Вейвлеты (от англ. wavelet), всплески — это математические функции, позволяющие анализировать различные частотные компоненты данных. Вейвлет-коэффициенты определяются интегральным преобразованием сигнала. Полученные вейвлет-спектрограммы принципиально отличаются от обычных спектров Фурье тем, что дают четкую привязку спектра различных особенностей сигналов ко времени.
Для обработки дискретных сигналов используется дискретное вейвлет-преобразование (ДВП, DWT).
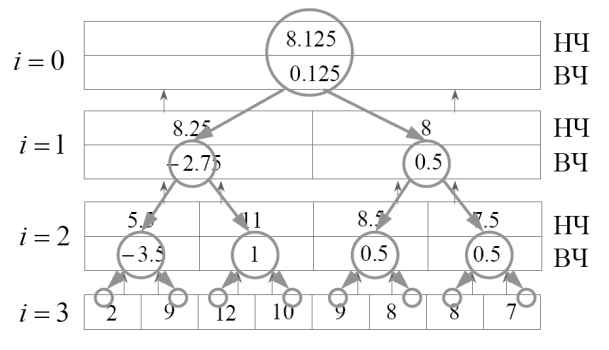
Первое ДВП было предложно венгерским математиком Альфредом Хааром. Для входного сигнала, представленного массивом 2n чисел, вейвлет преобразование Хаара просто группирует элементы по 2 и образует от них суммы и разности. Группировка сумм проводится рекурсивно для образования следующего уровня разложения. В итоге получается 2n−1 разность и 1 общая сумма. Мы начнем с одномерного массива данных, состоящего из N элементов. В принципе, этими элементами могут быть соседние пикселы изображения или последовательные звуковые фрагменты. Примером будет служить массив чисел (2,9,12,10,9,8, 8,7). Сначала вычислим четыре средние величины (Рис. 40)
(2+9)/2 = 5,5,
(12+10)/2 = 11,
(9+8)/2 = 8,5,
(8+7)/2 = 7,5.
Ясно, что знания этих четырех полусумм не достаточно для восстановления всего массива, поэтому мы еще вычислим четыре полуразности
(2 - 9)/2 = - 4,5,
(12 - 10)/2 = 1,
(9 – 8)/2 = 0,5,
(8 – 7)/2 = 0,5,
которые будем называть коэффициентами деталей. Средние числа можно представлять себе крупномасштабным разрешением исходного образа, а детали необходимы для восстановления мелких подробностей или поправок. Если исходные данные коррелированы, то крупномасштабное разрешение повторит исходный образ, а детали будут малыми.
Массив, состоящий из четырех полусумм и четырех полуразностей, можно использовать для восстановления исходного массива чисел. Новый массив также состоит из восьми чисел, но его последние четыре компоненты, полуразности, имеют тенденцию уменьшаться, что хорошо для сжатия.
Повторим нашу процедуру применительно к четырем первым (крупным) компонентам нашего нового массива. Они преобразуются в два средних и в две полуразности. Остальные четыре компонента оставим без изменений. Следующая и последняя итерация нашего процесса преобразует первые две компоненты этого массива в одно среднее (которое, на самом деле, равно среднему значению всех 8 элементов исходного массива) и одну полуразность.
Рисунок 3.18. Илллюстрация работы одномерного вейвлет-преобразования.
В итоге получим массив чисел, который называется вейвлетным преобразованием Хаара исходного массива данных [6].
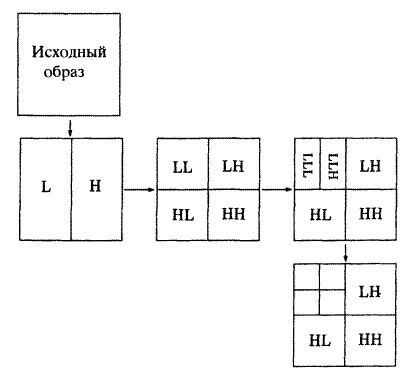
Одномерное вейвлетное преобразование Хаара легко переносится на двумерный случай. Стандартное разложение (рис. 3.19) начинается вычислением вейвлетных преобразований всех строк изображения. К каждой строке применяются все итерации процесса, до тех пора, пока самый левый элемент каждой строки не станет равен среднему значению чисел этой строки, а все остальные элементы будут равны взвешенным разностям. Получится образ, в первом столбце которого стоит среднее столбцов исходного образа. После этого стандартный алгоритм производит вейвлетное преобразование каждого столбца. В результате получится двумерный массив, в котором самый левый верхний угловой элемент равен среднему всего исходного массива. Остальные элементы верхней строки будут равны средним взвешенным разностям, ниже стоят разности средних, а все остальные пикселы преобразуются в соответствующие разности.
Пирамидальное разложение вычисляет вейвлетное преобразование, применяя итерации поочередно к строкам и столбцам. На первом шаге вычисляются полусуммы и полуразности для всех строк (только одна итерация, а не все вейвлетное преобразование). Это действие производит средние в левой половине матрицы и полуразности - в правой половине. На втором шаге вычисляются полусуммы и полуразности для всех столбцов получившейся матрицы.
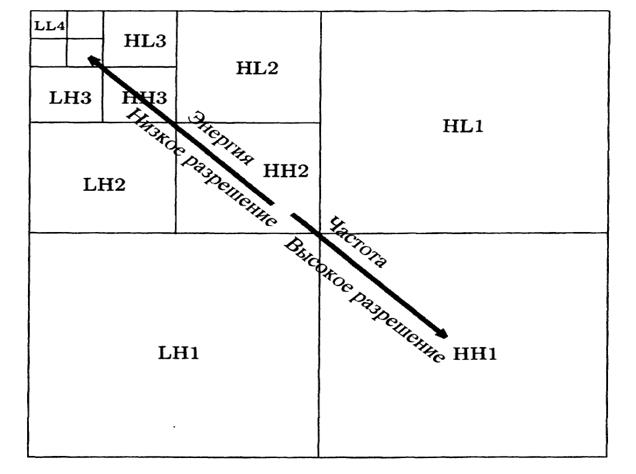
Результатом двумерного вейвлет-преобразования является набор матриц, соответствующих различным спектральным составляющим исходного изображения. При этом в левом верхнем углу находится низкочастотная компонента LL4 (рис. 3.21), которая создавалась только на основе полусумм и является уменьшенной копией исходного изображения.
Остальные компоненты преобразования можно использовать для восстановления исходного изображения. При этом, высокочастотные компоненты хорошо поддаются сжатию с использованием алгоритмов RLE и Хаффмана. Следует также отметить, что при сжатии с потерей информации возможно также использовать квантование, а также прямое отбрасывание части компонент. Результатом таких операций является хорошая степень сжатия. На рис. 3.22 приведен пример кодирования изображения, использующего вейвлет-преобразование.
Следует отметить, что двумерное вейвлет-преобразование требует значительных вычислительных ресурсов при реализации обычными программными методами. Однако, алгоритм вейвлет-преобразования состоит из большого количества простых преобразований, которые хорошо поддаются распараллеливанию. В результате, это преобразование хорошо выполняется аппаратно при использовании специализированной элементной базы.
Рисунок 3.22 . Пример вейвлет-преобразования изображения.
Вейвлет-преобразование используется в стандарте сжатия изображений JPEG2000, а также предусмотрено в качестве инструмента в формате MPEG-4.