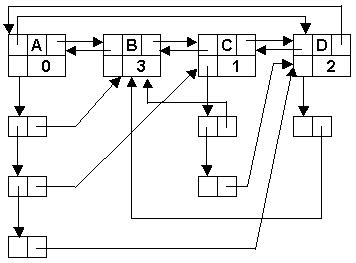
Первая фаза – первоначальное построение списочной структуры. Проходим массив пар, и для каждого элемента множества, который ещё не включен в список, создаем узел и помещаем его в хвост основного списка. Для каждой пары first, second в подсписок узла firstпомещаем узел, в поле m которого помещаем ссылку на узел основного списка second. Счетчик count узла second увеличиваем на единицу. После завершения первой фазы узел каждого элемента содержит число элементов, предшествующих данному. На рис.19 изображено состояние основного списка после завершения первой фазы для массива пар
предшествования
Рис 19. Топологическая сортировка. 1 фаза.
Вторая фаза – создание списка ведущих элементов. Список ведущих имеет такую же структуру, что и основной список. Проходя основной список слева направо, узлы, имеющие поле счетчика, равное нулю, переносим в список ведущих элементов. Этим элементам ничто не предшествует, и они первыми будут выведены в выходную последовательность.
Третья фаза – построение выходной последовательности. Проходим список ведущих и его элементы помещаем в выходную последовательность и удаляем из списка ведущих. Проходя подсписок выводимого в результат элемента, уменьшаем на единицу поле счетчика того элемента основного списка, на который ссылается поле m подсписка. Действительно, после вывода элемента списка ведущих в результирующую последовательность, он уже не предшествует оставшимся в основном списке элементам. Если поле счетчика окажется равным нулю, переносим его в хвост списка ведущих.
Если отношение предшествования было задано корректно, то все элементы будут выведены и основной список опустеет. Если же основной список по завершении третьей фазы не пуст, то это говорит о противоречивом задании частичного порядка. Например, частичный порядок
a í b; b í c; c í a
противоречив.
Ниже приведен текст функции, реализующей топологическую сортировку:
void TopSort(PAIR *p, int n_pair, FILE *result){
// p - массив пар указателей на имена элементов
// Наличие пары s1,s2 означает,
// что s1ís2
// n_pair - число таких пар
// result - файл, в который помещаются результаты
MAINS *mhead; // голова основного списка
MAINS *vhead; // голова списка ведущих элементов
MAINS *u1,*u2,*v,*w;
int i;
POD *x,*y;
// создание основного списка
mhead=new MAINS;
mhead->llink=mhead;
mhead->rlink=mhead;
// проход по всем парам
for(i=0; i<n_pair; i++){
// найдем или создадим элемент по имени p[i].first
u1=FindU(mhead,p[i].first);
// найдем или создадим элемент по имени p[i].second
u2=FindU(mhead,p[i].second);
// u1 предшествует u2, поэтому к счетчику u2 прибавим 1
u2->count++;
// в подсписок u1 добавим узел, указывающий на u2
x=new POD;
x->next=u1->pod;
u1->pod=x;
x->m=u2;
}
// создание списка ведущих
vhead=new MAINS; // голова
vhead->llink=vhead->rlink=vhead;
// проходим по основному списку и узлы с полем счетчика ==0
// переносим в список ведущих
for(v=mhead->rlink; v!=mhead; v=w){
w=v->rlink;
if(v->count==0){
// переносим в хвост списка ведущих
AddToTail(vhead,v);
}
}
// проход по списку ведущих
for(v=vhead->rlink; v!=vhead; v=v->rlink){
// имя элемента печатаем в файл результата
fprintf(result," \"%s\",\n",v->name);
// проходим по подсписку и уменьшаем на 1 поле счетчика
// в узлах основного списка, на которые ссылаются узлы
// подсписка
for(x=v->pod,y=x->next; x!=NULL; x=y){
y=x->next;
x->m->count--;
if(x->m->count==0){
// если счетчик==0, то переносим узел из основного
// списка в конец списка ведущих
AddToTail(vhead,x->m);
}
// узлы подсписка больше не понадобятся
delete x;
}
// узлы списка ведущих тоже больше не нужны
delete v;
}
delete vhead;
// осталось ли что-нибудь в основном списке ?
// если осталось, то это говорит о противоречивом
// задании предшествования и список содержит кольца