Следующему, пятому поколению МП Intel 80586, которые разрабатывались как Р5, для регистрации авторских прав было присвоено название Pentium. Серийное изготовление этого процессора началось в 1993 г. с рабочей частотой 60, а затем 66 МГц и напряжением питания 5 В. Кристалл, потребляя 16 Вт мощности, сильно нагревался и обдувался вентилятором. Через год биполярная КМОП-технология была усовершенствована с 0,8 до 0,6 мкм на элемент, снижено напряжение питания до 3,3 В и повышена внутренняя рабочая частота процессора до 75, затем 90 и 100 МГц. Эти процессоры второго поколения (Р54С) получены на кристалле, содержащем 3,3 млн транзисторов, в корпусе SPGA с 296 выводами, по суперскалярной архитектуре.
Под скалярным понимается МП с единственным конвейером (все МП до Pentium). Процессор Pentium имеет 2 конвейера, а Pentium Pro является трехпотоковым [4]. Эти МП способны обрабатывать несколько команд за такт, поэтому их называют суперскалярными. Понятие «суперскалярная архитектура» связано обычно с высокопроизводительными RISC - процессорами. Pentium является одним из первых CISC - процессоров, который параллельно обрабатывает 2 команды, так как его архитектура объединяет 2 конвейера i486 в своем корпусе, которые обозначаются U и V. Ведущий U - конвейер выполняет все операции, а второй V - конвейер выполняет простые операции с целыми числами и часть операций с плавающей запятой. Многие программы допускают одновременное выполнение двух последовательных команд, когда работают оба конвейера и процессор выполняет сдваивание команд. В некоторых случаях не все команды допускают сдваивание, тогда работает только U - конвейер. С целью получения большей производительности МП программы транслируют с наибольшим числом случаев сдваивания команд, чтобы обеспечить преимущество суперскалярной технологии в параллельной обработке.
По сравнению с i486 Pentium (P5) имеет следующие усовершенствования:
- имеется два конвейера U и V в результате объединения двух i486 в суперскалярную архитектуру, позволяющие одновременно обрабатывать 2 последовательные команды, допускающие сдваивание;
- внедрен блок динамического предсказания ветвлений ВТВ, обеспечивающий выполнение команд не дожидаясь вычисления условий ветвлений;
- используются два внутренних кэш-1 с отложенной сквозной или обратной записью результатов вычислений в буфере до освобождения шины;
- расширена шина данных (до 64 бит), удваивающая скорость передачи данных;
- кэш-1 одновременно доступен для 2 конвейеров, если они обращаются к разным банкам памяти;
- внедрен режим конвейерной обработки данных в устройстве с плавающей точкой FPU и увеличена его производительность в 2 - 10 раз;
- расширена система команд, в которую включена команда CPUID опроса модели МП, и расширен размер страницы до 4 Мб при страничной переадресации;
- расширено число регистров тестирования (TR1 - TR12);
- введена возможность совместной работы двух МП;
- расширены средства контроля и увеличена достоверность передачи и вычислений, введены средства снижения энергопотребления.
Обработка закодированной команды требует определенных затрат времени (тактов, т. е. импульсов синхронизации). Чем сложнее команда, тем больше требуется тактов и определенных последовательностей микроопераций на ее выполнение. Для повышения быстродействия вычислений последние модели МП обрабатывают команды по шагам в очереди поэтапно в нескольких операционных блоках. Набор блоков и правила обработки команд в этих блоках характеризует тип конвейера МП. В каждом такте в конвейер поступает одна команда, которая обрабатывается на первой ступени. Затем в следующем такте она сдвигается на вторую ступень и через несколько тактов (равное или меньшее числа ступеней) команда окончательно исполняется на последней ступени. На каждой ступени команда занимает один из блоков, в котором вычисляет адреса операндов, извлекает их в РОН МП, выполняет операции в АЛУ и т. д. В каждом блоке выполняется от одной до нескольких микроопераций. Один конвейер позволяет сократить время на выполнение любой команды до времени, равного длительности одного импульса синхронизации. Дальнейшее увеличение быстродействия может быть получено за счет параллельной обработки команд на нескольких конвейерах (суперскалярная архитектура). Так, в Pentium используется 2 пятиступенчатых конвейера, позволяющих за один такт при сдваивании обрабатывать 2 команды. Таким образом, чем больше ступеней конвейера, тем большее число последовательных микроопераций может быть включено в команду, а чем больше конвейеров, тем больше одновременно команд может быть обработано в одном такте синхронизации.
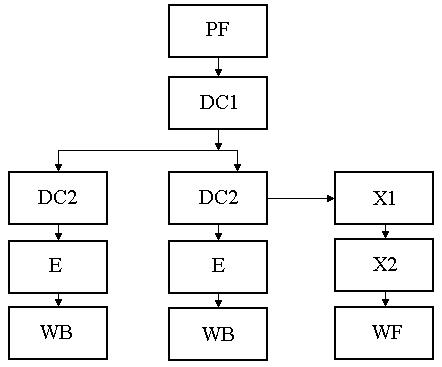
Чтобы уменьшить время ожидания вычисления адресов команд управления, изменяющих естественный порядок их обработки, используется буфер адреса ветвления (ВТВ). В Pentium имеется ВТВ на 256 элементов (вхождений) по схеме динамического предсказания ветвлений. В данный буфер с опережением считываются адреса и содержимое команд условных переходов из очереди предвыборки. «Предвидение» переходов и опережающая подготовка характеристик ветвления позволяет обрабатывать команды с максимальным быстродействием. Динамическое предсказание ветвлений осуществляется с учетом накопления статистики выполнения условных переходов и анализа предыстории вычислений. Процесс обработки команд в конвейерах U, V и FPU можно пояснить с помощью рис. 2.9 [8].
Блок предварительной выборки команд (PF), имеющий четыре 256- разрядных независимых буфера, поочередно из программного кэш извлекает команды в естественном порядке по 16 байт с учетом прогноза флага команды условного перехода, т. е. в направлении, предсказанном буфером адреса ветвлений ВТВ. Если предсказание не подтвердилось, то блок PF очищается, предвыборка повторяется в новом направлении с потерей 3 - 4 циклов вычислений. Если команды зависят друг от друга, то первая запускается в U - конвейер, а V - конвейер простаивает. Если предсказание не вычисляется, то команды обрабатываются в естественном порядке.
Рис. 2.9. Блок - схема конвейерной обработки МП Pentium
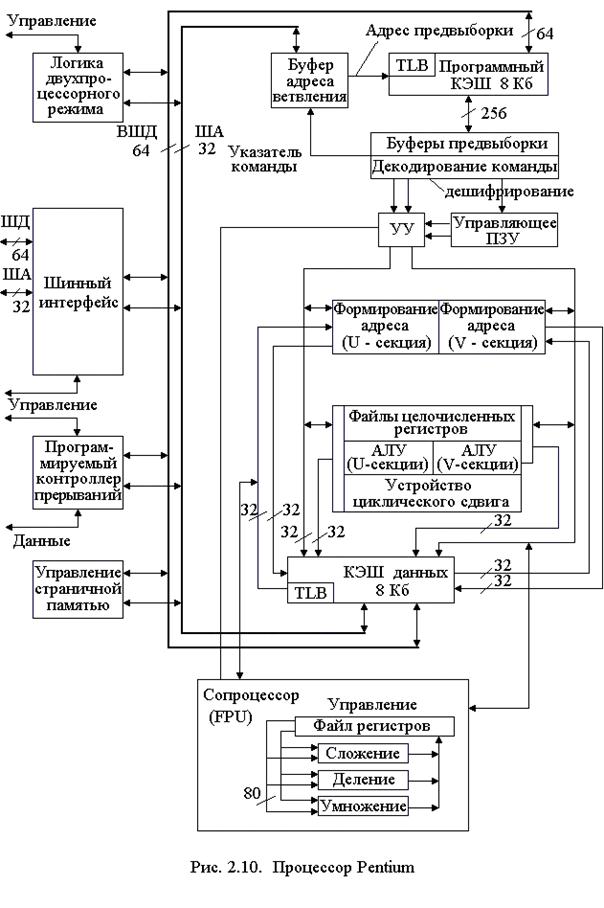
После предвыборки команды продвигаются по мере освобождения конвейеров на дальнейшую обработку и вначале проходят первую ступень дешифрации DC1. В этой ступени выявляется возможность сдваивания команд. При наличии сдваивания 2 команды передаются на вторые ступени дешифрации DC2, где могут вычисляться адреса операндов в памяти с использованием многоканального сумматора или может осуществляться передача их в трехступенчатый конвейер FPU (X1- X2 - WF). На четвертой ступени целочисленного конвейера Е происходит передача операндов для выполнения операции в АЛУ, после чего результаты передаются в буфер записи в память WB. Схема процессора Pentium изображена на рис. 2.10. Он имеет такую же, как и i486, 32-разрядную шину адреса, позволяющую обращаться к 4 Гб памяти, буфер адреса ветвления и схемы, обеспечивающие двухпроцессорный режим обработки информации.
Процессоры Pentium MMX (P55C) появились в начале 1997 г. для эффективного выполнения мультимедийных приложений, а также 2D и 3D- графики [9]. Они выполнены по 0,35 мкм технологии на кристалле, содержащем 4,5 млн транзисторов. Сначала МП обрабатывали команды с частотой 166 МГц, затем 200 и 233 МГц.
В архитектуре Pentium MMX один из конвейеров FPU был специализирован для обработки 4 новых типов данных и 57 ММХ команд в восьми 64-битных регистрах с прямой адресацией MMX0-MMX7. Основная идея расширения ММХ заключается в использовании способа SIMD, который предусматривает одновременную обработку нескольких операндов, находящихся в 64-битном формате ММХ, под управлением одной команды за один такт. В формате ММХ могут находиться упакованные 8 байт, 4 слова, 2 двойных слова и учетверённое слово.
Над этими данными могут выполняться арифметические операции, такие как сложение без переполнения (с насыщением), умножение, сравнение данных на равенство, преобразование форматов, сдвиги, пересылки, логические (И, И-НЕ, ИЛИ, Исключающее ИЛИ), обнуление регистров MMX0 - MMX7. Регистры MMX принадлежат FPU, поэтому они 80-разрядные. Эти же регистры используются при выполнении операций с плавающей запятой. Поэтому MMX и FPU команды несовместны, их частое чередование с настройкой конвейера на обработку существенно снижает быстродействие вычислений. В зависимости от типа команды ММХ за один такт могут обрабатываться параллельно как 8 однобайтных, так и 4 двухбайтных или 2 четырехбайтных операнда. Pentium MMX способен выполнять 2 SIMD команды с 16-битными данными за 1 такт. В нем U- и V- конвейеры имеют равные приоритеты и команды распределяются в них без жесткой привязки.
Он имеет лучшие характеристики в отличие от Pentium и при выполнении обычных команд. Кроме того, Pentium MMX имеет 4 буфера записи WR, которые могут быть использованы любым конвейером, удвоенную емкость внутреннего кэш (16+16 Кб). Для синтаксического разбора инструкций в конвейере МП введена дополнительная ступень F после ступени PF. Если в результате синтаксического разбора двух команд выявляется возможность их параллельного выполнения, они направляются: в два АЛУ ММХ; один ускоренный умножитель для операций умножения с задержкой на 3 цикла, но в каждом такте; один сдвигатель для левого или правого сдвига операндов на количество бит, указанных в операнде источнике. Команды ММХ при наличии микроопераций обращения к кэш-1 или к обычным РОН выполняются только в U-конвейере и не допускают в нем сдваивания с обычными командами х86.