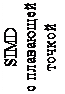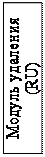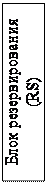Процессоры семейства P6 представляют собой реализацию наиболее современных процессоров в семействе IA: Pentium Pro, Pentium II, Celeron, Pentium III. В проектировании процессоров семейства P6 одной из главных задач было значительное увеличение производительности процессоров Pentium благодаря улучшению архитектуры. Принципиальное отличие этого семейства состоит в том, что P6 преобразует команды x86 во внутренние RISC-подобные команды, называемые микрокомандами (micro-ops). Микрокод – это элементарная инструкция, которая выполняется одним из шести блоков процессора параллельно. Это позволяет устранить многие ограничения, свойственные набору команд x86, такие как нерегулярность кодирования команд, операции целочисленных пересылок «регистр – память» и переменная длина непосредственных операндов. Процессоры семейства P6 имеют трехходовую суперскалярную конвейерную архитектуру. Термин “трехходовая суперскалярная” означает, что, используя технику параллельной обработки, процессор может в среднем за один такт декодировать, диспетчеризировать и выполнить три команды. На рис. 2.11 показан обобщенный вид конвейера.
Рис 2.11. Функциональная схема процессора типа P6
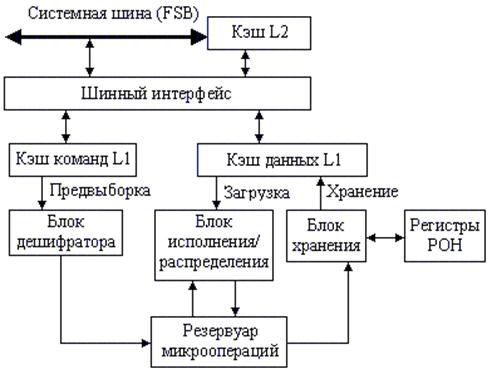
Для постоянного поступления команд и данных конвейер процессора P6 включает два уровня кэша. Кэш L1 состоит из кэша команд и кэша данных, каждый емкостью по 8 и более Кб, они вплотную присоединены к конвейеру. Кэш L2 может быть 256 Кб и более. Это статическое ОЗУ, которое присоединено к ядру процессора через 64-битную шину кэша.
Центральная часть архитектуры семейства процессоров P6 это введение механизма “динамического выполнения”. Динамическое выполнение включает 3 концепции обработки информации:
- глубокое прогнозирование ветвлений;
- динамический анализ потока данных;
- прогностическое выполнение.
Прогнозирование ветвлений – это концепция, которая позволяет процессору с опережением декодировать команды ветвлений для полного использования конвейеров. В семействе процессоров P6 блок выборки/декодирования команд использует оптимизированный алгоритм прогнозирования ветвлений для предсказания направления потока команд в многоуровневом ветвлении, вызовах процедур и возвратах из них.
В семействе процессоров P6 блок диспетчеризации/выполнения команд может одновременно следить за многими командами и выполнять их в порядке, который оптимизирует множественное выполнение до тех пор, пока сохраняется целостность данных. Такой режим держит занятым блок выполнения команд даже тогда, когда происходит кэш-промах, и при зависимости данных в командах.
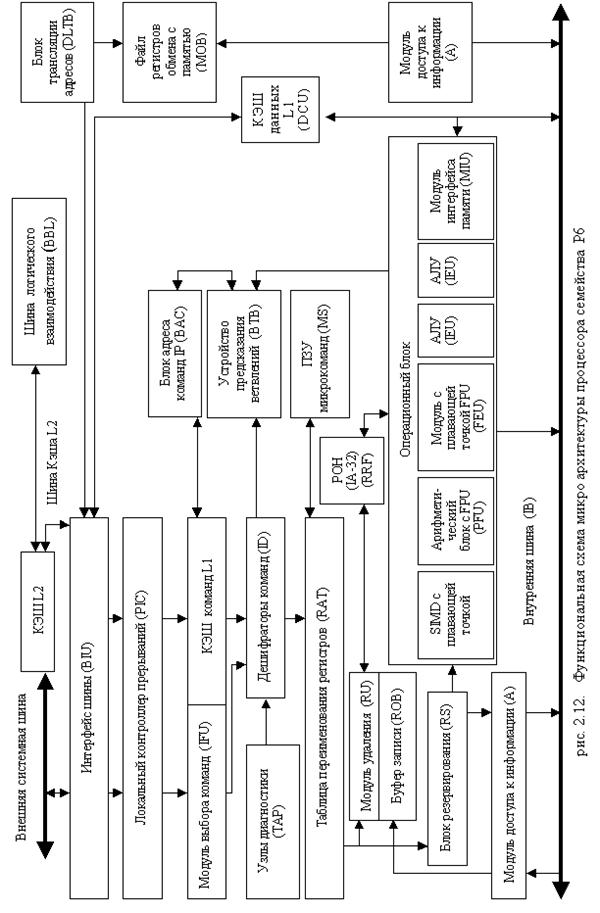
Прогностическое выполнение – это возможность процессора выполнять команды впереди счетчика команд, но фиксировать результаты в порядке поступления команд. Для обеспечения возможности прогностического выполнения в микроархитектуре семейства процессоров P6 разделяется диспетчеризация и выполнение команд. Процессорные блоки диспетчеризации/выполнения используют анализ потока данных для выполнения всех доступных команд в накопителе команд и временно сохраняют результаты в буферных регистрах. Блок сброса ищет в накопителе команд выполненные команды, в которых нет зависимостей данных с другими командами или неразрешенных ветвлений. Когда завершенные команды найдены, блок сброса фиксирует результаты этих команд в памяти или в регистрах в порядке их поступления и удаляет эти команды из накопителя команд. На рис. 2.12 показана более подробная функциональная схема архитектуры семейства процессоров P6, которая включает следующие подсистемы обработки:
- подсистема памяти;
- устройство выборки/декодирования;
- накопитель команд (буфер переупорядочивания);
- устройство диспетчеризации/выполнения;
- блок сброса.
Подсистема памяти для семейства процессоров P6 состоит из основного ОЗУ, первичного кэша (L1) и вторичного кэша (L2). Блок интерфейса шины обращается к системе памяти через внешнюю системную шину разрядностью 64 бит. Эта шина работает на основе транзакций – каждая операция доступа к шине обрабатывается как отдельная операция запроса и ответа. Пока шинный интерфейс ожидает ответ на запрос к шине, он может выполнить множество дополнительных запросов. Например, обращаться к кэшу L2 через 64‑битную (в последних моделях – 256-битную) шину кэша.
Блок интерфейса шин обращается к вторичному кэшу по отдельной 64-битной шине, также ориентированной на транзакции. Эта шина способна обслуживать до четырех одновременных запросов. Тактовая частота шины кэша, в зависимости от модели процессора, равна частоте ядра или ее половине.
Доступ к первичному кэшу идет по внутренней шине, работающей на частоте ядра. Четырехканальный наборно-ассоциативный первичный кэш инструкций имеет размер 8 Кб. Двухканальный наборно-ассоциативный первичный кэш данных (тоже 8 Кб) является двухпортовым – за один такт он может одновременно выполнить 1 запись и 1 чтение. Обмен кэша и памяти поддерживается протоколом MESI, который позволяет работать и в мультипроцессорных конфигурациях. Запросы к памяти от исполнительных блоков процессора проходят через блок интерфейса памяти и блок переупорядочивания запросов к памяти. Эти блоки предназначены для выравнивания потоков запросов к памяти через кэш и предотвращают блокировку (заторы) запросов. Первичный кэш свои промахи автоматически направляет к вторичному, а если промах произойдет и во вторичном кэше, то запрос через системную шину выйдет уже на основную память. Запросы к основной памяти и вторичному кэшу проходят через блок переупорядочивания запросов к памяти, который выступает в роли планировщика и диспетчера. В его ведении находятся все запросы к памяти, и он может менять порядок их исполнения для предотвращения блокировок и повышения производительности. Он может выполнять и спекулятивные чтения (но не записи).
Устройство выборки/декодирования включает блок выборки команд, буфер возможных переходов, декодер команд, последовательность микрокода и таблицу псевдонимов регистров.
Устройство диспетчеризации/выполнения содержит буфер резервации, 2 АЛУ, 1 блок с плавающей точкой x87, 2 блока генерации адреса и 2 SIMD-блока с плавающей точкой.
Накопитель команд имеет массив регистров переупорядочивания.
Блок сброса фиксирует результат прогностического выполнения микрокода в постоянное машинное состояние и удаляет микрокод из буфера переупорядочивания. Как и буфер резервации, блок сброса непрерывно проверяет состояние микрокода в буфере переупорядочивания – ищет те операции, которые были выполнены и у которых нет никаких зависимостей с другими микрооперациями в накопителе команд. Затем он “сбрасывает” завершенные микрооперации в их оригинальном порядке, принимая во внимание прерывания, исключения и промахи в прогнозировании перехода.
Суперконвейеризация в семействе P6 делит ступени стандартного конвейера на более мелкие части. Очевидно, что с увеличением числа ступеней каждая отдельная ступень выполняет меньшую работу и, следовательно, содержит меньше аппаратной логики в каждой схеме.
Временной интервал между поступлением набора входных воздействий на входы схемы и появлением результирующих сигналов на ее выходах (задержка распространения) в результате становится существенно меньше. Благодаря более коротким задержкам распространения сигнала в каждой отдельно взятой ступени конвейера становится возможным существенное повышение тактовой частоты.
Рассмотрим поэтапную работу конвейера процессора P6, состоящего из 10 стадий, представленных в табл. 2.3. Конвейер можно разделить на 3 самостоятельных функциональных части: входной блок упорядоченной обработки, отвечающий за декодирование и обработку команд; ядро исполнения с изменением последовательности, где, собственно, и происходит выполнение команд, и конвейер упорядоченного вывода команд из последовательности. Блок выборки команды IFU считывает поток инструкций из L1 кэша команд строками по 32 байта за такт. Для поиска начального адреса команды используется текущий указатель команды IP. По этому адресу извлеченные и выровненные до 16 байт команды передаются на три дешифратора. Если команда находится в конце первой строки кэша, считывается вторая строка кэша. Указатель команды управляется блоком вычисления адреса команды BAC с помощью информации, полученной от буфера адреса перехода BTB, учитывающей предысторию ветвлений.
Таблица 2.3
Структура конвейера процессора Р6
Стадии:
Блоки конвейера:
IFU
BTB
BAC
ID 0-2
MIS
RAT
ROB Rd
RS
IEU
FEU
PEU MIU RRF
Микрооперации:
Fetch
Decode
Rename
Reorder read
Reservation
Sche-dulers
Dis-patch
Execute
Пред-выборка
Дешиф-рирова-ние
Пере-имено-вание
Аккумули-рование /Удаление
Пла-ниро-вание
Раз-дача
Обработка /Запись
Предсказание переходов (ветвлений) призвано свести к минимуму холостую работу конвейера и обеспечить его непрерывным потоком команд. Вообще, в среднем до 10 % кода программы составляют безусловные переходы, передающие управление по новому указанному адресу, и от 10 до 20 % – условные переходы, которые меняют или не меняют ход выполнения программы в зависимости от результата вычисления условия (состояния флага). В случае, если условный переход не выполняется, программа просто продолжает выполнение следующей по порядку команды. Безусловные переходы задержек не вызывают, процессор просто начинает выборку команд по указанному адресу. Команды условных переходов представляют определенные трудности, потому что процессор не знает, будет ли выполнен переход до тех пор, пока команда не пройдет исполнительную ступень конвейера. Однако ожидание, пока команда ветвления покинет исполнительную ступень, означает временный отказ от возможности выборки и обработки дальнейших команд.
Для предсказания переходов процессор использует расширенный алгоритм Йеха (Yeh), позволяющий с большой достоверностью спрогнозировать, будет ли выполняться переход. Буфер возможных переходов на 512 адресов анализирует наборы команд программы. Внутри этого набора команд может быть несколько ветвлений, вызовов процедур и возвратов из них, и все они должны быть правильно предсказаны. Если предсказание окажется верным, то исполнение продолжится с малой задержкой или совсем без задержки. Если же предположение ошибочно, то частично выполненные команды придется удалять из конвейера, а новые команды выбирать из области памяти с правильным адресом, декодировать и выполнять их. Это повлечет за собой существенное снижение производительности, напрямую зависящее от глубины конвейера – для архитектуры P6 в случае ошибочного предсказания перехода потери составят от 4 до 15 тактов. Алгоритм предсказания ветвлений выбран динамическим двухуровневым. Он основывается на анализе поведения команд перехода за предшествующий период времени в цикле, а также на поведении конкретных групп команд, для которых с большой вероятностью можно предсказать переход. Точность предсказания данного алгоритма составляет около 90 %.
Выровненные 16-байтовые команды передаются в дешифратор команд, состоящий из трех параллельно работающих дешифраторов ID 0-2, два из которых – простые и один – сложный. Задача каждого дешифратора – преобразование IA инструкции в одну или несколько микрокоманд (на каждый микрокод два логических источника и один логический результат). Простые дешифраторы, обрабатывая команды x86, транслируют их в единственную микрокоманду. Сложный дешифратор работает с командами, которым соответствуют от одной до четырех микрокоманд. Некоторые особенно сложные команды невозможно непосредственно декодировать даже сложным дешифратором, поэтому они передаются в планировщик последовательности микрокоманд MIS, генерирующий необходимое число и последовательность микрокоманд. Если простой дешифратор встречает команду, которая не поддается трансляции, то она передается в сложный дешифратор либо в планировщик последовательности микрокоманд. Такая пересылка замедляет дешифрацию, что за счет буферизации с помощью станции-резервуара (RS) не очень значительно сказывается на производительности.
Последним этапом перед выполнением команд является закрепление микроопераций за дополнительными свободными физическими регистрами (отображение), осуществляемое в таблице псевдонимов регистров RAT. Для назначения внутренних регистров поставленные в очередь микрооперации из дешифратора команд посылаются в таблицу псевдонимов регистров RAT, где логические регистры IA преобразуются во внутренние ссылки на физические регистры. Программная архитектура x86 предусматривает только восемь 32-разрядных регистров общего назначения и вероятность того, что две соседние команды при параллельном исполнении будут использовать один регистр, относительно велика. Поэтому процессор "размножает клонированием" ограниченное число программных регистров и отслеживает, какие «клоны» содержат наиболее поздние значения. Это предотвращает задержки, которые в противном случае были бы внесены в процесс параллельной обработки команд в результате конфликтных обращений к регистрам. Распределитель в таблице псевдонимов регистров добавляет бит статуса и флаги к микрокоду (готовит для нестандартного выполнения) и посылает результирующую микрооперацию в накопитель команд. При отображении регистров происходит преобразование программных ссылок на архитектурные регистры в ссылки на 40 физических регистров микрокоманд, реализованных в буфере восстановления последовательности. Эти регистры могут содержать целые значения и числа с плавающей точкой.
В случае, если сложные и простые команды выровнены, то дешифраторы способны генерировать в общей сложности 6 микрокоманд за такт. Но, как правило, из всех 3 дешифраторов за один такт выдаются 3 микрокоманды, соответствующие в среднем 2-3 IA командам, которые передаются в буфер восстановления последовательности (ROB). ROB – это массив ассоциативной памяти, который содержит 40 регистров размером 254 бит. Каждый из них может хранить микрокоманду, 2 связанных с ней операнда, результат и несколько флагов состояния.
Станция-резервуар RS выступает диспетчером и планировщиком микрокоманд, для чего непрерывно сканирует буфер восстановления последовательности, выбирает и раздает команды, готовые к исполнению (имеющие все исходные операнды). Результат выполнения возвращается назад в буфер RRF и сохраняется вместе с микрокомандой до вывода.
Порядок исполнения команд основывается не на их первоначальной последовательности, а на факте готовности команды и ее операндов к исполнению, это и есть исполнение с изменением последовательности. Когда одновременно доступны две или более микрооперации одного типа (например, операции над целыми), они выполняются буфером переупорядочивания в порядке "первым пришел - первым обслужился". Если дешифраторы приостановили работу, исполнительные блоки продолжают работать, пользуясь микрокомандами, поставляемыми резервуаром, а в случае занятости исполнительных устройств резервуар приостанавливает работу дешифраторов. Выполнение до пяти микрокоманд за такт процессора осуществляется двумя целочисленными блоками АЛУ(IEU), двумя блоками вычислений с плавающей точкой FPU и PFU и одним блоком взаимодействия с памятью MIU.
Два целочисленных блока способны исполнять две целочисленные микрооперации одновременно. Один из блоков разработан специально для анализа перехода. Он способен обнаруживать ошибочно предсказанный переход и оповещать буфер предсказания переходов о необходимости перезапуска конвейера. Рассмотрим это подробнее. Дешифратор прикрепляет к команде перехода оба адреса – предсказанный адрес перехода и предварительно признанный неудачным. Когда целочисленный блок исполнения выполняет операцию перехода, он в состоянии определить, какая из ветвей была выбрана. В случае перехода по предсказанию все предварительно накопленные и выполненные команды данной ветви маркируются как годные для дальнейшего использования и продолжается исполнение данной ветви программы. В противном случае блок выполнения перехода в целочисленном блоке изменяет статус всех команд данной ветви на "подлежащие удалению". Потом передает в буфер адреса перехода правильный адрес перехода, и буфер, в свою очередь, перезапускает конвейер с этого адреса.
Блок взаимодействия с памятью отвечает за выполнение микрокоманд загрузки и сохранения. Загрузка требует только указания адреса памяти, поэтому может быть представлена одной микрокомандой. Сохранение требует также указания содержимого для сохранения, поэтому кодируется двумя микрокомандами. Часть блока, обрабатывающая микрокоманды сохранения, имеет два порта, что позволяет обрабатывать адреса и данные параллельно. Также возможно параллельное выполнение операций загрузки и сохранения в одном такте.
Для операций с плавающей точкой предусмотрены два блока вычислений FPU и PFU, причем второй предназначен для обработки SIMD-инструкций.
Команды, которые исполняются не в той последовательности, которая предписана программой, располагаются затем в должной последовательности – иначе процессор не всегда сможет получить правильные результаты. Буфер восстановления последовательности сохраняет статус исполнения и результаты каждой микрокоманды. Микрокоманда выводится блоком вывода, который подобно станции-резервуару сканирует буфер восстановления последовательности на предмет обнаружения микрокоманд, которые уже не повлияют на выполнение других микрокоманд. Такие команды признаются завершенными, и блок вывода выстраивает их в первоначальную последовательность, учитывая прерывания, исключения, точки останова и неверные предсказания переходов.
Блок вывода способен выводить 3 микрокоманды за такт. При выводе микрокоманды результаты записываются в выводящий регистровый файл RRF или память. Выводящий регистровый файл содержит 8 регистров общего назначения и 8 регистров для данных с плавающей точкой. После того, как микрокоманда выведена, она удаляется из буфера восстановления последовательности. Операции записи в память откладываются до тех пор, пока команда не будет выведена. Для этого в P6 предусмотрен буфер упорядочения обращений к памяти MOB, в котором по командам, выдаваемым блоком записи в память, сохраняется информация о данных и адресах. Буфер упорядочения обращений к памяти пересылает данные в память только после того, как буфер восстановления последовательности уведомит его о том, что микрокоманда, произведшая запись в память, удаляется.