы. Преимущество кластеризации для повышения работоспособности становится очевидным в случае сбоя какого-либо узла: при этом другой узел кластера может взять на себя нагрузку неисправного узла, и пользователи не заметят прерывания в доступе. Возможности масштабируемости кластеров позволяют многократно увеличивать производительность приложений для большего числа пользователей технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. Такие суперкомпьютерные системы являются самыми дешевыми, поскольку собираются на базе стандартных комплектующих элементов ("off the shelf"), процессоров, коммутаторов, дисков и внешних устройств.
Кластеризация может осуществляться на разных уровнях компьютерной системы, включая аппаратное обеспечение, операционные системы, программы-утилиты, системы управления и приложения. Чем больше уровней системы объединены кластерной технологией, тем выше надежность, масштабируемость и управляемость кластера.
Условное деление на классы предложено Язеком Радаевским и Дугласом Эдлайном:
Класс I. Класс машин строится целиком из стандартных деталей, которые продают многие поставщики компьютерных компонентов (низкие цены, простое обслуживание, аппаратные компоненты доступны из различных источников).
Класс II. Система имеет эксклюзивные или не слишком широко распространенные детали. Таким образом можно достичь очень хорошей производительности, но при более высокой стоимости.
Как уже отмечалось, кластеры могут существовать в различных конфигурациях. Наиболее распространенными типами кластеров являются:
системы высокой надежности;
системы для высокопроизводительных вычислений;
многопоточные системы.
Отметим, что границы между этими типами кластеров до некоторой степени размыты, и кластер может иметь такие свойства или функции, которые выходят за рамки перечисленных типов. Более того, при конфигурировании большого кластера, используемого как система общего назначения, приходится выделять блоки, выполняющие все перечисленные функции.
Кластеры для высокопроизводительных вычислений предназначены для параллельных расчетов. Эти кластеры обычно собраны из большого числа компьютеров. Разработка таких кластеров является сложным процессом, требующим на каждом шаге согласования таких вопросов как инсталляция, эксплуатация и одновременное управление большим числом компьютеров, технические требования параллельного и высокопроизводительного доступа к одному и тому же системному файлу (или файлам) и межпроцессорная связь между узлами, и координация работы в параллельном режиме. Эти проблемы проще всего решаются при обеспечении единого образа операционной системы для всего кластера. Однако реализовать подобную схему удается далеко не всегда и обычно она применяется лишь для не слишком больших систем.
Многопоточные системы используются для обеспечения единого интерфейса к ряду ресурсов, которые могут со временем произвольно наращиваться (или сокращаться). Типичным примером может служить группа web-серверов.
В 1994 году Томас Стерлинг (Sterling) и Дон Беккер (Becker) создали 16-узловой кластер из процессоров Intel DX4, соединенных сетью 10 Мбит/с Ethernet с дублированием каналов. Они назвали его "Beowulf" по названию старинной эпической поэмы. Кластер возник в центре NASA Goddard Space Flight Center для поддержки необходимыми вычислительными ресурсами проекта Earth and Space Sciences. Проектно-конструкторские работы быстро превратились в то, что известно сейчас как проект Beowulf. Проект стал основой общего подхода к построению параллельных кластерных компьютеров, он описывает многопроцессорную архитектуру, которая может с успехом использоваться для параллельных вычислений. Beowulf-кластер, как правило, является системой, состоящей из одного серверного узла (который обычно называется головным), а также одного или нескольких подчиненных (вычислительных) узлов, соединенных посредством стандартной компьютерной сети. Система строится с использованием стандартных аппаратных компонентов, таких как ПК, запускаемые под Linux, стандартные сетевые адаптеры (например, Ethernet) и коммутаторы. Нет особого программного пакета, называемого "Beowulf". Вместо этого имеется несколько кусков программного обеспечения, которые многие пользователи нашли пригодными для построения кластеров Beowulf. Beowulf использует такие программные продукты как операционная система Linux, системы передачи сообщений PVM, MPI, системы управления очередями заданий и другие стандартные продукты. Серверный узел контролирует весь кластер и обслуживает файлы, направляемые к клиентским узлам.
26.1. Архитектура связи в кластерных системах
Архитектура кластерной системы (способ соединения процессоров друг с другом) в большей степени определяет ее производительность, чем тип используемых в ней процессоров. Критическим параметром, влияющим на величину производительности такой системы, является расстояние между процессорами. Так, соединив вместе 10 персональных компьютеров, мы получим систему для проведения высокопроизводительных вычислений. Проблема, однако, будет состоять в поиске наиболее эффективного способа соединения стандартных средств друг с другом, поскольку при увеличении производительности каждого процессора в 10 раз производительность системы в целом в 10 раз не увеличится.
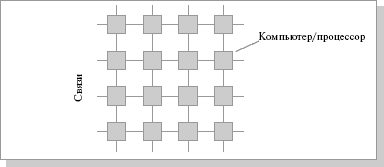
Рассмотрим для примера задачу построения симметричной 16-процессорной системы, в которой все процессоры были бы равноправны. Наиболее естественным представляется соединение в виде плоской решетки ( рис.26.1), где внешние концы используются для подсоединения внешних устройств.
Рис.26.1. Схема соединения процессоров в виде плоской решетки
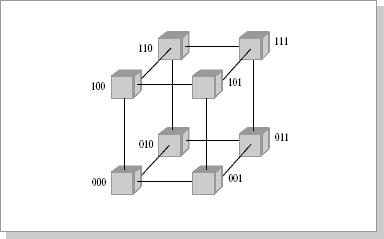
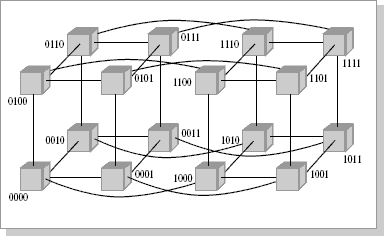
При таком типе соединения максимальное расстояние между процессорами окажется равным 6 (количество связей между процессорами, отделяющих самый ближний процессор от самого дальнего). Теория же показывает, что если в системе максимальное расстояние между процессорами больше 4, то такая система не может работать эффективно. Поэтому при соединении 16 процессоров друг с другом плоская схема является нецелесообразной. Для получения более компактной конфигурации необходимо решить задачу о нахождении фигуры, имеющей максимальный объем при минимальной площади поверхности. В трехмерном пространстве таким свойством обладает шар. Но поскольку нам необходимо построить узловую систему, вместо шара приходится использовать куб (если число процессоров равно 8, рис.26.2) или гиперкуб, если число процессоров больше 8. Размерность гиперкуба будет определяться в зависимости от числа процессоров, которые необходимо соединить. Так, для соединения 16 процессоров потребуется четырехмерный гиперкуб. Для его построения следует взять обычный трехмерный куб, сдвинуть в нужном направлении и, соединив вершины, получить гиперкуб размерностью 4 (рис.26.3).
Архитектура гиперкуба является второй по эффективности, но самой наглядной. Используются и другие топологии сетей связи: трехмерный тор, "кольцо" (рис.26.4), "звезда" и другие.
Рис.26.2. Топология связи, 3-х мерный гиперкуб
Рис.26.3. Топология связи, 4-х мерный гиперкуб
Рис.26.4. Архитектура кольца с полной связью по хордам (Chordal Ring)
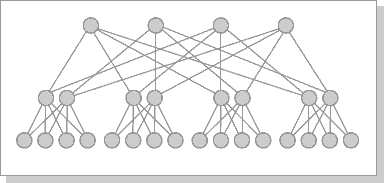
Наиболее эффективной является архитектура с топологией "толстого дерева" (fat-tree). Архитектура "fat-tree" (hypertree) была предложена Лейзерсоном (Charles E. Leiserson) в 1985 году. Процессоры локализованы в листьях дерева, в то время как внутренние узлы дерева скомпонованы во внутреннюю сеть (рис.26.5, 26.6). Поддеревья могут общаться между собой, не затрагивая более высоких уровней сети.
Рис.26.5. Кластерная архитектура "Fat-tree"
Рис.26.6. Кластерная архитектура "Fat-tree" (вид сверху на предыдущую схему)
26.2. Коммутаторы для многопроцессорных вычислительных систем.
Коммуникационные среды вычислительных систем (ВС) состоят из адаптеров вычислительных модулей (ВМ) и коммутаторов, обеспечивающих соединения между ними. Используются как простые коммутаторы, так и составные, компонуемые из набора простых. Простые коммутаторы могут соединять лишь малое число ВМ в силу физических ограничений, однако обеспечивают при этом минимальную задержку при установлении соединения. Составные коммутаторы, обычно строящиеся из простых в виде многокаскадных схем с помощью линий "точка-точка", преодолевают ограничение на малое количество соединений, однако увеличивают и задержки.
26.2.1. Простые коммутаторы
Типы простых коммутаторов:
– с временным разделением;
– с пространственным разделением.
Достоинства: простота управления и высокое быстродействие.
Недостатки: малое количество входов и выходов.
Простые коммутаторы с временным разделением называются также шинами или шинными структурами. Все устройства подключаются к общей информационной магистрали, используемой для передачи информации между ними (рис.18.11).
Рис.26.7. Общая схема шинной структуры
Обычно шина является пассивным элементом, управление передачами осуществляется передающими и принимающими устройствами.
Процесс передачи выглядит следующим образом. Передающее устройство сначала получает доступ к шине, далее пытается установить контакт с устройством-адресатом и определить его способность к приему данных. Принимающее устройство распознает свой адрес на шине и отвечает на запрос передающего. Далее передающее устройство сообщает, какие действия должно произвести принимающее устройство в ходе взаимодействия. После этого происходит передача данных.
Так как шина является общим ресурсом, за доступ к которому соревнуются подключенные к ней устройства, необходимы методы управления предоставлением доступа устройств к шине. Возможно использование центрального устройства для управления доступом к шине, однако это уменьшает масштабируемость и гибкость системы.
Для разрешения конфликтов, возникающих при одновременном запросе устройств на доступ к шине, используются различные приемы, в частности:
назначение каждому устройству уникального приоритета (статического или динамического);
Внутри микросхем шины используются для объединения функциональных блоков микропроцессоров, микросхем памяти, микроконтроллеров. Шины используются для объединения устройств на печатных платах и печатных плат в блоках. Шины используются также в мезонинной технологии, где на большой плате устанавливается один или несколько шинных разъемов для установки меньших плат, так называемых мезонинов.
Шины, объединяющие устройства, из которых состоит вычислительная система, являются критическим ресурсом, отказ которого может привести к отказу всей системы. Шины обладают также рядом принципиальных ограничений. Возможность масштабируемости шинных структур ограничивается временем, затрачиваемым на арбитраж, и количеством устройств, подключенных к шине. При этом чем больше подключенных устройств, тем больше времени затрачивается на арбитраж. Время арбитража ограничивает и пропускную способность шины. Кроме того, в каждый момент времени шина используется для передачи только одним устройством, что становится узким местом при увеличении количества подключенных устройств. пропускная способность шины ограничивается ее шириной – количеством проводников, используемых для передачи данных, – и тактовой частотой ее работы. Данные величины имеют физические ограничения.
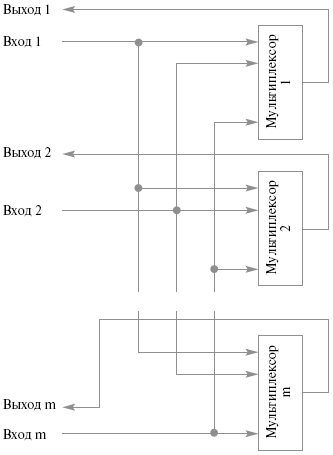
Простые коммутаторы с пространственным разделением позволяют одновременно соединять любой вход с любым одним выходом (ординарные) или несколькими выходами (неординарные). Такие коммутаторы представляют собой совокупность мультиплексоров, количество которых соответствует количеству выходов коммутатора, при этом каждый вход коммутатора должен быть заведен на все мультиплексоры. Структура этих коммутаторов показана на рис.26.8.
Рис.26.8. Простой коммутатор с пространственным разделением
Достоинства:
возможность одновременного контакта со всеми устройствами;
минимальная задержка;
Недостатки:
высокая сложность порядка n x m, где n – количество входов, m – количество выходов;
сложность обеспечения надежности.
26.2.2. Составные коммутаторы
Простые коммутаторы имеют ограничения на число входов и выходов, а также могут требовать большого количества оборудования при увеличении этого числа (в случае пространственных коммутаторов). Поэтому для построения коммутаторов с большим количеством входов и выходов используют совокупность простых коммутаторов, объединенных с помощью линий "точка-точка".
Составные коммутаторы имеют задержку, пропорциональную количеству простых коммутаторов, через которые проходит сигнал от входа до выхода, т.е. числу каскадов. Однако объем оборудования составного коммутатора меньше, чем простого с тем же количеством входов и выходов.
Чаще всего составные коммутаторы строятся из прямоугольных коммутаторов 2 х 2 с двумя входами и выходами. Они имеют два состояния: прямое пропускание входов на соответствующие выходы и перекрестное пропускание. Коммутатор 2 х 2 состоит из собственно блока коммутации данных и блока управления. Блок управления в зависимости от поступающих на него управляющих сигналов определяет, какой тип соединения следует осуществить в блоке коммутации - прямой или перекрестный. При этом если оба входа хотят соединиться с одним выходом, то коммутатор разрешает конфликт и связывает с данным выходом только один вход, а запрос на соединение со стороны второго блокируется или отвергается.
26.2.2.1. Коммутатор Клоза
Коммутатор Клоза может быть построен в качестве альтернативы для прямоугольного коммутатора с (m x d) входами и (m x d) выходами. Он формируется из трех каскадов коммутаторов: m коммутаторов (d x d) во входном каскаде, m коммутаторов (d x d) в выходном и d промежуточных коммутаторов (m x m) (рис.26.9).
Рис.26.9. Коммутатор Клоза 3х4
Соединения внутри коммутатора устроены следующим образом:
j-й выход i-ого коммутатора входного каскада соединен с i-ым входом j-ого промежуточного коммутатора;
Данный тип составных коммутаторов позволяет соединять любой вход с любым выходом, однако при установленных соединениях добавление нового соединения может потребовать разрыва и переустановления всех соединений.