Длина пакета может достигать 1024 байта. Передача данных по "неполной шине" (при работе с 8- или 16-разрядными платами адаптеров в стандарте ISA) осуществляется соответственно с меньшими скоростями.
В шине EISA (как и в МСА) предусмотрена возможность передачи управления шиной одной из плат адаптеров (bus mastering) для реализации режима ПДП или обмена между двумя адаптерами. Работу адаптеров координирует устройство, называемое арбитром шины (CACP), которое иногда еще называют периферийным контроллером (ISP – Integrated System Peripheral). Арбитр временно предоставляет всю систему в полное распоряжение той или иной плате адаптера в соответствии с четырехуровневой системой приоритетов, расположенных в следующем порядке (по убыванию):
- регенерация систем памяти;
- прямой доступ к памяти (DMA);
- процессор;
- адаптер шины (bus-master).
В компьютерах с шиной EISA предусмотрена самонастройка прерываний и адресов расположения адаптеров. В компьютерах с шиной ISA и несколькими платами адаптеров при неправильной установке перемычек и переключателей недоразумения практически неизбежны. Программа самонастройки EISA обнаруживает возможные конфликты и конфигурирует систему так, чтобы их исключить. Однако пользователь может и сам установить желаемую конфигурацию с помощью перемычек и переключателей, что бывает необходимо, например, при поиске неисправностей.
EISA – дорогая, но оправдывающая себя архитектура, применяющаяся в многопроцессорных системах, на файл-серверах и везде, где требуется высокоэффективная, надежная ШР.
21.1.3. Локальные шины расширения
Рассмотренные выше разновидности ШР (ISA, MCA, EISA) имеют общий недостаток – сравнительно низкое быстродействие. Быстродействие и разрядность процессоров и микросхем памяти (а следовательно, и локальной системной шины) возрастали, а характеристики ШР улучшались "экстенсивно", в основном за счет увеличения их разрядности. Для ряда ПУ, быстродействие которых определяется "человеческим фактором", например, клавиатуры, «мыши», высокого быстродействия ШР и не требуется. Однако при наличии таких ПУ, как жесткие диски, видеосистемы и т.д., низкое быстродействие ШР оказывает самое непосредственное влияние на производительность системы в целом. Проблема быстродействия ШР встала наиболее остро с появлением графических пользовательских интерфейсов, таких как Windows, при работе с которыми возникает потребность в передаче и обработке очень больших массивов данных.
Достаточно очевидным решением этой проблемы является осуществление обмена между наиболее быстродействующими ПУ и ядром ЭВМ не через ШР, а через дополнительную быстродействующую магистраль, выходящую непосредственно на шину процессора. В этом случае ПУ получают доступ к самой быстродействующей шине компьютера наряду с внешним кэш. Такая конфигурация получила название локальной шины расширения или просто локальной шины (local bus). Подключение локальной шины такого типа иллюстрируется упрощенной схемой на рис. 15.2.
Первая локальная шина появилась в 1992 году в результате совместных усилий фирм Dell Computer и Intel. Хотя система оказалась поначалу весьма дорогостоящей, она продемонстрировала преимущества подключения видеосистемы к той точке, где можно было воспользоваться высоким быстродействием шины процессора. Этот первый вариант локальной шины был официально назван локальной шиной ввода/вывода I486 (I486 local bus I/O). К концу 1992 года стоимость компьютеров с локальной шиной стала снижаться, и многие фирмы начали производить аналогичные системы.
Для организации в компьютере локальной шины необязательно устанавливать слоты расширения: адаптер устройства, использующего локальную шину, можно смонтировать непосредственно на системной плате. В первых компьютерах с локальной шиной использовался именно такой вариант.
Локальная шина не заменяла собой прежние стандарты, а дополняла их. Основными шинами расширения в компьютере по-прежнему оставались ISA или EISA, но к ним добавлялся один или несколько слотов локальной шины. При этом сохранялась совместимость со старыми платами расширения, а быстродействующие адаптеры устанавливались в слоты локальной шины, реализуя при этом все свои возможности.
Компьютеры с локальной шиной стали особенно популярны среди пользователей Windows и OS/2, поскольку в слоты локальной шины можно было установить 32-разрядные платы так называемых видеоускорителей, которые значительно увеличивали быстродействие системы при работе с графическими изображениями. Производительность Windows и OS/2 существенно снижалась из-за ограничений, существующих даже в лучших платах VGA, подключаемых к шинам ISA или EISA. Обычные платы VGA могли выводить на экран до 600 000 точек в секунду, в то время как видеоадаптеры, соединенные с локальной шиной, по утверждениям изготовителей, за то же время выводили 50-60 млн. точек. В реальных условиях быстродействие, конечно, ниже, но разница все равно оказывалась существенной.
21.1.3.1. Локальная шина VESA (VLB)
В своем первоначальном варианте слоты локальной шины использовались почти исключительно для установки видеоадаптеров. К концу 1992 года было разработано несколько локальных шин. Исключительными правами на них обладали только фирмы-изготовители. Отсутствие стандартов сдерживало распространение локальных шин.
Приемлемое решение предложила ассоциация VESA (Video Electronics Standards Association), которая разработала конструкцию стандартной локальной шины, названной VESA Local Bus или просто VLB. Как и в первых конструкциях локальной шины, через слот VLB можно было получить непосредственный доступ к системной памяти, а ее быстродействие равнялось быстродействию самого процессора. По VLB можно было производить 32-разрядный обмен данными между МП и совместимым видеоадаптером, т.е. ее разрядность соответствовала разрядности данных процессора I80486. Максимальная пропускная способность VLB составляла 132 Мбайт/с.
Использование VLB позволяло изготовителям интерфейсных плат жестких дисков устранить еще одно ограничение: низкую скорость обмена данными между жестким диском и МП. Обычный 16-разрядный IDE-накопитель и его интерфейс могут обеспечить скорость передачи данных не выше 5 Мбайт/с, а адаптеры жесткого диска для VLB позволяли увеличить ее до 8 Мбайт/с. В реальных условиях пропускная способность этих адаптеров несколько ниже, тем не менее VLB существенно повышала быстродействие накопителей на жестких дисках.
VLB – стандартизованная 32-битная шина расширения, практически представляющая собой линии шины процессора I80486, выведенные на дополнительные слоты системной (материнской) платы. Конструктивно шина VLB выполнена в виде добавочных слотов, расположенных позади уже существующих системных слотов ШР ISA-16, EISA, МСА (по продольной оси) вблизи процессора. Таким образом, платы адаптеров одновременно вставлялись и в слоты ШР, и в слоты VLB. Слоты шины VLB обычно использовались для подключения графического адаптера и адаптера жесткого диска. Однако существуют системные платы, которые имеют встроенный графический и дисковый интерфейсы с шиной VLB, но сами слоты VLB отсутствуют. С точки зрения надежности и совместимости такой вариант наиболее оптимален, поскольку проблемы совместимости адаптеров и согласования нагрузок для шины VLB стоят очень остро.
При всех своих достоинствах шина VLB имеет ряд недостатков, основными из которых являются:
· Ориентация на процессор I80486. Уже отмечалось, что VLB является по существу продолжением шины процессора I80486, хотя возможно ее использование и с процессором I80386. Для процессоров Pentium была разработана спецификация 2.0 шины VLB, в которой число линий данных было увеличено до 64. Кроме того, спецификация включала аппаратный преобразователь шины Pentium в VLB. Однако дальнейшего развития эта версия не получила.
· Ограниченное быстродействие. Стандарт VLB допускает работу с тактовыми частотами до 66 МГц, но частотные характеристики разъемов VLB ограничивают ее на уровне 50 МГц. Если в компьютере установлен переключатель для повышения тактовой частоты процессора (например, для увеличения ее в два раза), то VLB продолжает использовать в качестве тактовой основную частоту МП.
· Схемотехнические ограничения. К качеству импульсных сигналов, передаваемых по шине процессора, предъявляются очень жесткие требования, причем они могут быть разными для различных типов ИС процессоров. Соблюсти их можно только при определенных параметрах нагрузки каждой из линий шины, т.е. к шине процессора должен быть подключен вполне конкретный "набор" элементов, например внешний кэш и ИС контроллера шины. При добавлении новых плат нагрузка на линии шины возрастает. Если не принять соответствующих мер, это может привести к искажениям импульсных сигналов ("звонам", завалу фронтов, изменениям логических уровней), а в результате – к потерям данных, нарушениям синхронизации и другим сбоям как самого процессора, так и адаптеров VLB.
· Ограничение количества плат. По указанным в предыдущем пункте соображениям количество одновременно используемых адаптеров VLB ограничено. Стандарт VLB допускает одновременную установку трех плат, но это возможно только при тактовой частоте до 40 МГц и малой нагрузке на шину. При ее увеличении и повышении тактовой частоты возможное количество адаптеров уменьшается. При частоте 50 МГц и большой нагрузке разрешается устанавливать всего одну плату VLB.
Указанные недостатки оказались настолько существенными, что в современных IBM PC шина VLB не используется.
21.1.3.2. Локальная шина PCI
В начале 1992 года на фирме Intel была организована группа, перед которой была поставлена задача разработать новую шину. В результате в июне 1992 года появилась шина PCI (Peripheral Component Interconnect bus), в апреле 1993 она была модернизирована. Ее создатели отказались от традиционной концепции, введя еще одну шину между МП и обычной шиной ВВ. Вместо того чтобы подключаться непосредственно к шине процессора, чувствительной к подобным вмешательствам (о чем сказано выше), новый комплект ИС (чипсет) позволял создавать новую архитектуру шин IBM PC. Первые компьютеры с шиной PCI появились в середине 1993 года, и вскоре она стала неотъемлемой частью компьютеров класса high end.
Новая локальная шина существенно превосходила своих предшественниц по функциональным возможностям, производительности, надежности. Наличие чипсета делает шину PCI процессорно-независимой, что позволяет ее использовать с платформами не только на Intel-подобных процессорах. Это является очевидным преимуществом с точки зрения производителей плат расширения (адаптеров), которые стараются избегать разных версий одной и той же платы. Кроме того, наличие чипсета позволяет шине PCI работать параллельно с шиной процессора, не обращаясь к ней со своими запросами. Это даёт возможность процессору работать с данными, находящимися во внешнем кэш, в то время как по шине PCI может происходить обмен между ПУ и ОП в режиме ПДП (DMA).
Первоначально в IBM PC использовалась только версия 2.0 шины PCI, поддерживаемая чипсетами малой интеграции (5-6 микросхем) типа Neptun или Saturn. Однако с появлением чипсетов большей интеграции типа Intel 430 (Triton), Intel 440, Intel 810 в IBM PC стала использоваться новая версия шины PCI-2.1, которая вскоре была заменена версией PCI-2.2 (например, чипсет Intel 815). Эта версия используется и в настоящее время (чипсеты Intel 850, Intel 860, VIA KT 266 для процессоров AMD и др.). Версии 2.0, 2.1 и 2.2 имеют обратную совместимость на тактовой частоте 33 МГц. Основные возможности шины PCI следующие:
· Синхронный 32- или 64-разрядный обмен данными. Для уменьшения числа линий шины и контактов слота (а следовательно, и стоимости) используется мультиплексирование ША и ШД, т.е. для передачи адресов и данных используются одни и те же линии шины. Поддержка режима пакетных передач (linear burst), позволяющего не расходовать время шины на установку адреса каждого элемента данных при обмене блоком информации. Адрес автоматически модифицируется чипсетом для каждого последующего элемента данных. Это существенно повышает производительность шины при обмене ядра ЭВМ с видеосистемами и жесткими дисками большими блоками информации.
· Тактовая частота шины 33 МГц или 66 МГц (только для версий выше 2.0). Это позволяет обеспечить следующие максимальные пропускные способности шины с использованием пакетного режима:
ü 132 Мбайт/с при 32-бита/33 МГц;
ü 264 Мбайт/с при 32-бита/66 МГц;
ü 264 Мбайт/с при 64-бита/33 МГц;
ü 528 Мбайт/с при 64-бита/66 МГц.
· Работа на тактовой частоте 66 МГц возможна, если все адаптеры шины поддерживают эту частоту.
· Поддержка внешнего кэш с обратной и сквозной записью (write back и write through).
· Автоматическое конфигурирование карт расширения при включении питания.
· Полная поддержка режима multiply bus master, при котором на шине одновременно могут работать, например, несколько контроллеров жестких дисков.
· Установка запросов прерывания осуществляется по уровню (а не по фронту, как в шинах ISA и VLB), что делает систему прерывания более надежной и позволяет использовать одну линию прерывания для обслуживания нескольких ПУ.
· Спецификация шины позволяет комбинировать до восьми функций на одной плате (например, видео + звук + и т.д.).
· Шина позволяет устанавливать до четырех слотов расширения, конструкция которых существенно отличается от конструкции слотов шины ISA (EISA). Для увеличения числа подключаемых устройств (необходимость в этом возникает обычно в мощных серверных платформах) предусмотрено использование двух и более шин PCI, соединяемых одноранговыми мостами (peer-to-peer bridge). Следует отметить, что с разработкой нового поколения чипсетов (например, Intel 850, Intel 845, Intel 815, VIA KT 266 и др.) число слотов расширения, устанавливаемых на одной шине PCI, увеличилось до 5-6.
· Шина PCI имеет версии с питанием 5 В и 3.3 В. Разъемы для плат с питанием 5 В и 3.3 В различаются расположением ключей. Существуют и универсальные платы с переключаемым напряжением питания. Тактовая частота 66 МГц поддерживается только логикой питания 3.3 В.
· Наличие в устройстве шины PCI таймера, используемого для определения максимального интервала времени, в течение которого устройство может занимать шину при передаче блока информации.
Рассматривая возможности шины PCI, необходимо иметь в виду, что чипсет является не просто согласующим элементом между различными шинами PC. Он основное связующее звено между всеми компонентами системной платы. Набор решаемых им задач очень обширен и во многом определяет характеристики конкретной модели компьютера, поэтому рассмотрение функциональных возможностей PCI-архитектуры в отрыве от функций чипсета весьма затруднительно. Так, например, возможность выполнения обмена данными между процессором и ОП одновременно с обменом между другими устройствами шины PCI (concurrent PCI transferring), предусмотренная в спецификации шины, реализована не во всех типах чипсетов.
В общем случае чипсет можно разделить на две функциональные части. Одна часть чипсета обеспечивает взаимодействие шины PCI с локальной системной шиной (т.е. с шиной процессора и шиной памяти). Эту часть принято называть главным мостом (host bridge), северным мостом (northbridge) или контроллером-концентратором памяти (Memory Controller Hub, MCH). Вторая часть обеспечивает взаимодействие шины PCI с жёстким диском, картами PSI и низкоскоростными интерфейсами, типа ШР ISA, PCI Express, интерфейсами IDE, SATA, USB и т.п. Эту функциональную часть чипсета принято называть мостом PIIX (PCI, IDE, ISA Xcelerator bridge), южным мостом ( southbridge) или контроллером-концентратором ввода-вывода (I/O Controller Hub, ICH). Такому функциональному делению соответствует и разделение набора задач, решаемых чипсетом. Чаще всего чипсет современных материнских плат состоит из двух основных микросхем (MCH и ICH), но иногда их объёдиняют в одну микросхему (чип) и называют системным контроллером-концентратором (System Controller Hub, SCH).
В функции главного моста входит решение следующих задач:
· Обслуживание управляющих и конфигурационных сигналов процессора.
· Мультиплексирование адреса и формирование управляющих сигналов динамической памяти (ОП), связь шины данных памяти с локальной шиной.
· Формирование управляющих сигналов внешнего кэш, сравнение его тегов с текущим адресом обращения на локальной шине (т.е. выполнение функций контроллера кэш-памяти).
· Обеспечение когерентности (согласования) данных в обоих уровнях кэш-памяти и ОП при обращении как со стороны процессора, так и контроллеров устройств шины PCI.
· Связь мультиплексированной шины адреса и данных шины PCI с шиной процессора и шиной ОП.
· Формирование управляющих сигналов шины PCI, арбитраж контроллеров устройств шины (т.е. выполнение функций арбитра шины PCI).
· Поддержка магистрального интерфейса AGP (Accelerated Graphic Port), предназначенного для подключения мощных графических адаптеров.
Мост PIIX также является многофункциональным устройством и решает следующие задачи:
· Организацию моста между шинами PCI b жёстким диском, картами PSI и низкоскоростными интерфейсами, типа ШР ISA, PCI Express, интерфейсами IDE, SATA, USB и т.п. с согласованием частот синхронизации этих шин.
· Реализацию стандартных системных средств ВВ – контроллеров прерываний, контроллеров ПДП, системного таймера, канала управления динамиком, логики немаскируемого прерывания и т.п.
· Коммутацию линий запросов прерывания шин PCI и других шин, а также встроенной периферии на линии запросов контроллеров прерываний, управление их чувствительностью (по перепаду или уровню), обслуживание прерывания от сопроцессора.
· Коммутацию каналов ПДП.
· Поддержку режимов энергосбережения.
· Реализацию моста с внутренней шиной X-Bus, используемой для подключения микросхем контроллера клавиатуры, BIOS, CMOS RTC, контроллеров гибких дисков и интерфейсных портов.
Микросхемы чипсета при инициализации во время начального тестирования (POST) программируются по многим параметрам, основная часть которых находится в BIOS. Таким образом, системные платы, выполненные даже на одном и том же чипсете, могут иметь различные производительности и диапазоны поддерживаемых устанавливаемых компонентов (процессоров, DRAM, кэш). Соответственно и шины PCI, реализованные в различных моделях РС (особенно у разных производителей), могут несколько отличаться по своим функциональным возможностям.
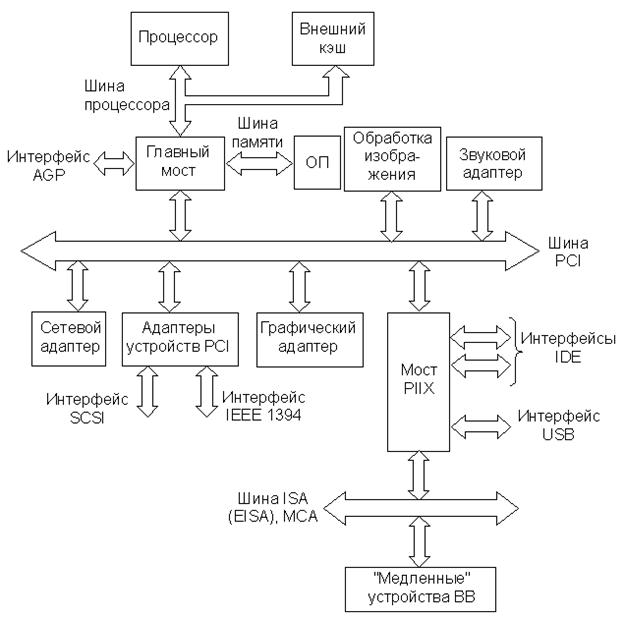
Очень упрощенная структура шин IBM РС (с учетом функций чипсета) при наличии шины PCI представлена на рис. 21.3.
Обозначенные на схеме интерфейсы для подключения высокоскоростных ПУ (AGP, SCSI, IEEE 1394, IDE, USB) в настоящем разделе не рассматриваются. Отметим только, что многие модели современных IBM PC имеют еще ряд других (не обозначены на схеме) специализированных интерфейсов для подключения разнообразных типов ПУ.
Для устройств промышленного назначения в начале 1995 года был принят стандарт Compact PCI, разработанный на основе версии PCI 2.1. Шины Compact PCI и PCI имеют электрическую совместимость и одинаковые протоколы обмена по шине, хотя и имеют некоторые отличия в механизме автоконфигурации системы. В отличие от стандарта PCI стандарт Compact PCI позволяет устанавливать на одной шине до восьми слотов расширения, конструкция которых существенно отличается от конструкции слотов PCI и предназначена для работы компьютера в тяжелых условиях – пыль, вибрация, влажность и т.д.
В заключение следует отметить, что появление шины PCI положило начало полному вытеснению из РС фирмы IBM, в общем-то, устаревшей ШР ISA. В настоящее время шина ISA оказалась практически вытесненной из архитектуры IBM PC и все ее функции выполняет шина PCI, которая из локальной превратилась в основную ШР современных IBM PC.
Рис.21.3. Упрощённая структура шин IBM PC
21.2. Современные схемы поддержки МП на системных платах
В данном пункте кратко рассмотрим для примера три чипсета разных фирм, используемые при построении системных плат по состоянию на 2011 год. Архитектура и функции чипсетов бурно прогрессируют, но общие решения, представленные на рис.15.3, пока остаются актуальными. Конструктивно, часть функций может быть переложена на процессор, или оба моста могут быть реализованы в одной микросхеме, но в большинстве случаев чипсет состоит из двух микросхем – северного моста и южного.
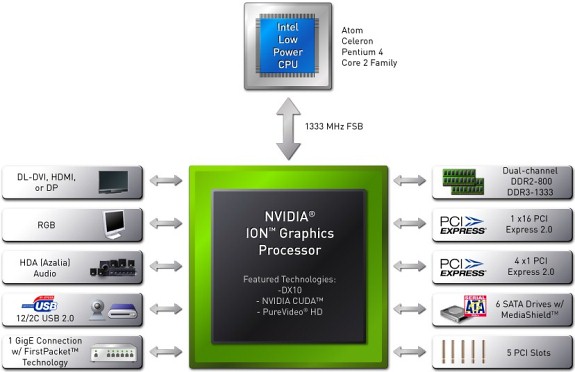
21.2.1. Чипсет GeForce 9300/9400 фирмы NVIDIA
Функциональная схема чипсета GeForce 9300/9400 ( другое название ION) приведена на рис.21.4.
Платы на Ion, предназначенны для создания компактных систем и нетбуков. Очевидно, что по поддержке периферии все современные решения в таких условиях будут равны, а если кто-то и окажется не в состоянии обеспечить полноскоростной слот PCI Express 2.0 x16, то покупатели неттопа на него за это не сильно обидятся. Важные особенности чипсетов в этой нише таковы: поддержка процессоров, поддержка памяти (тип и максимальный объем; количество каналов тоже может играть роль ввиду активного обращения графического ядра к памяти) и, конечно же, встроенная графика.
ION имеет полную аппаратную поддержку воспроизведения HD-видео и умеет выводить по HDMI сжатый или несжатый 8-канальный звук, что делает его крайне привлекательным для использования в медиацентрах.
21.2.2. Чипсет AMD 890FX + SB850
Функциональная схема чипсета AMD 890FX + SB850 приведена на рис.21.5. 890FX – микросхема северного моста, SB850 – микросхема южного моста.
Спецификации чипсета 890FX+SB850 выглядят следующим образом:
поддержка всех процессоров для Socket AM3 (Phenom II, Athlon II, Sempron 140);
до 4 портов PCIEx16 (PCI-E 2.0), при установке двух видеокарт в режиме CrossFire обеспечивается полноскоростной режим (x16+x16), при установке большего числа видеокарт, линии автоматически перераспределяются по схеме x16+x8+x8 или x8+x8+x8+x8;
до 8 портов PCIEx1 (полноскоростные PCI-E 2.0, из которых шесть реализуются северным мостом, два — южным);
6 портов Serial ATA III на 6 устройств SATA 3.0, с поддержкой режима AHCI и функций вроде NCQ, с возможностью индивидуального отключения, с поддержкой eSATA и разветвителей портов;
возможность организации RAID-массива уровней 0, 1, 0+1 (10) и 5;
до 4 слотов PCI;
14 устройств USB 2.0 (на двух хост-контроллерах EHCI) с возможностью индивидуального отключения;
MAC-контроллер Gigabit Ethernet;
High Definition Audio (7.1);
порт PATA с поддержкой двух устройств PATA/133;
обвязка для низкоскоростной и устаревшей периферии.
Рис.21.5. Функциональная схема чипсета AMD 890FX
21.2.3. Чипсет Intel Z68 для платформы Socket 1155
Функциональные возможности Intel Z68 выглядят следующим образом (рис.21.6):
поддержка всех новых процессоров на ядре Sandy Bridge при подключении к этим процессорам по шине DMI 2.0 (с пропускной способностью ≈4 ГБ/с);
интерфейс FDI для получения полностью отрисованной картинки экрана от процессора и блок вывода этой картинки на устройство(-а) отображения;
до 8 портов PCIEx1 (полноценные PCI-E 2.0);
2 порта Serial ATA III на 2 устройства SATA600 и 4 порта Serial ATA II на 4 устройства SATA300, с поддержкой режима AHCI и функций вроде NCQ, с возможностью индивидуального отключения, с поддержкой eSATA и разветвителей портов;
возможность организации RAID-массива уровней 0, 1, 0+1 (10) и 5 с функцией Matrix RAID (один набор дисков может использоваться сразу в нескольких режимах RAID – например, на двух дисках можно организовать RAID 0 и RAID 1, под каждый массив будет выделена своя часть диска);
поддержка технологии Smart Response;
14 устройств USB 2.0 (на двух хост-контроллерах EHCI) с возможностью индивидуального отключения;
MAC-контроллер Gigabit Ethernet и специальный интерфейс (LCI/GLCI) для подключения PHY-контроллера (i82579 для реализации Gigabit Ethernet, i82562 для реализации Fast Ethernet);
High Definition Audio (7.1);
обвязка для низкоскоростной и устаревшей периферии, прочее.
Z68 объединил достоинства чипсетов серии 6x, поддерживая одновременно встроенную графику новых процессоров (вывод картинки, формируемой видеоядром и пересылаемой по специальному интерфейсу FDI, на дисплей через набор видеовыходов на любой вкус: HDMI 1.4, Display Port, DVI, аналоговый d-Sub; два независимых потока), работу двух видеокарт в режиме x8+x8,
Тема 16. Некоторые вопросы развития архитектуры ЭВМ
Лекция 22
Ранее отмечалось, что в процессе эволюции классическая структура ЭВМ претерпела некоторые изменения, в частности, изменилось устройство памяти, организация которого стала иерархической. Однако это далеко не все изменения, которые произошли с классической пятиблочной структурой ЭВМ и ее основными принципами функционирования, сформулированными фон Нейманом.
Ниже очень коротко рассматриваются некоторые элементы архитектуры современных ЭВМ четвертого поколения, которые выходят за рамки классических структур и принципов функционирования первых ЭВМ различных классов. Материал раздела, по возможности, иллюстрируется примерами построения упрощенных элементов вычислительных устройств на базе процессора I80386, структуры которых достаточно прозрачны.
22.1. Теги и дескрипторы. Самоопределяемые данные
Одним из эффективных средств совершенствования архитектуры современных ЭВМ является теговая организация памяти, при которой каждое хранящееся в памяти или регистре слово снабжается тегом. Тег определяет тип данных – целое число, ЧПЗ, десятичное число, адрес, строку символов, дескриптор и т.д. В поле тега обычно указывают не только тип, но и длину (формат) и некоторые другие его параметры. Теги формируются компилятором. Формат данных, хранимых в памяти, при этом имеет вид, изображенный на рис. 22.1.
Рис.22.1. Теговая организация памяти
Наличие тегов придает хранящимся в машине данным свойство самоопределяемости. Это принципиальная особенность в функционировании ЭВМ.
Следует отметить, что ЭВМ с теговой памятью выходят за рамки модели вычислительной машины фон Неймана именно в результате самоопределяемости данных. Классическая модель фон Неймана исходит из того, что тип (характер) данного, хранящегося в памяти, определяется только в контексте выполнения программы, а точнее, команды, использующей данное в качестве операнда. В обычных ЭВМ, соответствующих классической модели фон Неймана, тип данных-операндов и их формат задаются кодом операции команды, а в ряде случаев размер (формат) операндов определяется специальными полями команды.
Например, в IBM-360/370 команда десятичное сложение самим своим кодом операции определяла, что адресуемые ею операнды являются десятичными числами. Специальные четырехразрядные поля в этой команде задавали число десятичных цифр в 1-м и 2-м операндах. Таким образом, в IBM-360/370 имелось 256 кодов только одной команды десятичное сложение.
Теговая организация памяти позволяет достигнуть инвариантности команд относительно типов и форматов операндов, что приводит к значительному сокращению набора команд машины. Это упрощает и делает более регулярной структуру процессора. Кроме того, такая организация памяти дает еще ряд преимуществ, а именно: