Напомним, что Глобальный каталог (global catalog) — это перечень всех объектов леса Active Directory. По умолчанию, контроллеры домена содержат только информацию об объектах своего домена. Сервер Глобального каталога является контроллером домена, в котором содержится информация о каждом объекте (хотя и не обо всех атрибутах этих объектов), находящемся в данном лесу.
Сервер глобального каталога выполняет две очень важные функции:
поиск объектов в масштабах всего леса (клиенты могут обращаться к глобальному каталогу с запросами на поиск объектов по определенным значениям атрибутов; использование сервера глобального каталога — единственный способ осуществлять поиск объектов по всему лесу);
аутентификация пользователей (сервер глобального каталога предоставляет информацию о членстве пользователя в универсальных группах, universal groups; поскольку универсальные группы со списками входящих в них пользователей хранятся только на серверах глобального каталога, аутентификация пользователей, входящих в такие группы, возможна только при участии сервера глобального каталога).
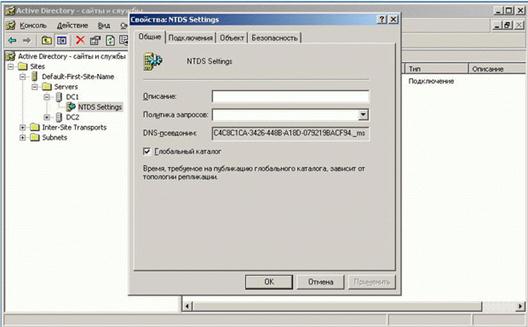
По умолчанию самый первый контроллер домена в лесе является сервером глобального каталога. Однако администратор сети может назначить любой контроллер домена сервером глобального каталога. Это делается с помощью административной консоли "Active Directory – сайты и службы", в свойствах узла "NTDS Settings" выбранного контроллера (рис. 6.41):
Для эффективной работы службы каталогов Active Directory необходимо, чтобы в каждом сайте AD был либо сервер глобального каталога, либо контроллер домена, кэширующий у себя списки членов универсальных групп. Кэширование универсальных групп также настраивается в консоли "Active Directory – сайты и службы" в свойствах узла "NTDS Settings" для каждого сайта Active Directory. Для включения кэширования нужно поставить галочку у поля "Разрешить кэширование членства в универсальных группах" и указать, из какого сайта данный сайт будет получать списки универсальных групп в поле "Обновлять кэш из:" (рис. 6.42):
Рис. 6.42.
Сортировкой называется процесс расположения элементов массива в порядке убывания (возрастания) из значений. Пример : Алгоритм выполнения сортировки называется методом сортировки. К наиболее распространенным методам относятся:
Простым выбором
Простой перестановкой
Пузырьковый метод
На каждом шаге находится минимальный (максимальный) неотсортированной части. Он меняется с первым элементом в неотсортированной части, после чего отсортированная часть увеличивается на один элемент. На первом шаге весь массив считается неотсортированным. Сортировка заканчивается за (n-1) шаг. Пример: 241795
На каждом шаге массив делится на отсортированную и неотсортированную части. Первый элемент из неотсортированной части сравнивается с каждым элементом отсортированной части, начиная с последнего. Если найден элемент, больший сравниваемого, то они меняются местами. Шаг закончен когда просмотрены все отсортированные элементы. Сортировка закончена когда просмотрены все неосортированные элементы. На первом шаге отсортироованным считается первый элемент. Пример: 2 | 41795
На каждом шаге сравниваются все соседние элементы. В случае необходимости они меняются местами. Сортировка считается законченной за nn действий или на шаге, когда не выполнено ни одной перестановки. Пример: 241795
Переменная типа строка предназначена для обработки цепочек символов. Каждый символ является элементом типа char. Строки могут вводиться с помощью стандартных операторов read/readln и выводиться стандартными операторами write/writeln. Объявляются переменные типа строка в разделе var. При объявлении указываются идентификатор переменной, зарезервированное слово string и, в квадратных скобках, целое число - максимально возможная длина строки. Наибольшая длина строки составляет 256 символов. Если переменная имеет значение с максимальной длиной строки, то при объявлении переменной ограничиваются зарезервированным словом. Пример: var identificator_1: string; identificator_2: string[20]; identificator_3: string[255]; Значение строкового типа также как и значение типа char при записи внутри программы заключаются в апострофы. Пример: identificator_1:='это - компьютер'; identificator_1[1]:='э'; Простейшая операция которую Pascal позволяет выполнить со строками - это операция конкатенации, или сцепления, или объединения строк в операторе присваивания. Операция записывается с помощью знака "+". Пример: identificator_1:='это' + '-' + 'компьютер';
Для обработки строковых данных используется ряд встроенных функций: 1) Length (L) - определяет длину строки, являющуюся значением переменной L. Значение, возвращаемое этой функцией является целочисленным и отображает реальную длину строки, т.е. может не совпадать со значением длины строки, объявленным при декларации. Пример 1: var L: string[15]; A: byte; Begin L:='Урок'; A:=length(L); Write(A); End.
Пример 2: Begin write(length('Урок')); End. 2) Upcase (C) - преобразует любой символ в прописной. Переменная C может иметь значение типа char, либо являться одним элементом из строки. Русские символы обрабатываться этой функцией не могут. 3) Copy (L, A, B) - позволяет копировать фрагмент строки являющейся значением переменной L, начиная с позиции A в количестве B, где A и B - целые числа, причем значение A не превышает длины строки L, а значение B не превышает (длина строки L - A). Если эти правила нарушены, то ошибки компиляции не произойдет, но возможно совершение логической ошибки в программе. 4) Pos (L, M) - возвращает результат целочисленного типа, являющийся номером позиции, с которой строка L входит в строку M. Если строки L нет в строке M, то результат - 0. 5) Insert (L, M, A) - вставляет строку L в строку M, начиная с позиции с номером A. Фактически, вставка производится перед указанной позицией. 6) Delete (L, A, B) - удаляет из строки L B символов, начиная с позиции A. Если номера позиций в функциях Insert и Delete не соответствуют длине рассматриваемых строк, то произойдет ошибка компиляции. Пример 1: переставить буквы введенного слова в противоположном порядке. Например, ввели "урок", получили - "кору": Пример 2: изменить введенное значение строковой переменной на слово, записанное теми же символами, но в обратном порядке. Новую переменную не использовать: Пример 3: сравнение слов в Pascal.
Program slovo; Var word1, word2: string[60]; Begin readln(word1); readln(word2); if word1 > word2 then writeln ('>') else begin if word1 = word2 then writeln ('=') else writeln ('<'); End.
Множества.
Множеством называется упорядоченная совокупность данных одного типа, записанных без повторений и отсортированных по возрастанию. Максимальное множество состоит из 256 элементов. Для объявления множеств используется зарезервированное слово set, за которым указывается тип элемента множества или сами элементы. Пример: type A: 5..9; var B: set of A; C: set of char; D: set of '1'..'5'; Внутри программы элементы множества записываются в квадратных скобках. Для перечисления используется интервальный, перечисляемый типы или их комбинации. Пример: e:['A'..'Q', 'T', 'x'..'z'] Элементы множеств нельзя вводить с клавиатуры и выводить стандартными операторами, т.к. элементы множества относятся к перечисляемому типу. Над множествами можно выполнять следующие операции:
Объединение (+). Результатом будет множество, состоящее из всех элементов первого и второго множеств без повтора: Пример: [1..3, 6, 9..11] + [2..4, 7, 10..12] = [1, 2, 3, 4, 6, 7, 9, 10, 11, 12] = [1..4, 6, 7, 9..12]
Пересечение (*). Результатом будет множество, состоящее из тех элементов, которые присутствуют как в первом, так и во втором множествах. Пример: [1..3, 6, 9..11] * [2..4, 7, 10..12] = [2, 3, 10, 11]
Разность двух множеств (-). Результатом будет множество, состоящее из тех элементов первого множества, которых нет во втором. Пример: [1..3, 6, 9..11] - [2..4, 7, 10..12] = [1, 6, 9]
Операция in - проверяет принадлежность элемента множеству. Результатом операции будет логическое значение (true или false). Пример: [2] in [1..4] (true) [7] in [1..7] (false)
Сравнение. Равными называются множества, состоящие из одинаковых элементов. Большим будет множество, у которого больше элементов. Из двух множеств с равным количеством элементов большим будет то, первое несовпадающее значение которого больше.
Пример: из введенной последовательности символов, признаком конца которой является '0', сформировать множество заглавных и строчных латинских букв. var c: char; a, pl: set of 'A'..'Z'; b, sl: set of 'a'..'z'; i: char; Begin pl:= [0]; sl:= [0]; repeat read(c); if [c] in a then pl:=pl+[c]; if [c] in b then sl:=sl+[c]; until [c]='0'; for i:='A' to 'Z' do if [i] in pl then write(i:3); for i:='a' to 'z' do if [i] in sl then write(i:3); End.
Записи.
Пример: Для реализации объединения данных разного типа в языке Pascal существует специальная структура - запись. Объявление записи начинается с зарезервированного слова record, за которым перечисляются имена и типы всех составляющих записей ее полей. Заканчивается объявление скобкой end. Пример: type karta = record family: string[20]; name: string[15]; age: integer; end; При обращении к записи в программе указывается имя записи и через точку имя поля. Пример: karta.family:='Иванов'; karta.name:='Иван'; karta.age:=20; Для упрощения обращения к записи может быть использован оператор работы со структурой with. Пример: with karta do begin family:='Иванов'; name:='Иван'; age:=20; end; Полями записи наряду с простыми типами могут быть и данные структурированных типов, например, массивы или записи. Пример 1: var z: record pole1: string; pole2: array [1..10] of byte; end; Begin for i:=1 to 10 do read (z.pole2[i]); End.
Пример 2: объявите запись, содержащую сведения о фамилии, дате рождения и адресе студента. var student: record fam: string[15]; data: record day: 1..31; mes: 1..12; year: integer; end; adres: record street: string[15]; dom: byte; kvart: byte; end; end; Begin with student do begin fam:= 'Иванов'; with data do begin day:= 30; mes:= 4; year:= 1987; end; with adres do begin street:= 'Туполева'; dom:= 22; kvart:= 154; end; end; End. Для использования в программе набора с одинаковыми полями используются массивы записей. Пример: объявить массив из десяти записей. 1 вариант решения: var A: array [1..10] of record fam: string; name: string; end; 2 вариант решения: type student = record fam: string; name: string; end; var A: array [1..10] of student;