Результатом решения задачи идентификации является имитационная или аналитическая модель структурного примитива. Как уже отмечалось, аналитические модели делятся на теоретические и экспериментальные. Теоретические модели получают на основе известных описаний процессов функционирования объекта. Экспериментальные – на основе изучения поведения объекта моделирования во внешней среде.
Для построения экспериментальных моделей используют:
- методы аппроксимация зависимостей;
- методы корреляционного и регрессионного анализа;
- методы планирования эксперимента.
Пусть экспериментальная статистика функционирования структурного примитива задана таблично. В этом случае значения функции базисной координаты известны только для дискретных значений входной переменной. Для того чтобы вычислять значение базисной координаты в любой произвольной точке, необходимо восстановить непрерывную функцию v=f(х). Такое приближение называют аппроксимацией.
Аппроксимация характеристик структурных примитивов применяется в следующих случаях:
- если аналитическое описание характеристики неизвестно и она задана набором экспериментальных данных;
- аналитическое описание v=f(х) сложное и затрудняет расчеты.
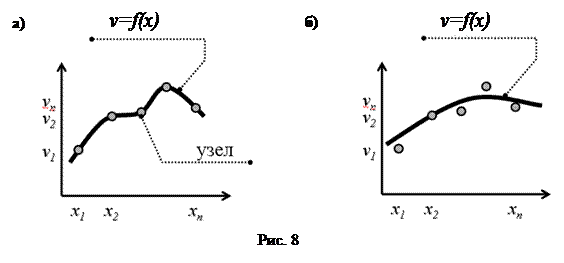
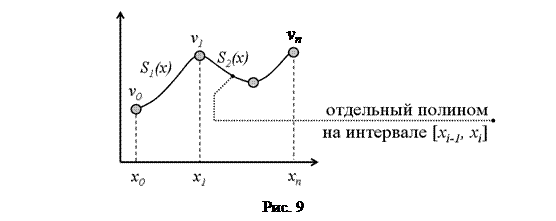
Постановка задачи аппроксимации имеет два варианта. В первом случае осуществляется поиск аппроксимирующей функции, наилучшим образом описывающей экспериментальную статистику, при условии обязательного прохождения графика аппроксимирующей функции через определенные заданные точки экспериментальной статистики (см. рис. 8-а). Эти точки называются узлами. Второй вариант постановки задачи аппроксимации не имеет ограничивающего условия обязательного прохождения функции через узлы (см. рис. 8-б).
Для решения первой задачи используется методы кусочно-линейной аппроксимации и аппроксимации сплайнами.
Кусочно-линейная аппроксимация получается соединением узлов отрезками прямых линий. Узлы располагаются так, чтобы обеспечить наименьшую ошибку между аппроксимирующей и точной функцией.
Главный недостаток кусочно-линейного приближения заключается в том, что, хотя аппроксимирующая функция непрерывна в узлах, ее производные в этих точках имеют разрывы. Другой недостаток – требование большого числа узлов для достаточно точного описания характеристик.
ПРИМЕР использования кусочно-линейной аппроксимации.
Для преодоления указанного недостатка можно в качестве аппроксимирующей функции использовать полином высокой степени. С математической точки зрения для n заданных узлов экспериментальной статистики всегда найдется полином степени n, график которого строго пройдет через все узлы. Однако на практике при большом числе пар значений такая аппроксимация часто бывает бессмысленной или требует неоправданных затрат ресурсов. Чаще используют аппроксимацию сплайнами. В отличие от интерполяции полиномом, которым описывается вся область данных, при интерполяции сплайнами строится отдельный полином, описывающий интервал от узла xi-1 до узла xi (см. рис. 9).
Наиболее часто используют полиномы третьей степени – кубические сплайны. На каждом отрезке кубический сплайн является многочленом третьей степени:
.
В узлах сплайн принимает заданные значения , :
(1)
(2)
Условия (1) и (2) требуют, чтобы сплайны соприкасались в заданных точках. Количество условий таких условий равно . Во внутренних узлах , сплайн имеет непрерывную первую и вторую производные:
(3)
(4)
Условия (3) и (4) означают, что в местах соприкосновения сплайнов их первые и вторые производные должны быть равны. Таких условий . Для отыскания искомого сплайна требуется найти коэффициенты , , , многочленов , , т. е. неизвестных. Однако количество уравнений, записанных по условиям (1)–(4) равно . Чтобы система алгебраических уравнений имела решение, необходимо, чтобы число уравнений равнялось числу неизвестных. Следовательно, для разрешимости задачи нужны еще два дополнительных условия. Их обычно получают из естественного предположения о нулевой кривизне графика сплайна на концах:
, .
Полученный таким образом сплайн называют естественным. Если есть дополнительные сведения о поведении функции на концах интервала интерполяции, то можно записать другие краевые условия.
Для решения второй задачи аппроксимации используют методы регрессионного и корреляционного анализа. При помощи регрессионного анализа на основании экспериментальных данных строится уравнение, вид которого задает исследователь. Например, линейный парный регрессионный анализ заключается в определении параметров эмпирической линейной зависимости v(x)=b1x+b0, где для определения неизвестных коэффициентов b1 и b0 используют систему линейных уравнений
Решение этой системы имеет вид:
Найденные коэффициенты регрессионного уравнения обеспечивают минимум среднеквадратических отклонений расчетных значений v от экспериментальных. Параболическая регрессия обеспечивает получение трех параметров b0, b1 и b2 приближения экспериментальной зависимости параболической функцией v(x)= b0+b1x+b2x2.
Для моногофакторных моделей (две и более переменных х) наиболее распространенными являются модели в виде полинома степени d:
В частном случае это может быть линейный полином ,
или неполный квадратичный полином .
Корреляционный анализ позволяет оценить степень взаимосвязи двух переменных по набору их экспериментальных значений. Применительно к задачам аппроксимации корреляционный анализ используют для оценки согласованности выбранной аппроксимации с экспериментальными данными. Для оценки рассчитывают коэффициент корреляции между расчетными vр и экспериментальными vэ значениями базисной переменой:
Значение R лежит в пределах от -1 до +1. Коэффициент -1 соответствует максимальной отрицательной корреляции, когда с ростом параметра, откладываемого по оси х, параметр откладываемый по оси y уменьшается, а все точки лежат точно на прямой. Значение 0 соответствует отсутствию корреляции; +1 – максимальной положительной корреляции. Чем ближе значение R по модулю к 1, тем бóльшую точность имеет аппроксимация. Квадрат коэффициента корреляции называется коэффициентом детерминации или коэффициентом точности аппроксимации.
ПРИМЕРЫ использования корреляционного анализа для оценки взаимосвязи переменных и точности аппроксимации.
Получение экспериментальной статистики функционирования объекта моделирования (структурного примитива на n-ом уровне иерархии или системы в целом) для последующей идентификации методами регрессионного и корреляционного анализа является самостоятельной задачей, которая решается методами планирования эксперимента. Различают три типа экспериментов:
- активный: экспериментатор преднамеренно параметры системы с целью получения ее модели;
- пассивный: связь между параметрами устанавливается по результатам наблюдений за самопроизвольными изменениями в системе;
- смешанный.
Под планированием эксперимента понимается процедура выбора числа опытов и условий их проведения, необходимых для идентификации с требуемой точностью. Все переменные, определяющие объект моделирования, изменяются одновременно по специальным правилам. Результаты эксперимента представляются в виде математической модели, обладающей определенными статистическими свойствами, например минимальной дисперсией оценок параметров модели.
Варьирование одного фактора на нескольких уровнях при фиксированном постоянном значении всех остальных факторов называется однофакторным экспериментом. В этом случае можно получить количественную оценку эффекта только одного фактора. Влияние других факторов оценить нельзя. Выводы о влиянии изучаемого фактора могут существенно различаться в зависимости от уровня фиксирования прочих факторов. Это может привести к неадекватности моделей идентификации. Только в тех случаях, когда отклик является функцией одного фактора, однофакторный эксперимент вполне закономерен.
Однако на практике приходится иметь дело с многофакторными объектами, где однофакторный эксперимент неэффективен. В многофакторных планах эксперимента одновременно варьируется несколько факторов, а не каждый в отдельности. В планировании эксперимента сам эксперимент рассматривается как объект исследования и оптимизации. Планирование многофакторных экспериментов – основной подход к организации и проведению экстремальных исследований сложных систем. Цель планирования эксперимента – извлечение максимума информации при заданных затратах на эксперимент либо минимизация затрат при получении информации, достаточной для решения задач. Планирование эксперимента позволяет соразмерить число опытов поставленной задаче.
ПРИМЕР логических оснований планирования эксперимента.
Табличная форма плана эксперимента называется матрицей планирования. Построение матрицы начинается с определения числа рассматриваемых факторов и уровней варьирования факторов. Уровни варьирования кодируются. Если при проведении эксперимента реализуются все возможные сочетания уровней факторов, такой эксперимент называется полным факторным экспериментом.
Матрица полного трехфакторного двухуровневого эксперимента имеет вид, приведенный в таблице 2. Данный план обладает следующими свойствами:
1) симметричностью относительно центра эксперимента – сумма элементов столбца матрицы для каждого фактора равна нулю;
2) попарной ортогональностью столбцов – сумма почленных произведений их элементов равна нулю: ;
3) нормировкой – сумма квадратов элементов каждого столбца равна числу опытов: .
Таблица 2
Номер опыта
x1
x2
x3
+
+
+
+
-
-
-
+
-
-
-
+
+
+
-
-
+
+
+
-
+
-
-
-
Свойства плана полного трехфакторного двухуровневого эксперимента обеспечивают независимость оценок коэффициентов регрессионной функции. Коэффициенты регрессии оцениваются по всем N опытам и, соответственно, в N раз уменьшается дисперсия их оценки по сравнению с дисперсией единичного опыта. Если опыты выполняются произвольным образом, то оценки закореллированы.
Ортогональность обеспечивает хорошие статистические свойства оценок и приводит к простой формуле расчета b-коэффициентов регрессионной модели:
.
При этом важно помнить, что планирование эксперимента само по себе не может улучшить физический смысл модели, оно только улучшает ее статистические свойства [9, 12-15].


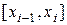 кубический сплайн
кубический сплайн 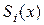 является многочленом третьей степени:
является многочленом третьей степени: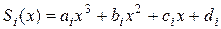 .
.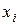 сплайн
сплайн 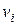 ,
, 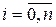 :
: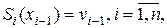
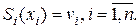
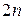 . Во внутренних узлах
. Во внутренних узлах 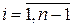 сплайн имеет непрерывную первую и вторую производные:
сплайн имеет непрерывную первую и вторую производные: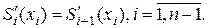
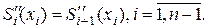
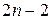 . Для отыскания искомого сплайна требуется найти коэффициенты
. Для отыскания искомого сплайна требуется найти коэффициенты 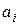 ,
, 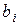 ,
, 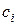 ,
, 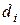 многочленов
многочленов 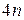 неизвестных. Однако количество уравнений, записанных по условиям (1)–(4) равно
неизвестных. Однако количество уравнений, записанных по условиям (1)–(4) равно 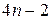 . Чтобы система алгебраических уравнений имела решение, необходимо, чтобы число уравнений равнялось числу неизвестных. Следовательно, для разрешимости задачи нужны еще два дополнительных условия. Их обычно получают из естественного предположения о нулевой кривизне графика сплайна на концах:
. Чтобы система алгебраических уравнений имела решение, необходимо, чтобы число уравнений равнялось числу неизвестных. Следовательно, для разрешимости задачи нужны еще два дополнительных условия. Их обычно получают из естественного предположения о нулевой кривизне графика сплайна на концах: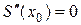 ,
, 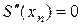 .
.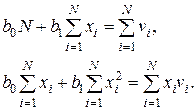
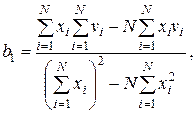
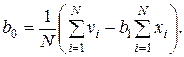
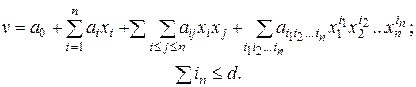
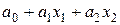 ,
,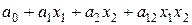 .
.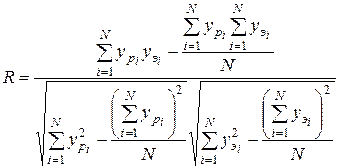
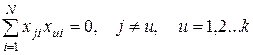 ;
;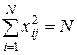 .
.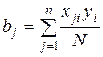 .
.