Комментарий. Стек реализуется таким же способом, как в SET4 t[1] указывает на узел в вершине стека, и каждый элемент t[j] в стеке немедленно получает новое значение, как только он исключается из стека. Присваивания {1} и {2} служат для добавления в стек m-1,...,h+1.
Упражнения. 1. Доказать корректность программы SUBSET3.
2. Откорректировать программу так, чтобы она правильно функционировала при k=0.
Последовательно для каждого значения элемента массива двигаемся по дереву, начиная с корня, до точки роста, к которой привешиваем этот элемент. При этом двигаемся по левой ветви, если значение подвешиваемого элемента меньше значения помещенного в этом узле элемента и по правой в противном случае. На языке Паскаль этот алгоритм может реализован процедурой pd, приведенной ниже. В этой реализации мы считаем, что признаком конца массива, расположенного во входном потоке, является появление нулевого значения.
program dersort;
type ref=^yz; yz=record i:integer; l,r:ref end;
var x:ref;
procedure pd(var x:ref);
var z,y,y1:ref;
a: integer;
begin read(a);
if a<>0 then
begin new(x); x^.i:=a; x^.l:=nil; x^.r:=nil;read(a);
while a<>0 do
begin y:=x; new(z); z^.i:=a; z^.l:=nil; z^.r:=nil;
while y<>nil do
begin y1:=y;
if a<y^.i then y:=y^.l else y:=y^.r
end;
if a<y1^.i then y1^.l:=z else y1^.r:=z;
read(a)
end
end
end;
procedure cod(var x:ref);
begin if x<>nil then
begin cod(x^.l); write(x^.i:3); cod(x^.r) end
end;
begin pd(x);cod(x) end.
Построенное дерево обладает следующим интересным свойством:
При симметричном обходе дерева поиска элементы массива перечисляются в порядке возрастания значений элементов.
Это свойство дерева поиска может быть положено в основу построения алгоритма сортировки элементов массива. Однако более интересной является обобщение этой задачи, которую можно сформулировать так:
Необходимость сортировки массив связано, в основном, с тем, что поиск конкретных значений элементов в упорядоченном массиве может быть осуществлен в среднем за O(log2n), где n – число элементов в массиве, а в неупорядоченном за O(n). Предположим, что мы отказываемся от сортировки массивов, заменяя ее построением дерева поиска и поиском конкретных значений элементов в построенном дереве. Давайте оценим эффективность подобной замены.
Ограничимся рассмотрением случая, когда все элементы массива различны. Рассмотрим различные перестановки элементов массива и для каждой такой перестановки построим соответствующее ей дерево поиска. Оценим необходимое число сравнений различных элементов массива для поиска конкретного значения элемента в дереве поиска в среднем по всем возможным перестановкам элементов массива и среднее число сравнений для построения каждого такого дерева.
Пусть Тn –мультимножество всех деревьев, соответствующее всем перестановкам элементов массива.
Замечание. Совокупность Tn действительно представляет мультимножество, однако, если узлы дерева помечать номерами мест откуда взято конкретное значение элемента массива то эта совокупность будет множеством.
Пример, n=3, элементы массива: 1 2 3, тогда возможны следующие деревья поиска:
1 2 3 1 3 2 2 1 3 2 3 1 3 1 2 3 2 1
1 1 2 2 3 3
2 3 1 3 1 3 1 2
3 2 2 1
1 1 1 1 1 1
2 2 2 3 3 2 2 2
3 3 3 3
Обозначим общее число вершин i-го уровня во всей совокупности Tn через m(i,n), а число точек роста, расположенных на i-том уровне, через q(i,n). Установим некоторые соотношение между m(i,n) и q(i,n).
Каждая вершина i-го уровня, при i>1, расположена в конце дуги, исходящей из вершины (i-1)-го уровня, а таких дуг равно удвоенному числу вершин (i-1)-го уровня за вычитом числа точек роста того же уровня, так что
m(i,n)=2 m(i-1,n) - q(i-1,n), i>1
Естественно принять, что m(i,n)=0, при i>n.
Рассмотрим теперь, что происходит при переходе от совокупности Tn к совокупности Tn+1. Каждое дерево из Tn порождает n+1 дерево совокупности Tn+1 соответственно его n+1 точке роста. В каждом из этих деревьев на уровне i сохраняются все вершины i-го уровня исходного дерева и, кроме того, в этой частичной совокупности из n+1 дерева к ним добавится столько новых вершин i-го уровня, сколько точек роста в исходном дереве на i-1, т.е.
m(i,n+1)=(n+1) m(i,n)+q(i-1,n), i>1.
Складывая, полученные равенства, получаем
m(i,n+1)=n m(i-1,n)+`2m(i-1,n), i>1.
Число вершин первого уровня а совокупности Tn равно числу деревьев:
m(1,n)=n!
Оценим, теперь вычислительную сложность поиска конкретного значения элемента в дереве поиска. Прежде всего заметим, что если элемент находится в дереве на i-м уровне, то он обнаруживается после i сравнений.
Пусть tÎ Tn, t – конкретное дерево, обозначим для t число вершин i-го уровня через mt(i), i=1,…,n. тогда среднее число сравнений необходимое для поиска в дереве t будет равно
kt=.
Но, нас интересует среднее значение числа сравнений по всем n! деревьям n-го порядка, образующих совокупность Tn. Оно равно
K(n) = = = .
Но, по определению, = m(i,n), поэтому
k(n) = .
Опираясь на рекуррентное соотношение для m(i,n), можно получить аналогичное соотношение для k(n)
k(n) = ,
а с его помощью доказать (по индукции) справедливость выражения
Так как 2.ln(2)»1.39, среднее время поиска конкретного значения элемента в дереве поиска превышает минимально необходимое на 40%.
Перейдем к задаче определение средней сложности построения дерева поиска.
Пусть некоторому массиву соответствует дерево t, то элемент, размещающийся в вершине уровня i, займет свое место после i-1 сравнения. Отсюда число сравнений, затрачиваемых на организацию этого массива, равно
pt = (i-1).mt(i) = i.mt(i) - .mt(i).
Первая сумма в этом выражении равна n.kt, а вторая дает n – число вершин дерева t, так что
pt =n.kt-n.
Усредняя по всем деревьям из Tn, получаем выражение для среднего числа p(t) сравнений, требуемых для построения дерева:
Так что и здесь вычислительная сложность оказывается больше минимально необходимой в тоже число раз, что для поиска конкретного значения элемента в дереве поиска.
Упражнение. Определить дисперсию числа сравнений, необходимых для поиска конкретного значения элемента в дереве поиска. Эта дисперсия определяется выражением
d(n) = (i-k(n))2 m(i,n)
Деревья.
Определение. Связный граф без циклов называется деревом. Связный граф без циклов с выделенной вершиной называется корневым деревом. Выделенную вершину называют корнемдерева.
Легко определяются понятия: потомка, сына, предка, отца для данной вершины; понятие листа и внутренней вершины.
В программировании большой интерес представляют деревья, вершины которого помечены метками, отличающие одну вершину от другой. В дальнейшем будем считать, что в дереве с n вершинами в качестве меток используются числа 1,…,n.
Заметим, что одно и тоже непомеченное дерево может быть помечено различными способами, т. е. двум различным помеченным деревьям может соответствовать одно и тоже непомеченное дерево.
Пример, n=3.
1 2 3 2 1 3
Теорема(Кэли,1897). Число помеченных деревьев с n вершинами равно nn-2.
Доказательство (Прюфер,1917).
Пусть дерево с n вершинами, помеченными числами 1, …,n. Свяжем с этим деревом последовательность натуральных чисел i1,…,in-2 , построенную следующим образом:
1)положим j=0;
2)повторим следующий процесс n-2 раза:
увеличим значение j на единицу; найдем в дереве лист, помеченный натуральным числом с наименьшим значением. Пусть это значение kj, и пусть отцом листа kj является вершина, помеченная числом ij. Выберем значение ij в качестве j-ого элемента последовательности. Удалим в дереве ребро (ij,kj).
После исполнения этого алгоритма начальное дерево преобразуется в дерево, состоящее из одного ребра либо (in-2,n), либо, в случае in-2=n, – из ребра (n,n-1).
а) b)
1 7 1 7
8 2 3 2 8 3
5 5
6 6
4 4
Заметим, что в приведенном алгоритме, построенный им код определен однозначно.
Рассмотрим алгоритм восстановления дерево по его коду Прюфера i1,…,in-2. Для этого
1. Восстановим заключительное звено дерева. Как было отмечено, им является ребра либо (in-2,n), в случае in-2¹n, либо ребро – (n,n-1), в случае in-2=n.
2. Для восстановления других ребер дерева выполним следующее
2.1 Пусть j=n-2.
2.2 Повторим n-2 раза
Если вершина ij-1 (исключая j=1) еще не включена в дерево, то строим в нем ребро (ij,ij-1); в противном случае строим ребро (ij,m), где m наибольший номер вершины еще не включенной в дерево.
Упражнение. Восстановите деревья по кодам Прюфера, полученным в предыдущем упражнении.
Замечание. Пусть задана произвольная последовательность натуральных чисел i1,…,in-2, каждое из которых из промежутка 1..n. Тогда, по приведенному алгоритму, для этой последовательности может быть построено помеченное дерево, при этом двум разным последовательностям соответствуют два разных дерева.
Таким образом, теорема Кэли следует из установленной биекции.
Рассмотрим теперь задачу построения приведенных алгоритмов на языке Паскаль. Вначале разберем задачу построения кода Прюфера по заданному дереву. Будем считать, что дерево представлено в виде таблицы смежности, а его код Прюфера мы получаем в целочисленном массиве из n-2 элементов, где n – число вершин помеченного дерева.
Замечание. При решении многих задач, связанных с деревьями, выбранное для них представление не является наиболее удобным. В дальнейшем будут рассмотрены другие представления деревьев. В виде списка смежности, вообще говоря, может быть представлен граф самого общего вида, однако при решении данной задачи мы будем исходить из того, представленный в списке смежности граф действительно является деревом. Алгоритм проверки этого свойства представленного графа будет также рассмотрен ниже.
Для решения поставленной задачи мы будем исходить из того, что нам задан следующий глобальный контекст:
program pruff;
const n=7;
type v=^t;
t=record i:1..n; r:v end;
pru=array[0..n-2] of integer; {нулевой элемент – “корень”, равный n}
var k,i,j,a:integer; {n-1 – для основной программы }
sp:array[1..n] of v;
x,y : v;
Тогда процедура построения кода Прюфера выглядит так:
procedure inpruff(var pr:pru); {строит код Прюфера по списку смежности}
var rab:boolean;
begin
for j:=1 to n-2 do
begin k:=1;
В режиме неполного вычисления
логических выражений
оператор repeatможно заменить
оператором
while (sp[k]=nil) or (sp[k]Ù.r<>nil) do
k:=k+1;
repeat
rab:=false;
if sp[k]=nil then k:=k+1
else
if sp[k]^.r<>nil then k:=k+1
else rab:=true
until rab;
a:=sp[k]^.i; pr[j]:=a;
sp[k]:=nil;
x:=sp[a];
while ( x^.i<>k) do begin y:=x; x:=x^.r end;
if sp[a]=x then sp[a]:=x^.r else y^r:=x^.r
end ;
end{inpruff};
Процедура восстановления дерева по коду Прюфера выглядит так:
procedure outpruff; {преобразует код Прюфера в список смежности }
procedure bk(var a,b:integer); {включить вершины a,b в список смежности}
begin new(x); new(y);
x^.i:=a; x^.r:=sp[b]; sp[b]:=x;
y^.i:=b; y^.r:=sp[a]; sp[a]:=y
end{bk};
begin{ outpruff }
for i:=1 to n do sp[i]:=nil; pr[0]:=n;
a:=pr[n-2];
if a=n then i:=n-1 else i:=n; bk(a,i);
for j:=n-2 downto 1 do
{1} if sp[pr[j-1]]=nil then bk(pr[j-1],pr[j])
else begin while sp[i]<>nil do i:=i-1;
bk(i,pr[j])
end
end{outpruff};
Комментарий. Нулевой элемент в описании типа pru введен для корректного вычисления, в случае j=1, логического выражения в условии оператора {1}. В массиве pr, используемого процедурой outpruff в качестве значения кода Прюфера, нулевому элементу присвоено значение равное n.
Замечание. Код Прюфера является оптимальным по памяти кодирования деревьев. В самом деле, W =Wn, где Wn – конечные множества. Предположим, что при каком-то способе кодирования элементов из W для запоминания одного элемента из Wn используется самое большое f(n) бит памяти. Кодирование f(n) называется оптимальным, если =1, где h(n) = log2ô Wnô.
Для оценки энтропия h(n) для множества деревьев с n вершинами по теореме Кэли имеем h(n) = (n-2)log2n. Отсюда следует, что кодирование деревьев кодом Прюфера необходимо f(n) = (n-2)log2n , бит памяти, и поэтому =1.
При задании дерева списками смежности имеем =3 для неориентированных графов, и =2 для ориентированных.
В. А. Евстигнеев. Применение теории графов в программировании. Наука. 1985.
Статистическая теория деревьев (по А. Реньи).
Начнем со следующего вопроса: сколько висячих вершин может быть у дерева с n вершинами? На первый взгляд ответ кажется тривиальным. Число t висячих вершин всегда удовлетворяет неравенству 2£t£n-1, причем как предельные случаи (прямолинейный маршрут и звезда), так и все промежуточные случаи осуществимы. Но такой ответ на поставленный нами вопрос нельзя считать исчерпывающим. Действительно, если число n очень велико, то среди огромного числа возможных конфигураций (напомним, что существует nn-2 вариантов строения помеченных деревьев с n вершинами) предельные случаи t=2 и t=n-1 крайне редки: случай t=n-1 встречается только n раз, а случай t=2 встречается n!/2 раз. Хотя число n!/2 само по себе велико, оно все же (как следует из формулы Стирлинга) очень мало по сравнению с nn-2. Учитывая это, поставим наш вопрос несколько иначе: сколько помеченных деревьев с n вершинами имеют ровно t висячих вершин? В частности, сколько помеченных деревьев с n вершинами обладают наибольшим числом висячих вершин? В новой постановке наш вопрос можно сформулировать также следующим образом: если nn-2 различных помеченных деревьев с n вершинами сложить в большую шляпу и вытягивать их оттуда наугад по одному, каждый раз подсчитывая у извлеченного дерева число висячих вершин, то с какой вероятностью будет встречаться то или иное число? Более кратко тот же вопрос можно поставить и так: сколько висячих вершин у “типичного” дерева с n вершинами?
Глава 8 Теорема о сложности рекурсивных программ
Теорема*. Пусть a, b, c неотрицательные постоянные. Решение рекуррентного уравнения
,
где n – степень числа c, имеет вид:
Доказательство.
Если n – степень числа c, то T(n) =, где .
Если a<c, то сходиться и, следовательно, T(n) = O(n).
Если a=c, то каждый член этого ряда равен единице, а всего в нем О(log n) членов. Поэтому T(n) = O(n×log n).
Если a>c, то , что составляет , или .
Из теоремы вытекает, что разбиение задачи размера n ( за линейное время) на две подзадачи размера n/2 дает алгоритм сложности O(n×log n).
Из теоремы вытекает, что разбиение задач размера n (за линейное время) на две подзадачи размера n/2 дает алгоритм сложности O(n log n). Если бы подзадач было 3,4,8, то получился бы алгоритм сложности nlog3,n2, n3 соответственно.
С другой стороны, разбиение задачи на 4 подзадачи размера n/4 дает алгоритм сложности O(n log n), а на 9 и 16 – порядка nlog3, n2 соответственно. Поэтому асимптотически более быстрый алгоритм умножения целых чисел (см. ниже) можно было бы получить, если бы удалось так разбить исходные целые числа на 4 части, чтобы суметь выразить исходное умножение через 8 или менее умножений. Другой тип рекуррентных соотношений возникает в случае, когда работа по разбиению задачи не пропорциональна ее размеру.
Если n не является степенью числа c, то ,обычно, можно вложить задачу размера n в задачу размера n’, где n’ – наименьшая степень с, большая или равная n. Поэтому порядки роста, указанные в теореме, сохраняются для любого n. на практике часто можно разработать рекурсивные алгоритмы, разбивающие задачи произвольного размера на c равных частей, где с велико, насколько возможно. Эти алгоритмы, как правило, эффективней (на постоянный множитель) тех, которые получаются путем представления размера входа в виде ближайшей сверху степени числа c.
Пример 1. Нахождение наибольшего и наименьшего элементов.
Вход: множество S из n элементов, где n степень числа 2, n³2.
Выход: наибольший и наименьший элементы множества S.
Метод: К множеству S применяется рекурсивная процедура MAXMIN. Она имеет один аргумент, представляющий собой множество S, такое, что |S|=2k при некотором k³1, и вырабатывает пару (а, b), где а – наибольший и b – наименьший элемент в S.
Procedure MAXMIN(S);
1 if |S|=2 then
begin
2 пусть S={a,b};
3 return (MAX(a,b),MIN(a,b))
end
else
begin
4 Разбить S на два равных полмножества S1 и S2;
5 (MAX1,MIN1):=MAXMIN(S1);
6 (MAX2,MIN2):=MAXMIN(S2);
7 return (MAX(MAX1,MAX2),MIN((MIN1,MIN2)
end.
Заметим, что сравнение элементов множества S происходит только на шаге 3, где сравниваются два элемента множества S, из которых оно состоит, и на шаге 7, где сравниваются MAX1 с MAX2 и MIN1 с MIN2. Пусть T(n) – число сравнений элементов множества S, которые надо произвести в процедуре MAXMIN, чтобы найти наибольший и наименьший элементы n-элементного множества.
Ясно, что Т(2)=1. Если n>2, то T(n) – общее число сравнений, произведенных в двух вызовах процедуры MAXMIN (стоки 5 и6),работающих на множествах размера n/2 и еще два сравнения в строке 7. таким образом
(1)
Решение рекуррентных уравнений (1) служит функция T(n)=n-2. Легко проверить, что эта функция удовлетворяет (1) при n=2, и если она удовлетворяет (1) при n=m, то
T(2m)=2 (-2)+2=(2m)-2,
т.е. она удовлетворяет (1) при n=2m. Таким образом, индукцией доказано, что T(n)= -2 удовлетворяет (1), если n степень 2.
Докажем*, что для одновременного нахождения наибольшего и наименьшего элементов n-элементного множества надо сделать не менее -2 сравнений его элементов.
Различные стадии работы такого алгоритма над n-элементным множеством опишем четверкой (a,b,c,d), где a элементов вообще не сравнивались, b элементов участвовали в сравнениях и всегда были большими, c элементов участвовали в сравнениях и всегда были меньшими, d элементов участвовали в сравнениях и были как большими так меньшими. Начальная конфигурация характеризуется – (n,0,0,0); конечная – (0,1,1,n-2). Из конфигурации (a,b,c,d) можно перейти либо в себя, либо в
(a-2, b+1, c+1, d), если а³2;
(a-1, b, c+1, d) или (a-1,b+1,c,d), если а³1;
(a, b-1, c d+1), если b³2;
(a, b, c-1, d+1), если c³2.
Отсюда следует, что требуется +b+c-2 сравнений, чтобы из (a, b, c, d) получить (0, 1, 1,a+b+c+d-2).
Пример 2. Умножение двух n-разрядных двоичных чисел.
Традиционный метод требует О(n2) , битовых операций. Рассмотрим метод, в котором достаточно битовых операций порядка ».
Пусть x и y – два n-разрядных двоичных чисел. Снова будем считать для простоты, что n есть степень 2. Разобьем
y = y =
Если рассматривать каждую из этих частей как (n/2)-разрядные число, то можно представить произведение z=xy в виде
z=(a×2n/2+b)(c×2n/2+d)=ac×2n+(ad+bc)2n/2+bd (1)
Равенство (1) дает способ вычисления произведения xy с помощью четырех умножений (n/2)-разрядных чисел и нескольких сложений и сдвигов (умножение на степень 2). Произведение z чисел x и y также можно вычислить по следующей программе:
begin
u:=(a+b)×(c+d); u:=(a+b)×(c+d);
(2)
v:=a×c;
w:=b×d;
z:= v×2n+(u-v-w)2n/2+w
end
На время забудем, что из-за переноса a+b и c+d могут иметь n/2+1 разрядов, и предположим, что они состоят из n/2 разрядов. Наша схема для умножения двух n-разрядных чисел требует только трех умножении (n/2)-разрядных чисел и нескольких сложений и сдвигов. Для вычисления произведений u,v и w можно применить эту программу рекурсивно. Сложение и сдвиги занимают О(n) времени. Следовательно, временная сложность умножения двух n-разрядных чисел ограничена сверху функцией
(3)
где k – постоянная, отражающая сложение и сдвиги в выражениях, входящих в (2).
Решение рекуррентных уравнений (3) ограничено сверху функцией
3k×»3.
В самом деле, покажем, что T(n)=3k×-2k×n. Применим индукцию по n.
n=1 – тривиально.
Если функция T(n)=3k×-2k×n удовлетворяет (3) при n=m, то
T(2m)=3T(m)+2km=3[3k×-2km]+2km=3k×-2k×(2m).
Так, что она удовлетворяет (3) и при n=2m. Отсюда следует, что T(n)£3k×.
Замечание. Попытка использовать в индукции 3k×вместо 3×-2кn не проходит.
Для завершения описания алгоритма умножения мы должны учесть, что числа a+b и c+d, вообще говоря, имеют n/2+1 разрядов, и поэтому произведение (a+b)(c+d) нельзя вычислить непосредственно применением нашего алгоритма к задаче размера n/2. вместо этого надо записать a+b в виде а1×2n/2+b1, где а1 равно 0 или 1. Аналогично запишем c+d с1×2n/2+d1/ тогда произведение (a+b)(c+d) можно представить в виде
а1×c1×2n+(a1×d1+b1× c1)×2n/2+b1×d1. (4)
Слагаемое b1×d1 вычисляется с помощью рекурсивного применения нашего алгоритма умножения к задаче размера n/2. остальные умножения в (4) можно сделать за время О(n), поскольку они содержит в качестве одного из аргументов либо единственный бит а1 или с1, либо степень числа 2.
Упражнение. Решите следующие рекуррентные уравнения, считая, что T(1)=1:
a) T(n)=a×T(n-1)+ b×n
b) T(n)=a×T(n/2)+ b×n×log2n
c) T(n)=a×T(n-1)+ b×nc
d) T(n)=a×T(n/2)+ b×nc
Глава 9 Производящие функции
При доказательстве тех или иных комбинаторных тождеств часто используется одно или одновременно два из следующих правил:
Правило суммы. Если объект А может быть выбран m способами, а объект В другими n способами, то выбор “либо А, либо В” может быть осуществлен m+n способами.
Правило произведения. Если объект А может быть выбран m способами и после каждого из таких выборов объект В в свою очередь может быть выбран n способами, то выбор “А, и В” в указанном порядке может быть осуществлен m×n способами.
Примеры. На основе этих правил в курсе математического анализа легко были получены формулы для числа k-перестановок и числа k-сочетаний из n объектов, а именно
= n(n-1)…(n-k+1)
=
Упражнение. Докажите, что число k-перестановок из n объектов с повторениями равно nk.
Задача. Доказать, что число k-сочетаний из n объектов с повторениями равно .
Решение (Л. Эйлер): Пусть X={1,2,…n} и рассмотрим любое из k-сочетаний с повторениями с1с2…сk этих n чисел (считаем, что в сочетании с1с2…сk элементы выписаны в неубывающем порядке). Естественно, что в каждом сочетании вследствие возможности неограниченных повторений любые рядом стоящие элементы могут быть одинаковыми. Ввиду этого обстоятельства строим с помощью соотношений
d1=c1+0; d2=c2+1;…; di=ci+i-1;…; dk=ck+k-1
последовательность элементов d1d2…dk следовательно, при любых элементах ci элементы di всегда различны. Ясно, что отображение с1с2…сk в d1d2…dk биективно. Число последовательностей из элементов di равно числу k-сочетаний без повторений из элементов от 1 до n+k-1, т. е. .
Производящие функции для сочетаний.
Для примера рассмотрим три объекта, обозначенные x1, x2, x3. Образуем произведение
(1+x1t)(1+ x2t)(1+x3t).
Перемножив и разложив это произведение по степеням t, получим
1+(x1+x2+x3)t+(x1x2+x1x3+x2x3)t2+x1x2x3t3,
или
1+а1t+а2t2+а3t3,
где а1, а2, а3 – элементарные симметрические функции трех переменных x1, x2, x3. Эти симметрические функции определяются вышеприведенным выражением. Можно заметить, что число слагаемых каждого коэффициента аm (m=1,2,3) равно числу сочетаний из трех элементов по k. Следовательно, число таких сочетаний получается приравниванием каждого xi единице, т. е.
(1+t)3=
Для случая n различных объектов, обозначенных x1, . . . , xn ясно, что
поэтому выражение (1+t)n называют перечисляющей функциейсочетаний из n различных объектов. Этот результат можно также обосновать следующими комбинаторными рассуждениями:
В произведении (1+x1t)(1+ x2t)× . . . .×(1+xnt) каждый множитель является биномом, который благодаря наличию в нем слагаемых 1 и xi указывает на возможность наличия или отсутствия в каждом из сочетаний элемента xi. Это произведение порождает сочетания, так как коэффициент при tm в нем получается выбором “1” в n-m из n двучленных множителей и в m оставшихся после такого выбора множителях - членов вида xit всеми возможными путями. Эти коэффициенты по самому их определению являются m-сочетаниями. Каждый элемент в любом сочетании может появляться не более одного раза, ибо любой множитель состоит только из двух слагаемых.
Обобщая эти комбинаторные рассуждения, для случая, когда прежние множители вида 1+xit заменяются множителями вида 1+xt+xt2+ … +xtj, построим производящую функцию для сочетаний, в которых элементы xi могут содержаться 0,1,2,…,j раз. Более того, множители производящей функции можно совершенно независимо друг от друга приспосабливать к любым требованиям задачи. Так, например, если xk должно всегда входить четное число раз, но не более чем 2k раз, то k-й множитель следует выбирать в виде
1+xt+xt4+ … +xt2k .
Таким образом, производящая функция для любой задачи описывает не только виды элементов, но и виды искомых сочетаний.
Пример. Для сочетаний с неограниченным повторением элементов n и без ограничения на число появлений любого элемента перечисляющей производящей функцией будет
(1+t+t2+. . .)n
или, что же самое
(1-t)-n = ==.
Упражнение. 1. Постройте производящую функцию для сочетаний с повторениями, в которых каждый элемент входит, по крайней мере, один раз.
2. Постройте производящую функцию для сочетаний с повторениями, в которых любой элемент обязательно появляется в сочетании, но только четное число раз.
Производящие функции для перестановок.
В случае коммутативных алгебраических операций произведения х1х2 и х2х1 одинаковы. Поэтому производящую функцию, описывающую перестановки, невозможно построить так, как это было сделано для сочетаний. В случае n различных элементов из соотношения p(n,m)=”число m-перестановок” вытекает, что (1+t)n = , т. е. в разложении выражения (1+t)n число p(n,m) является коэффициентом при . Этот факт указывает пути обобщения.
Если какой-либо элемент может появляться 0,1,…,k раз или если существует k элементов данного вида, то множитель 1+t в левой части равенства заменяется множителем 1+t++…+. Это объясняется тем, что число перестановок из n элементов, p из которых одного вида, q другого и т. д., равно
.
Это число оказывается коэффициентом при в произведении
×× × ×, n=p+q+…,
что в точности соответствует необходимым требованиям.
Определение и простейшие свойства производящих функций.[3]
Определение. Обычной производящей функцией для последовательности a0,a1,… называется формальная сумма
A(t)=a0+a1t+a2t2+ … antn+… . (1)
Экспоненциальной производящей функцией для той же последовательности называется сумма
Е(t)=a0+a1t+a2t2/2!+ … antn/n!+… . (2)
В связи с этими определениями необходимо сделать несколько замечаний. Во-первых, элементы последовательности a0,a1,…, как видно, из самих обозначений, упорядочены, но не обязательно должны быть различны. Во-вторых, переменная t производящей функции никак не определена.
На производящих функциях можно определить формальные операции, такие как сложение, умножение, дифференцирование и интегрирование по t, и выявить зависимости в этой алгебре, в частности путем приравнивания коэффициентов при степенях tn после выполнения этих операций. С этой точки зрения неуместно ставить вопрос о сходимости соответствующих рядов.
Алгебра степенных рядов A(t), определяющих производящие функции, известна под именем алгебры Коши, а алгебра степенных рядов E(t), определяющих экспоненциальные производящие функции, известна как символическое исчисление Блиссара. В статистике функция E(t) фигурирует как производящая функция моментов; E(t) используется также в теории чисел.
В комбинаторике неизбежно возникают производящие функции, отличные от А(t) или E(t), например, сумма вида
G(t)= a0f0(t)+a1f1(t)+a2f2(t)+ … anfn(t)+…, (*)
для которой единственным требованием является линейная независимость функций f0(t), f1(t),…(для того чтобы сделать выражение однозначным). A(t) и E(t) являются частными случаями этого выражения.
Наконец, для любителей операций над непрерывными переменными следует отметить, что аналогом обычной производящей функции с одной переменной служит несобственный интеграл
А(t)=
Этот факт, по-видимому, более известен для случая экспоненциального ядра е-tk, т. е. для преобразования Лапласа
А(t)=
Выражение, включающее в себя как частные случаи оба приведенные выше интеграла и степенные ряды, представляет собой интеграл Стильтьеса
А(t)=,
в котором t – параметр. Чтобы получить сумму (1), в качестве функции F(t,k) выбираем ступенчатую функцию. Эта функция имеет скачки при к=0,1,2,…; скачок в точке k равен tk.
Элементарные соотношения между обычными производящими функциями.
Обозначим через A(t), B(t), C(t) производящие функции, соответствующие последовательностям (ак), (bк), (cк), тогда в качестве непосредственного следствия из самого определения последовательности (а) получаем две пары соотношений; в каждой паре выполнение одного из соотношений влечет за собой выполнение второго
Сумма ак=bк+cк
A(t)=B(t)+C(t)
Произведение ак=bкc0+bк-1c1+…+b1cк-1+b0cк
A(t)=B(t)×C(t)
Последовательность (ак) называется сверткой (bк) и (cк), если A(t)=B(t)×C(t). Сумма и произведение обладают свойствами коммутативности и ассоциативности.
Для экспоненциальных производящих функций соответствующие соотношения определяются следующим образом:
Пусть E(t), F(t), G(t) экспоненциальные производящие функции, соответствующие последовательностям (eк), (fк), (gк), тогда
Сумма eк=fк+gк
E(t)=F(t)+G(t)
Произведение eк=fкg0+fк-1g1+…+f1gк-1+f0gк
E(t)=F(t)×G(t)
Решение линейных рекуррентных уравнений.
Пример. Найдем производящую функцию к числам Фибоначчи: F0=F1=1, Fn+2=Fn+Fn+1, n³0.
Производящая функция F(t) для последовательности F(0),F(1),F(2),… удовлетворяет уравнению
Используя метод неопределенных коэффициентов, найдем
=+
т. е.
F(t)=A(1-at)-1+B(1-bt)-1=A+B=tk
и
Fk=+
Замечание. этот метод можно перенести на произвольное линейное уравнение с постоянными коэффициентами.
Задача 1. Пусть задана последовательность Фибоначчи
F0=F1=1, Fn+2=Fn+Fn+1, n³0.
Рассмотрим множество последовательностей из нулей и единиц длины n, в которых нет двух рядом стоящих единиц. Пусть таких последовательностей A(n). Тогда А(n)=Fk+1.
Доказательство.
Имеем А(0)=1, так как существует только одна – пустая, такая последовательность; А(1)=2, так как существует две такие последовательности – ‘0’ и ‘1’.
Заметим, что число последовательностей длины n, у которых на n месте находится нуль, равно А(n-1).
Все последовательности длины n+1 могут быть построены из последовательностей длины n приписыванием к каждой из них на n+1 место нуля и, кроме того, тем из них, которые на n месте имеют ноль, можно также приписать единицу. Таким образом, А(n+1)=A(n)+A(n-1)=Fn+1+Fn=Fn+2.
Задача 2. "n>0 А(n)==.
Доказательство.
А(n) можно получить следующим образом:
Заметим, что каждая такая последовательность длины n может содержать не более [(n+1)/2] единиц. Подсчитаем, сколько существует последовательностей, содержащих k единиц, 0£k£[(n+1)/2]. Если последовательность имеет к единиц, то она содержит n-k нулей. Рассмотрим последовательность из n-k нулей. Тогда в этой последовательности имеется n-k+1 мест для расстановки k единиц. Т. е. общее число требуемых последовательностей длины n,содержащих k единиц, равно . Таким образом, A(n)= .
Для дальнейшего анализа задач, связанных с двоичными деревьями определим их число, т. е. вычислим число неизоморфных двоичных деревьев с n вершинами.
Пусть Cn – число неизоморфных двоичных деревьев с n вершинами, тогда
C0 = 1 - одно дерево, представленное пустым множеством вершин
C1 = 1 ·
C2 = 2 · ·
· ·
C3 = 5 · · · · ·
· · · · · ·
· · · ·
Из рекурсивного определения бинарного дерева справедливо следующее рекуррентное соотношение
C0=1
Cn=Ck Cn-k n>0
Рассмотрим производящую C(x) = , тогда на основе определения произведения производящих функций и указанного выше рекуррентное соотношение имеем
C(x) = x×C2(x)+1
или
x×C2(x)-C(x) +1 = 0 {*}
Предположим, что существует функция C(x), аналитическая в окрестности нуля, удовлетворяющая этому уравнению. В силу регулярности такой функции существует ее разложение в окрестности нуля в степенной ряд (ряд Тейлора) и этот ряд удовлетворяет этому же уравнению {*}.
Для того чтобы найти необходимую аналитическую функцию, рассмотрим {*} как квадратное уравнение относительно C(x). Значение искомой аналитической функции в точке x, при x¹0
C(x) = {**}
Найдем разложение C(x) в степенной ряд
Разложим в ряд Маклорена
Для n>0 имеем
= ×(-1)×( -2) × × ×(-n+1)××(-4)n =
= 2n×(-1)×1×3 × × × (2n-3)×
и следовательно
= 1-= 1-= 1-2=
1-
отсюда видно, что для получения решения с положительными коэффициентами следует в {**} выбрать знак минус.
Т. е.
C(x) = = = .
Отсюда окончательно получаем
Cn =
Число Cn называется числом Каталана, они часто появляются в контексте целого ряда других комбинаторных задач.
Во многих приложениях удобно представлять перестановки в циклической форме.
Рассмотрим производящую функцию Сn(t)=, определяющую число перестановок n-го порядка, имеющих k циклов, т. е. С(n,k) определяет число перестановок n-го порядка, имеющих k циклов. Тогда
C(0,0)=1,
C(n,0)=0, при n>0,
C(n,k)=0, при к>n,
Для n>0, C(n,k)=С(n-1,k-1)+(n-1)C(n-1,k) или Cn(t)=(t+n-1)Cn-1(t).
Докажем последнее утверждение.
Все ниже рассматриваемые перестановки представлены в канонической циклической форме. Заметим, что если максимальное число в такой перестановке расположено на первом месте, то оно образует отдельный цикл (так как оно является левосторонним минимумом и следующее за ним число также левосторонний минимум). Если же оно расположено на любом другом месте, то оно входит в какой-то цикл длины, большей единицы. Перестановка n-го порядка, содержащая k циклов, может быть получена либо добавлением n на первое место в перестановку (n-1)-го порядка, содержащую k-1 цикл, либо добавлением n в перестановку(n-1)-го порядка, содержащую k циклов, на любое место со второго до n-го.
Следствие. Учитывая, что C1(t)=t, получаем
Cn(t)=t(t+1)…(t+n-1).
Числа Стирлинга первого и второго рода.
Обозначение. (t)n=t(t-1)…(t-n+1).
Числа Стирлинга определяются следующим образом. Положим
(t)0=t0=s(0,0)=S(0,0)=1
(t)n=t(t-1)…(t-n+1)=, n>0 (1)
tn=, n>0. (2)
Тогда s(n,k) и S(n,k) называются числами Стирлинга соответственно первого и второго рода. Заметим, что числа обоих рядов отличаются от нуля только для k=1,2,…,n, n>0 и что (t)n является обычной производящей функцией для s(n,k), тогда как tn является новым типом производящей функции для входящей в уравнение (*) функции fk(t), равной (t)k.
Упражнение. Докажите, что совокупность функций {(t)0,(t)1,…,(t)n} линейно независима.
Для заданного n или k числа Стирлинга первого рода s(n,k) могут иметь тот или иной знак, действительно
(-t)n=(-1)nt(t+1)…(t+n-1),
тогда из (1) немедленно следует, что (-1)n+ks(n,k) всегда положительно. Кроме того, учитывая вид производящей функции Сn(t), получаем С(n,k)=(-1)n+ks(n,k). Т. е модули чисел Стирлинга первого рода s(n,k) определяют число перестановок n-го порядка с k циклами.
Рекуррентные соотношения для чисел Стирлинга первого рода s(n k) вытекают из соотношения для факториалов (t)n=(t-n+1) (t)n-1, т.е.
s(n,k)=s(n-1,k-1)-(n-1)s(n-1,k).
Для чисел Стирлинга второго рода, используя (2), находим
tn==t=
и
S(n+1,k)= S(n,k-1)+k S(n,k). (3)
С числами Стирлинга второго рода можно связать разбиения конечных множеств, а именно:
Пусть Х={1,2,…,n}, рассмотрим всевозможные разбиения Х на k блоков. Множество таких разбиений будем обозначать Пk(X), пусть u(n,k)=|Пk(X)|, тогда
u(0,0)=1 u(n,k)=u(n-1,k-1)+k×u(n-1,k). (4)
Доказательство.
Разобьем Пk(X) на два различных класса:
– тех разбиений, которые содержат одноэлементный блок {n}, и
– тех разбиений, для которых n является элементом большего (по крайней мере, двухэлементного) блока.
Мощность первого класса равна u(n-1,k-1). Т. е. такова, каково число разбиений множества {1,2,…,n-1} на k-1 блоков.
Мощность другого класса составляет k×u(n-1,k), так как каждому разбиению множества {1,2,…,n-1} на k блоков соответствует в этом классе в точности k разбиений, образованных добавлением элемента n поочередно к каждому блоку.
Следствие. Сравнивая (3) и (4), получаем S(n,k)=u(n,k), т. е.
Числа Стирлинга 2-го рода S(n,k) определяют число разбиений n-элементного множества на k дизъюнктных блоков.
Теорема . Пусть |X|=n, |Y|=k, то число всех функций f:X®Y и f(X)=Y, равно Sn,k=k!S(n,k).
Доказательство.
Зафиксируем конкретное разбиение Х на k дизъюнктных подмножеств, тогда существует k! вариантов отображений, при которых каждому элементу разбиения сопоставляется биективно элемент Y. Каждое конкретное разбиение можно выбрать S(n,k) способами.
Принцип включения и исключения. (было у И. В. Романовского)
Пусть A1,…,An некоторые подмножества (необязательно различные) конечного множества Х.
Теорема 1.(Принцип включения и исключения).
-+-…(-1)n-1||
Доказательство
Применим математическую индукцию по n.
Для n=1 терема очевидно справедлива!
Предположим, что для произвольных A1,…,An-1 выполняется
||=-+-…(-1)n-2||
Применяя эту формулу к сумме
,
получаем
||=-+…(-1)n-2||,
а отсюда
||==+|An|-||=
-+-…(-1)n-1||.
Покажем несколько применений принципа включения и исключения
Теорема 2. Пусть |X|=n, |Y|=k, то число всех функций f:X®Y и f(X)=Y, равно
Sn,k=
Доказательство
Пусть У={y1,…,yk} и Ai={f : f:X®Y & yiÏf(X)}, тогда
f(X)¹YÛfÎ
Множество всех f:X®Y имеет мощность kn. Определим , пусть 1£p1£…£pi£k пересечение есть множество всех функций f:X®Y таких, f(X), a, следовательно, мощность этого пересечения ровно (m-i)n. Согласно теоремы 1 имеем
Sn,k=kn-||=kn-=
Эта формула дает простое выражение для вычисления чисел Стирлинга 2го рода
S(n,k)=Sn,k=
Рассмотрим вопрос об определении числа “беспорядков” на множестве {1,…,n}
Определение. Под беспорядком на множестве {1,…,n} будем понимать произвольную перестановку f этого множества, такую что f(i)¹i для 1£i£n.
Пусть Dn – множество всех беспорядков на {1,…,n} и
Ai={fÎSn: f(i)=i}, i=1,…,n.
Заметим, что fÎDn ÛfÏ Ai для "iÎ{1,…,n}, следовательно
|Dn|=|Sn|-+-+…(-1)n-1||
Для произвольной последовательности 1£p1£…£pi£n пересечение является множеством таких перестановок f, для которых f(pj)=pj для 1£j£n, и значит, ||=(n-i)!. Заметив, что последовательность 1£p1£…£pi£n можно выбрать способами, получаем в итоге
|Dn|== =n!( )
Отметим, что сумма в скобках является начальным членом ряда е-1=. Это означает, что беспорядки составляют е-1=0.36788… всех перестановок.
Упражнение. Напишите программу порождения всех “беспорядков” размерности n,
* материал взят из монографии: А. Ахо, Дж. Хопкрофт, Дж. Ульман. Построение и анализ вычислительных алгоритмов. – М.; Мир,1979
* А. Ахо, Дж. Хопкрофт, Дж. Ульман. Построение и анализ вычислительных алгоритмов. – М.; Мир,1979
[1] Перманенты квадратных матриц является частным случаем перманентов прямоугольных матриц. Теория перманентов рассматривается в комбинаторной математике. Она имеет приложение к решению теоретико-вероятностных, комбинаторных и физических задач [3].
[2]Обработка информации, хранящейся в узлах бинарного дерева, по левостороннему обходу характеризуется тем, при обработки каждой вершины вначале совершается обход левой ветви, выходящей из этой вершины; затем обработка информация хранящейся непосредственно в этой вершине; после этого, обход правой ветви, исходящей из вершины.
* материал взят из монографии: А. Ахо, Дж. Хопкрофт, Дж. Ульман. Построение и анализ вычислительных алгоритмов. – М.; Мир,1979
* Д. Кнут ‘Искусство программирования для ЭВМ’. Т 3, 5.3.3, упражнение 16.
[3] Материал взят из книги Дж. Риордан ‘Введение в комбинаторный анализ’ ИЛ, М., 1962
Устранение с рынка обанкротившихся предпринимательских структур — непременное условие эффективного функционирования рыночного механизма. Однако предотвратить банкротство, обеспечить продолжительное процветание этих структур — задача значительно более сложная и важная.
Решению именно этой задачи подчинена система мер, именуемая антикризисным управлением. Часто под таким управлением понимают либо управление в условиях кризиса, либо управление, направленное на вывод предприятия из кризисного состояния, в котором оно находится.
Нам представляется, что подобная трактовка сущности антикризисного управления ослабляет его предотвращающую, опережающую направленность. Поэтому стратегически антикризисное управление начинается не с анализа баланса предприятия (фирмы) за предшествующий или текущий периоды функционирования и осуществления чрезвычайных мер по недопущению несостоятельности, а с момента выбора миссии фирмы, выработки концепции и цели ее предполагаемой деятельности, формировании и поддержании на должном уровне стратегического потенциала фирмы, способного обеспечивать в течение длительного периода конкурентное преимущество фирмы как на внутреннем, так и на внешнем рынках.
Поэтому, с одной стороны, антикризисное управление должно охватывать значительно более широкие сферы деятельности, чем анализ только финансового состояния фирмы. С другой стороны, в процессе антикризисного управления, протекающего под влиянием страха постоянной угрозы банкротства, не должно возникать своеобразного «эффекта пустыни Тартари», деформирующего поведение менеджеров, вызывающего неадекватные их действия, еще более усугубляющие и без того сложное положение фирмы.
Таким образом, антикризисное управление — это:
— анализ состояния макро- и микросреды и выбор предпочтительной миссии фирмы;
— познание экономического механизма возникновения кризисных ситуаций и создание системы сканирования внешней и внутренней сред фирмы с целью раннего обнаружения «слабых сигналов» об угрозе приближения кризиса;
— стратегический контроллинг деятельности фирмы и выработка стратегии предотвращения ее несостоятельности;
— оперативная оценка и анализ финансового состояния фирмы и выявление возможности наступления несостоятельности (банкротства);
— разработка предпочтительной политики поведения в условиях наступившего кризиса и вывода из него фирмы;
— постоянный учет риска предпринимательской деятельности и выработка мер по его снижению.


 2
2
 -2 6
-2 6
 4 7
4 7 3 5 8
3 5 8





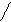

 2 3 1 3 1 3 1 2
2 3 1 3 1 3 1 2


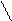



 1 1 1 1 1 1
1 1 1 1 1 1

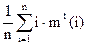 .
.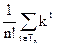 =
= 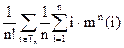 =
= 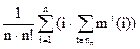 .
.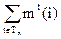 = m(i,n), поэтому
= m(i,n), поэтому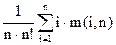 .
.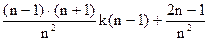 ,
,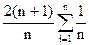 -3, n³1.
-3, n³1.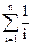 = ln (n + O(1),
= ln (n + O(1),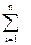 (i-1).mt(i) =
(i-1).mt(i) =  =
= 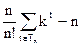 = n.k(n)-n.
= n.k(n)-n.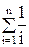 - 4n.
- 4n.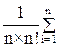 (i-k(n))2 m(i,n)
(i-k(n))2 m(i,n)

 1 2 3 2 1 3
1 2 3 2 1 3


 1 7 1 7
1 7 1 7


 8 2 3 2 8 3
8 2 3 2 8 3
 5 5
5 5
 6 6
6 6 Wn, где Wn – конечные множества. Предположим, что при каком-то способе кодирования элементов из W для запоминания одного элемента из Wn используется самое большое f(n) бит памяти. Кодирование f(n) называется оптимальным, если
Wn, где Wn – конечные множества. Предположим, что при каком-то способе кодирования элементов из W для запоминания одного элемента из Wn используется самое большое f(n) бит памяти. Кодирование f(n) называется оптимальным, если 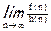 =1, где h(n) = log2ô Wnô.
=1, где h(n) = log2ô Wnô.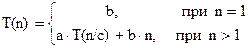 ,
,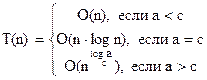
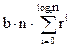 , где
, где 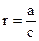 .
.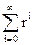 сходиться и, следовательно, T(n) = O(n).
сходиться и, следовательно, T(n) = O(n). , что составляет
, что составляет  , или
, или 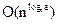 .
.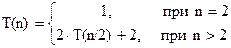 (1)
(1)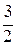 n-2. Легко проверить, что эта функция удовлетворяет (1) при n=2, и если она удовлетворяет (1) при n=m, то
n-2. Легко проверить, что эта функция удовлетворяет (1) при n=2, и если она удовлетворяет (1) при n=m, то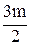 -2)+2=
-2)+2=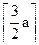 +b+c-2 сравнений, чтобы из (a, b, c, d) получить (0, 1, 1,a+b+c+d-2).
+b+c-2 сравнений, чтобы из (a, b, c, d) получить (0, 1, 1,a+b+c+d-2).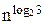 »
» .
.
 Пусть x и y – два n-разрядных двоичных чисел. Снова будем считать для простоты, что n есть степень 2. Разобьем
Пусть x и y – два n-разрядных двоичных чисел. Снова будем считать для простоты, что n есть степень 2. Разобьем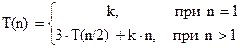 (3)
(3)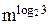 -2km]+2km=3k×
-2km]+2km=3k×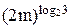 -2k×(2m).
-2k×(2m).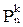 и числа k-сочетаний
и числа k-сочетаний 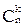 из n объектов, а именно
из n объектов, а именно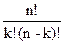
 .
.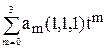
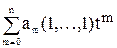 =
= ;
;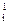 t+x
t+x t2+ … +x
t2+ … +x tj, построим производящую функцию для сочетаний, в которых элементы xi могут содержаться 0,1,2,…,j раз. Более того, множители производящей функции можно совершенно независимо друг от друга приспосабливать к любым требованиям задачи. Так, например, если xk должно всегда входить четное число раз, но не более чем 2k раз, то k-й множитель следует выбирать в виде
tj, построим производящую функцию для сочетаний, в которых элементы xi могут содержаться 0,1,2,…,j раз. Более того, множители производящей функции можно совершенно независимо друг от друга приспосабливать к любым требованиям задачи. Так, например, если xk должно всегда входить четное число раз, но не более чем 2k раз, то k-й множитель следует выбирать в виде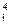 t4+ … +x
t4+ … +x t2k .
t2k .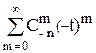 =
=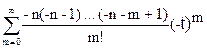 =
=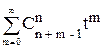 .
.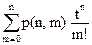 , т. е. в разложении выражения (1+t)n число p(n,m) является коэффициентом при
, т. е. в разложении выражения (1+t)n число p(n,m) является коэффициентом при 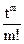 . Этот факт указывает пути обобщения.
. Этот факт указывает пути обобщения.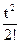 +…+
+…+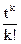 . Это объясняется тем, что число перестановок из n элементов, p из которых одного вида, q другого и т. д., равно
. Это объясняется тем, что число перестановок из n элементов, p из которых одного вида, q другого и т. д., равно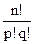 .
. ×
×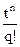 × × ×, n=p+q+…,
× × ×, n=p+q+…,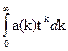
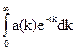
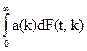 ,
,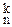
 fкg0+
fкg0+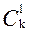 fк-1g1+…+
fк-1g1+…+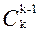 f1gк-1+
f1gк-1+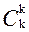 f0gк
f0gк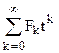 =1+t+
=1+t+ =
=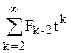 +t
+t =
=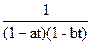 =
= +
+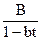

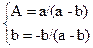
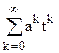 +B
+B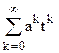 =
=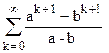 tk
tk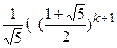 +
+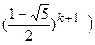
 =
=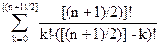 .
. . Таким образом, A(n)=
. Таким образом, A(n)=  C2 = 2 · ·
C2 = 2 · · Ck Cn-k n>0
Ck Cn-k n>0 , тогда на основе определения произведения производящих функций и указанного выше рекуррентное соотношение имеем
, тогда на основе определения произведения производящих функций и указанного выше рекуррентное соотношение имеем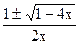 {**}
{**}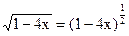 в ряд Маклорена
в ряд Маклорена =
=  ×(
×( ×(-4)n =
×(-4)n =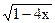 = 1-
= 1- = 1-
= 1- = 1-2
= 1-2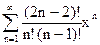 =
=
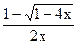 =
= 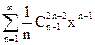 =
=  .
.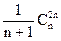
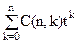 , определяющую число перестановок n-го порядка, имеющих k циклов, т. е. С(n,k) определяет число перестановок n-го порядка, имеющих k циклов. Тогда
, определяющую число перестановок n-го порядка, имеющих k циклов, т. е. С(n,k) определяет число перестановок n-го порядка, имеющих k циклов. Тогда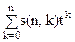 , n>0 (1)
, n>0 (1)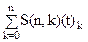 , n>0. (2)
, n>0. (2)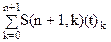 =t
=t =
=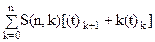
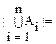
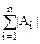 -
-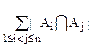 +
+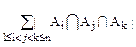 -…(-1)n-1|
-…(-1)n-1| |
| |=
|=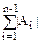 -
-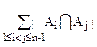 +
+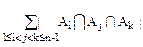 -…(-1)n-2|
-…(-1)n-2|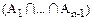 |
|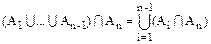 ,
, |=
|= -
- +…(-1)n-2|
+…(-1)n-2| |=
|= =
=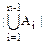 +|An|-|
+|An|-|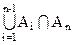 |=
|=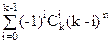
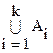
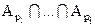 есть множество всех функций f:X®Y таких,
есть множество всех функций f:X®Y таких, 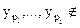 f(X), a, следовательно, мощность этого пересечения ровно (m-i)n. Согласно теоремы 1 имеем
f(X), a, следовательно, мощность этого пересечения ровно (m-i)n. Согласно теоремы 1 имеем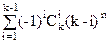 =
= Sn,k=
Sn,k=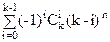
 -
-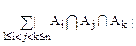 +…(-1)n-1|
+…(-1)n-1| |=(n-i)!. Заметив, что последовательность 1£p1£…£pi£n можно выбрать
|=(n-i)!. Заметив, что последовательность 1£p1£…£pi£n можно выбрать 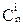 способами, получаем в итоге
способами, получаем в итоге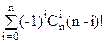 =
= 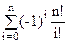 =n!(
=n!( 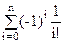 )
) . Это означает, что беспорядки составляют е-1=0.36788… всех перестановок.
. Это означает, что беспорядки составляют е-1=0.36788… всех перестановок.