Процессоры ARM (Advanced RISK Machine – усовершенствованная RISK – машина) разрабатываются британской компанией ARM и её лицензиатами. Сама компания ARM не занимается выпуском микросхем, а продаёт готовые решения для процессорного ядра другим компаниям, которые пристраивают к ядру свою периферию и занимаются выпуском микросхем и устройств на их основе.
На данный момент компания ARM выпускает следующие семейства процессоров: ARM7, ARM9, ARM10, ARM11 и Cortex. Объявлено о подготовке к выпуску в 2012 году семейства ARM A15 под кодовым названием Eagle.
Процессоры ARM A15 будут обладать следующими характеристиками: тактовая частота до 2,5 ГГц, одно, два, четыре или восемь ядер, поддержка 1 терабайта оперативной памяти, ECC кеш L1 и L2, общий кеш для многопроцессорных систем, поддержка виртуализации, двойная проверка операций с плавающей запятой, векторные инструкции, слежение за кешем.
В отдельных моделях будущих чипов компании ARM обещает поддержку технологии многопоточности, которая позволит каждому ядру одновременно обрабатывать более одного потока инструкций.
По лицензии компании ARM производят микропроцессоры такие фирмы как Atmel, Cirrus Logic, Intel, Marvell, NXP, STMicroelectronics, Samsung, Qualcomm, Sony Ericsson, Texas Instruments, nVidia, Freescale, Analog Devises и другие. Примеры процессоров разработанных основными лицензиатами: DEC StrongARM, Freescale i.MX, Marvell XScale, NVIDIA Tegra, ST-Ericsson Nomadik, Qualcomm Snapdragon и Texas Instruments OMAP.
Архитектура ARM содержит следующие особенности RISC:
Архитектура загрузки/хранения.
Равномерный 16х32-битный файл регистра.
Фиксированная длина команд (32 бита) для упрощения декодирования за счет снижения плотности кода. Есть специальный режим Thumb повышающий плотность кода.
Одноцикловое исполнение.
Арифметические инструкции заменяют условные коды только когда это необходимо.
32-битное многорегистровое циклическое сдвиговое устройство, которое может быть использовано без потерь производительности в большинстве арифметических инструкций и адресных расчетов.
Мощные индексированные адресные режимы.
Регистр ссылок для быстрого вызова функций .
Простые, но быстрые, с двумя уровнями приоритетов подсистемы прерываний с включенными банками регистров.
Одним из существенных отличий архитектуры ARM от других архитектур процессоров является так называемая предикация - возможность условного исполнения команд. Под "условным исполнением" здесь понимается то, что команда будет выполнена или проигнорирована в зависимости от текущего состояния флагов состояния процессора.
В то время как для других архитектур таким свойством, как правило, обладают только команды условных переходов, в архитектуру ARM была заложена возможность условного исполнения практически любой команды. Это было достигнуто добавлением в коды их инструкций особого 4-битового поля (предиката). Одно из его значений зарезервировано для того, чтобы инструкция могла быть выполнена безусловно, а остальные кодируют то или иное сочетание условий (флагов). С одной стороны, с учётом ограниченности общей длины инструкции, это сократило число бит, доступных для кодирования смещения в командах обращения к памяти, но с другой - позволило избавляться от инструкций ветвления при генерации кода для небольших if-блоков.
ARM процессор также имеет некоторые особенности, редко встречающиеся в других архитектурах RISC — такие, как адресация относительно счетчика программ (на самом деле счетчик команд ARM является одним из 16 регистров), а также пре- и пост-инкрементные режимы адресации.
ARM7 и более ранние версии имеют трехступенчатый конвейер. Это ступени переноса, декодирования и исполнения. Более производительные архитектуры, типа ARM9, имеют более сложные конвейеры. Cortex-a8 имеет 13-ступенчатый конвейер.
Архитектура предоставляет способ расширения набора команд, используя сопроцессоры, которые могут быть адресованы, используя команды регистрового обмена с сопроцессором MCR, MRC, MRRC, MCRR и похожие команды. Пространство сопроцессора логически разбито на 16 сопроцессоров с номерами от 0 до 15, причем 15й зарезервирован для некоторых типичных функций управления, типа управления кэш-памятью и MMUоперации (memory management unit — блок управления памятью).
В машинах на основе ARM периферийные устройства обычно подсоединяются к процессору путем сопоставления их физических регистров в памяти ARM или в памяти сопроцессора, или путем присоединения к шинам, которые в свою очередь подсоединяются к процессору. Доступ к сопроцессорам имеет большее время ожидания, поэтому некоторые периферийные устройства проектируются для доступа в обоих направлениях. В остальных случаях разработчики чипов лишь пользуются механизмом интеграции сопроцессора. Например, движок обработки изображений должен состоять из малого ядра ARM7TDMI, совмещенного с сопроцессором, который поддерживает примитивные операции по обработке элементарных кодировок HDTV (High-Definition Television- Телевидение высокой чёткости).
ARM предоставляет 31 регистр общего назначения разрядностью 32 бит. В зависимости от режима и состояния процессора пользователь имеет доступ только к строго определённому набору регистров. В ARM state разработчику постоянно доступны 17 регистров:
13 регистров общего назначения (r0..r12).
Stack Pointer (r13) — содержит указатель стека выполняемой программы.
Link register (r14) — содержит адрес возврата в инструкциях ветвления.
Program Counter (r15) — биты [31:1] содержат адрес выполняемой инструкции.
Current Program Status Register (CPSR) — содержит флаги, описывающие текущее состояние процессора. Модифицируется при выполнении многих инструкций: логических, арифметических, и др.
Во всех режимах, кроме User mode и System mode, доступен также Saved Program Status Register (SPSR). После возникновения исключения регистр CPSR сохраняется в SPSR. Тем самым фиксируется состояние процессора (режим, состояние; флаги арифметических, логических операций, разрешения прерываний) на момент непосредственно перед прерыванием
В большинстве существующих моделей микропроцессоров реализована шина PCI и возможность работы с внешней динамической оперативной памятью (DRAM). В процессорах, предназначенных для потребительских устройств, также обычно интегрируются: контроллеры шин USB, IIC, AC’97-совместимое звуковое устройство, устройство для работы с флэш-носителями стандарта SD и MMC, контроллер последовательного порта.
Все процессоры имеют линии ввода-вывода общего назначения (GPIO). В потребительских устройствах к ним могут быть подключены кнопки «быстрого запуска», сигнальные светодиоды, колесо прокрутки (JogDial), клавиатура.
24.2.1. Дополнительные технологии
Thumb (Большой палец/Тумба)
Для улучшения компилируемой плотности кода, процессоры, начиная с ARM7TDMI, снабжены режимом тумбы (в оригинале обыграны слова arm--рука и thumb--большой палец). В этом режиме процессор выполняет 16-разрядные команды. Большинство из этих 16-разрядных команд тумбы переводятся в нормальные команды ARM. Экономия пространства происходит за счет сокрытия некоторых операндов и ограничения возможностей по сравнению с режимом полного набора команд ARM.
В режиме тумбы меньшие коды операций обладают меньшей функциональностью. Например, только ветвления могут быть условными, и многие коды операций имеют ограничение на доступ только к половине главных регистров процессора. Более короткие коды операций в целом дают большую плотность кода, хотя некоторые операции требуют дополнительных команд. В ситуациях, когда порт памяти или ширина шины ограничены 32мя битами, более короткие коды операций режима тумбы становятся гораздо производительнее по сравнению с обычным 32-битным ARM кодом, так как меньший программный код придется загружать в процессор при ограниченной пропускной способности памяти.
Thumb-2
Thumb-2 — технология, стартовавшая с ARM1156 core, анонсированного в 2003 году. Он расширяет ограниченный 16-битный набор команд Thumb дополнительными 32-битными командами, чтобы задать набору команд дополнительную ширину. Цель Thumb-2 — достичь плотности кода как у Thumb, и производительности как у набора команд ARM на 32 битах. Можно сказать, что в ARMv7 эта цель была достигнута.
Thumb-2 расширяет как команды ARM, так и команды Thumb еще большим количеством команд, включая управление битовым полем, табличное ветвление, условное исполнение. Новый язык «Unified Assembly Language» (UAL) поддерживает создание команд как для ARM, так и для Thumb из одного и того же исходного кода.
Jazelle
Jazelle — это метод, который позволяет байткоду Java исполняться прямо в архитектуре ARM в качестве 3го состояния исполнения (и набора команд) наряду с обычными командами ARM и режимом бегунка. Поддержка этого свойства обозначается буквой «J» в названии процессора — например, ARMv5TEJ. Необходимость такой поддержки появляется начиная с процессоров ARMv6, хотя новые ядра лишь содержат тривиальные реализации, которые не поддерживают аппаратного ускорения.
Усовершенствованный SIMD(NEON)
Расширение усовершенствованного SIMD, также называемое технологией NEON — это комбинированный 64- и 128-битный набор команд SIMD (single instruction multiple data), который обеспечивает стандартизованное ускорение для медиа приложений и приложений обработки сигнала. NEON может выполнять декодирование аудио формата mp3 на частоте процессора в 10Мгц, и может работать с речевым кодеком GSM AMR (adaptive multi-rate) на частоте более чем 13Мгц. Он обладает внушительным набором команд, отдельными файлами регистра, и независимой системой исполнения на аппаратном уровне. NEON поддерживает 8-,16-,32-,64-битную информацию целого типа, одинарной точности и с плавающей точкой, и работает в операциях SIMD по обработке аудио и видео (графика и игры). В NEON SIMD поддерживает до 16 операций единовременно.
VFP
Технология VFP (Vector Floating Point, вектора чисел с плавающей запятой) — это расширение сопроцессора в архитектуре ARM. Она производит низкозатратные вычисления над числами с плавающей запятой одинарной двойной точности, в полной мере соответствующие стандарту ANSI/IEEE Std 754—1985 Standard for Binary Floating-Point Arithmetic.VFP производит вычисления с плавающей точкой, подходящие для широкого спектра приложений — например, для КПК, смартфонов, сжатия звука, 3д-графики и цифрового звука, а также принтеров и телеприставок. Архитектура VFP также поддерживает исполнение коротких векторных команд. Но, поскольку процессор выполняет операции последовательно над каждым элементом вектора, то VFP нельзя назвать истинным SIMD набором инструкций. Этот режим может быть полезен в графике и приложениях обработки сигнала, так как он позволяет уменьшить размер кода и выработку команд.
Другие сопроцессоры с плавающей точкой и/или SIMD, находящиеся в ARM процессорах включают в себя FPA, FPE, iwMMXt. Они обеспечивают ту же функциональность, что и VFP, но не совместимы с ним на уровне опкода.
Расширения безопасности
Расширения безопасности, позиционируемые как TrustZone Technology, находятся в ARMv6KZ и других, более поздних, профилированных на приложениях архитектурах. Оно обеспечивает низкозатратную альтернативу добавлению специального ядра безопасности, обеспечивая 2 виртуальных процессора, поддерживаемых аппаратным контролем доступа. Это позволяет ядру приложения переключаться между двумя состояниями, называемыми «миры» (чтобы избежать путаницы с названиями возможных доменов), чтобы не допустить утечку информации из более важного мира в менее важный. Этот переключатель миров обычно ортогонален всем другим возможностям процессора. Таким образом, каждый мир может работать независимо от других миров, используя одно и то же ядро. Память и периферия соответственно изготавливаются с учетом особенностей мира ядра, и могут использовать это, чтобы получить контроль доступа к секретам и кодам ядра. Типичные приложения TrustZone Technology должны запускать полноценную операционную систему в менее важном мире, и компактный, специализированный на безопасности, код в более важном мире, позволяя Digital Rights Management’у намного точнее контролировать использование медиа на устройствах на базе ARM, и предотвращая несанкционированный доступ к устройству.
Отладка
Все современные процессоры ARM включают аппаратные средства отладки, так как без них отладчики ПО не смогли бы выполнить самые базовые операции типа остановки, отступа, установка контрольных точек после перезагрузки.
Архитектура ARMv7 определяет базовые средства отладки на архитектурном уровне. К ним относятся точки останова, точки просмотра и выполнение команд в режиме отладки. Такие средства были также доступны с модулем отладки EmbeddedICE. Поддерживаются оба режима — остановки и обзора. Реальный транспортный механизм, который используется для доступа к средствам отладки, не специфицирован архитектурно, но реализация, как правило, включает поддержку JTAG.
24.2.2. Ядро ARM7TDMI
Архитектура ядра ARM7TDMI приведена на рис.24.2.
Рис.24.2. Упрощённая архитектура ядра ARM7TDMI
Ядро ARM7TDMI стало первым Thumb-ориентированным ядром. Это ядро семейства ARM7 располагающее:
– встроенной макроячейкой EmbeddedICE™, поддерживающей отладку встроенного ядра ,
– 32-разрядным аппаратным умножителем ,
– декомпрессором Thumb,
– 32-разрядной производительностью в 8- и 16-разрядных управляющих применениях .
Ядро ARM7TDMI пополнило стандартный ряд 32-разрядных ядер ARM, обеспечив возможность выхода на рынок встраиваемого управления, привнося 32-разрядную производительность в 8 и 16-разрядные применения управления. Первый Thumb-ориентированный прибор в кремнии был выпущен во второй половине 1995.
Ядро ARM7TDMI используется как лицензионная макроячейка ARM, предназначенная использования при создании стандартных приборов специального назначения .
И ARM7 и ARM7T ядра в одном тактовом цикле, используют 3-уровневый конвейер с фазами выборки, декодирования и выполнения
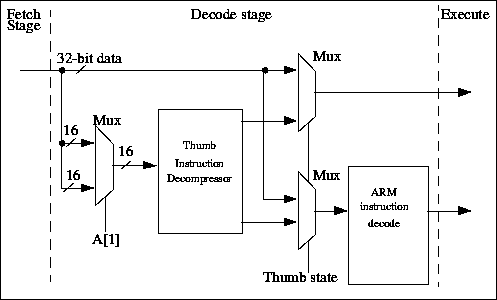
( рис.24.3). Поток команд через каждый уровень конвейера управляется высокими и низкими фазами тактового сигнала. В ядре ARM7TDMI неиспользуемая фаза тактового сигнала используется для декомпрессирования команд Thumb в каскаде декодирования. Следовательно, в одном тактовом цикле производится и декодирование и выполнение команды, не требуется никаких дополнительных непроизводительных затрат синхронизации.
Рис.24.3. Thumb декодирование и декомпрессия
Команды ARM, поступающие из каскада выборки конвейера, проходят через декодер ARM и активируют сигналы управления старшими и младшими битами операционного кода. Старшие биты опкода описывают тип выполняемой команды, тогда как младшие биты определяют детали команды типа определения регистров или операнда.
В Thumb состоянии мультиплексоры направляют Thumb команды через логику декомпрессии Thumb, разворачивающую команду Thumb в ее эквивалент ARM команды . Затем команда ARM выполняется в нормальном режиме.
24.2.3. Семейство ARM10 Tumb
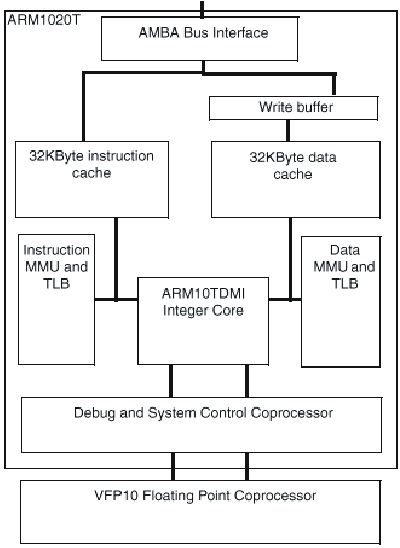
Блок-схема ядра ARM1020T семейства ARM10 приведена на рис.24.4.
Рис.24.4. Блок-схема ядра ARM1020T
Главной особенностью семейства ARM10 является наличие векторного сопроцессора вычислений с плавающей точкой, явного свидетельства современной тенденции к объединению в одном приборе управляющих целочисленных процессоров и процессоров цифровой обработки сигналов..
В основе процессоров семейства ARM10 Thumb целочисленное ядро ARM10TDMI(TM), использующее ARM® 32-разрядную RISC систему команд, сжатую 16-разрядную систему команд Thumb и расширенные Multi-ICE средства отладки программного обеспечения. Ядро процессора ARM10TDMI - первая реализация ARMV5T Архитектуры Системы команд (Instruction Set Architecture - ISA). Архитектура ARMV5T - некоторая комбинация архитектуры ARMV4 ISA, используемой StrongARM процессорами, и ARMV4T ISA используемой процессорами семейств ARM7 Thumb и ARM9 Thumb.
Ядро ARM10TDMI оснащено пятиуровневым конвейером, реализует параллельное выполнение команд, предсказание переходов и способно продолжать работу при неудачном обращении к кэш, обеспечивая высокую производительность в реальных применениях.
Выполнение (Сдвиг и ALU), вычисление адреса и умножение
M:
Обращение к памяти и умножение
W:
Запись в регистры
Процессор ARM10T обеспечивает производительность 400 MIPS
( миллионов операций в секунду) на частоте 300 МГц, а векторное устройство операций с плавающей точкой, обеспечивает производительность 600 MFLOPS (миллионов операций с плавающей точкой в секунду). Такие уровни целочисленной и с плавающей точкой производительности необходимы для применений, оснащенных сложными интерфейсами с 2- и 3-мерной графикой, типа игровых видео плееров и высокопроизводительных принтеров, при сохранении доступных потребительских цен.
В настоящее время в семейство входит ARM1020T™ - кэшированное макроядро процессора, сформированное на основе ядра ARM10TDMI и оснащенное встроенными кэш команд и данных емкостью по 32 Кбайт, MMU, поддерживающим виртуальную память с подкачкой страниц по требованию, буфером записи, и широкополосным шинным интерфейсом AMBA, класса "система на кристалле".
Сопроцессор векторных вычислений с плавающей точкой VFP10 (Vector Floating Point - VFP) интегрируется на тот же кристалл что и процессор ARM1020T в тех применениях, для которых он необходим. Сопроцессор VFP10 - первая реализация новой архитектуры VFPV1 процессоров вычислений с плавающей точкой фирмы ARM. Сопроцессор VFP10 обеспечивает высокопроизводительные IEEE вычисления с плавающей точкой одиночной и двойной точности, занимая на кристалле площадь малого размера и при его реализации был использован RISC подход, заключающийся в том, что простые, наиболее часто используемые операции реализуются в кремнии (аппаратно) а для обработки редких исключительных случаев используются программные решения. Векторные операции хорошо использовать для обеспечения потребностей целевых применений и они обеспечивают существенный параллелизм при простой схемотехнике.
Векторный характер архитектуры VFP, с одним потоком команд и многими потоками данных (SIMD - single-instruction, multiple-data), позволяет одиночной команде оперировать с множеством элементов данных, что позволяет сразу выполнять многоадресные команды и существенно увеличивает производительность в применениях с интенсивными операциями с плавающей точкой.
В конвейере вычислений с плавающей точкой VFP10 используется два конвейера - пятиуровневый конвейер команд загрузки и памяти и семиуровневый конвейер арифметических команд. Эти конвейеры совместно используют два первых уровня, что ограничивает количество выполняемых команд одной командой, но из-за векторного характера архитектуры VFP в параллель могут быть выполнены команда векторной арифметики и векторной загрузки или команда сохранения.
Конвейером отслеживаются пять уровней загрузки и хранения. В случае выполнения множественных пересылок уровень памяти конвейера используется многократно для каждого элемента данных. За каждый цикл могут быть перемещены два значения одиночной точности или одно значение двойной точности.
В семиуровневом арифметическом конвейере первые 3 уровня соответствуют конвейеру ARM, в которых команды принимаются от ARM (выборка, декодирование и выполнение). Команды загрузки и сохранения и команды пересылки данных, остаются зафиксированными в ARM на два следующих цикла, с тем, чтобы передать данные на соответствующем уровне памяти ARM, и записи данных на пятом уровне.
Малое потребление процессора ARM10 (менее 600 мВт) позволяет приборы с высоким уровнем интеграции размещать в недорогих корпусах, использовать более дешевые компоненты питания, позволяющие отказаться от дорогостоящих средств теплоотвода.
Специалисты фирмы ARM так излагают основные идеи заложенные в семействе процессоров ARM10: чтобы отслеживать характер работы и, в зависимости от этого, снижать потребление, разработчики отказались от сложности и дороговизны полностью суперскалярной машины. Необходимый уровень производительности был достигнут за счет использования уникальных особенностей архитектуры ARM, обеспечивающих высокую степень внутреннего параллелизма в единожды созданной машине. Система команд векторных операций с плавающей точкой полностью новая, так что разработчики, проанализировав алгоритмы, необходимые для основных применений, имели возможность создать устройство очень быстрое, применяя возможные кремниевые решения для наиболее часто используемых операций, оставляя на долю программных решений действительно уникальные операции.
24.3. Контрольные вопросы
1. Характерные особенности RISC-архитектуры .
2. Назначение механизма перекрывающихся регистровых окон .
3. Характерные особенности архитектура ARM.
4. Назначение предиката в ARM.
5. Дополнительные технологии в ARM.
6. Технологии Thumb и Thumb2.
7. Технология Jazelle.
8. Технология NEON.
9. Технология VFP.
10. Система безопасности TrustZone Technology.
11. Упрощённая архитектура ядра ARM7TDMI.
12. Thumb декодирование и декомпрессия.
13. Блок-схема ядра ARM1020T.
Тема 18. Суперкомпьютеры. Параллельные вычислительные системы
Лекция 25
25.1. Смена приоритетов в области высокопроизводительных вычислений
Потребности человека к производительности вычислительных систем постоянно растут. Одним из возможных решений является разработка и применение систем с массовым параллелизмом — кластеров, Grid-систем, многопроцессорных комплексов, систем на многоядерных процессорах.
Происходит смена приоритетов при разработке процессоров, систем на их основе и, соответственно, программного обеспечения. Направление смены приоритетов связано с преодолением трёх, так называемых "стен", когда на смену прежним истинам приходят новые:
– Энергетическая стена. Старая истина — энергия не стоит ничего, транзисторы дороги. Новая истина — дорога энергия, транзисторы не стоят ничего.
– Стена памяти. Старая истина — память работает быстро, а операции с плавающей запятой медленны. Новая истина — системную производительность сдерживает память, операции выполняются быстро.
– Стена параллелизма на уровне команд. Старая истина — производительность можно повысить за счет качества компиляторов и таких архитектурных усовершенствований, как конвейеры, внеочередное выполнение команд, сверхдлинное командное слово (Very Long Instruction Word, VLIW), явный параллелизм команд (Explicitly Parallel Instruction Computing, EPIC) и др. Новая истина — естественный параллелизм, команды допустимы и длинные, и короткие, но выполняются они параллельно, на разных ядрах.
Можно говорить о двух заметно разнящихся между собой тенденциях в процессе увеличения числа ядер. Одна носит название мультиядерность (multi-core). В этом случае предполагается, что ядра являются высокопроизводительными и их относительно немного, но согласно закону Мура их число будет периодически удваиваться. Основных недостатков два: первый — высокое энергопотребление, второй — высокая сложность чипа и, как следствие, низкий процент выхода готовой продукции. При производстве 8-ядерного процессора IBM Сell только 20% производимых кристаллов являются годными. Другой путь — многоядерность (many-core). В таком случае на кристалле собирается на порядок большее число ядер, но имеющих более простую структуру и потребляющих миливатты мощности. Сейчас количество ядер варьируется от 40 до 200, и если закон Мура будет выполняться и для них, то можно ожидать появления процессоров с тысячами и десятками тысяч ядер.
Традиционным средством повышения производительности процессоров всегда было увеличение тактовой частоты, но рост потребления энергии и проблемы с отводом тепла заставили разработчиков вместо этого наращивать количество ядер. Однако, многоядерные процессоры, если все сводится к размещению большего числа классических простых ядер на одной подложке, нельзя воспринимать как решение всех проблем. Их чрезвычайно сложно программировать, они могут быть эффективны только на приложениях, обладающих естественной многопоточностью.
Энергетическая стена, стена памяти и стена параллелизма на уровне команд являются прямым следствием фон-неймановской архитектуры. Из-за технологических ограничений Джоном фон Нейманом была избрана схема, в основе которой лежит управляемый поток команд, программа, выбирающая необходимые для команд данные. Этим определяется канонический состав архитектурных компонентов, составляющих любой компьютер, — счетчик команд, код операции и адреса операндов; он остается неизменным по сей день. Все мыслимые и немыслимые усовершенствования архитектуры фон Неймана в конечном счете сводятся к повышению качества управления потоком команд, методам адресации данных и команд, кэшированию памяти и т.п. При этом последовательная архитектура не меняется, но сложность ее возрастает. Очевидно, что представление о компьютере как об устройстве, выполняющем заданную последовательность команд, лучше всего подходит для тех случаев, когда объем обрабатываемых данных невелик, а данные являются статическими. Но в современных условиях приходится сталкиваться с приложениями, где относительно небольшое количество команд обрабатывает потоки данных. В таком случае целесообразно предположить, что компьютером может быть и устройство, которое имеет каким-то образом зашитые в него алгоритмы и способно обрабатывать потоки данных. Такие компьютеры могли бы обладать естественным параллелизмом, а их программирование свелось бы к распределению функций между большим числом ядер.
Можно допустить существование следующих альтернативных схем. Одна, фон-неймановская, предполагает, что вычислительным процессом управляет поток команд, а данные, в основном статичные, выбираются из каких-то систем хранения или из памяти. Вторая схема основывается на том, что процессом вычислений управляют входные потоки данных, которые на входе системы попадают в подготовленную вычислительную инфраструктуру, обладающую естественным параллелизмом. С точки зрения реализации первая схема гораздо проще, кроме того, она универсальна, программы компилируются и записываются в память, а вторая требует специальной сборки нужной для определенной задачи аппаратной конфигурации. Вторая схема старше; пример тому — табуляторы, изобретенные Германом Холлеритом и с успехом использовавшиеся на протяжении нескольких десятилетий. Корпорация IBM достигла своего могущества и стала одной из самых влиятельных компаний в США, производя электромеханические табуляторы для обработки больших массивов информации, не требующей выполнения логических операций. Их программирование осуществлялось посредством коммутации на пульте, а далее устройство управления в соответствии с заданной программой координировало работу остальных устройств.
От машины фон Неймана антимашина отличается наличием одного или нескольких счетчиков данных, управляющих потоками данных. Она программируется с использованием потокового обеспечения (Flowware), а роль центрального процессора в ней играют один или несколько процессоров данных (Data Path Unit, DPU). Центральной частью антимашины может стать память с автоматической последовательностью (Auto-Sequence Memory)(рис.18.1).
Асимметрия между машиной и антимашиной наблюдается во всем, за исключением того, что антимашина допускает параллелизм внутренних циклов, а это значит, что в ней решается проблема параллельной обработки данных. В антимашине доступ к памяти обеспечивается не по адресу команды или фрагмента данных, записанному в соответствующий регистр, а посредством универсального генератора адресов (Generic Address Generator, GAG). Его преимущество в том, что он позволяет передавать блоки и потоки данных. В то же время компиляция, посредством которой создается специализированная под определенную задачу система, заключается в объединении нужного количества настроенных процессоров данных в общий массив (Data Process Array, DPA), на котором выполняются алгоритмы Flowware и который может быть реконфигурируемым.