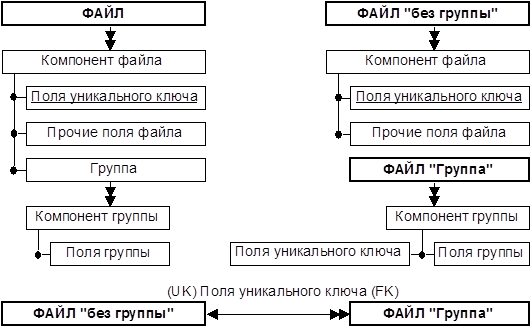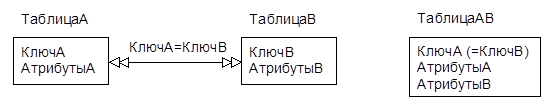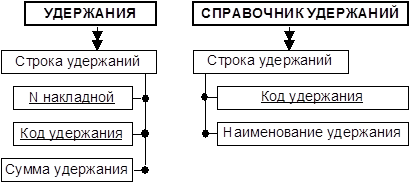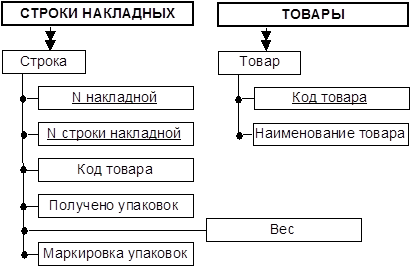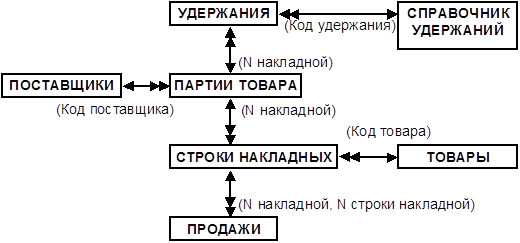Реализация этого запроса на SQL потребует устранения "-квантора с помощью эквивалентностей "x A(x) º Ø$x ØA(x) и Ø(AÚB) º ØA&ØB. В итоге получим формулировку, не удовлетворяющую требованиям языка реляционного исчисления кортежей, но семантически эквивалентную и подходящую для реализации на SQL:
Поскольку (KPst,KDet) является первичным ключом для таблицы Dog (а значит имеется соответствующий индекс), то выделенный жирным курсивом фрагмент можно заменить на:
Воспользуемся представлениями (View), чтобы связать имя W1 с рабочим файлом промежуточных вычислений. (*)
CREATE VIEW W1 AS
SELECT KDet FROM Det WHERE Cvet='КРАСНЫЙ'
· Сформировать файл W2 – делимое.
CREATE VIEW W2 AS SELECT KPst,KDet FROM Dog
· Сформировать файл W3=(W2¸W1).
Деление реализуется довольно громоздко, т.к. оно имеет "$-определение:
W3=(W2¸W1) = НАЙТИ{(r.KPst)/rÎW2}
"sÎW1 $tÎW2 ((t.KDet=s.KDet)&(t.KPst=r.KPst))
Согласно этому определению его можно реализовать, как было описано выше.
Внимание. В этом запросе W2 используется два раза НАЙТИÎW2 и $ÎW2.
В SQL эта проблема решается с помощью псевдонима:
CREATE VIEW W3 AS
SELECT W2.KPst FROM W2
WHERE NOT EXISTS (SELECT * FROM W1
WHERE NOT EXISTS (SELECT * FROM W2 psevdonimW2
WHERE (psevdonimW2.KDet=W1.KDet) AND
(psevdonimW2.KPst=W2.KPst)))
В ObjectPascal эта проблема решается с помощью двух объектов типа TTable, управляющих доступом к таблице W2. Например, W2aTable – для работы во внешнем цикле, и W2bTable – для работы во внутреннем цикле.
· Окончательный ответ [ImPst](Psts*W3):
SELECT Psts.ImPst FROM Psts,W3 WHERE Psts.KPst=W3.KPst
Однако ж окончательный ответ можно было получить уже на предыдущем шаге, т.к.
[ImPst](Psts*W3) = НАЙТИ{(r.ImPst)/rÎPsts}
"sÎW1 $tÎW2 ((t.KDet=s.KDet)&(t.KPst=r.KPst))
Решение задачи «о поставщиках красных деталей» в СУБД FoxPro см. DBL(FOX).doc
4.4. Равносильность по выразимости реляционного исчисления и реляционной алгебры. Пределы представимости в реляционной алгебре. Языки запросов, основанные на реляционной алгебре и исчислении.
5. Проектирование информационных систем и баз данных.
Жизненный цикл программного обеспечения (ЖЦ ПО) (*) - это непрерывный процесс, который начинается с момента принятия решения о необходимости его создания и заканчивается в момент его полного изъятия из эксплуатации. Принято выделять три основных процесса в ЖЦ ПО - разработка, эксплуатация, сопровождение.
Разработка включает в себя работы по созданию ПО в соответствии с заданными требованиями. Обычно выделяют следующие фазы процесса разработки – определение и анализ требований, проектирование и реализация (программирование).
Эксплуатация включает в себя работы, обеспечивающие функционирование ПО в интересах пользователей, - в том числе конфигурирование операционной среды, базы данных и рабочих мест пользователей, локализацию проблем и устранение причин их возникновения.
Сопровождение включает в себя модификацию ПО, поддержку его текущего состояния и функциональной пригодности в соответствии с изменяющимися условиями эксплуатации.
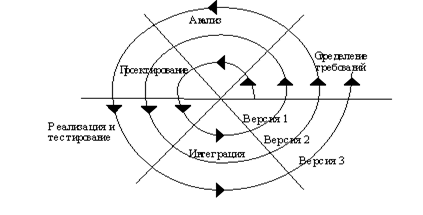
ЖЦ ПО носит итерационный характер: результаты очередного этапа часто вызывают изменения в проектных решениях, выработанных на более ранних этапах. К настоящему времени широкое признание получили варианты спиральной модели ЖЦ.
Спиральная модель ЖЦ.
Спиральная модель ЖЦ делает упор на начальные этапы: анализ и проектирование. На этих этапах реализуемость технических решений проверяется путем создания прототипов. Каждый виток спирали соответствует созданию фрагмента или версии ПО, на нем уточняются цели и характеристики проекта, определяется его качество и планируются работы следующего витка спирали. Таким образом углубляются и последовательно конкретизируются детали проекта и в результате выбирается обоснованный вариант, который доводится до реализации.
Разработка итерациями отражает объективно существующий спиральный цикл создания системы. Неполное завершение работ на каждом этапе позволяет переходить на следующий этап, не дожидаясь полного завершения работы на текущем. При итеративном способе разработки недостающую работу можно будет выполнить на следующей итерации. Главная же задача - как можно быстрее показать пользователям системы работоспособный продукт, тем самым активизируя процесс уточнения и дополнения требований.
Фаза определения и анализа требований (Analysis/Software Requirements).Определение требований выполняется при совместном участии пользователей и специалистов-разработчиков. Результаты этой фазы: список и приоритетность функций будущей ИС, предварительные функциональная и информационная модели ИС (модели процессов и данных предметной области).
Фаза проектирования (Design). Результаты этой фазы:
· общая информационная модель системы (даталогическая модель, модель данных предметной области);
· функциональные модели системы в целом и подсистем (модели процессов предметной области);
· точно определенные интерфейсы между автономно разрабатываемыми подсистемами;
· построенные прототипы экранов, отчетов, диалогов (представленные в виде форм документов, слайдов и программ-прототипов).
Фактически проектирование начинается уже в фазе анализа требований и продолжается в фазе реализации. Принято различать уровни (этапы, стадии) проектирования и соответствующих моделей.
§ Концептуальное проектирование (Conceptual Design) — это сбор, документирование и анализ информации о бизнес-проблеме (о комплексе задач предметной области), выработка способа ее решения и его описание с точки зрения пользователя и с точки зрения бизнеса. Цель этого этапа — учет требований пользователей и реальных условий, в которых будет функционировать программный продукт. Результатом этого этапа является совокупность концептуальных (внешних) моделей, типичных схем и сценариев использования программной системы.
§ Логическое проектирование(Logical Design) — описание структуры решения и взаимодействия составляющих его компонентов с точки зрения группы разработчиков проекта. Цель логического проектирования — учет требований проектной группы. Результат этого этапа — набор бизнес-объектов (объекты предметной области) с соответствующими сервисами (функции объектов), атрибутами (свойства объектов) и взаимосвязями; детальный проект пользовательского интерфейса и логическая модель базы данных (без привязки к конкретной СУБД, платформе...).
§ Физическое проектирование(Physical Design) — описание компонентов, сервисов и технологий, выбранных для получения решения. Цель этого этапа — анализ логического проекта с учетом ограничений, накладываемых существующими технологиями, включая соображения сложности реализации и производительности продукта. Результат физического проектирования — спецификации компонентов программной системы и взаимосвязей между ними, проект пользовательского интерфейса для выбранной платформы и физическая модель базы данных (с привязкой к конкретной СУБД).
Фаза реализации (Development), по другой терминологии фаза конструирования, программирования или собственно разработки. Результатом этой фазы является законченная версия программного продукта, готовая к внешнему тестированию. Иногда в эту фазу включают этап внешнего тестирования и внедрения программного продукта, иногда эти работы выделяют в отдельную фазу ЖЦ ПО.
Одним из возможных подходов к разработке ПО в рамках спиральной модели ЖЦ является получившая в последнее время широкое распространение методология быстрой разработки приложений RAD (Rapid Application Development). Под этим термином обычно понимается процесс разработки ПО, содержащий 3 элемента:
· небольшую команду программистов (от 2 до 10 человек);
· короткий, но тщательно проработанный производственный график разработки версии программного продукта (от 2 до 6 мес.);
· повторяющийся цикл, при котором разработчики, по мере того, как приложение начинает обретать форму, и его версии передаются на эксплуатацию, запрашивают и реализуют в продукте требования, полученные через взаимодействие с заказчиком.
Следует отметить, что методология RAD, как и любая другая, не может претендовать на универсальность, она хороша в первую очередь для относительно небольших проектов, разрабатываемых для конкретного заказчика. В частности, не подходят для разработки по методологии RAD приложения, от которых зависит безопасность людей (например, управление самолетом или атомной электростанцией), так как итеративный подход предполагает, что первые версии наверняка не будут полностью работоспособны, что в данном случае исключается.
В таком процессе разработки особую роль играют CASE-средства проектирования и реализации программных систем(Computer Aided Software Engineering). Эти средства не просто облегчают разработку моделей, документирование процесса в целом и подготовку документации по программному обеспечению. CASE-средства используются для быстрого получения работающих прототипов приложений. Пользователи, непосредственно взаимодействуя с ними, уточняют и дополняют требования к системе, которые не были выявлены ранее. Каждый прототип развивается в часть будущей системы. Таким образом, на следующую фазу передается более полная и полезная информация. Применение единой среды хранения информации о проекте позволяет сохранять информацию о проекте при переходах с этапа на этап и от версии к версии.
5.1. Информационное моделирование процессов предметной области и применение потоковых диаграмм.
Языки потоковых диаграмм, которые мы рассмотрим в этом разделе курса, акцентируют внимание на действиях-процессах, но с точки зрения приема-передачи-хранения-преобразования информации, т.е. откуда (или от кого) действия принимают информацию, куда (или кому) ее передают и как (посредством чего и кого) они преобразуют информацию. Иначе говоря, эти языки информационного моделирования процессов акцентируют внимание на информационных связях между дейстиями-процессами, а не на связях по управлению (порядком выполнения).
В таких языках используются различные виды графовых (сетевых) представлений.
· Двудольный ориентированный граф: два типа вершин - хранилища данных и процессы (обработки данных), ориентированные ребра - потоки данных(DataFlow), которые показывают из каких хранилищ процессы берут входные данные, и в какие хранилища посылают результаты своей работы.
· Простой ориентированный граф: вершины - процессы, ориентированные ребра - потоки данных. Такое представление показывает – «кто (процесс) на кого (процесс) работает и что (поток данных) при этом получает и передает».
· Представление, двойственное предыдущему: вершины - данные, ориентированные ребра – процессы (потоки работ-преобразований, WorkFlow), использующие входные данные и создающие выходные. Представления этого вида заметно больше, чем предыдущие, акцентируют внимание на данных, поэтому их можно трактовать и как модели данных.
Конкретные языки информационного моделирования, естественно, содержат и другие средства - в частности, внешние объекты - конечные пользователи и другие объекты, обменивающиеся данными с информационной системой; средства декомпозиции сложных данных и процессов...
ПОТОКОВЫЕ ОПЕРАЦИОННЫЕ ДИАГРАММЫ С ХРАНИЛИЩАМИ (DFD - Data Flow Diagramming).
Базовые элементы языка.
·
Имя действия (глагол)
Действие (процесс)
Имя потока (существительное)
· Поток данных
· Хранилище данных
· Внешний объект
Группируя более простые действия и данные в более сложные, мы получаем возможность отвлечься (абстрагироваться) от внутренних деталей и сконцентрировать внимание на взаимосвязях между этими сложными действиями и данными. А при необходимости, мы можем сконцентрировать внимание на одном сложном действии или данном, рассмотрев его детализацию (конкретизацию), и отвлечься от внешней для него среды.
Группировка (композиция) и разгруппировка (декомпозиция) действий (процессов) представляется многоуровневыми потоковыми диаграммами, сложное действие представляется (прямоугольником) как единое целое в одной диаграмме и как набор взаимосвязанных действий в детализирующей диаграмме.
Группировка (композиция) и разгруппировка (декомпозиция) потоков представляется как их слияние и разветвление соответственно.
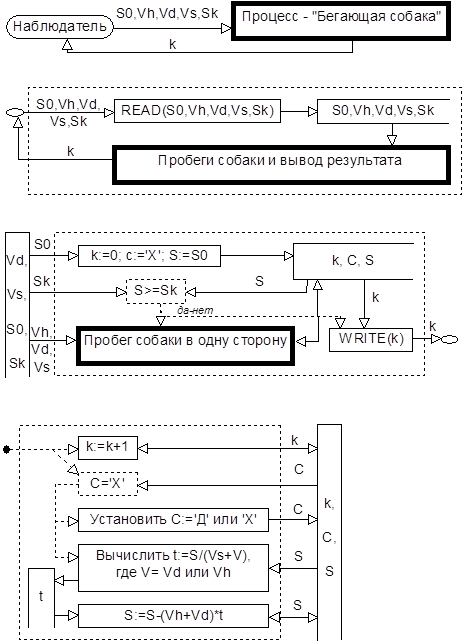
ЗАДАЧА о хозяине, его собаке и его друге.
PROGRAM Pp; VAR S0,Sk,Vh,Vd,Vs:REAL;
S,t:REAL; k:INTEGER; C:CHAR;
BEGIN READ(S0,Sk,Vh,Vd,Vs); S:=S0; C:='Х'; k:=0;
WHILE S>=Sk DO
BEGINIF C='Х' THENBEGIN C:='Д'; t:=S/(Vs+Vd) END
ELSEBEGIN C:='Х'; t:=S/(Vs+Vh) END;
S:=S-t*(Vh+Vd); k:=k+1 END;
WRITE(k) END.
ПРИМЕР Потоковой операционной диаграммы с хранилищами для задачи о бегающей собаке.
Типы потоков и действий. Реальные действия (процессы) и связывающие их потоки могут иметь специфические особенности, которые желательно отобразить в информационной модели. Для этих целей в языках потоковых диаграмм обычно имеются дополнительные средства.
Потоки можно классифицировать на:
· чисто информационные, их особенность состоит в том, что при разветвлении информация может дублироваться и поступать по всем ветвям (например, информация о наличии финансовых средств может поступить от одного источника нескольким адресатам);
· материальные, их особенность состоит в том, что при разветвлении содержимое потока не дублируется, а реально распределяется по ветвям (например, исходящие из одного источника финансовые средства поступят нескольким адресатам не в общей сумме, а в соответствующих долях);
· управляющие (изображены в вышеприведенном примере пунктирными стрелками, причем связывают действия напрямую – без выделения соответствующего хранилища данных), их особенность состоит в том, что информация такого потока имеет директивный характер, она неким образом ограничивает или предписывает условия выполнения действия.
В языке могут быть специальные элементы, которые используются в точках разветвления и слияния потоков, и позволяют фиксировать различия в семантике различных видов разветвления и слияния.
Аналогично можно классифицировать (и соответственно по-разному обозначать) действия (процессы):
· действия приема, передачи и преобразования потоков;
· управляющие действия, имеющие специфический директивный характер (в вышеприведенном примере к таким отнесены «действия проверки условия», изображенные пунктирными прямоугольниками).
Пример [9] модели деятельности условного предприятия «ТОРГОВАЯ СИСТЕМА». TGS.doc (DBLEC\TGS.BP1)
Заказчиком на разработку программной системы является некая организация, занимающаяся оптовой торговлей сельхозпродуктами. В представленной концептуальной модели еще не проведена «граница автоматизации» – из общего набора бизнес-процессов не выделены процессы, выполняемые непосредственно программной системой или с помощью нее.
ВЕРБАЛЬНОЕ ОПИСАНИЕ. «ТОРГОВАЯ СИСТЕМА» предназначена для обслуживания клиентов оптового рынка.
§ Организация заключает договора с поставщиками сельхозпродуктов о приеме и сбыте поставленного товара за соответствующие комиссионные.
§ Партии товаров от поставщиков доставляют транспортные агентства. Прием оформляется соответствующим документом – накладная о приеме партии товара.
§ Покупатели после переговоров с торговыми агентами (сотрудниками организации) принимают решение о приобретении товаров. Продажа оформляется соответствующим документом – квитанция о продаже товара. Грузчики (сотрудники организации) получают инструкции об отгрузке товаров со склада.
§ Ведется учет цен и количества отпускаемых товаров и их комплектации (от каких поставщиков в каком количестве), а также учет комиссионных по сделкам с поставщиками...
§ Управляющий запрашивает сведения о ходе продаж, выполнении договоров с поставщиками...
См. также о языке SADT/IDEF0-диаграмм DB2LSADT.doc
5.2. Информационное моделирование данных предметной области (*).
Рассмотрим одно из хранилищ данных ранее рассмотренного примера «ТОРГОВАЯ СИСТЕМА».
ХРАНИЛИЩЕ ДАННЫХ «Накладные о приеме товаров».
Содержательной единицей хранения является некий документ о партии товара, поставленного неким поставщиком, и сбыте этого товара нашей торговой организацией. В процессе сбыта этот документ пополняется, а по окончании информация этого документа предоставляется поставщику в виде отчета «Об итогах завершающего анализа» по этой партии товаров.
ПОСТАВЩИК: Джон Харрис ЛТД
АДРЕС: НКГР Лондон СВ8
ПОЛУЧАТЕЛЬ:
ДАТА ПРИЕМА:
14 июля 1980
N НАКЛАДНОЙ:
978
ДАТА ПРОДАЖИ:
25 июля 1980
НОМЕР СЧЕТА:
195 015
N КОНТЕЙНЕРА:
аааааааааа
N АВТОМАШИНЫ:
ббббббббббб
СПОСОБ ХРАНЕНИЯ:
вввввввв
ПОЛУЧЕНО
ПРОДАНО
МАРКИРОВКА
К-ВО
ВЕС
К-ВО
ЦЕНА
СТОИМОСТЬ
НАИМЕНОВАНИЕ ТОВАРА: Персики «Красный Дикси» А
XXX
1.00
40.00
1.05
10.50
НАИМЕНОВАНИЕ ТОВАРА: Персики «Красный Дикси» Б
YYY
0.75
75.00
0.77
115.50
0.80
160.00
0.85
25.35
ИТОГО:
427.35
СБОРЫ
ВСЕГО
СБОРЫ:
200.19
ЗА ХРАНЕНИЕ
КОМИССИОННЫЕ
ПРОЧИЕ
8.55
42.74
148.90
ЧИСТЫМИ:
227.16
5.2.1. Нормализация баз данных и функциональные зависимости.
СТРУКТУРА ХРАНИЛИЩА ДАННЫХ «Накладные о приеме товаров».
За основу возьмем структуру вышеприведенного документа.
В итоге мы имеем глубоко структурированное представление хранилища данных.
¨ Это представление обладает рядом положительных качеств.
§ Данные предметной области сгруппированы в набор содержательных документов, к компонентам документов применимы традиционные средства доступа (языка Паскаль).
§ По такому представлению легко подготовить отчет поставщику об итогах сделки по партии товаров.
¨ Но с другой стороны, это представление имеет и много недостатков.
§ Иерархический принцип группировки предполагает некую определенную точку зрения, в данном случае - «чьи товары надо продать». Но данные предназначены для многоцелевого использования. Если на это представление посмотреть с точки зрения «какие товары имеются для продажи», то возникает много вопросов... Решить задачи такого типа конечно можно, но при выбранном способе группировки проблематично воспользоваться, например упорядоченностью по видам имеющихся товаров...
§ Кроме внутренней структуры хранилищ данных (обычно) имеется внешняя структура взаимосвязей между данными из разных хранилищ. Описывать структуру взаимосвязей между сложно структурированными данными довольно трудно. Поэтому уже на уровне спецификаций задач будет оставаться много недоговоренного... с соответствующими последствиями...
ПЕРВАЯ НОРМАЛЬНАЯ ФОРМА. В реляционной модели баз данных рассматриваются только файлы в (первой) нормальной форме - «плоские файлы», точнее таблицы-отношения. Поля таких файлов должны иметь базовый неструктурный тип.
Устранение повторяющихся (внутренних) группировок (приведение к нормальной форме) проводится (многократной) декомпозицией исходного файла на два, связанных по уникальному ключу исходного файла.
При устранении повторяющихся группировок потребуются дополнительные поля («N строки накладной») для ключей межтабличных связей. Для надежной идентификации поставщиков, товаров и удержаний введем соответствующие коды. Вычислимые поля («итого», «всего сборы», «чистыми», «стоимость») исключим. Первичные ключи таблиц подчеркнуты.
В итоге мы получили нормализованную базу данных – многотабличную с межтабличными связями.
Такую БД всегда можно свести к нормализованной однотабличной (универсальная таблица-отношение) - соединением по ключу межтабличной связи, даже если эта связь типа «многие ко многим»:
SELECT КлючА, АтрибутыА, АтрибутыВ
FROM ТаблицаА, ТаблицаВ WHERE КлючА = КлючВ
Взаимосвязи между данными отражают семантику базы данных, унаследованную от предметной области. Поэтому в проектировании БД особое внимание уделяется выбору способа представления зависимостей между данными. Известно, что неудачный выбор может создавать впоследствии трудности при обновлении данных - аномалии.
Аномалии обновления данных. Рассмотрим эти трудности на примере таблицы «Партии товара».
¨ Аномалия вставки(insert).
§ Пусть в таблице уже имеются накладные по некоторым еще не завершенным сделкам с данным поставщиком, и надо добавить новую накладную в связи с заключением новой сделки с этим поставщиком.
Поставщики в БД идентифицируются кодом, но при добавлении накладной надо ввести и его реквизиты – наименование, адрес. Кроме того, придется провести проверку. Если в других накладных этого поставщика указаны другие значения этих реквизитов, то впоследствии могут быть недоразумения. Например, в списке различных наименований окажется больше организаций, чем в списке различных (по коду) поставщиков(*).
§ Пусть имеются сведения о потенциальном поставщике, с которым пока не заключались сделки, но хотелось бы хранить информацию о нем.
В нашей БД можно хранить информацию о таком поставщике, только добавив частично заполненную накладную о фиктивной (пустой) сделке с этим поставщиком. Такие фиктивные сделки тоже впоследствии либо будут вызывать недоразумения в учете сделок, либо будут создавать дополнительные трудности в обработке (их придется «обходить»).
¨ Аномалия удаления(delete). Если с поставщиком заключена единственная сделка, и по каким-то причинам необходимо удалить соответствующую накладную, то будет потеряна информация о наименовании и адресе этого поставщика. Либо, как и в предыдущем случае придется оформлять фиктивную сделку.
¨ Аномалия обновления(update). Если изменился адрес поставщика, то соответствующее изменение придется внести в каждую накладную по сделкам с этим поставщиком.
Причины аномалий исследуются в теории и методологии проектирования БД. Получены результаты об устранении некоторых видов аномалий приведением базы данных к более сильным нормальным формам, чем первая.
ВТОРАЯ НОРМАЛЬНАЯ ФОРМА. Значения неключевых полей должны зависеть от всего ключа в целом, а не от его части.
Уникальным ключом новой таблицы УДЕРЖАНИЯ является пара (N накладной, Код удержания), но поле «Наименование удержания» зависит от части ключа - поля «Код удержания». Можно привести примеры аномалий, используя «код и наименование удержания», аналогично «коду и наименованию поставщика» в вышеприведенных примерах.
Разложим эту таблицу на две.
ТРЕТЬЯ НОРМАЛЬНАЯ ФОРМА. В таблице «ПАРТИИ ТОВАРА» поля «Наименование и адрес поставщика» зависят от поля «Код поставщика», а «Код поставщика» в свою очередь зависит от ключа «N накладной». С другой стороны, поля «Наименование и адрес поставщика» однозначно определяются напрямую по ключу «N накладной». Такая ситуация называется транзитивной зависимостью. В третьей нормальной форме не должно быть транзитивных зависимостей. Отметим, что аналогичная ситуация в таблице «СТРОКИ НАКЛАДНЫХ» для полей «Код товара» и «Наименование товара».
Разложим каждую из этих таблиц на две.
Отметим, что ранее рассмотренные для таблицы «ПАРТИИ ТОВАРОВ» примеры аномалий уже не проявляются в новой БД.
(Упрощенная) ER-диаграмма новой базы данных «Накладные о приеме товаров».
ER/IDEF1X-диаграмма БД «Накладные о приеме товаров».


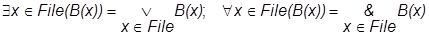
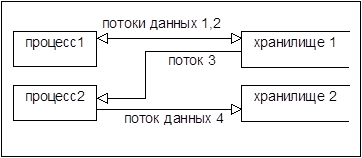

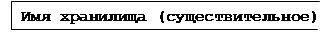
 Внешний объект
Внешний объект