for k:=0 to n do p[k]:=k; {задание начальной перестановки}
k:=1;
while k<> 0 do
for k:=1 to n do write(p[k]); writeln; {вывод перестановки}
k:=n-1; while p[k]>p[k+1] do k:=k-1; {поиcк k}
j:=n; while p[k]>p[j] do j:=j-1; {поиск j}
r:=p[k]; p[k]:=p[j]; p[j]:=r; {транспозиция рк и pj }
j:=n; m:= k+1;
while j>m do {инвертирование хвоста перестановки}
begin r:=p[j]; p[j]:=p[m]; p[m]:=r; j:=j-1; m:=m+1 end
Комментарий. Нулевой элемент включен в массив р для того, чтобы обеспечить конец цикла {поиск k}после генерации последней перестановки.
Упражнение. Протестируйте приведенную выше программу при n=3.
Оценим временную вычислительную сложность приведенной программы. Обычно временная вычислительная сложность программ, представленных на языке высокого уровня, оценивается как порядок роста числа исполняемых операторов программы в зависимости от некоторого параметра исходных данных [3]. Однако, в алгоритмах генерации перестановок такой подход малоэффективен, так как в процессе работы любого алгоритма генерации всех перестановок порождается n!перестановок, т. е. временная вычислительная сложность всегда будет, по крайней мере, O(n!) - величина слишком быстро растущая. Любая ‘экономия’ в реализации будет сказываться только на коэффициенте пропорциональности при n!. Поэтому для того, чтобы удобнее было сравнивать различные алгоритмы генерации перестановок, обычно вводят другие критерии оценки вычислительной сложности. Здесь разумно ввести два критерия - количество транспозиций элементов перестановки, выполняемых в среднем при генерации одной перестановки, и аналогичное среднее числа сравнений элементов перестановки в операторах {поиск k} и {поиск j}.
Оценим их число. Пусть Tk - число транспозиций, выполняемых при вызове оператора LEC(n-k+1), т. е. Tk –число транспозиций, которые необходимо выполнить при генерации перестановок k-го порядка. Имеем
Tk=k*Tk-1+(k-1)*(1+ë(k-1)/2û )=
k*Tk-1+(k-1)*ë(k+1)/2û,где ëaû = ‘целой части числа a’.
Первое слагаемое определяет число транспозиций при вызовах оператора LEC(n-k), а второе - число транспозиций, выполняемых в операторах {3} и {4}. Заметим, что T1=0.
Для решения этого рекуррентного уравнения сделаем замену переменной. Пусть Sk=Tk+ë(k+1)/2û, тогда
S1=1, Sk=k*(Sk-1+dk-1),
где dk=0, если k нечетно, и dk=1, если k четно.
Решение этого рекуррентного соотношения легко получается по индукции:
Sk=,
т. е.
Tk=- ë(k+1)/2û.
Учитывая, что »ch(1)»1.543 и ë(k+1)/2û=o(k!). получаем
Tk»k!*ch(1),
т. е. на генерирование одной перестановки в лексикографическом порядке требуется в среднем ch(1)»1.543 транспозиций.
Перейдем теперь к оценке числа сравнений элементов перестановки в операторах {поиск k}и {поиск j}; обозначим это число Сn.
Определим Сn как функцию от Сn-1. Отметим, что при генерации каждого из n блоков, определенных в Л2, требуется Cn-1 сравнений, а таких блоков n. Далее, при переходе от одного блока к другому оператор {поиск k} выполняется n-1 раз, а оператор {поиск J} при переходе от блока p к блоку p+1 (1£p<n) - p раз, т. е.
Cn= n*Cn-1+(n-1)*(n-1)+1+...+(n-1), C1=0
или
Cn= n*Cn-1+(n-1)*(3n-2)/2 C1=0.
Пусть Dn=Cn+(3n+1)/2, тогда D1=2, Dn=n*Dn-1+3/2,
и по индукции получаем
Dn=n!*(+)
или
учитывая, что е=,получаем Dn»n!*(e-1).
Тогда, Cn» n!*(e-1)-(3n+1)/2, учитывая, что (3n+1)/2=о(n!),получаем
Cn/n!»(e-1)
Таким образом, на генерирование одной перестановки алгоритмом LEX в среднем выполняется (e-1)» 3.077 сравнений.
Замечание. Применение методов рекурсивного программирования не требует выяснения того факта, как выглядит следующая перестановка после текущей в лексикографическом порядке. Легко построить соответствующую рекурсивную программу непосредственно на основе свойств Л1-Л3. Эта рекурсивная программа может быть написана так:
{1} begin for i:=1 to n do write (p[i]); writeln end
for i:=n downto k do
{2} begin
LEC (k+1);
if i>k then
r:=p[i]; p[i]:=p[k]; p[k]:=r;
{3} INVERT (k+1)
{4} end
end {LEC};
for i:=1 to n do p[i]:=i;
end.
Комментарий. Процедура INVERT служит для восстановления первоначальной перестановки (свойство Л1) после генерации всех перестановок данного обобщенного блока. Процедура LEC осуществляет либо печать перестановки (строка {1}), если все n позиций уже сформированы, либо ( по свойству Л2) генерирует перестановки n-k+1 порядка как последовательность n-k+1 блоков перестановок n-k порядка с возрастающим по значению элементом на k позиции.
Тест n=3
{2}
k=1
i=3
{4}
k=2
p=2 3 1
{2}
k=2
i=3
{2}
k=2
i=2
{1}
k=3
вывод<1 2 3>
{1}
k=3
вывод<2 3 1>
{3}
k=2
i=3
p=1 3 2
{3}
k=1
i=2
p=3 2 1
{4}
k=2
p=1 3 2
{4}
k=1
p=3 1 2
{2}
k=2
i=2
{2}
k=1
i=3
{1}
k=3
вывод<1 3 2
{3}
k=2
i=3
{3}
k=1
i=3
p=2 3 1
{1}
k=3
i=3
вывод<3 1 2>
{4}
k=1
p=2 1 3
{3}
k=2
i=3
p=3 2 1
{2}
k=1
i=2
{4}
p=3 2 1
{2}
k=2
i=3
{2}
k=2
i=2
{1}
k=3
вывод<2 1 3>
{3}
k=3
вывод<3 2 1>
{3}
k=2
i=3
p=2 3 1
Упражнение. Проведите формальное доказательство правильности алгоритма процедуры LEC. Указание. Методом математической индукции докажите, что если p[k]<...<p[n], то вызов LEC(k) приводит к генерированию всех перестановок множества p[k],...,p[n] в лексикографическом порядке при неизменных значениях p[1],...,p[k-1].
Для оценки сложности приведенной рекурсивной программы наряду со средним числом количества транспозиций элементов перестановки, нам необходимо определить среднее число вызовов процедуры LEC, как функции от n - порядка перестановок.
Пусть Bn - число вызовов процедуры LEC при генерации всех перестановок n - порядка программой LEX1. Для Bn справедливо следующее рекуррентное соотношение
B1=1
Bn= n×Bn-1+1
Его решением является последовательность Bn=n!×. Это приводит к тому, что в среднем на одну перестановку приходится e-1 вызовов процедуры LEC. Этот результат позволяет сравнить алгоритмы LEX и LEX1. Фактически сравнение сводится к оценке того, что эффективнее реализуется на конкретной ЭВМ: e-1 вызовов рекурсивной процедуры или 3.077 сравнений целых чисел.
Наряду с лексикографическим порядком достаточно часто встречается генерирование перестановок в антилексикографическом порядке.
Определение. Пусть f=<a1,...,an>, g=<b1,...,bn>, будем говорить, что f<g в антилексикографическом порядке, если существует k£n такое, что ak>bk и aq=bq для q>k.
Пример. При n=4 в антилексикографическом порядке перестановки располагаются так:
1. <1, 2, 3, 4>
7. <1, 2, 4, 3>
13. <1, 3, 4, 2>
19. <2, 3, 4, 1>
2. <2, 1, 3, 4>
8. <2, 1, 4, 3>
14. <3, 1, 4, 2>
20. <3, 2, 4, 1>
3. <1, 3, 2, 4>
9. <1, 4, 2, 3>
15. <1, 4, 3, 2>
21. <2, 4, 3, 1>
4. <3, 1, 2, 4>
10. <4, 1, 2, 3>
16. <4, 1, 3, 2>
22. <4, 2, 3, 1>
5. <2, 3, 1, 4>
11. <2, 4, 1, 3>
17. <3, 4, 1, 2>
23. <3, 4, 2, 1>
6. <3, 2, 1, 4>
12. <4, 2, 1, 3>
18. <4, 3, 1, 2>
24. <4, 3, 2 ,1>
Упражнение.
1.Сформулируйте свойства А1-А3 антилексикографического порядка, аналогичные свойствам Л1-Л3 для лексикографического порядка.
2.Определите соотношения между некоторой перестановкой и непосредственно следующей за ней в антилексикографическом порядке.
3.Постройте нерекурсивный алгоритм ANTYLEX, порождающий все перестановки в антилексикографическом порядке (сравните с [1]).
4.Постройте рекурсивный алгоритм ANTYLEX1, порождающий все перестановки в антилексикографическом порядке.
4.2 Генерация перестановок за минимальное число транспозиций
4.3 .
При конструировании алгоритмов с использованием генерации перестановок, рассмотренные алгоритмы генерации в лексикографическом или антилексикографическом порядке иногда мало эффективны.
Пример. Пусть задана квадратная матрица вещественных чисел ||aij|| порядка n. Вычислить
åa[1,i1]×a[2,i2]× ... ×a[n,in], (1)
где суммирование проводится по всем перестановкам <i1 i2 ... in> n-го порядка.
Выражение (1) называется перманентом [1] матрицы ||aij|| и весьма похоже на ее определитель. Заметим, что вычисление перманента или определителя непосредственно по определению имеет сложность O(n!), так как требуется генерация всех перестановок n-го порядка. Поэтому машинные алгоритмы вычисления определителей никогда не строятся непосредственно на его определении, а используют ряд его свойств, уменьшающих вычислительную сложность. Перманенты, однако, подобными свойствами не обладают, поэтому для их вычисления вполне приемлем подход, основанный на их определении. Остановимся на таком алгоритме подробнее.
Как уже отмечалось, подобный алгоритм требует генерирование всех перестановок n-го порядка. Однако генерация перестановок в лексикографическом или антилексикографическом порядке нецелесообразна. Здесь более желателен такой алгоритм генерирования, при котором каждая последующая перестановка отличалась бы от предыдущей на транспозиции только двух ее элементов.
Действительно, пусть последующая перестановка отличается от предыдущей на транспозиции [ik,ii], k¹j; тогда для того чтобы вычислить произведение, соответствующее последующей перестановке, не надо выполнять все n умножений, определяемые формулой (1), а достаточно, произведение, соответствующее, предыдущей, перестановке, умножить на a[j,ij]/a[k,ik], т. е. можно получить только за одно деление и умножение (считаем, что a[k,ik]¹0).
Для полного решения поставленной в примере задачи покажем возможность алгоритма генерирования перестановок, в котором каждая последующая перестановка отличается от предыдущей на одну транспозицию. Опишем только такие из них, которые могут быть представлены по следующей рекурсивной схеме [2].
Пусть генерируемые элементы перестановки содержатся в массиве p[1],…,p[n] и имеется некоторая процедура PERM(m), генерирующая все перестановки элементов, хранящиеся в p[1],…,p[m], 1 £ m £ n, таким образом, что каждая последующая перестановка отличается от предыдущей одной транспозицией. Тогда генерирование перестановок n-го порядка может быть представлено как n обращений PERM(m-1), при условии, что при каждом очередном обращении элемент перестановки, хранящийся в p[n], заменяется на другой элемент из p[1],…,p[n-1] так, что элементы в p[n] не повторяются. В общем виде процедура PERM(m) может быть описана так:

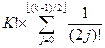 ,
, - ë(k+1)/2û.
- ë(k+1)/2û.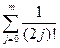 »ch(1)»1.543 и ë(k+1)/2û=o(k!). получаем
»ch(1)»1.543 и ë(k+1)/2û=o(k!). получаем +
+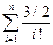 )
)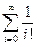 ,получаем Dn»n!*(
,получаем Dn»n!*(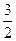 e-1).
e-1). e-1)
e-1) {2}
{2}
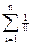 . Это приводит к тому, что в среднем на одну перестановку приходится e-1 вызовов процедуры LEC. Этот результат позволяет сравнить алгоритмы LEX и LEX1. Фактически сравнение сводится к оценке того, что эффективнее реализуется на конкретной ЭВМ: e-1 вызовов рекурсивной процедуры или 3.077 сравнений целых чисел.
. Это приводит к тому, что в среднем на одну перестановку приходится e-1 вызовов процедуры LEC. Этот результат позволяет сравнить алгоритмы LEX и LEX1. Фактически сравнение сводится к оценке того, что эффективнее реализуется на конкретной ЭВМ: e-1 вызовов рекурсивной процедуры или 3.077 сравнений целых чисел.