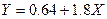Excel располагает средствами, позволяющими прогнозировать процессы. Задача аппроксимации возникает в случае необходимости аналитически описать явления, имеющие место в жизни и заданные в виде таблиц, содержащих значения аргумента (аргументов) и функции. Если зависимость удается найти, можно сделать прогноз о поведении исследуемой системы в будущем и, возможно, выбрать оптимальное направление ее развития. Такая аналитическая функция (называемая еще трендом) может иметь разный вид и разный уровень сложности в зависимости от сложности системы и желаемой точности представления.
Самый простой и популярной является аппроксимация прямой линией - линейная регрессия.
Пусть мы имеем фактическую информацию об уровнях прибыли Y в зависимости от размера X капиталовложений - Y(X). На рисунке показаны четыре такие точки M(Y,X).
Пусть также у нас имеются основания предполагать, что зависимость эта линейная, т.е. имеет вид Y=A+BX. Если бы нам удалось найти коэффициенты А и В и по ним построить прямую (например, такую, как на рисунке), в дальнейшем мы могли бы сделать осознанные предположения о динамике бизнеса и возможном коммерческом состоянии предприятия в будущем. Очевидно, что нас бы устроила прямая, находящаяся как можно ближе к известным точкам M(Y,X), т.е. имеющая минимальную сумму отклонений или сумму ошибок (на рисунке отклонения показаны пунктирными линиями). Известно, что существует только одна такая прямая.
Для решения этой задачи используют метод наименьших квадратов ошибок. Разность (ошибка) между известным значением Yi точки Mi(Yi,Xi) и значением Y(Xi), вычисленным по уравнению прямой для того же значения Хi, составит .
Запишем выражение для суммы квадратов этих ошибок:
Здесь нам известны все X и Y и неизвестны коэффициенты А и В. Пpoведем искомую прямую так (т.е. выберем А и В такими), чтобы эта сумма квадратов ошибок Ф(А,В) была минимальной. Условиями минимальности являются известные соотношения:
и
После преобразований, получим коэффициенты А и В.
,
В случае если величина Y зависит не от одного, а от нескольких параметров Y(x,z,...w), задача нахождения коэффициентов решается аналогично и называется задачей множественной регрессии.
Оценить функциональную близость (в линейном смысле) значений X и Y можно с помощью коэффициента корреляции R, который находится по следующей формуле:
Принято считать, что при R<=0,3 наблюдается слабая линейная связь, при - средняя, при R>=0,7 - сильная, при R>=0,9 - весьма сильная связь, при R=1 - полная функциональная связь (все точки Y(X) лежат на одной прямой). Необходимые вычисления удобно выполнить, пользуясь таблицей:
А
В
С
D
Е
F
G
УРАВНЕНИЕ РЕГРЕССИИ
а+Ьх
=
0,64
+1,80х
R=
0,722
i
Xi
Yi
Xi*Yi
Х2
Y расч.
Y2
2,44
1,0
3,07
25,0
3,71
36,0
4,35
25,0
4,98
16,0
5,62
9,0
6,25
16,0
6,89
36,0
7,53
81,0
8,16
100,0
S
Полученное уравнение регрессии таково:
Для анализа результатов найдем значение функции Y(X) для всех заданных аргументов (столбец F). Видим, что расхождение между фактическими и полученными значениями достаточно заметно. Для вычисления коэффициента корреляции R нам понадобится еще значение суммы квадратов функции (столбец G). В нашем случае R=0,722
В строке 14 все формулы являются суммами вышележащих ячеек в диапазоне с 4 по 13 строки.
Таким образом, если нам понадобится вычислить ожидаемое значение прибыли Y в будущем, например, при капиталовложениях в сумме 20 единиц, нужно подставить их в найденную функцию Y=0,64+1,8*20= 36,64. Однако достоверность такого предположения может оказаться не достаточно высокой, ввиду того, что линейное описание процесса, возможно, слишком примитивно.
Рассмотрим встроенные функции Excel (ЛИНЕЙН() и ТЕНДЕНЦИЯ()) для более быстрого нахождения коэффициентов уравнения линейной регрессии.
ЛИНЕЙН(<известное У>;<известное Х>)- вычисляет два коэффициента линейного уравнения регрессии для множества значений независимой переменной X и зависимой переменной Y. Результат выводится в две смежные ячейки - сначала коэффициент при X, затем - свободный член. Ввиду этого функция должна вводиться как функция обработки массива: выделяются две ячейки для результата, вводится функция и нажимаются клавиши Ctrl+Shift+Enter (вместо обычного Enter).
Пример. Если исходные данные расположены так, как показано на рисунке
А
В
С
D
Е
F
G
H
I
J
К
X
Y
0,6364
1,80
9,44
4,5
4,66
и в В4.С4 введена функция {=ЛИНЕЙН(В2:К2;В1:К1)},результаты в ячейках В4 и С4 можно интерпретировать как коэффициенты линейного уравнения регрессии у = 0,6364х+ 1,8.
ТЕНДЕНЦИЯ(<известное Y>;<известное Х>;<новое Х>)
- вычисляет ожидаемое новое значение Y для нового X, если известны некоторые опытные значения X и Y. Вычисления делаются в предположении, что X и Y зависят линейно.
Пример: Исходные данные расположены в ячейках G4 и G5, результаты - в Н4 и Н5


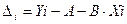 .
.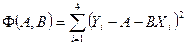
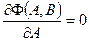 и
и 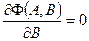
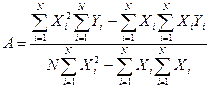 ,
, 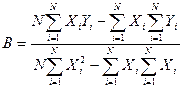
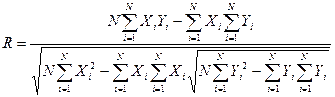
 - средняя, при R>=0,7 - сильная, при R>=0,9 - весьма сильная связь, при R=1 - полная функциональная связь (все точки Y(X) лежат на одной прямой). Необходимые вычисления удобно выполнить, пользуясь таблицей:
- средняя, при R>=0,7 - сильная, при R>=0,9 - весьма сильная связь, при R=1 - полная функциональная связь (все точки Y(X) лежат на одной прямой). Необходимые вычисления удобно выполнить, пользуясь таблицей: