Начиная с 1995 г. Intel приступила к выпуску серийного CISC-процессора P6 шестого поколения i686 под торговой маркой Pentium Pro с напряжением питания около 3 В. Он содержит 5 500 тысяч транзисторов на кристалле и изготовлен по 0,35 мкм технологии в корпусе с 387 выводами. В создании этого процессора разработчики воспользовались всеми техническими решениями, ранее применяемыми в суперЭВМ. К таким решениям относятся включение в структуру процессора устройств динамического определения порядка выполнения команд и нескольких многоступенчатых конвейеров. В отличии от двух 5-ступенчатых конвейеров Pentium, P6 имеет три 10-ступенчатых. Увеличение числа конвейеров и ступеней обработки команд в них позволило увеличить внутреннюю тактовую частоту синхронизации, которая стала равной 133, 166, 180, 200 МГц и более. В Pentium Pro для повышения производительности вычислений за счет увеличения внутренней тактовой частоты внедрены следующие структурные дополнения в семейство х86:
- применено динамическое исполнение команд, при котором команды, не зависящие от вычислений ранних операций в программе, выполняются в измененном сдвоенном порядке с передачей результатов в закрепленном в программе порядке;
- использован тыльный кэш-2 с двумя раздельными системными шинами обмена: скоростной короткой для обмена между МП и кэш-2; традиционной процессорной с частотой синхронизации 66,6 МГц;
- внешний кэш-2 емкостью 256 или 512 Кб размещен в корпусе МП;
- внедрены дополнительные средства контроля ECC при обмене в системной шине, кэш-2, ОЗУ и возможность контроля дублированием вычислений вторым МП в режиме FRC;
- системная шина с программируемым контроллером и интерфейсом APIC обеспечивает мультипроцессорную обработку до 4 МП, объединенных в единую систему.
Увеличение частоты синхронизации позволяет повысить быстродействие обработки команд, что, в свою очередь, требует повышения скорости обмена с внешним ОЗУ. Чтобы исключить задержки обмена с ОЗУ, в кристалле процессора смонтирована буферная память второго уровня (кэш-2) емкостью 256 Кб. Блок кэш-2 связан внутри процессора через интерфейс памяти собственной синхронной внутренней 64-разрядной шиной данных, работающей на тактовой частоте процессора.
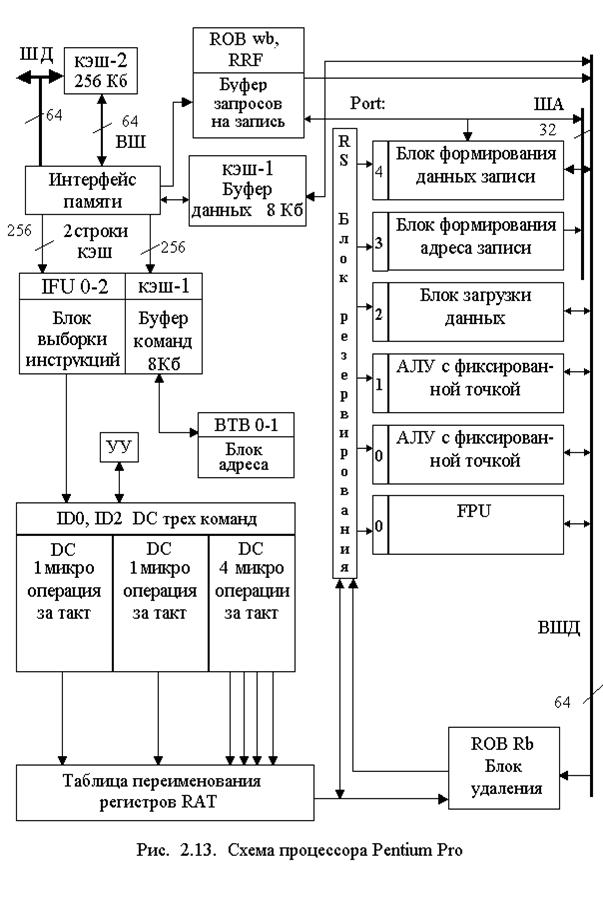
С целью эффективного вычисления последовательности команд в Pentium Pro используется буфер предсказания ветвлений ВТВ0, ВТВ1 на 512 входов. Использование этих блоков позволило разработчикам добиться наибольшей загрузки двух блоков целочисленной арифметики (АЛУ), сопроцессора (FPU), блоков записи и загрузки, увеличив производительность по сравнению с Pentium на 35 – 45 %. Эта производительность оказалась всего лишь в 1,5 раза меньше, чем у самого быстрого RISC-процессора DEC Alpha 21164. Схема МП Pentium Pro показана на рис. 2.13. Процессор Pentium Pro выполняет вычисления в конвейере в следующей последовательности. Операционная система загружает из ОЗУ через системную шину в кэш-2 массивы данных и набор команд для выполнения программ, которые образуют очередь с приоритетами и привилегиями. Первая программа из очереди одновременно загружается в кэш-1 команд, а операнды, с которыми она работает, передаются в кэш-1 данных. Адреса команд и данных располагаются в блоке тэгов обоих кэш-1, и в случае промаха при обращении к кэш-1 недостающие команды или данные постоянно доизвлекаются чаще всего из кэш-2 и реже, при отсутствии в нем, из основного ОЗУ. На первой ступени дешифрирования (DC) три команды динамически распределяются на параллельную обработку во вторую ступень дешифрации ID1 (распределение на параллельную обработку в целочисленные АЛУ и FPU). В результате после второй ступени дешифрации в каждом такте могут появляться одновременно до шести микроопераций, подлежащих выполнению в операционном блоке (Port 0 - 4) ядра процессора.
Эти микрооперации закрепляются за регистрами в блоке переименования регистров и выделения ресурсов RAT. Блок переименования регистров RAT позволяет закрепить для выполнения операций более восьми РОН, используемых для программирования. При наличии нескольких конвейеров это даёт возможность одновременно выполнять несколько команд, ссылающихся на одни и те же регистры в разных конвейерах по мере их освобождения.
После RAT набор микроопераций направляется в блок резервирования RS и буфер переупорядочивания чтения ROB Rd, который осуществляет вычисление адресов операндов и загрузку ими переименованных регистров РОН в двух целочисленных АЛУ.
После выполнения микроопераций ROB Rd удаляет их из блока резервирования RS. Блок RS является начальной ступенью произвольной обработки в ядре МП. В нем микрооперации могут ожидать операнды или устройства для выполнения операции. Если операнды доступны и устройства свободны, микрооперация направляется на исполнение через один из портов Port 0 - 4 минуя такты ожидания. Результаты выполнения микроопераций передаются в переупорядочивающий буфер записи ROB wb и файл регистров RRF, способный принимать за один такт три операнда. В этом блоке результаты окончания операций ожидают освобождения ШД для записи в кэш и ОЗУ. Для чего им восстанавливается порядок, соответствующий порядку результатов при выполнении закодированной программы.
Для Pentium Pro Intel разработала два чипсета PCI: 82450GX (для серверов) и 82450FХ (для рабочих станций) и специальное программное обеспечение, обеспечивающее параллельную обработку команд в конвейере с 32 - разрядными числами. Хотя Pentium Pro программно совместим с предыдущими моделями микропроцессоров x86, эффективное его использование в персональных компьютерах сдерживалось дороговизной ЭВМ и недостаточным количеством необходимого программного обеспечения.