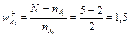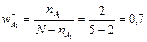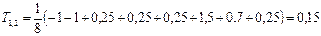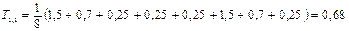- для проверки соответствия выборочных частот распределения случайной величины признака той или иной модели, гипотезе;
- для проверки гипотезы о том, принадлежат ли различные выборки к одной или разным генеральным совокупностям;
- для оценки степени сопряженности между качественными признаками.
Это стандартный набор задач, имеющийся в любом справочнике по непараметрической статистике. Рассмотрим другие важные задачи.
Для оценки степени сходства между объектами по комплексу признаков, оцененных по номинальной шкале, используют показатель сходства, предложенный Сокалом и Снитом (Sokal, Snith, 1963) и таксономический отношение Е.С.Смирнова (Смирнов, 1964).
Рассмотрим показатель сходства по Sokal, Snith, который предполагает одинаковый вклад всех признаков в показатель сходства. Этот показатель определяется как частное от деления числа совпадающих признаков у пары сравниваемых объектов на общее число признаков. Он принимает значения от 0 до 1. Так, если при сравнении двух объектов все признаки совпадают, то показатель сходства равен 1.
Пример. Необходимо определить показатель сходства для 3 сортов по трем признакам: окраске плода, опушению побега и окраске бутона.
№ сорта
Окраска плода
Опушение побега
Окраска бутона
желтая
есть
белая
красная
есть
розовая
фиолетовая
нет
красная
Показатель сходства между 1 и 2 сортом будет равен 1/3 ≈ 0,33.
Между 1 и 3 сортом: 0/3 = 0.
Между 2 и 3 сортом: 0/3 = 0.
В таксономическом анализе Е.С.Смирнова предполагается, что вес модальностей признаков различен в зависимости от частот их встречаемости. Чем реже встречается модальность в выборке, тем её вес больше и наоборот. При этом различают веса по присутствию и по отсутствию одной и той же модальности. Следовательно, учитываются совпадения не только по присутствию тех или иных модальностей признаков, но и по их отсутствию. Всякому несовпадению двух объектов по модальностям приписывается один и тот же вес «– 1».
Итак, Tij – коэффициент сходства между i-м и j-м объектами равен:
, где
M – общее количество модальностей по всем признакам;
wk – вес k – ой модальности либо по присутствию ее, либо по отсутствию, либо по несовпадению их.
Вес по присутствию k - ой модальности (wk+) определяют по формуле:
,
а вес по отсутствию:
, где
N – общее число сравниваемых объектов;
nk – число объектов, у которых данная модальность присутствует.
Пример. Среди 10 сортов, 2 имели опушенную кожицу плодов, 8 неопушенную. Тогда:
Вес по присутствию опушения wk+= (10 – 2) / 2 = 4.
Вес по отсутствию опушения wk– = 2 / (10 – 2) = 0,25.
Поскольку сорта с опушенной кожицей встречаются более редко (2 из 10) вес по присутствию опушения (4) значительно превосходит вес по его отсутствию (0,25).
Пример: Оценка степени сходства между 5 сортами по 3 признакам (таблица).
№ сорта
Окраска листовой пластинки
Опушение листовой пластинки
Форма листовой пластинки
зеленая
есть
овальная
антоциановая
есть
овальная
антоциановая
нет
яйцевидная
зеленая
есть
яйцевидная
пестрая
есть
обратнояйцевидная
Для удобства вычислений необходимо провести кодировку объектов и определить веса по присутствию и отсутствию определенных модальностей (таблица). Обозначит признаки соответственно буквами А, В и С, а их модальности подстрочными цифрами. Присутствие модальности будем обозначать большой буквой, а её отсутствие – маленькой.
Кодировка объектов
№ сор-
та
Окраска листовой пластинки
(А)
Опушение
(В)
Форма листовой пластинки
(С)
зел.
ант.
пестр.
есть
нет
овальн.
яйц.
обр.яйц.
А1
а2
а3
В1
b2
С1
с2
с3
а1
А2
а3
В1
b2
С1
с2
с3
а1
А2
а3
b1
В2
с1
С2
с3
А1
а2
а3
В1
b2
с1
C2
c3
а1
а2
А3
В1
b2
с1
с2
С3
Определим вес по присутствию модальности «зеленая» (А1) признака «окраска листовой пластинки».
Вес по отсутствию этой модальности равен:
Аналогично определяют веса по присутствию и отсутствию для всех модальностей всех признаков.
Веса по присутствию и отсутствию модальностей.
Веса
Окраска плода (А)
Опушение побега (В)
Окраска бутона (С)
А1
А2
А3
В1
В2
С1
С2
С3
wk+
1,5
1,5
0,25
1,5
1,5
wk–
0,7
0,7
0,25
0,25
0,7
0,7
0,25
Общее число модальностей М = 3 + 2 + 3 =8
Определим коэффициент сходства между сортами 1 и 2 (см. таблицу – кодировка объектов).
Поясним, как было получено выражение в скобках. Производим сравнение двух сортов по всем модальностям. Так при сравнении сорта 1 и 2 по модальности А1 (зеленая) наблюдается несовпадение (А1 у 1-го сорта и а1у 2-го. Следовательно, записываем «–1», поскольку, всякому несовпадению двух объектов по модальностям приписывается один и тот же вес «– 1». Далее сравниваем модальности А2 (антоциановая). Здесь также обнаруживается несовпадение (а2у 1-го сорта и А2 у 2-го). Значит, записываем следующее слагаемое тоже «–1». При сравнении сорта 1 и 2 по модальности А3(пестрая) наблюдается совпадение по отсутствию этой модальности (а3 у 1-го сорта и а3 у 2-го). Следовательно, записываем вес по отсутствию данной модальности, который равен 0,25. Аналогично определяются все слагаемые выражения в скобках.
Подобным образом вычисляют коэффициенты сходства между всеми парами сортов.
Помимо оценки сходства между всеми парами объектов в таксономическом анализе Е.С.Смирнова вычисляется для каждого объекта так называемый коэффициент оригинальности. Коэффициент оригинальности представляет собой среднюю сумму весов по присутствию и отсутствию модальностей каждого объекта исследуемой совокупности. Этот коэффициент является мерой оригинальности объекта, то есть, он будет тем больше, чем более редкими модальностями обладает объект. Анализ коэффициентов оригинальности может оказаться очень полезным, например, при оценке той или иной исходной коллекции сортов, линий или гибридов а именно, позволит отобрать образцы, сочетающие комплекс редких модальностей признаков.
Поясним это на примере. Определим коэффициент оригинальности для первого сорта, характеризующий этот сорт по наличию редких модальностей.
Аналогично вычисляют коэффициенты оригинальности для остальных сортов.
Теперь можно построить матрицу коэффициентов сходства и коэффициентов оригинальности (таблица)
Из полученных данных видно, что сорта 1 и 2 и 1 и 4 наиболее сходны между собой, поскольку у них максимальное значения коэффициента сходства (0,15). Сорта 1 и 3 наиболее сильно отличаются
№
0,68
0,15
-0,69
0,15
-0,26
0,15
0,68
-0,16
-0,38
-0,26
-0,69
-0,16
1,61
-0,16
-0,58
0,15
-0,38
-0,16
0,68
-0,26
-0,26
-0,26
-0,58
-0,26
1,41
по проанализированным признакам. Их коэффициент сходства самый маленький (-0,69). Из всех сортов наиболее оригинален сорт 3. Его коэффициент оригинальности составляет 1,61, что выше, чем у остальных сортов. Следовательно, этот сорт сочетает больше редких модальностей.
К полученной матрице коэффициентов сходства можно применить кластерный анализ. Этот метод позволяет последовательно объединять сорта сначала с максимальным коэффициентом сходства, а затем и менее сходные между собой. Результат кластерного анализа представляют в виде дендрограммы, характеризующей группировки объектов. Для полученной матрицы дендрограмма кластерного анализа имеет следующий вид
Кластерный анализ позволяет разделить изучаемую выборку объектов (в данном случае сортов) на группы, кластеры по степени сходства комплекса признаков. Результаты кластеризации оказываются полезными при решении многих сложных биологических проблем, в частности: 1) классификации таксонов разного ранга: родов, видов, разновидностей, форм, сортов, гибридов, линий, популяций и т.п.; 2) оценки сходства гибридов с родительскими формами; 3) подбора родительских форм для скрещиваний по степени их фенотипического сходства и др.
Кроме того, для выделения так называемых «плеяд» сходных объектов можно использовать метод максимального корреляционного пути, который будет рассмотрен ниже.

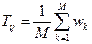 , где
, где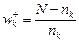 ,
,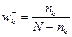 , где
, где