· Если время удержания магистрали истекло (хотя обмен и не закончен), то master освобождает магистраль либо сам, либо после выставления арбитром сигнала БПД, который запрещает активным устройствам магистрали bus mastering.
12. Начинается процедура захвата магистрали ведущим устройством с меньшим приоритетом (организация канала M-S), если запрос в арбитр уже поступил (см. операции, начиная с п. 4).
В простых системах bus master DMA цепочечной структуры может присутствовать только одна ЛЗПД. В этом случае отпадает необходимость выполнения процедуры поиска возбужденной ЛЗПД с максимальным приоритетом. Отпадает необходимость и в отдельном арбитре магистрали. Такие системы bus master DMA являются наиболее динамичными, даже при достаточно большом количестве ИЗПД.
20.3.5. Принципы организации арбитража магистрали
Нормальное функционирование системы ПДП любой структуры очень во многом зависит от правильного выбора дисциплины обслуживания устройств магистрали, т.е. от правильного выбора системы приоритетных соотношений. Особенно остро эта проблема стоит в вычислительных системах, использующих bus mastering, поскольку общая производительность системы существенно зависит от равномерности загрузки всех ведущих устройств магистрали. Последнее можно обеспечить только рациональным выбором дисциплины арбитража (в дальнейшем просто арбитража). Существуют многочисленные варианты арбитража, каждый из которых имеет свои преимущества и недостатки, причем ни один из них не может быть назван идеальным для любых вычислительных систем. Оптимальный вариант арбитража всегда зависит от конкретной конфигурации вычислительной системы и ее целевого назначения, типа используемых процессоров, конфигурации и назначения ведущих устройств магистрали, способов взаимодействия с системой прерывания и многих других факторов. Способ арбитража определяет и название арбитра, используемого в конкретной вычислительной системе.
Наиболее популярными вариантами арбитров в настоящее время являются: одноуровневый, с фиксированными приоритетами, с циклическим изменением приоритетов, круговой. Рассмотрим их более подробно.
Одноуровневый арбитр
Это простейший вариант арбитра, который используется в простых системах bus master DMA цепочечной структуры, изображенной на рис. 20.3. В соответствии со своим названием он обслуживает только один уровень запроса и предоставляет магистраль, используя одну линию ЛРПД, т.е. в системе используется только одна ШАр. В этом случае отпадает необходимость выполнения процедуры поиска возбужденной ЛЗПД с максимальным приоритетом. Отпадает необходимость и в отдельном арбитре магистрали, поэтому термин "одноуровневый арбитр" не совсем уместен, так как реальным арбитражем он не занимается. Каждое ИЗПД само принимает решение принимать или пропускать сигнал РПД. Такие системы bus master DMA, как уже отмечалось, являются наиболее динамичными, даже при достаточно большом количестве ИЗПД, и могут быть построены с минимальной аппаратной поддержкой.
Основной недостаток такого арбитра состоит в том, что постоянное преимущество в использовании магистрали имеют устройства, расположенные в слотах с малыми номерами, т.е. близкие к слоту "0".
Арбитр с фиксированными приоритетами
Это также достаточно простой вариант арбитра, который предполагает, что за каждым входом ШАр (система bus master DMA) или ЛЗПД (система slave DMA) закреплен определенный уровень приоритета, который не может быть изменен в процессе обслуживания устройств магистрали. В большинстве случаев количество входов в арбитр или контроллер ПДП не превышает 4-8. Для увеличения количества входов, особенно в контроллерах систем slave DMA, обычно допускается их каскадное включение. Основной недостаток такого арбитра состоит в том, что постоянное преимущество в использовании магистрали имеют устройства, использующие вход арбитра с максимальным приоритетом.
Арбитр с циклическим изменением приоритета
Этот вариант арбитра является развитием варианта арбитра с фиксированными приоритетами. Алгоритм функционирования такого арбитра состоит в следующем. Пусть арбитр имеет четыре входа, к которым подключены четыре ШАр – ШАр0, ШАр1, ШАр2, ШАр3. После инициализации входам арбитра присваиваются фиксированные приоритеты (например, ШАр0 – высший, а ШАр3 – низший). Однако после обслуживания устройств одной из ШАр ей автоматически назначают низший приоритет, а приоритеты остальных ШАр изменяются в круговой последовательности. Например, после обслуживания ШАр2 приоритеты остальных ШАр убывают в таком порядке: ШАр3, ШАр0, ШАр1, ШАр2. Такой режим позволяет выровнять приоритеты всех ШАр и не допустить преимущественное использование магистрали устройствами одной ШАр. Возможны и другие схемы выравнивания приоритетов.
Основной недостаток такого арбитра состоит в том, что невозможно жестко зафиксировать наивысший приоритет какой-либо ШАр или устройства.
Круговой арбитр
Этот вариант арбитра предоставляет равный приоритет всем ШАр, подключенным к его входам. Пусть, как и в предыдущем случае, к арбитру подключены четыре ШАр. Тогда арбитр предоставляет магистраль в распоряжение устройств каждой ШАр на основе круговой диспетчеризации подобно круговому переключателю на четыре позиции. После запуска вычислительной системы "переключатель" может установиться либо на фиксированную, либо на случайную позицию (вход ШАр). Все зависит от конкретной технической реализации арбитра. Пусть это будет вход ШАр0. Когда одно из ведущих устройств ШАр0 осуществит обмен и освободит магистраль, "переключатель" повернется на следующую позицию и предоставит возможность захвата магистрали ведущим устройствам ШАр1. Если на входе ШАр1 его не ожидает запрос, арбитр пропустит этот вход и переключится на следующий, т.е. на вход ШАр2. Таким образом, ведущие устройства всех ШАр обеспечиваются равными правами на захват магистрали.
Основной недостаток такого арбитра аналогичен предыдущему.
Рассмотренные выше варианты, как уже отмечалось, не исчерпывают всего многообразия арбитров, используемых в реальных вычислительных системах. Кроме того, следует помнить, что многие арбитры являются сложными перепрограммируемыми устройствами и могут, после соответствующей инициализации, поддерживать не только различные варианты арбитража, но и использовать комбинированные варианты, наиболее оптимальные для конкретной вычислительной системы.
20.4. Микропроцессорная система на основе МП КР580ВМ80А
Упрощенная структурная схема вычислительного устройства на базе МП I8080 (КР580ВМ80А) представлена на рис. 20.4. Это простейшая микро-ЭВМ минимальной конфигурации, структура которой является частным случаем обобщенной (см. рис. 18.1).
Представленная схема включает все основные функциональные блоки, за исключением источника питания. ПЗУ может быть использовано для хранения программы, а ОП для хранения данных, поступающих от ПУ (через ППУ), а также результатов работы программы. Предполагается, что ОП и ПЗУ охвачены единым полем адресов.
К шинам адреса и данных системной магистрали, даже в простейшей микро-ЭВМ, подключено достаточно много устройств: ОП, ПЗУ, несколько ППУ. Однако нагрузочная способность выходов МП КР580, в силу технологических особенностей, весьма мала. К любому выходу МП допускается подключать не более одного входа микросхемы ТТЛ, поэтому в шины адреса и данных включаются специальные буферы, причем ШД требует двунаправленного буфера. Для построения таких буферов предусмотрены микросхемы шинных формирователей КР580ВА86 и КР580ВА87.
Общие принципы функционирования микропроцессорной системы следующие. Из МП на ША (16 разрядов) выдается адрес очередной команды. В этот момент МП еще «не знает», сколько байт занимает данная команда. Первый байт команды, выбранный из памяти (в частном случае из ПЗУ), пересылается по внутренней ШД в РгК. Выход РгК связан с дешифратором команд, который определяет тип выполняемой операции. При этом к содержимому СчК добавляется 1, т.е. формируется адрес следующего байта, а УУ вырабатывает ряд сигналов, позволяющих выполнить те или иные микрооперации. После этого возможны два варианта дальнейших действий:
· Если команда однобайтовая, то она выполняется, а содержимое счетчика адреса (РС) = (РС) + 1 является адресом следующей команды.
· Если команда содержит более одного байта (2 или 3) и для ее выполнения требуется вызов дополнительных байтов, то содержимое счетчика адреса команд (РС) = (РС) + 1 является адресом следующего байта той же команды.
Рис.20.4. Упрощённая структурная схема микропроцессорной системы на базе МП КР580ВМ80
Рассмотрим более подробно процесс выполнения команды. Этот процесс разбивается на машинные циклы, которые обозначаются M1...M5. Число циклов в одной команде может быть от одного до пяти. В свою очередь, каждый машинный цикл состоит из тактов, обозначаемых T1...T5. В одном машинном цикле может быть от трех до пяти тактов. Имеется в виду 5 типов тактов, поскольку в каждом такте выполняется определенное действие по реализации машинного цикла. При этом количество тактов как временных интервалов может быть значительно больше за счет тактов Т2, о чем речь пойдет ниже. В каждом машинном цикле производится одно обращение к памяти или ППУ в разных вариантах. Каждый такой вариант обращения называется состоянием цикла. Всего в МП КР580 возможно 10 состояний машинного цикла. Это выборка первого байта команды, чтение из памяти, запись в память, чтение из стека, запись в стек, ввод из ППУ, вывод через ППУ, подтверждение прерывания, подтверждение останова, подтверждение прерывания при останове. При этом первым машинным циклом любой команды всегда является выборка первого байта команды.
Во всех машинных циклах первые три такта (T1,T2,T3) используются для организации обмена с памятью и ППУ. Такты T4 и T5 (если они есть) – для выполнения внутренних операций в МП. Таким образом, процесс выполнения команд состоит из стольких машинных циклов, сколько обращений к памяти или ППУ требуется для ее исполнения.
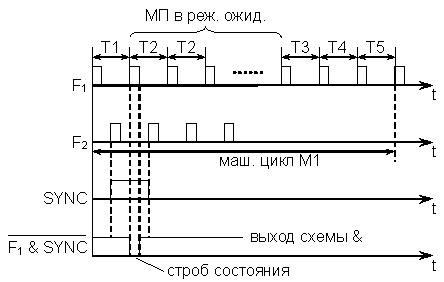
Рис.20.5. Временная диаграмма цикла М1
На рис. 20.5 представлена временная диаграмма цикла М1 из пяти тактов (первый машинный цикл любой команды). Отсчет тактов производится от положительных фронтов импульса F1. Действия процессора по реализации машинного цикла М1 состоят в следующем:
T1 – содержимое РС выдается на ША, адрес принимается памятью, где начинается чтение байта команды из ячейки.
T2 – проверяется наличие сигнала на входе READY (уровень логической 1). Этот сигнал подается на вход МП через интервал времени, достаточный для завершения процесса чтения из памяти. Если на входе READY сигнал отсутствует (действует логический 0), то МП устанавливается в режим ожидания, в котором каждый следующий такт рассматривается как T2 до тех пор, пока не появится сигнал READY. С приходом этого сигнала МП выходит из режима ожидания и переходит в такт T3.
T3 – байт с ШД принимается в МП и помещается в регистр команд (РгК).
T4 – происходит анализ принятого байта и выяснение потребности в дополнительном обращении к памяти. Если дополнительных обращений не требуется (команда однобайтовая и операнды находятся в регистрах процессора), то в этом же такте или с использованием дополнительного такта T5 выполняются предусмотренные командой микрооперации.
T5 – дополнительный такт.
Если требуется дополнительное обращение к памяти, то после T4 цикл M1 завершается и происходит переход к циклу M2.
Отметим, что КОП всегда находится в первом байте команды. Если команда двух- или трехбайтовая, то в остальных байтах находятся данные или адрес. Содержимое этих байтов помещается в аккумулятор или буферные регистры. Так, например, в команде MOV (запись аккумулятора в ячейку памяти) двухбайтовый адрес, который следует за КОП, помещается в регистровую пару WZ, а затем, при исполнении, он передается через мультиплексор непосредственно в РА и далее через буфер на ША.
В каждом машинном цикле в такте T1 по переднему фронту F2 МП выдает сигнал синхронизации SYNC, т.е. на выходе SYNC появляется уровень логической 1. Одновременно с этим сигналом в такте T1 МП выставляет на ШД 8-разрядное управляющее слово, которое несет в себе полную информацию о микрооперациях в текущем машинном цикле. Так, например, 1 в разряде D0 управляющего слова является сигналом подтверждения прерывания INTA. Наличие 1 в разряде D2 означает, что в данном машинном цикле на ША установлено содержимое указателя стека (регистр SP). Наличие 1 в разряде D3 означает, что МП в состоянии останова. В момент прихода импульса F1, означающего начало такта T2, на схеме "&" (рис. 14.6) вырабатывается импульс, называемый строб состояния. Этот строб разрешает запись управляющего слова с ШД во внешний регистр, названный на схеме фиксатор состояния.
Используя это слово или его часть, специальные логические схемы вырабатывают системные управляющие сигналы для обращения к памяти и ППУ. В общем случае фиксатор состояния и блок логических схем называются системным контроллером. Эти, а также некоторые другие вспомогательные схемы, в частности шинный формирователь, оформлены в виде специальной БИС КР580ВК28. Однако в простейших микроЭВМ часто требуются только 4 управляющих сигнала – R, W, IN, OUT. В связи с этим необходимость в БИС ВК28 отпадает, а используют какой-либо управляемый регистр и 2-3 логические схемы.
20.5. Контрольные вопросы
1. Принципы организации систем прямого доступа в память.
2. Способы организации доступа к системной магистрали при ПДП.
3. Возможные структуры систем ПДП.
4. Обобщённая цепочечная структура системы Bus Master DMA.
5. Структура шины арбитража ”n” системы bus master DMA цепочечного типа.
6. Организация обмена в режиме ПДП.
7. Принципы организации арбитража магистрали.
8. Упрощённая структурная схема микропроцессорной системы на базе МП КР580ВМ80.
Тема 15. Схемы поддержки МП на системных платах
Лекция 21
С целью оптимизации работы процессоров выпускается большое количество вспомогательных наборов микросхем, называемых чипсетами (chipset), которые выполняют какие-либо отдельные функции процессора и/или выполняют роль связующего компонента, обеспечивающего совместное функционирование всех составных частей ЭВМ и устройств, построенных на их основе, например, сотовых телефонов. Далее идеология построения схем поддержки МП будет рассмотрена на примере чипсетов для архитектуры х86, используемой в персональных компьютерах типа IBM PC. Среди основных производителей таких чипсетов фирмы Intel, NVidia, AMD, Via, SiS.
21.1. Эволюция шинной архитектуры IBM PC
В разделе 10 было показано, что переход от мэйнфреймов к малым ЭВМ (мини и микро) сопровождался существенным упрощением внутренней структуры компьютера, а именно, переходом к магистрально-модульной структуре. Магистрально-модульная структура предполагает наличие в компьютере некоторой общей магистрали, к которой в необходимой номенклатуре и количестве подключены все устройства ЭВМ, выполненные в виде функционально законченных блоков. Эта магистраль получила название системной. Первоначально это был единственный канал связи, по которому внутри ЭВМ передавалась информация между двумя и более компонентами системы. В процессе эволюции мини- и микро-ЭВМ, а также повышения быстродействия процессоров одной системной магистрали оказалось недостаточно. Однако необходимость преемственности программно-аппаратных средств серийно выпускаемых компьютеров разных поколений не позволила так просто заменить разработанные ранее системные магистрали на более быстродействующие, хотя их производительность не соответствовала производительности новых поколений процессоров. Компромиссным решением этой проблемы оказалось введение помимо основной системной магистрали ряда других, более быстродействующих магистралей, которые получили название локальных шин. В процессе эволюции ЭВМ некоторые из них потеряли свое значение и исчезли (например, VLB), другие продолжали развиваться, принимая на себя все больше функций основной системной магистрали (например, PCI). Ввиду этого в современных компьютерах помимо основной системной магистрали, имеется ряд быстродействующих локальных шин различного назначения.
Прежде чем перейти к рассмотрению основных этапов эволюции шинной архитектуры PC фирмы IBM, необходимо сделать ряд замечаний. Уже отмечалось, что в литературе встречаются различные термины для обозначения системной или общей магистрали. Это прежде всего термины: "общая шина", "системная шина", "шина ВВ" и "шина расширения". Последний термин отражает тот факт, что системная магистраль позволяет подключать к компьютеру дополнительные ПУ для расширения или изменения его возможностей, т.е. позволяет изменять конфигурацию оборудования. При этом часть устройств ВВ устанавливается непосредственно на системной (материнской) плате и не может быть заменена пользователем, а часть устройств ВВ размещается в слотах, установленных на системной магистрали. При взаимодействии с МП те и другие используют одну и ту же системную магистраль. Количество слотов расширения может быть разным. В первом IBM PC их было пять, а в PC/XT – восемь. В последующих моделях РС, имеющих быстродействующие локальные шины, их число изменялось в зависимости от конкретной конфигурации материнской платы.
При дальнейшем изложении материала будет использоваться термин шина расширения (ШР), поскольку сама системная магистраль уже в первых РС претерпела существенные изменения по сравнению с классическим вариантом структуры простейшей микроЭВМ, изображенным на рис. 13.1.
21.1.1. Локальная системная шина
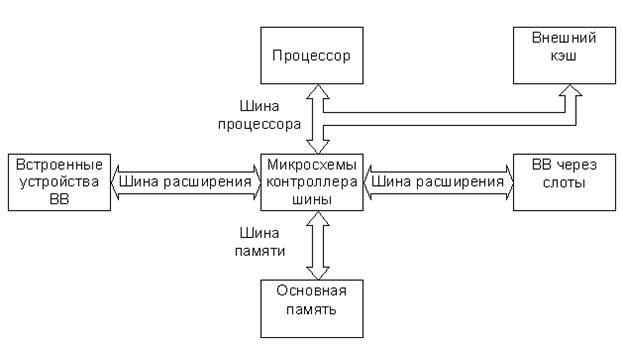
Быстродействие ШР первых IBM PC (8 МГц) вполне соответствовало быстродействию процессора I8088, на базе которого они были построены. Между тем для оптимизации процесса обмена между ОП и МП разработчики пошли на усложнение структуры РС и ввели две добавочные шины – шину процессора и шину памяти. Таким образом, обмен внутри ядра ЭВМ (т.е. между ОП и МП) осуществлялся не по ШР, а по автономной магистрали, состоящей из двух шин, которую некоторые авторы называют локальной системной шиной. Этот термин будет использоваться при дальнейшем изложении материала. Взаимодействие шины процессора и шины памяти, а также их взаимодействие с ШР осуществлялось через набор специализированных микросхем (чипсет), которые условно можно назвать контроллером шины. Очень упрощенная структура шин первых IBM PC приведена на рис. 21.1
Рис.21.1. Упрощённая структура шин первых IBM PC
Шина процессора является самой быстродействующей и предназначается для передачи данных, команд, адресов и сигналов управления между МП и контроллером шины, который связывает ее с ОП и ШР. Шина процессора первых IBM PC работала на той же тактовой частоте, что и процессор, поэтому слово данных или адрес могли быть переданы по ней в течение одного – двух периодов тактовой частоты процессора (в современных РС тактовая частота шины процессора всегда ниже тактовой частоты процессора). К этой же шине подключался внешний кэш, что позволяло вести обмен процессор – кэш с максимальной скоростью. Число физических цепей в шине процессора существенно различно для различных поколений процессоров. Так, в компьютере с процессором I80286 шина процессора имела 24 линии адреса, 16 линий данных и 12 линий сигналов управления, а в компьютере с процессором Pentium было уже 32 линии адреса, 64 линии данных и почти в три раза больше сигналов линий управления.
Скорость передачи данных по шине процессора (как и по любой другой шине) определяется произведением разрядности шины на тактовую частоту шины, деленному на число тактов, необходимое для передачи одного бита. Так, для первых моделей процессора Pentium с тактовой частотой 66 МГц, совпадающей с тактовой частотой шины процессора, максимальная скорость передачи данных составляет
При этом предполагается, что передача машинного слова происходит за один период тактовой частоты шины. Эта скорость передачи данных называется пропускной способностью шины и является максимальной. Она всегда выше средней рабочей производительности шины примерно на 25%. Таким образом, для рассмотренного примера средняя рабочая производительность шины будет составлять около 400 Мбайт/с.
Шина памяти предназначена для передачи информации между ОП и МП, а также ОП и ПУ в режиме ПДП. Информация по шине памяти передается с существенно меньшей скоростью, чем по шине процессора. Это связано с тем, что шина памяти содержит меньше линий данных. Их число определяется шириной выборки. Кроме того, как уже отмечалось, быстродействие микросхем памяти всегда отстает от быстродействия процессора, поэтому процесс передачи информации по шинам памяти и процессора (т.е. по локальной системной шине) требует обязательной синхронизации, которая осуществляется контроллером шины. Уже в первых моделях IBM PC ОП выполнялась в виде отдельных модулей (SIMM), которые размещались в специальных слотах, расположенных на шине памяти, аналогично слотам на ШР. Этот принцип сохранен и в современных PC, хотя сами слоты и модули памяти (DIMM) несколько видоизменились.
21.1.2. Шина расширения
Как уже отмечалось, ШР позволяет МП и ОП взаимодействовать с различными ПУ. За время, прошедшее после появления первых IBM PC, было разработано достаточно много вариантов ШР, поскольку появление новых быстродействующих поколений процессоров и ПУ (особенно видеосистем) требовало и более производительных ШР. Между тем одной из главных причин, сдерживающих интенсивное внедрение новых ШР, явилась их несовместимость со старыми стандартами, по которым множество фирм уже выпустили сотни тысяч единиц электронных компонентов PC и которые становились совершенно ненужными в случае использования новых ШР. В связи с этим эволюция ШР происходит достаточно медленно, без резких скачков. Ниже рассматриваются основные моменты в процессе эволюции архитектуры ШР IBM PC.
21.1.2.1. Шина расширения ISA
Шина ISA (Industrial Standard Architecture) была использована в первых IBM PC, построенных на процессоре I8088, в 1981 г. Она имела 8 линий данных, 20 линий адреса, позволяла адресовать до 1 Мбайта памяти и тактовую частоту 8 МГц. Для передачи данных требовалось от двух до восьми тактов. Эта же ШР была использована и в следующей модели – PC/XT, построенной на процессоре I8086.
Шина ISA считается достаточно простой, но фирма IBM никогда не публиковала ее полной спецификации, поэтому при создании плат адаптеров для первых IBM-совместимых компьютеров разработчикам приходилось самим разбираться в ее работе.
Появление в 1984 году процессора второго поколения I80286, оперирующего уже 16-разрядными данными, поставило проблему замены или модернизации ШР ISA. Фирма IBM пошла по второму пути, и появился компьютер PC/AT со сдвоенными слотами расширения на модернизированной шине ISA. Вторая версия шины ISA имела 16 линий данных, 24 линии адреса, позволяющих адресовать до 16 Мбайт памяти, и тактовую частоту 8 МГц. Для передачи данных также (как и в первой версии) требовалось от двух до восьми тактов. Первая и вторая версии шины ISA были полностью совместимы, а сдвоенные слоты позволяли использовать старые 8-разрядные платы адаптеров, которые можно было вставлять в переднюю часть слота. Новые же (16-разрядные) платы адаптеров вставлялись в обе части сдвоенного слота. Пропускная способность новой версии шины ISA составляла
Соответственно, пропускная способность первой версии шины ISA вдвое меньше, т.е. 4 Мбайт/с. Как уже отмечалось, это теоретическая, максимальная скорость передачи данных. Однако достаточно сложный протокол обмена существенно снижает реальную пропускную способность шины. Считается, что реальная пропускная способность ШР составляет примерно половину от максимальной.
Впоследствии с появлением 32-разрядных процессоров некоторые фирмы начали разрабатывать свои собственные версии расширения шины ISA, но сколько-нибудь заметного распространения они не получили. Дополнительные линии этих шин обычно использовались только при работе с платами расширения памяти и видеоадаптерами. Их параметры и разводки разъемов существенно отличаются от стандартных.
21.1.2.2. Шина расширения MCA
Появление 32-разрядного процессора I80386 привело к тому, что 16-разрядная ISA перестала соответствовать возможностям нового поколения МП. Фирма IBM не стала вновь модернизировать шину ISA, а разработала новую – МСА (Micro Channel Architecture). Шина МСА полностью несовместима с шиной ISA и не позволяет использовать старые платы адаптеров, однако по всем параметрам превосходит 16-разрядную шину ISA. Это достаточно дорогая шина, разработанная в пику конкурентам для своих компьютеров PS/2, начиная с модели 50. Состав управляющих сигналов, протокол и архитектура ориентированы на асинхронное функционирование шины и процессора, что снимает проблемы согласования скоростей процессора и ПУ. В процессе работы шина МСА может передавать управление отдельным подключенным к ней адаптерам (bus mastering), для реализации режима ПДП или обмена между двумя адаптерами. Все запросы на захват шины поступают в специализированное устройство, называемое арбитром шины (CACP – Central Arbitration Control Point). Арбитр обеспечивает доступ к шине всем устройствам в соответствии с системой приоритетов, предотвращая конфликты и монополизацию шины одним из них. Архитектура шины позволяет эффективно и автоматически конфигурировать все устройства программным путем (в МСА PS/2 нет переключателей ни на системной плате, ни на адаптерах). В шине МСА предусмотрено 6 типов слотов:
- 16-разрядные;
- 32-разрядные;
- 16- и 32-разрядные с дополнением для плат памяти;
- 16- и 32-разрядные с дополнениями для видеоадаптеров.
Фирма IBM хотела не просто заменить старый стандарт ISA на новый, но и сделать на этом деньги. IBM потребовала от всех производителей, желающих получить лицензию на использование новой шины МСА, заплатить за использование шины ISA во всех ранее выпущенных компьютерах. Это непомерное требование привело к разработке конкурентами фирмы IBM альтернативной шины EISA, что существенно замедлило распространение шины МСА.
Эта причина, а также полная несовместимость с массовыми ISA-устройствами привели к тому, что новая шина МСА при всей прогрессивности архитектуры (относительно ISA) не пользуется популярностью из-за узости круга пользователей МСА-устройств. Между тем МСА еще находит применения в мощных файл-серверах, где требуется обеспечить высоконадежный производительный ВВ.
21.1.2.3. Шина расширения EISA
Стандарт EISA (Extended Industry Standard Architecture) появился в 1988 году в ответ на разработку фирмой IBM шины МСА и требование ее лицензировать . Конкуренты сочли излишним платить задним числом за давно используемую шину ISA и, проигнорировав новую разработку IBM, создали свою. В этой работе приняли участие практически все ведущие изготовители компьютеров (за исключением, естественно, IBM) и крупнейшие фирмы по производству программных продуктов. Первые компьютеры с шиной EISA появились в 1989 г. Это единственное жестко стандартизированное расширение ISA до 32 бит и количеством слотов расширения до восьми.
Шина EISA разрабатывалась как преемница ISA, а не как альтернатива ей, поэтому различия между ними связаны лишь с появлением дополнительных возможностей. В шине EISA предусмотрены 32-разрядные слоты для компьютеров с процессорами 386DX и последующими моделями. Слот шины EISA построен так, что позволяет разрабатывать устройства, обладающие многими возможностями адаптеров МСА, но при этом может работать и с платами, созданными в старом стан- дарте ISA.
Несмотря на существенное увеличение числа линий в шине EISA (55 новых сигналов), 32-разрядный слот EISA выглядит почти так же, как и 16-разрядный слот ISA. Между тем слот шины EISA сдвоенный. Два ряда контактов соответствуют 16-разрядному слоту ISA, остальные расположены в глубине разъема и относятся к расширению EISA, поэтому контакты кромкового разъема старых плат ISA, не имеющих специального ключа, попадают только на верхние контакты слота.
По шине EISA можно передавать до 32 бит данных одновременно при тактовой частоте шины 8,33 МГц. В большинстве случаев передача данных осуществляется, как минимум, за два такта, хотя возможна и большая скорость передачи. Максимальную производительность шины реализует пакетный режим (burst mode) – скоростной режим пересылки пакетов данных без указания текущего адреса внутри пакета. В пакете очередные данные могут передаваться в каждом такте шины, т.е. максимальная пропускная способность шины EISA составляет