В предыдущих разделах мы рассмотрели задачи исследования операций в детерминированном случае, когда показатель эффективности W зависит только от двух групп факторов: заданных, заранее известных α и элементов решения х. Реальные задачи исследования операций чаще всего содержат помимо этих двух групп еще одну – неизвестные факторы, которые в совокупности обозначим буквой β. Итак, показатель эффективности W зависит от всех трех групп факторов:
W=W(α, х, β).
Так как величина W зависит от неизвестных факторов β, то даже при известных α и х она уже не может быть вычислена, остается неопределенной. Задача поиска оптимального решения тоже теряет определенность, поскольку нельзя максимизировать неизвестную величину W. И все-таки нам необходимо сделать эту неизвестную величину по возможности максимальной. Поставим перед собой следующую задачу. При заданных условиях α, с учетом неизвестных факторов β, найти такое решение х, которое, по возможности, обеспечивает максимальное значение показателя эффективности W.
Это уже другая задача. Наличие неопределенных факторов переводит ее в новое качество: она превращается в задачу о выборе решения в условиях неопределенности.
Задачи принятия решения в условиях неопределенности встречаются очень часто. Например, планируется ассортимент товаров для распродажи на ярмарке. Желательно было бы максимизировать прибыль. Однако заранее неизвестно ни количество покупателей, которые придут на ярмарку, ни потребности каждого из них. Как быть? Неопределенность налицо, а принимать решение нужно!
Другой пример: проектируется система сооружений, оберегающих район от паводков. Ни моменты их наступления, ни размеры заранее неизвестны. А проектировать все-таки нужно, и никакая неопределенность не избавит нас от этой обязанности.
Наконец, еще более сложная задача: разрабатывается план развития вооружения на несколько лет вперед. Неизвестны точно ни конкретный противник, ни вооружение, которым он будет располагать. А решение принимать надо.
Порассуждаем немного о возникшей задаче. Прежде всего, неопределенность есть неопределенность и ничего хорошего в ней нет. Если условия операции неизвестны, мы не можем также успешно оптимизировать решение, как мы это сделали бы, если бы располагали большей информацией. Поэтому любое решение, принятое в условиях неопределенности, хуже решения, принятого при заранее известных условиях. Однако плохое или хорошее – решение все равно должно быть принято. Наша задача – придать этому решению в возможно большей мере черты разумности. Недаром Т.Л. Саати, один из видных зарубежных специалистов по исследованию операций, определяя свой предмет, говорит: «Исследование операций представляет собой искусство давать плохие ответы на практические вопросы, на которые даются еще худшие ответы другими методами».
Для того чтобы принимать решения в условиях неопределенности, наука располагает рядом приемов. Какими из них воспользоваться – зависит от того, какова природа неизвестных факторов β, откуда они возникают и как контролируются. Другими словами, с какого вида неопределенностью мы в данной задаче сталкиваемся?
Прежде всего, рассмотрим наиболее благоприятный для исследования, так сказать «хороший» вид неопределенности. Это случай, когда неизвестные факторы β представляют собой обычные объекты изучения теории вероятностей – случайные величины (или случайные функции), статистические характеристики которых нам известны или в принципе могут быть получены к нужному сроку. Такие задачи исследования операций будем называть стохастическими задачами, а присущую им неопределенность – стохастической (вероятностной) неопределенностью.
Рассмотрим более подробно этот «хороший» вид неопределенности. Пусть неизвестные факторы β представляют собой случайные величины с какими-то, в принципе известными, вероятностными характеристиками – законами распределения, математическими ожиданиями, дисперсиями и т.п. Тогда показатель эффективности W, зависящий от этих факторов, тоже будет величиной случайной. Максимизировать случайную величину невозможно: при любом решении х она остается случайной, неконтролируемой. Как же быть?
Один из способов – заменить случайные факторы β их средними значениями (математическими ожиданиями). Тогда задача становится детерминированной и может быть решена обычными методами. Но весь вопрос в том, насколько случайны эти параметры: если они мало отклоняются от своих математических ожиданий, так поступать можно. Также обстоит дело и в исследовании операций где есть задачи, в которых случайностью можно пренебречь. Например, если составляем план снабжения группы предприятий сырьем, можно в первом приближении пренебречь, скажем, случайностью фактической производительности источников сырья (если, разумеется, его производство хорошо отлажено). Тот же приём – пренебречь случайностью и заменить все входящие в задачу случайные величины их математическими ожиданиями – будет уже опрометчивым, если влияние случайности на интересующий нас исход операции существенно.
Рассмотрим пример. Планируется работа ремонтной мастерской, обслуживающей автобазу. Пренебрежем случайностью момента возникновения неисправностей (то есть, заменим случайное время безотказной работы машин его математическим ожиданием) и случайностью времени выполнения ремонта. Скорее всего, такая мастерская, работа которой спланирована без учета случайности, не будет справляться со своей задачей. То есть очень часто встречаются операции, в которые случайность входит по существу, и свести задачу к детерминированной не удаётся.
Итак, рассмотрим такую операцию, где факторы β «существенно случайны» и заметно влияют на показатель эффективности W, в результате чего он тоже «существенно случаен». Попытаемся взять в качестве показателя эффективности среднее значение (математическое ожидание) этой случайной величины = M[W] (например, прибыль хозяйства за конкретный год при среднемноголетней урожайности высеянных сортов) и выбрать такое решение х, при котором этот усредненный по условиям лет показатель обращается в максимум:
= M[W(α, х, β)] → max.
Заметим, что именно так поступают, выбирая в качестве показателя эффективности в задачах, содержащих неопределенность, не просто «доход», а «средний доход», не просто «время», а «среднее время». Такой подход (называемый «оптимизацией в среднем») иногда вполне оправдан. Действительно, если мы выберем решение так, чтобы среднее значение показателя эффективности обращалось в максимум, то, безусловно, поступим правильнее, чем если бы выбирали решение наобум.
Что же касается элемента неопределенности, конечно, он сохраняется. Эффективность каждой отдельной операции (за один год), проводимой при конкретных значениях случайных факторов β, может сильно отличаться от ожидаемой как в большую, так, к сожалению, и в меньшую сторону. Однако, оптимизируя операцию «в среднем», мы в конечном счете после многих ее повторений выигрываем больше, чем если бы совсем не пользовались расчётом.
Такая «оптимизация в среднем» очень часто применяется на практике в стохастических задачах исследования операций, и пользуются ею обычно не задумываясь над ее правильностью. Чтобы этот прием был правильным, нужно, чтобы операция обладала свойством повторяемости, и «недостача» показателя эффективности в одном случае компенсировалась его «избытком» в другом. Например, если мы предпринимаем длинный ряд однородных операций с целью получить максимальный доход (средний по годам), то доходы от отдельных операций суммируются, «минус» в одном случае покрывается «плюсом» в другом, и все в порядке.
Однако не всегда это допустимо. Чтобы убедиться в этом рассмотрим пример. Организуется автоматизированная система управления (АСУ) для службы неотложной медицинской помощи большого города. Вызовы, возникающие в разных районах города в случайные моменты, поступают на центральный пункт управления, откуда они передаются на тот или другой пункт неотложной помощи с определенным количеством машин. Требуется разработать такое привило (алгоритм) диспетчерской работы АСУ, при котором служба в целом будет функционировать наиболее эффективно. Для этого, прежде всего, надо выбрать показатель эффективности W службы.
Разумеется, желательно, чтобы время Т ожидания врача было минимально. Но это время – величина случайная. Если применить «оптимизацию в среднем», то надо выбрать тот алгоритм, при котором – среднее время ожидания для больного минимально. Однако времена ожидания врача отдельными больными не суммируются: слишком долгое ожидание одного из них не компенсируется почти мгновенным обслуживанием другого. Выбирая в качестве показателя эффективности среднее время ожидания , мы рискуем дать предпочтение тому алгоритму, при котором среднее время ожидания мало, но отдельные больные (в удаленных малонаселенных районах) могут ожидать врача очень долго.
Чтобы избежать таких неприятностей можно дополнить показатель эффективности требованием: фактическое время Т ожидания врача должно быть не больше какого-то предельного значения t0. Поскольку Т – величина случайная нельзя просто потребовать выполнения условия T ≤ t0; можно только потребовать, чтобы оно выполнялось с большой вероятностью, настолько большой, что событие T ≤ t0 будет практически достоверным. Назначим какое-то значение λ, близкое к единице (например, 0,99 или 0,95), и потребуем, чтобы условие T ≤ t0 выполнялось для любого больного с вероятностью, не меньшей, чем λ:
Р(T ≤ t0) ≥ λ.
Введение такого ограничения означает, что из области возможных решений Х (в данной задаче возможных алгоритмов АСУ) исключаются решения, ему не удовлетворяющие. Ограничения подобного типа называются стохастическими ограничениями.
Особенно осторожным надо быть с «оптимизацией в среднем», когда речь идет не о повторяемой, массовой операции, а о единичной, «уникальной». Все зависит от того, к каким последствиям может привести неудача этой операции, то есть случайно реализовавшееся слишком малое значение показателя эффективности W; иногда оно может означать попросту катастрофу. Что толку в том, что операция в среднем (за много лет) приносит большой выигрыш, если в данном, единичном случае она может нас разорить? От таких катастрофических результатов можно спасаться введением стохастических ограничений. При достаточно большом значении уровня доверия λ можно быть практически уверенным в том, что угрожающее разорение нас не постигнет.
Итак, вкратце рассмотрен случай «хорошей» (стохастической) неопределенности и в общих чертах освещен вопрос об оптимизации решения в таких задачах. Но стохастическая неопределенность – это почти определенность, если только известны вероятностные характеристики входящих в задачу случайных факторов. Гораздо хуже обстоит дело, когда неизвестные факторы β не могут быть изучены и описаны статистическими методами. Это бывает в двух случаях: либо а) распределение вероятностей для параметров β в принципе существует, но к моменту принятия решения не может быть получено, либо б) распределение вероятностей для параметров β вообще не существует.
Пример ситуации типа а): проектируется информационная компьютерная система, предназначенная для обслуживания каких-то случайных потоков требований (запросов). Вероятностные характеристики этих потоков требований в принципе могли бы быть получены из статистики, если бы данная система (или аналогичная ей) уже существовала и функционировала достаточно долгое время. Но к моменту создания проекта такой информации нет, а решение принимать надо! Как быть?
Можно применить следующий прием: оставить некоторые элементы решения х свободными, изменяемыми. Затем выбрать для начала какой-то вариант решения, зная заведомо, что он не самый лучший, и пустить систему в эксплуатацию, а потом, по мере накопления опыта, целенаправленно изменять свободные параметры решения, добиваясь того, чтобы эффективность не уменьшалась, а увеличивалась. Такие совершенствующиеся в процессе применения алгоритмы управления называют адаптивными. Преимущество адаптивных алгоритмов в том, что они не только избавляют нас от предварительного сбора статистики, но и перестраиваются в ответ на изменение обстановки.
Теперь обратимся к самому трудному и неприятному случаю б), когда у неопределенных факторов β вообще не существует вероятностных характеристик; другими словами, когда их нельзя считать «случайными». Напомним, что под термином «случайное явление» в теории вероятностей принято понимать явление, относящееся к классу повторяемых и, главное, обладающее свойством статистической устойчивости. При повторении однородных опытов, исход которых случаен, их средние характеристики проявляют тенденцию к устойчивости, стабилизируются. Частоты событий приближаются к их вероятностям. Средние арифметические – к математическим ожиданиям. Если много раз бросать монету, частота появления герба постепенно стабилизируется, перестает быть случайной. Это пример «хорошей» стохастической неопределенности. Однако бывает неопределенность и нестохастического вида, которую мы условно назовем «плохой неопределенностью»: не имеет смысла говорить о «законах распределения» факторов β или других вероятностных характеристиках.
Пример. Допустим, планируется некая торгово-промышленная операция, успех которой зависит от того, юбки какой длины β будут носить женщины через два года. Распределение вероятностей для величины β в принципе, не может быть случайно получено ни из каких статистических данных. Даже если рассмотреть великое множество опытов (годов), начиная с тех отдаленных времен, когда женщины впервые надели юбки, и в каждом из них зарегистрировать величину β, это вряд ли поможет в нашем прогнозе. Вероятностное распределение величины β попросту не существует, так как не существует массива однородных опытов, где она обладала бы должной устойчивостью. Это случай «плохой неопределенности».
Как же найти решение в подобном случае? Вообще отказываться от применения математических методов решения в данном случае не стоит. Некоторую пользу предварительные расчеты могут принести даже в таких скверных условиях.
Пусть ищем решение х, когда показатель эффективности W содержит «плохую неопределенность» - параметры β, относительно которых никаких сведений мы не имеем, а можем делать лишь предположения. Попробуем все же решить задачу.
Зададим какие-нибудь более или менее правдоподобные значения параметров β. Тогда задача перейдет в категорию детерминированных и может быть решена обычными методами. Однако радоваться рано. Допустим, что затратив много усилий и времени мы это сделали. Будет ли найденное решение хорошим для других условий β? Как правило, нет. Поэтому ценность его – сугубо ограниченная. В данном случае разумно будет выбрать не решение х, оптимальное для каких-то условий β, а некое компромиссное решение, которое не будучи оптимальным, возможно, ни для каких условий, будет все же приемлемым в целом их диапазоне. В настоящее время полноценной научной теории компромисса не существует, хотя некоторые попытки в этом направлении в теории игр и статистических решений делаются.
Обычно окончательный выбор компромиссного решения осуществляется человеком. Опираясь на предварительные расчеты, в ходе которых оценивается большое число W для разных условий β и разных вариантов решения х, он может сравнить сильные и слабые стороны каждого варианта и на этой основе сделать выбор (х).
Подчеркнем еще одну полезную функцию предварительных математических расчетов в задачах с «плохой неопределенностью»: они помогают заранее отбросить те решения х, которые при любых условиях β уступают другим, то есть оказываются неконкурентоспособными. В ряде случаев это помогает существенно сузить множество решений, иногда – свести его к небольшому числу вариантов, которые легко могут быть просмотрены и оценены человеком в поисках удачного компромисса.
При рассмотрении задач исследования операций с «плохой неопределенностью» всегда полезно сталкивать разные подходы, разные точки зрения. Среди последних надо отметить одну, часто применяемую в силу своей математической определенности, которую можно назвать «позицией крайнего пессимизма». Она сводится к тому, что, принимая решение в условиях «плохой неопределенности», надо всегда рассчитывать на худшее и принимать то решение, которое дает максимальный эффект в наихудших условиях. Если в таких условиях мы получаем выигрыш, то можно гарантировать, что в любых других он будет не меньше («принцип гарантированного результата»).
Этот подход привлекателен тем, что дает четкую постановку задачи оптимизации и возможность ее решения корректными математическими методами. Но он оправдан далеко не всегда. Область его применения – по преимуществу так называемые «конфликтные ситуации», в которых условия β зависят от сознательно действующего лица («разумного противника»), отвечающего на любое наше решение наихудшим для нас образом.
В более нейтральных ситуациях принцип «гарантированного выигрыша» не является единственно возможным, но может быть рассмотрен наряду с другими. Пользуясь им, нельзя забывать, что эта точка зрения – крайняя, что на ее основе можно выбрать только очень осторожное, «перестраховочное» решение, которое не всегда будет разумным. Скорее следует подумать о том, откуда можно было бы взять недостающую информацию. Здесь все способы хороши – лишь бы прояснить положение.
Следует упомянуть еще об одном довольно оригинальном методе, не очень «объективном», но тем не менее полезном, а иногда – единственно возможном. Речь идет о так называемом методе экспертных оценок. Он часто применяется в задачах, связанных с прогнозированием в условиях «плохой неопределенности» (например, в футурологии). Упрощенно, идея метода сводится к следующему: собирается коллектив сведущих, компетентных в данной области людей, и каждому из них предлагается ответить на какой-то вопрос (например, назвать срок, когда будет совершено то или другое открытие, или оценить вероятность того или другого события). Затем полученные ответы обрабатываются наподобие статистического материала. Результаты обработки, разумеется, сохраняют субъективный характер, но в гораздо меньшей степени, чем если бы мнение высказывал один эксперт.
Подобного рода экспертные оценки для неизвестных условий могут быть применены и при решении задач исследования операций с «плохой неопределенностью». Каждый из экспертов на глаз оценивает степень правдоподобия различных вариантов условий β, приписывая им какие-то субъективные вероятности. Несмотря на субъективный характер оценок каждого эксперта, усредняя оценки целого коллектива, можно получить нечто более объективное и полезное. Таким образом, задача с «плохой неопределенностью» как бы сводится к обычной стохастической задаче.

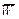 = M[W] (например, прибыль хозяйства за конкретный год при среднемноголетней урожайности высеянных сортов) и выбрать такое решение х, при котором этот усредненный по условиям лет показатель обращается в максимум:
= M[W] (например, прибыль хозяйства за конкретный год при среднемноголетней урожайности высеянных сортов) и выбрать такое решение х, при котором этот усредненный по условиям лет показатель обращается в максимум: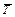 – среднее время ожидания для больного минимально. Однако времена ожидания врача отдельными больными не суммируются: слишком долгое ожидание одного из них не компенсируется почти мгновенным обслуживанием другого. Выбирая в качестве показателя эффективности среднее время ожидания
– среднее время ожидания для больного минимально. Однако времена ожидания врача отдельными больными не суммируются: слишком долгое ожидание одного из них не компенсируется почти мгновенным обслуживанием другого. Выбирая в качестве показателя эффективности среднее время ожидания