Представление перестановок в виде таблицы инверсий.
. . .
Возникает естественный вопрос: ‘ Сколько раз в среднем в этом фрагменте программы выполняется оператор {1}, если считать распределения значений элементов в массиве aравновероятным?’.
Заметим, что оператор {1} выполняется только при таких i, когда значение a[i] является левосторонним минимумом, т. е. по теореме 2, оператор {1} выполняется Hn-1 раз.
Упражнение. Оцените среднее число выполнения оператора {1}, если в массиве a допускают равные значения элементов, причем значение индекса должно быть максимально возможным. Как и в примере, считаем, что все возможные распределения значений элементов в a равновероятны.
Определение. Таблицей инверсий перестановки f = <a1 ... an> называется последовательность чисел r1,...,rn, где ri, 1 £ i £ n, равно числу элементов, больших i и расположенных перед ним. Таблицу инверсий будем обозначать /r1,...,rn/.
Например, f = <5 1 2 6 4 7 3> r =/1,1,4,2,0,0,0/.
По определению: 0 £ r1 £ n-1
0 £ r2 £ n-2
. . .
0 £ rn-1 £ 1
rn = 0.
Упражнение. Пусть f = <a1 ... an>, ее таблица инверсий /r1,...,rn/. Как выглядит таблицей инверсий перестановки f=<an ... a1>?
Замечание. Наряду с таблицей инверсии перестановки f можно рассмотреть таблицу r,...,rантиинверсий перестановки f, где rопределяется как число элементов f, меньших i и расположенных перед ним.
Теорема 3. Последовательность чисел r1+r+1, r2+r+1,..., rn+r+1 образует обратную перестановку к f.
Доказательство следует из определения обратной перестановки.
Пусть q[i] (q`[i]), 1 £ i £ n, обозначает число элементов перестановки f, больших (меньших) i и расположенных после него. Тогда из определения также следует
q[i]+r[i] = n-i
q’[i]+r`[i] = i-1
q[i]+q`[i] = n-1-f-1[i]
Например, f = <5 1 2 6 4 7 3>
r = 1,1,4,2,0,0,0, r` = 0,1,2,2,0,3,5,
q = 5,5,0,1,2,1,0, q` = 0,0,0,1,4,2,1.
Следствие. Если определена какая-нибудь одна из четырех таблиц r, r`, q, q`, то из указанных соотношений легко вычисляются и три других.
Упражнение. Докажите, что для заданной перестановки f, соответствующая ей таблица инверсий определяется однозначно. Указание. Воспользуйтесь следующим соотношением: пусть перестановка <a1 ... an>, (n-1) порядка соответствует /r1,...,rn-1/, тогда перестановке <a1 ... ai n аi+1 ... an> соответствует таблица инверсий /r,...,r,0/, где r=rk, если kÎ{a1 ... ai} и r= rk+1, если kÎ{ai+1 ... an}.
На языке Паскаль тип данных, соответствующий таблице инверсий перестановки, может быть определен как
tpi= array [1..n] of 0..n;
для конкретных значений которого истинна следующая верификационная функция:
function TYPEJ (var f tpi:) : Boolean;
var i : 0..n; s : Boolean;
begin i := n; s := true;
while (i > 0) and s do
begin s:=f[i] <= n-1; i := i-1 end;
TYPEJ :=s
end;
Непосредственно из определения вытекает следующий алгоритм построения таблицы инверсий для перестановки, заданной в естественной форме:
procedure TABIN (var f :TPE; var r :TPI);
var i, j, k : integer;
begin for i := 1 to n do
begin k := f[i]; r[k] := 0;
for j := i-1 downto 1 do
{1} if f[j] > k then r[k] :=r[k]+1
end
end;
Временная сложность этого алгоритма фактически определяется числом выполнения {1}, которое равно n(n-1)/2, т. е. является О(n2).
Рассмотрим теперь алгоритм восстановления перестановки в естественной форме по его таблице инверсий. Здесь возможны два похода.
1. Будем последовательно, начиная с единицы и кончая n, расставлять элементы перестановки на свои места. Вначале всем вставляемым элементам перестановки соответствуют нулевые значения. Тогда для того чтобы определить место элемента i, достаточно перед ним оставить ri нулей для элементов со значениями, большими i. Реализация этого подхода на языке Паскаль выглядит так:
type P = array [1..0] of 1..n;
procedure TABOUT1 (var r : TPI; var f : P);
var i, j, k : 0..n;
begin for i := 1 to n do f[i] := 0;
for i := 1 to n do
begin k := r[i]+1; j := 0;
repeat j := j+1;
if f[j] = 0 then k :=k-1
until k = 0;
f[j] := i
end
end;
Комментарий. Для параметра f определен новый тип P, отличающийся от типа TPE тем, что его элементы массива могут получать нулевые значения. После исполнения процедуры TABOUT1 параметр f принимает значения типа TPE. Переменная k служит для пропуска нулевых значений, аj - для определения места элемента i.
Упражнение. Исполните алгоритм TABOUT1 при n=5, r=/2,3,1,1,0/.
Оценим временную сложность алгоритма. Она определяется числом выполнения операторов внутри цикла repeat. Пусть Ti - точное число выполнения операторов внутри цикла для заданного i. Тогда r[i]+1 £ Ti £ n. Если все перестановки из Sn равновероятны, то среднее значение r[i] равно (n-i)/2. Это приводит к тому, что вычислительная сложность этого алгоритма в среднем по всем перестановкам есть O(n2).
2. Запишем число n. Далее если r[n-1]=1, то значение n-1 поместим после n или перед ним, если r[n-1]=0. Предположим, что уже расставлены элементы n, n-1,..., i+1, тогда i нужно поставить после r[i] значений уже построенной последовательности.
Например, пусть n=5, r=/2,2,1,0,0/
1 шаг (постановка 5) r[5]=0 5
2 шаг (постановка 5) r[5]=0 4 5
3 шаг (постановка 5) r[5]=1 4 3 5
4 шаг (постановка 5) r[5]=2 4 3 2 5
5 шаг (постановка 5) r[5]=2 4 3 1 2 5
f = < 4 3 1 2 5>
В реализации этого алгоритма на языке Паскаль хранение формируемой последовательности естественней всего организовать в виде линейного цепного списка. В этом случае включение в список значения i сводится к вставке в него соответствующего элемента после r[i] ранее включенных элементов. Вследствие того, что каждое значение элементов списка лежит в промежутке от 1 до n, а число элементов не превосходит n, список удобно хранить в массиве (c) из n+1 ячейки. При этом в нулевой ячейке хранится значение первого элемента списка, а в ячейке с индексом i - значение элемента следующего в списке за ним. Для последнего включенного в список элемента перестановки и для не включенных значений соответствующие ячейки равны нулю.
Например, список 4®3®2®5 при n=5 будет представлен c[0]=4, c[1]=0, c[2]=5, c[3]=2, c[4]=3, c[5]=0.
Реализация этого подхода на языке Паскаль выглядит так:
рrocedure TABOUT2 ( var r : :TPI; var f :TPE);
var c : array [0..n] of 0..1;
i, j, k : 0..n;
begin c[0]:=0;
for i:=n downto 1 do {формирование списка}
begin j:=0;
for k:=r[i] downto 1do {движение по списку }
{1} j:=c[j];
c[i]:=c[j]; c[j]:=i {вставка элемента }
end;
j:=0;
for i:=1 to n do {формирование f }
begin
f[i]:=c[j]; j:=c[j]
end
end;
Заметим, что временная сложность этого алгоритма определяется числом выполнения оператора {1} и равна O(n2), т. е. алгоритм TABOUT2 несколько эффективней алгоритма TABOUT1, хотя его вычислительная сложность того же порядка.
Упражнение. Модернизируйте алгоритм TABOUT2 так, чтобы вспомогательный массив совместить с массивам f.
Рассмотренные TABIN и TABOUT1, TABOUT2 имеют временную сложность O(n2). Возникает естественный вопрос, существует ли алгоритм, аналогичный по действию, например, алгоритму TABIN, но имеющий лучшую временную сложность. Для того чтобы прояснить возникающие здесь проблемы, рассмотрим близкие к исследуемым понятия, связанные с алгоритмами линейного упорядочивания значений элементов (сортировки).
Пусть задан некоторый массив X, например,
X : array [1..n] of real;
При этом для упрощения рассуждений будем считать, что все значения элементов Х различны между собой. Тогда задача упорядочивания (например в порядке возрастания значений) может быть интерпретирована как поиск перестановки f = <a1 … an>, где ak – порядковый номер элемента X[k] после упорядочивания, 1£k£n. Для любого элемента X[k] можно определить следующие числа:
b[k] (b`[k]) – число элементов Х, больших (меньших) X[k]
и расположенных перед ним;
c[k] (c`[k]) – число элементов Х, больших (меньших) X[k]
и расположенных после него;
Например, X = -2.5 1.3 1.0 -0.8 0.3 -5.0
f = <2 6 5 3 4 1>
b = 0 0 1 2 2 5
b`= 0 1 1 1 2 0
c = 4 0 0 1 0 0
c`= 1 4 3 1 1 0
Нетрудно показать, что для любого k, 1£k£n, определены следующие соотношения:
(1) b`{k} + c`[k] + 1 = f[k]
(2) b{k} + c[k] + 1 = n-f[k]
(3) b{k} + b`[k] + 1 = k
(4) c{k} + c`[k] + 1 = n-k
Из соотношений (3), (4) следует: если по массиву Х определены таблицы b, c, то легко вычислить таблицы b`, c`, и обратно. Из соотношений (1), (2) следует: если вычислены b` и c` (либо b и c), то легко построить таблицу f.
По характеру своего числа b, b`, c, c` весьма близки к числам r, r`, q, q`, определенным для перестановок. Рассмотрим вопрос, какова может быть временная сложность при вычислении по массиву Х таблиц, например, b`и c`?
Пусть A(b`,c`) – временная сложность наиболее эффективных алгоритмов вычисления b` и c`, а A(f) – временная сложность наиболее эффективных алгоритмов вычисления f; тогда, так как f линейно зависит от b` и c`, то A(b`,c`)/ A(f) =O(1).
Из теории сортировки известно, что если не задана дополнительная информация о структуре значений элементов массива, то наиболее эффективные алгоритмы сортировки имеют временную сложность O(n×log2n). Это следует, например, из следующих рассуждений. В зависимости от исходных значений элементов Х ему может соответствовать любая из n! Возможных перестановок f. Фактически алгоритм сортировки может быть интерпретирован как поиск соответствующей ему перестановки f из множестваSn, элементы которого упорядочены некоторым образом. Но наиболее эффективный алгоритм поиска индекса элемента в упорядоченном массиве размерностью k – это бинарный поиск, временная сложность которого O(log2k). То есть поиск конкретной перестановки из n! упорядоченных перестановок оценивается минимальной временной сложностью O(log2n!).
Упражнение. Докажите равенство O(log2n!) = O(n×log2n).Указание. Воспользуйтесь неравенством n×ln(n)-n+1 < ln(n!) < (n+1)×ln(n)-n+1, n>1, которое доказывается индукцией по n.
Таким образом, для произвольного массива Х наиболее эффективные алгоритмы вычисления таблиц b` и c` не могут иметь временную сложность лучшую, чем O(n×log2n).
Возвратимся к алгоритмам построения таблицы инверсий для заданной перестановке f. Приведенные рассуждения наводят на мысль поиска подобного алгоритма сложностью O(n×log2n). Действительно, такой алгоритм существует. Однако его построение требует привлечение новых идей, которые в данных методических указаниях не рассматривались. Можно показать, что алгоритмы с временной сложностью O(n×log2n) являются наиболее эффективными алгоритмами построения таблицы инверсий. Такое доказательство строится на построении модели, в которой инверсиям соответствуют некоторые операции, и эту модель характеризуют O(n!) состояний. Однако этот материал явно выходит за рамки данных методических указаний.
Перейдем к рассмотрению алгоритмов выполнения операций суперпозиции, вычисления обратной и четности для перестановок, заданных в виде таблицы инверсий. Наиболее простой из них – определение четности перестановки. В самом деле, непосредственно из определения таблицы инверсий следует, что перестановка четна, если сумма всех ее элементов таблицы инверсий четна, и нечетна в противном случае.
Упражнение. Напишите булевскую функцию с заголовком
function Ч3 (var r :TPI) : Boolean;
и временной сложностью O(n), определяющую четность перестановки, заданной в виде таблицы инверсий.
Рассмотрим алгоритм определения таблицы инверсий обратной перестановки для перестановки, заданной в виде таблицы инверсий.
Теорема 4. Для любой перестановки fÎSn, число инверсий f совпадает с числом инверсий f-1.
Доказательство. Пусть f = <a1 … an>, f-1 = <b1 … bn> и х = /x1,...,xn/, y = /y1,...,yn/ - таблицы инверсий f и f-1 соответственно. Рассмотрим элемент i, 1 £ i £ n, d перестановке f, расположенный на k-м месте; и пусть j,…, j- элементы в f, которыми i образуют инверсию, и расположенные левее i. Индексы элементов j,…, jобозначим соответственно k,…, k. Заметим, что j<k, 1£m£xi
Тогда в перестановке f-1 на i-м месте располагается элемент k и он образует инверсии с элементами k,…, k, которые расположены после него. Таким образом, для каждой инверсии (j,i) перестановки f однозначно сопоставляется инверсия (k, k) перестановки f-1.
Аналогично доказывается, что каждой инверсии перестановки f-1 однозначно сопоставляется инверсия перестановки f.
Приведенное доказательство может быть наглядно представлено следующим образом. Рассмотрим таблицу размером n´n. Поставим ‘·’ в k-й клетке i-й строки. После этого расставим символ ‘1’ в позициях k,…, ki-й строки. Заметим, что число ‘1’ в каждой строке соответствует значению хi. Тогда перестановке f-1 соответствует таблица, транспонированная построенной, и число ‘1’ в каждой i-й строке этой транспонированной таблицы yi. Так построенную таблицу в дальнейшем будем называть матрицей инверсий перестановки f.
·
·
·
·
·
·
·
Пример.
Матрица инверсий
заданной перестановки
f = <2 7 3 6 5 1 4>, f-1 = <6 1 3 7 5 4 2>
x = /5,0,1,3,2,1,0/, y = /1,5,1,3,2,0,0/.
Алгоритм вычисления y по x с использованием рассмотренных идей на языке Паскаль может выглядеть так:
procedure O3 (var x,y : TPI);
var k, i, j, s, : integer;
next : array [0..n] of integer;
begin for i:=1 to n do
begin y[i]:=0; next [i]:=i+1 end; next [0]:=1; {3}
for i:=1 to n-1 do {2}
begin s:=0; k:=next[0];
j:=x[i];
while j>0 do
begin y[k]:=y[k]+1; {1}
s:=k; k:=next[k]; j:=j-1
end;
next[s]:=next[k] {4}
end
end;
Комментарий. Для каждого столбца k матрицы инверсий алгоритм последовательно подсчитывает число единиц, расположенных в этом столбце. Перебор строк матрицы организован циклом {2}, а столбцов – с помощью вспомогательного массива next и ограничен числом инверсий в текущей строке. Для исключения столбцов, в которых ‘·’ расположена текущей строки, осуществляется корректировка значений массива next. В начальный момент всем значениям элементов массива next присваивается ссылка на следующий элемент {3}, а при достижении точки в данной строке ссылка на текущий столбец исключается из списка (оператор {4}). Переменные s и k хранят значения индексов предыдущего и текущего столбца соответственно.
Временная сложность алгоритма O3 оценивается числом выполнения оператора {1}, равного числу инверсий перестановки f. Ее порядок O(n2).
Упражнение. Протестируйте алгоритм O3 на перестановки, рассмотренной в предыдущем примере.
Рассмотрим алгоритм вычисления суперпозиции двух перестановок, в случае если они представлены в виде таблицы инверсий. Один из подходов может состоять в преобразовании перестановок, например, в естественную форму, затем в выполнении суперпозиции и обратного преобразования результата.
Упражнение. Напишите процедуру на языке Паскаль, реализующую вычисление суперпозиции перестановок по указанной схеме, с использованием ранее рассмотренных процедур для преобразований и вычисления суперпозиции перестановок в естественной форме.
Подобная схема алгоритма имеет временную сложность O(n2). Улучшенные варианты этой схемы реализации (за счет более эффективных схем перевода из одной формы в другие) имеют временную сложность O(n×log2n).
В качестве упражнения, являющегося скорее исследованием, предлагается ответить на следующие вопросы. Существует ли более эффективная реализация алгоритма суперпозиции для перестановок, представленных в виде таблиц инверсий? Можно ли, ‘непосредственно’ преобразуя исходные таблицы исходных данных, получить таблицу результата?
В этой теме были рассмотрены представления перестановок: в естественной форме, разложением на циклы (с разметкой начала циклов и каноническое) и таблицей инверсий. Над перестановками рассматривались операции суперпозиции, вычисления обратной и определения четности. В зависимости от внутреннего представления, выполнение этих операций существенно различно и имеет различные характеристики временной сложности. Однако с точки зрения пользователя (например, алгебраиста, решающего на ЭВМ свою конкретную задачу, описанную в терминах этих операций) совершенно безразлично, в каком представлении будут выполняться эти операции. Для него перестановки выступают как некоторый абстрактный тип данных, характеризующийся только тем, что отличает одну перестановку от другой, и возможностью выполнения указанных операций. Такое выделение понятия абстрактного типа данных методически весьма оправдано – оно позволяет пользователю описывать решение своей задачи в наиболее естественной и удобной форме, а проблему внутреннего представления этих типов данных либо оставить на более позднее время, либо передать другому специалисту, лучше знакомому с представлением данных на ЭВМ.
Кроме построенного абстрактного типа данных, на множестве всех перестановок можно построить другой тип, определив иные выполняемые операции.
Рассмотрим вначале задачу о складывании единичной полоски марок. Пусть задана прямоугольная полоска бумаги формы 1*n, разбитая на n единичных клеток (марок). Все клетки последовательно пронумерованы натуральными числами 1,...,n. Предположим, что полоска складывается (сгибанием по линиям разбивки на клетки) таким образом, что все клетки находятся под одной единственной. Тогда каждому такому складыванию соответствует некоторая перестановка f=<a1 a2 ... an>,гдеa1 - номер клетки, расположенной сверху, a2 - номер клетки, расположенной непосредственно под a1, и т. д.
Определение. Перестановка называется складываемой, если ей соответствует некоторое складывание полоски, и нескладываемой в противном случае.
В качестве операции, заданной на множестве всех перестановок, рассмотрим булевскую функцию, истинную для складываемых перестановок и ложную в противном случае. Для построения алгоритма вычисления этой логической функции разберем вначале алгоритм вычисления аналогичной функции, принимающей истинное значение только в случае, когда единичная полоска склеена в кольцо так, что после n-й клетки следует первая.
Например, перестановка <3 4 2 1> перестает быть складываемой для замкнутых единичных полосок четвертого порядка, а перестановка <3 4 1 2> остается складываемой и в этом случае.
Рассмотрим свойства складываемых перестановок, соответствующих замкнутым единичным полоскам:
1.Порядок складываемых перестановок, соответствующих замкнутым полоскам, четен.
Для доказательства этого свойства введем на полоске ориентацию. Сторону некоторой клетки полоски с номером i, 1<i<n, будем называть начальной (конечной), если она смежна с клеткой с меньшим (большим) номером. Для первой (n-й) клетки начальная сторона это та, которая смежна сn-й ( (n-1)-й) клеткой, а конечная- со второй (первой). Определим для начальных и конечных сторон ориентацию. Пусть замкнутая полоска представлена в сложенной форме. Выберем направление в зависимости от расположения начальной и конечной сторон клетки с номером 1 относительно ее центра. При этом будем считать, что начальная сторона первой клетки находится слева, а конечная - справа. Тогда начальным и конечным сторонам других клеток приписывается направление в зависимости от того, расположены ли они с той же стороны, что и начальная или конечная сторона первой клетки.
Заметим, что в этом случае начальные (конечные) стороны клеток с нечетным номером расположены слева (справа), а клеток с четными - наоборот. Поэтому отождествление начальной стороны первой клетки с конечной стороной n-й клетки для сложенной полоски возможно только при четном n.
Упражнение. Используя введенное понятие ориентации, докажите, что у складываемых перестановок четные элементы находятся либо все на четных, либо все на нечетных местах.
Рассмотрим пары смежных клеток полоски, общая сторона которых расположена справа. Сюда относятся пары (1,2), (3,4),...,(n-1,n). При этом клетки с меньшим номером могут как предшествовать, так и следовать за клетками с большим номером, если рассматривать элементы складываемой перестановки от ее начала к концу. Эти пары смежных клеток образуют некоторую структуру частичной упорядоченности, определенную вложенностью друг в друга.
Например, n=10, f=<5 4 9 10 3 6 7 2 1 8>
Естественно, что всегда существует хотя бы одна пара, в которую не вложены никакие другие. В приведенном примере это пары (9,10) и (1,2). Заметим, что элементы такой пары в перестановке расположены на двух соседних местах. Таким образом, можно сформулировать следующее свойство.
2.Для любой складываемой перестановки существует хотя бы одно такое i, 1£i£n, что на i и i+1 местах расположены номера двух последовательных клеток полоски. Эти номера принадлежат множеству неупорядоченных пар {(1,2),(3,4),...,(n-1,n)}.
Замечание. Наряду с выбором пар смежных клеток полоски, общая сторона которых расположена справа, можно рассмотреть пары смежных клеток, общая сторона которых расположена слева. В этом случае пары образуют множество {(2,3),...,(n,1)}, а приведенный пример выглядит так:
f=<5 4 9 10 3 6 7 2 1 8>.
3.Перестановка четного порядка складываема тогда и только тогда, когда и справа, и слева смежные пары ее элементов образуют вложенную структуру. Проверка вложенности справа (слева) может быть осуществлена последовательным удалением пар (свойство 2).
Например, n=10, f=<5 4 9 10 3 6 7 2 1 8>:
удаление справа
удаляемая пара
удаление слева
удаляемая пара
<5 4 3 6 7 2 1 8>
(9,10)
< 9 10 3 6 7 2 1 8>
(5,4)
<5 6 7 2 1 8>
(4,3)
< 9 10 3 2 1 8>
(6,7)
< 7 2 1 8>
(5,6)
< 9 10 1 8>
(3,2)
< 7 8>
(2.1)
< 9 8>
(10,1)
< >
(7,8)
< >
(9,8)
Упражнение. Складываема ли перестановка
<1 2 7 6 5 8 9 4 3 10> ?
4.Пусть f=<a1 ... an> - складываемая перестановка, тогда перестановка <b1 ... bn>, где bi=(ai+m)mod n+1, i=1,...,n, m - любое целое число, - также складываемая.
Данное преобразование фактически соответствует перенумерации клеток замкнутой полоски, при котором значение ‘единица’ сопоставляется клетке с номером m mod n +1.
Замечание. Для нечетных m меняется ориентация полоски, т.е. левые стороны клеток становятся правыми, а правые - левыми.
На основе свойств 3 и 4 можно построить алгоритм вычисления булевской функции, истинной для складываемых перестановок замкнутых полосок и ложной в противном случае.
const n=...; {порядок перестановок}
type permit =array [1..n] of 1..n;
function sk (var f:permit):boolean;
var i,a,b : integer;
c:boolean;
procedure skr;
function pair(x,y:integer):boolean;
var z:integer;
begin if x>y then begin z:=x; x:=y; y:=z end;
pair:=odd(y) or (y-x<>1)
end;
procedure step;
begin c:=c and (i<n);
if c then begin i:=i+1; b:=f[i] end
end;
procedure bc (a:integer);
begin step;
while pair(a,b) and c do bc(b);
end;
begin {skr}
a:=f[1]; b:=f[2]; i:=2;
while i<n do
begin if pair(a,b) and c then bc(b)
else begin i:=i+2; {1}
a:=f[i-1];
b:=f[i]
end
end;
c:=c and not pair(a,b) {2}
end;{skr}
begin {sk}
c:=true; skr;
for i:=1 to n do f[i]:=f[i] mod n +1;
sk:=c
Комментарий. Переменная i служит для перебора элементов перестановки f; a,b определяют значения номеров клеток полоски, обрабатываемых в данный момент; c - булевская переменная, которая принимает значение false, если уже определено, что перестановка нескладываемая.
Функция pair принимает значение false, если клетки с номером xи y образуют пару клеток полоски, смежную справа. При этом если x, y - смежные справа клетки, эта пара она исключается из перестановки.
Поиск пар смежных справа клеток (процедура skr) основан на последовательном просмотре элементов перестановки от меньших индексов к большим (процедура step, оператор {1} ). При этом хранение элементов, для которых еще не найдены парные, организовано в виде стека. Формирование этого стека осуществляется за счет рекурсивного вызова процедуры bc. Перестановка признается складываемой справа в том и только в том случае, если при просмотре элемента с наибольшим индексом стек полностью разгружается (оператор {2} ).
В разделе операторов функции sk вначале проверяется складываемость f справа, затем происходят переориентация f с помощью перенумерации ее элементов и проверка складываемости справа измененной перестановки.
Замечание. Нетрудно видеть, что функция sk имеет временную вычислительную сложность O(n).
Упражнение. Разработайте реализацию функции skr без использования рекурсии в процедуре bc.
Возвратимся к незамкнутым складываемым единичным полоскам. Какие свойства сохраняются и для них, а какие изменяются?
Прежде всего об ориентации. Будем по-прежнему считать, что полоска ориентирована таким образом, что начальная сторона первой клетки находится слева, а конечная - справа. Естественно, что для таких полосок нет никаких ограничений на порядок, т.е. порядок складываемых незамкнутых полосок может быть как четным, так и нечетным. Здесь сохраняется только свойство, что при четном порядке конечная сторона n-й клетки расположена слева, а при нечетном справа.
Свойство, сформулированное в упражнении и связанное с месторасположением четных элементов, для складываемых перестановок, соответствующих незамкнутым полоскам, может не выполняться.
С точки зрения построения алгоритма распознавания складываемости перестановок наиболее интересными были свойства 2-4. Остановимся вначале на 4 свойстве. Для незамкнутых полосок возможна только перенумерация клеток в обратном порядке, когда n-й клетке сопоставляется 1, (n-1)-й—2 и т.д. Такое преобразование изменяет перестановку <a1 ... an> на <n+1-a1 ... n+1-an>. Заметим, что это преобразование меняет ориентацию перестановки только при нечетном n.
Алгоритм распознавания складываемых перестановок замкнутых полосок был основан на проверке структуры вложенности смежных клеток полоски справа (слева). А эта проверка, в свою очередь, строилась на последовательном удалении пар смежных клеток полоски, расположенных на двух рядом стоящих местах. Незамкнутая полоска характеризуется тем, что неупорядоченная пара (n,1),вообще говоря, не принадлежит к множеству смежных пар (слева, если n четно, и справа, если n нечетно). Это приводит к тому, что возможны ситуации, когда в складываемых перестановках нет двух смежных (слева, справа) элементов, расположенных на соседних местах.
Например, n=10, проверка складываемости слева
f=<1 3 8 7 4 10 5 6 9 2>
Причиной этого являются концевые клетки полоски (первая или последняя). Фактически в таких ситуация концевая клетка может быть интерпретирована как ‘неполная пара’ смежных клеток и должна быть удалена на этом шаге. В данном примере такой концевой клеткой является клетка с номером 10. Ее заключительная сторона располагается справа, но для нее отсутствует смежная клетка, которая переводила бы ‘продолжение’ полоски на левую сторону.
Обработка таких ‘неполных’ пар возникает: при четном n в случае проверки складываемости справа -для первой и последней клетки; при нечетном n - для первой клетки при проверке складываемости справа и для последней при проверке складываемости слева.
Упражнение. Разработайте алгоритм вычисления функции sk1, принимающей истинное значение для складываемых перестановок, соответствующих незамкнутым единичным полоскам, и ложное в противном случае.
Замечание.1. Алгоритм проверки вложенности справа смежных пар клеток полоски основан на использовании автоматов с магазинной памятью для разбора правильных структур арифметических выражений.
2. Со складываемыми перестановками связана одна из интересных задач перечислительной комбинаторики, получившая в свое время название ‘Проблема С. Улама’. Ее можно сформулировать следующим образом:
Можно ли с помощью элементарных операций арифметики и алгебры написать формулу, определяющую число складываемых перестановок, как функцию от n - порядка перестановок.
Другими словами, эту проблему можно сформулировать так. Хватает ли ‘изобразительной мощности’ элементарных операций для того, чтобы выразить данное число складываемых перестановок. Здесь даже не важно, какие операции мы включаем в число элементарных. Более существенным является разработка математического аппарата для исследования подобных задач. Решение этой задачи можно сравнить с решением Десятой проблемы Гильберта о неразрешимости диофантовых множеств, окончательный ответ в решении которой был дан Ю. В. Mатисевичем [1]. Разработка подобного аппарата выводит нас на самые современные методы математической логики, связанные с разрешимостью множеств. Проблема Улама актуальна с точки зрения компьютерной алгебры - в какой форме можно представить ответ на решение тех или иных достаточно сложных математических задач.
Упражнение. Обобщите изложенный материал для прямоугольных карт формы n*m.
При решении некоторых задач возникает необходимость генерирования перестановок n-го порядка. Чаще всего генерирование перестановок связано с задачами перебора, в которых решение данной представляет собой некоторую перестановку, обладающую конкретным заданным свойством. Для поиска искомой перестановки мы перебираем все возможные перестановки и проверяем для каждой из них выполнение этого конкретного свойства. Последовательное генерирование перестановок определяет на множестве всех перестановок некоторый порядок, а именно: пусть f и g перестановки, тогда f<g, если в этой генерации перестановка f появляется раньше перестановки g.
Например, предположим, мы разобрали кубик Рубика на отдельные части и собрали его случайным образом. После этого мы хотим проверить, можно ли его преобразовать таким образом, чтобы все его грани были одного цвета. Моделирование подобной задачи на компьютере явно потребует генерации перестановок.
С другой стороны, при проектировании решения задачи обычно имеются вполне определенные аргументы в пользу выбора той или иной упорядоченности перестановок при генерации. Фактически эта упорядоченность определяет алгоритм генерации перестановок. Чаще всего эти алгоритмы строятся по схеме, когда каждая последующая перестановка вычисляется как некоторая функция от предыдущей.
Замечание. Интересен вопрос, какого порядка перестановки можно генерировать, в разумное время, на современных ЭВМ? Вследствие того, что общее число перестановок n-го порядка равно n!, современные ЭВМ позволяют генерировать перестановки не более чем 16-го порядка (обоснуйте это!).
Вначале мы рассмотрим алгоритмы генерации всех перестановок в лексикографическом порядке. Этот порядок свойственен расположению слов в различных словарях, поэтому его часто называют словарным. Он характеризуется тем, что буквы алфавита считаются упорядоченным множеством, а слова в словаре располагаются вначале с меньших (ранее перечисленных в алфавите) букв, а затем с больших. Слова, начинающиеся с одинаковых букв, располагаются в зависимости от упорядоченности вторых букв в слове, и так далее. Для перестановок множества {1,2,…,n} числа считаются упорядоченными естественным образом. Формально можно дать следующее определение лексикографического порядка для перестановок.
Определение. Пусть f=<a1,...,an>, g=<b1,...,bn>, будем говорить, что f<g в лексикографическом порядке, если существует k³1 такое, что ak<bk и aq=bq для q<k.
Пример. При n=4 в лексикографическом порядке перестановки располагаются так:
1. <1, 2, 3, 4>
7. <2, 1, 3, 4>
13. <3, 1, 2, 4>
19. <4, 1, 2, 3>
2. <1, 2, 4, 3>
8. <2, 1, 4, 3>
14. <3, 1, 4, 2>
20. <4, 1, 3, 2>
3. <1, 3, 2, 4>
9. <2, 3, 1, 4>
15. <3, 2, 1, 4>
21. <4, 2, 1, 3>
4. <1, 3, 4, 2>
10. <2, 3, 2, 4>
16. <3, 2, 4, 1>
22. <4, 2, 3, 1>
5. <1, 4, 2, 3>
11. <2, 4, 1, 3>
17. <3, 4, 1, 2>
23. <4, 3, 1, 2>
6. <1, 4, 3, 2>
12. <2, 4, 3, 1>
18. <3, 4, 2, 1>
24. <4, 3, 2, 1>
Лексикографический порядок может быть интерпретирован так. Пусть каждая перестановка интерпретируется как целое число, записанное в n-ричной позиционной системе (с цифрами ‘0’«’1’,...,’n-1’«’n’). Тогда генерация их в лексикографическом порядке - это перечисление в порядке возрастания чисел, состоящих из n разных цифр.
Наша цель заключается в построении алгоритма генерации всех перестановок в лексикографическом порядке для произвольного n. Для этого мы выясним, как должна выглядеть следующая перестановка в генерации, если мы знаем текущую, при условии, что текущая перестановка не является последней в генерации. Рассмотрим подробнее свойства лексикографического порядка генерации перестановок:
Л1) В первой перестановке элементы располагаются в возрастающей последовательности, в последней - в убывающей (докажите это свойство для произвольного n).
Л2) Последовательность всех перестановок можно разбить на n блоков длины (n-1)!, соответствующих возрастающим значениям элемента в первой позиции. Остальные n-1 позиций блока, содержащего элемент p в первой позиции, определяют последовательность перестановок множества {1,...,n}/{р} в лексикографическом порядке.
Это свойство легко иллюстрируется приведенным примером генерации перестановок 4-порядка. Нетрудно видеть, что все перестановки 4-порядка разбиты на четыре столбца, при этом у перестановок первого столбца на 1-ой позиции расположен элемент 1, у второго - элемент 2 и так далее. Кроме того, в каждом столбце элементы, расположенные в перестановках со 2-ой по 4-ую позиции, образуют перестановки этих элементов в лексикографическом порядке. Для первого столбца перестановки элементов 2,3,4; для второго - 1,3,4; третьего - 1,2,4; для четвертого 1,2,3. Отметим также, что в каждом столбце элементы, расположенные со 2-ой по 4-ую позиции в первой перестановке, образуют возрастающую последовательность, а в последней перестановке эти же элементы расположены в убывающей последовательности (свойство Л1 лексикографического порядка).
Таким образом, если мы рассмотрим перестановки каждого столбца, то для элементов, расположенных со 2-ой по 4-у позиции, полностью выполняются свойства Л1 и Л2. Это замечание приводит к следующему обобщению свойства Л2 для перестановок произвольного порядка:
Л3) Последовательность всех перестановок можно разбить на n*(n-1)*...*(n-k+1) блоков выбором значений р1,...,pk элементов, расположенных на первых k позициях. При этом блок p1,...,pk предшествует блоку q1,...,qk, если р1,...,pk меньше q1,...,qk в лексикографическом порядке. Кроме того, для перестановок каждого такого обобщенного блока элементы, расположенные с k+1-ой по n-ую позиции, представляют собой генерацию перестановок этих элементов в лексикографическом порядке.
Теперь мы готовы сформулировать самое важное свойство лексикографического порядка, на основе которого легко преобразовать текущую перестановку в следующую. Это свойство можно записать так:
Л4) Любая текущая перестановка является заключительной для некоторого обобщенного блока. Этот блок определяется элементами текущей перестановки, расположенными на позициях в конце перестановки и представляющими собой максимально возможную убывающую последовательность значений элементов перестановки. Справедливость последнего замечания следует из свойства Л1 лексикографического порядка.
В дальнейшем максимально возможную убывающую последовательность значений элементов перестановки, расположенную на позициях в конце перестановки, будем называть “хвостом” перестановки.
Примеры. Рассмотрим приведенную выше генерацию перестановок 4-го порядка, тогда:
Перестановка <2,1,4,3> является заключительной для блока, состоящего из перестановок 7.<2,1,3,4> и 8.<2,1,4,3>, элементы 4,3 образуют ее хвост;
Перестановка <3,1,2,4> является заключительной для блока, состоящего из одной перестановки 13.<3,1,2,4>, ее хвост состоит из одного элемента - 4;
Перестановка <2,4,3,1> является заключительной для второго столбца приведенной генерации, ее хвост - 4,3,1;
Перестановка <4,3,2,1> является заключительной для всей генерации перестановок 4-го порядка, ее хвост совпадает со всей перестановкой.
Как же воспользоваться этим свойством, чтобы преобразовать текущую перестановку в следующую. Это можно сделать по следующему алгоритму:
1. Выделяем хвост текущей перестановки;
2. Если он не совпадает со всей перестановкой, то ищем в хвосте первый с конца перестановки элемент, больший элемента перестановки, расположенного непосредственно перед ее хвостом (если перестановка совпадает со своим хвостом, то она является заключительной во всей генерации);
3. Меняем местами элемент, найденный в предыдущем пункте, с элементом, расположенным непосредственно перед хвостом перестановки;
4. Располагаем все элементы, преобразованного в пункте 3 хвоста перестановки, в обратном порядке (инвертирование преобразованного хвоста перестановки).
Примеры. Перестановка <2,1,4,3> преобразуется по вышеприведенному алгоритму в перестановку <2,3,1,4>, а перестановка <3,1,2,4> в <3,1,4,2>. Рассмотрим перестановку 15-порядка <15,2,4,3,1,13,7,10,14,12,11,9,8,6,5>, она преобразуется в перестановку <15,2,4,3,1,13,7,11,5,6,8,9,10,12,14>.
Упражнение. В какие перестановки преобразуются следующие перестановки: а) n=3, <2,3,1>; б) n=5, <2,5,4,3,1>;
Замечание 1. Можно провести формальное доказательство того факта, что преобразованная по данному алгоритму перестановка действительно совпадает со следующей после текущей перестановки в лексикографическом порядке. Однако мы такое доказательство опустим.
Замечание 2. Приведенный выше алгоритм преобразования текущей перестановки в следующую формально можно записать так:
Пусть p=<p1,...,pk,...,pj,...,pn>,где
1£k<n pk<pk+1 и для q:k<q<n следует pq>pq+1
(если p=<n,n-1,...,1>, то k=0),
j>k и pj>pk и для q:j<q£n следует pq<pk;
тогда следующая за p перестановка, при k¹0, имеет вид
Теперь мы легко можем написать на языке Паскаль алгоритм генерации всех перестановок в лексикографическом порядке. Он основан на поиске k и j в текущей перестановке, транспозиции элементов pk и pj, и инвертировании ее‘хвоста’:
program LEX;
const n=...; {порядок перестановок}
var р : array [0..n] of 0..n; { текущая перестановка}

 ,...,r
,...,r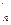 антиинверсий перестановки f, где r
антиинверсий перестановки f, где r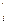 определяется как число элементов f, меньших i и расположенных перед ним.
определяется как число элементов f, меньших i и расположенных перед ним.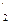 +1,..., rn+r
+1,..., rn+r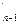 ,0/, где r
,0/, где r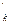 =rk, если kÎ{a1 ... ai} и r
=rk, если kÎ{a1 ... ai} и r ,…, j
,…, j - элементы в f, которыми i образуют инверсию, и расположенные левее i. Индексы элементов j
- элементы в f, которыми i образуют инверсию, и расположенные левее i. Индексы элементов j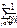 . Заметим, что j
. Заметим, что j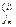 <k, 1£m£xi
<k, 1£m£xi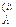 ,…, k
,…, k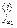 , которые расположены после него. Таким образом, для каждой инверсии (j
, которые расположены после него. Таким образом, для каждой инверсии (j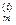 ,i) перестановки f однозначно сопоставляется инверсия (k, k
,i) перестановки f однозначно сопоставляется инверсия (k, k

 f=<1 3 8 7 4 10 5 6 9 2>
f=<1 3 8 7 4 10 5 6 9 2>