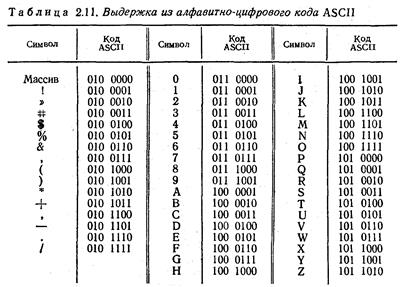
Когда микро-ЭВМ взаимодействует с телетайпом или видеотерминалом, необходимо прибегать к коду, который одновременно включает в себя числовые и алфавитные знаки. Такие коды называются буквенно-цифровыми.
Наиболее распространен буквенно-цифровой код ASCII (произносится АСКИ) — стандартный американский код обмена информации.
В табл. 3.1 приведена выдержка 7-разрядного кода ASCII. В этот список входят 7-разрядные коды цифр, прописных букв и знаков пунктуации. Полный код ASCII включает кодирование строчных букв и признаков команд.
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
Во время передачи, обработки и хранения двоичных кодов в ЭВМ могут произойти ошибки с вероятностью, отличной от нуля, т. е. прием 1 вместо 0, или наоборот. Это может привести к неверному результату работы ЭВМ. Для снижения вероятности получения ошибочного результата разработчики ЭВМ принимают ряд мер, одной из которых является специальное кодирование информации.
Рассмотрим некоторые методы специального кодирования. Двоичные коды, очень удобные для вычислений, создают серьезные осложнения в случаях, где используются переходы между двумя соседними значениями. Примером может служить система управления углом поворота вала или линейных перемещений какого-либо объекта. Два соседних кодовых состояния датчика положения, имеющего выходной сигнал в двоичном коде, могут отличаться во многих разрядах. Например, соседние позиции 7ю и 8ю будут иметь коды 0111 и 1000 соответственно. Часто при переходе от одной позиции к другой возникает кратковременная неопределенность в значениях кода. В результате датчик может выдавать выходные коды 1010, 0101, 1100 и т.д., которые сильно отличаются от старого 0111 и нового 1000 значений. В результате система управления будет вырабатывать неверный управляющий сигнал.
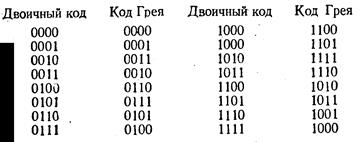
Возникающую погрешность можно уменьшить путем применения кода Грея. Этот код для двух соседних позиций должен отличаться только на 1 бит. Так как все другие биты неизменны во время перехода, то выходной сигнал в переходный момент может представляться только старым или новым значением кода. Поэтому неопределенность уменьшается до значения кода в предыдущей или новой позиции и никаких других кодов не возникает.
Код Грея похож на двоичный тем, что он имеет такую же разрядность и такой же старший разряд. Главное его отличие в том, что два соседних числа в коде Грея отличаются только одним битом. Ниже сравниваются двоичный код и код Грея:
Когда достаточно определить наличие одинарной ошибки в слове, применяют контроль по четности— метод контроля данных при котором сумма двоичных единиц в машинном слове, включая контрольный разряд, должна иметь определенную четность (быть всегда четной или нечетной). Такой метод позволяет обнаруживать одинарные ошибки и принимать меры для -предотвращения их влияния на ход вычислений (например, обеспечивать повторную передачу неверно принятых сообщений).
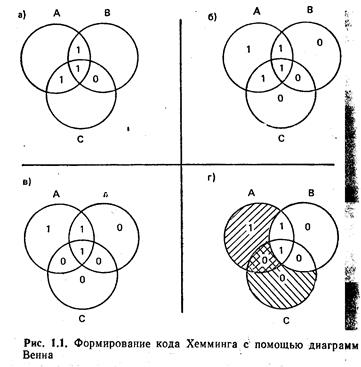
Существует способ, позволяющий не только обнаруживать, но и исправлять возникающие при обработке данных ошибки. Пусть необходимо хранить четыре бита данных, например 1110. Для графического представления предлагаемого способа кодирования воспользуемся диаграммой Венна, состоящей из трех взаимно пересекающихся кругов (рис. 4.2), образующих семь областей. Запишем значения битов хранимого слова во внутренние области на диаграмме. Оставшиеся три области заполним «битами четности». При вычислении их надо помнить, что полное число единиц в каждом круге должно быть четным. Например, в круге А на диаграмме Венна находятся три единицы (рис. 3.2, а). Следовательно, бит четности в круге А должен быть равен 1. По завершении процедуры вычисления битов четности каждая из семи областей будет содержать по одному биту (рис. 3.2,6). Эти семь битов называются кодовым словом, а процедура получения кодового слова из четырехбитового называется алгоритмом кодирования.
Если значение одного из битов кодового слова станет ошибочным (рис. 3.2, в), то для обнаружения ошибки проверяют значения битов четности. Проверка показывает (рис. 3.2, г), что в кругах Л и С произошла ошибка, в круге В—нет. Одна и только одна область на диаграмме принадлежит одновременно кругам А и С, но не принадлежит В. Следовательно, ошибочным является бит, расположенный именно в этой области. Если изменить его значение, то ошибка будет исправлена. Описанная процедура называется алгоритмом декодирования.
Разумеется, процедура корректировки эффективна только в том случае, когда в кодовом слове только одна ошибка. Если возникают две ошибки и более, то их исправить не удастся. Вместо исправления двух ошибок будет привнесена третья. От этого нежелательного эффекта можно избавиться, хотя бы частично, путем добавления еще одного бита четности, расположенного за пределами пересекающихся кругов. Значение этого бита выбирается таким образом, чтобы полное количество единиц на диаграмме было четным. Эта мера не позволяет алгоритму декодирования исправлять двойные ошибки, но она дает возможность их обнаруживать.
Описанный код назван кодом Хемминга в честь его разработчика. Существует несколько разновидностей кодов Хемминга, и все они сравнительно легко реализуются в микропроцессорных средствах обработки информации.