Базы данных— именованные совокупности структурированных, организованных данных, отображающих состояние объектов и их отношений в определенной предметной области.
Данные, отображающие сведения об определенной предметной области, могут поступать из внешней и внутренней среды системы как в неструктурированном виде (например, различные документы на естественном языке), так и в структурированной форме (анкеты, таблицы). Естественно, что способы сбора и обработки таких данных отличаются друг от друга. Эти данные необходимо так структурировать, т. е. создать такие структурированные документы, чтобы стала возможной их программная обработка. В общем случае документ представляет собой зафиксированную на материальном носителе информацию (данные) с реквизитами, позволяющими ее идентифицировать.
Сбор информации осуществляется от источников по каналам получения информации. Отнесение информации к определенной предметной области — сложная классификационная и плохо поддающаяся автоматизации задача, поэтому эта операция, как правило, выполняется специалистами.
Далее осуществляется комплектование БД, т. е. выполняется предварительная обработка и рубрикация информации. Далее неструктурированная информация подлежит структуризации.
Структуризация информации— процесс представления неформализованной документированной информации на информационном языке представления данных в конкретной АИС.
Структурированная информация заносится в БД системы и устанавливается ее связь с уже имеющейся в базе информацией.
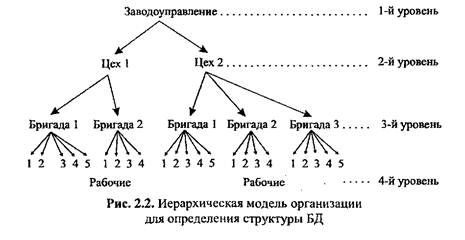
Структура БД организована в зависимости от типа модели данных (иерархическая, сетевая, реляционная). Иерархическая модель — наборы данных, представляющие сущности предметной области и отношения между ними, организованные в виде древовидной (иерархической) структуры (пример на рис. 2.2):
В иерархической модели соблюдается строгая последовательность обхода по вертикали или горизонтали. Операции над данными имеют строгую определенность: найти указанное дерево, в этом дереве найти указанный уровень, в уровне найти указанную запись и т. д. Соблюдается строгая последовательность перехода от родительской сущности к дочерней.
Сетевая модель — наборы данных (объекты), которые имеют связи между любыми объектами любого уровня.
Реляционная модель — наборы данных (объекты) и связи между ними, представленные в виде таблиц (двухмерных массивов).
Но рассматривается и общая для БД логическая структура. БД включает одну или несколько подбаз (файлов, таблиц, массивов). Каждая подбаза состоит из агрегатов данных (записей, документов). Запись состоит из полей. Поля могут быть элементарными (имеют фиксированную и ограниченную длину), составными (агрегаты элементарных), текстовыми (имеют переменную длину и сложную внутреннюю структуру), бинарными (данные, рассматриваемые как поля).
Файл БД - именованная совокупность записей, связанных по каким-либо признакам.
Поле — именованный наименьший элемент записи БД.
Запись — совокупность полей, описывающих один объект.
Так, в реляционной (табличной) БД, представленной в виде совокупности таблиц, информация структурируется следующим образом (см. рис. 2.3).
К физической структуре БД относят файлы первичных (исходных) данных, файлы вторичной (справочной) информации, тезаурусы и словари данных (см. описание лексической базы), индексы.
Файлы исходных данных содержат объекты, подлежащие обработке.
Файлы вторичной информации содержат описания объектов или их элементов.
Индекс — указатель (файл), связывающий адрес объекта с его содержанием. Включает список и частотный словарь.
В настоящее время для создания баз данных (БД) АИС используют различные СУБД — системы управления базами данных. Современные СУБД — это многопользовательские системы, которые специализируются на управлении массивами информации одним или множеством одновременно работающих пользователей.
Среди наиболее известных СУБД можно отметить: иерархические — IMS (Information Management System) фирмы IBM, «ОКА» и «ИНЭС» отечественные, реляционные — MS Access, Lotus Approach, Borland dBase, Borland Paradox, MS Visual FoxPro, MS SQL Server, Oracle.
Современные реляционные СУБД обеспечивают набор средств для поддержки таблиц и отношений между связанными таблицами, развитый пользовательский интерфейс и средства программирования высокого уровня.
СУБД различаются по своим возможностям и требованиям к вычислительной технике.
Различают два основных класса СУБД:
персональные — ориентированы на работу одного пользователя на ПК (dBase, FoxPro, MS Access и др.);
многопользовательские — ориентированы на параллельную работу многих пользователей на больших компьютерах (MS SQL Server).
Персональная СУБД имеет удобный интерфейс и применяется как единая программа.
Информация БД размещается в файлах (в реляционных БД — в табличных файлах).
Часто СУБД приспособлены для работы в сетевой среде, что дает возможность разместить файлы базы данных на файловом сервере и иметь доступ к этой информации всем пользователям, компьютеры которых включены в локальную сеть. Но при этом могут возникнуть большие трудности при одновременной работе нескольких пользователей с одними и теми же данными.
Рассмотрим методику создания реляционной БД в среде FoxPro.
Прежде всего следует осуществить проектирование реляционной структуры БД и выполнить нормализацию таблиц.
Первый этап проектирования БД — построение концептуальной информационной модели организации. Для этого должны быть изучены концептуальные требования заказчика (организации) и на основе анализа этих требований определены сущности. Результатом работ 1-го этапа проектирования БД должен быть список основных сущностей — прообраз будущих таблиц и информационная (концептуальная) модель данных.
Второй этап проектирования — определение взаимосвязей между сущностями. Результатом работ 2-го этапа проектирования БД должна быть схема, отражающая взаимосвязи между сущностями.
Третий этап проектирования — задание первичных и внешних ключей для перехода между сущностями. Результатом работ 3-го этапа проектирования БД должна быть общая таблица с описанием всех сущностей — прообразами будущих таблиц. В таблице, кроме атрибутов (будущих полей), задаются первичные и внешние ключи для каждой таблицы.
Четвертый этап проектирования — приведение модели к требуемому уровню нормальной формы, т. е. выполнение нормализации отношений между таблицами. Следует удалить из БД избыточную информацию. Для этого нужно создать для каждой сущности по одной таблице с ее именем, а полями будут атрибуты сущности. При этом следует выполнить условия:
I.первой нормальной формы таблицы:
· каждое поле должно быть неделимо;
· не должно быть повторяющихся полей или групп полей; второй нормальной формы таблицы:
II.все условия первой нормальной формы;
· первичный ключ однозначно определяет всю запись;
· все поля зависят от первичного ключа;
· первичный ключ не должен быть избыточен; третьей нормальной формы таблицы:
· все условия второй нормальной формы;
· • каждое неключевое поле не должно зависеть от другого неключевого поля.
Пятый этап проектирования — описание каждой таблицы:
Присвоение имен таблицам и полям, определение типа и размера полей, указание полей, по которым надо построить ключи и индексы, определение виртуальных полей, указание назначения каждого поля. Результатом работ 5-го этапа проектирования БД должны быть нормализованные таблицы с полным описанием всех их элементов.
После проектирования БД выполняют ее создание. Пример вида созданных таблиц приведен на рис. 2.4.
Создать файл БД, открыть таблицы и работать с записями можно двумя способами: с помощью специальных команд и с помощью Главного меню.
Для облегчения поиска данных в таблице выполняют индексирование таблиц.
Индексы (указатели) создаются по значениям одного поля (простой) или нескольких полей (сложный). Во время построения индекса записи в таблице сортируются по значениям поля (или полей) будущего индекса. Индекс (ключ) имеет свой тип (Туре): первичный (Primary) — только один, уникальный, а внешние ключи — типы Candidate, Unique или Regular. Если построен один индекс, то он хранится в одноиндексном файле, имеющем расширение .idx. Файлы, хранящие много индексов, называются мультииндексными и имеют расширение .cdx. Создать индекс можно с помощью командной строки и с помощью Главного меню.
Сортировку данных в таблицах осуществляют по возрастанию, или убыванию двумя способами: в соответствии с индексом; с помощью команды SORT.
При поиске данных в таблицах используют два метода:
последовательного (полного) перебора;
деления пополам (по полю текущего индекса).
Поиск методом полного перебора производится по любому полю таблицы с помощью определенных команд или при задании из Главного меню команды: Table—> Go to Record —►Locate.
Поиск данных в таблицах по полю текущего индекса (метод деления пополам) выполняется также с помощью определенных команд или при задании из Главного меню команды: Edit —> Find.
Фильтрация данных осуществляется с помощью фильтров двух видов:
· фильтр для строк, когда ограничивается количество строк;
· фильтр для полей, когда ограничивается количество полей, отображаемых на экране. Для установки фильтра данных используют команду SET FILTER ТО <выражение>.
Очень важным моментом является установление взаимосвязей между таблицами.
Для одновременной работы с несколькими таблицами нужно поместить каждую таблицу в свою рабочую область и установить взаимосвязи между ними. Указатели записей во взаимосвязанных таблицах будут двигаться синхронно.
В старшей таблице указатель перемещается произвольно. В младшей или подчиненной таблице указатель перемещается в соответствии с перемещением указателя в старшей таблице. К одной старшей таблице можно подключать несколько младших.
Родительская таблица должна иметь первичный ключ (индекс). Дочерняя таблица должна иметь внешний ключ (индекс). Одна запись в родительской таблице порождает несколько записей в дочерней. Общее поле, т. е. имеющее одинаковое имя, тип и размер, необходимо для установления взаимосвязи между родительской и дочерней таблицами.
Таблицы могут быть объединены параллельно, последовательно и смешанно.
Перед установлением взаимосвязей все таблицы следует открыть в своих рабочих областях. Связываемые таблицы должны иметь хотя бы одно общее поле, для которого в обеих таблицах (или хотя бы в одной) должен быть построен индекс.
Для организации взаимосвязей «один-к-одному», «один-ко-многим» используют различные команды.
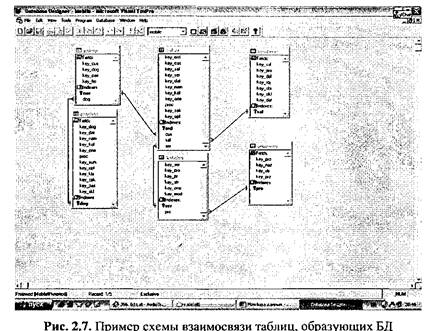
В реляционной БД взаимосвязи между таблицами можно установить также с помощью Главного меню. Для этого предварительно в каждой таблице строят первичный и внешние ключи. Затем выводят на экран диалоговую панель Table Designer. Курсор мыши размещают на имени первичного ключа родительской таблицы и буксируют его внутрь дочерней таблицы, устанавливая на имя соответствующего внешнего ключа. Обратная буксировка (от дочерней таблицы к родительской) недопустима. Проверить, а при необходимости и уточнить параметры взаимосвязи можно с помощью диалоговой панели Edit Relationship. На рис. 2.7 представлен пример схемы взаимосвязи таблиц, образующих БД, по ключевым полям (индексам).
Имеются команды для сведения информации из нескольких таблиц в одну, для корректировки данных в связанных таблицах, для создания итогового табличного файла (содержит суммы по указанным полям).
Меню является основным инструментом диалога в БД. В FoxPro можно создать меню различных типов: световое меню типа FOX и типа dBase, клавишное меню.
Световое меню типа FOX существует в трех вариантах:
произвольного типа — LIGHTBAR-меню;
вертикальное — POPUP-меню;
двухуровневое — PULLDOWN-меню.
Световое меню типа dBase существует в двух вариантах:
вертикальное — POPUP-меню;
горизонтальное — BAR-меню;
Клавишное меню представляет собой набор одно- или дву-клавишных команд.
Для создания клавишного меню используются определенные команды. Для физически существующей таблицы можно создать экранную форму с помощью Мастера форм (Form Wizard) или с помощью Конструктора форм (Form Designer).
Создать отчеты можно с помощью Мастера отчетов (Report Wizard) или Конструктора отчетов (New Report).
Отчеты — это отсортированная информация, которая выводится на экран, в файл или в виде распечатки с помощью принтера.
Табличный отчет — регулярная структура, состоящая из произвольного количества однотипных записей.
Виды отчетов: одностраничный табличный, многостраничный табличный, в свободной форме, почтовая этикетка.
Отчет в свободной форме — информация одной строки таблицы может быть размещена на экране или бумаге произвольным способом.
Почтовая этикетка — разновидность отчета в свободной форме, содержащего на части печатного листа адреса адресата и адресанта.
Мастер отчетов позволяет создать отчет по данным одной или нескольких таблиц. Допускается произвольный выбор полей, сортировка и группировка данных, изменение стиля отображения данных.
Этапы создания отчета: определение окружения; размещение текста; размещение полей, линий, рисунков; перемещение объектов; сохранение отчета.
Один из видов отчета представлен на рис. 2.9.
Многопользовательские СУБД состоят из ядра (сервера) и большого числа программ-агентов, которые обслуживают запросы конечных пользователей, и прикладных программ. Ядро и данные находятся на одном компьютере. Одна копия СУБД управляет одной копией данных. Одновременный доступ к данным многих пользователей и устранение конфликтов организует единая управляющая система.
Банк данных (БнД) — система специально организованных данных, программных, языковых, организационных и технических средств, предназначенных для централизованного накопления и коллективного многоцелевого использования данных. Можно сказать, что БнД включает БД, СУБД, наборы входных и выходных форм, организационные методы и технические средства.
База знаний— именованная совокупность организованных данных и знаний в определенной предметной области и логические правила манипулирования ими для получения необходимых, в том числе новых, знаний. БЗ является, как правило, информационной основой экспертных систем, создание которых — очень трудоемкая работа.
Знания в БЗ должны быть представлены в такой форме, чтобы они могли быть легко обработаны в ЭВМ. Алгоритм обработки знаний заранее неизвестен и строится по ходу решения задачи на основании эвристических правил. Эвристики (правила), по которым решаются задачи, хранятся также в БЗ.
Для формирования БЗ используют три способа приобретения знаний:
диалог эксперта с инженером по знаниям;
автоматическая генерация знаний;
построение индивидуальной модели исследования предметной области конкретным экспертом.
Кроме того, необходимы знания в области математической логики и методов представления знаний, знания возможностей ЭВМ, языков и систем программирования. Для разработки БЗ нужны специалисты, обладающие этими знаниями и исполняющие роль посредников между экспертами в предметной области и системами.
Интеграция данных в базах подразумевает совместное использование данных для решения различных задач. Однако это требует централизованного управления, которое называется администрированием данных. Коллектив специалистов, обслуживающий большие БД, включает администратора, аналитиков, системных и прикладных программистов.
Администратор — специалист, имеющий представление об информационных потребностях конечных пользователей и отвечающий за определение, загрузку, защиту и эффективность БД.