1. Коэффициент корреляции изменяется на отрезке от -1 до 1, т.е. .
2. При r = корреляционная связь представляет линейную функциональную зависимость.
3. При r = 0 линейная корреляционная связь отсутствует.
Выполнив преобразования в формуле (3.1.8), получим формулу (3.1.9) для вычисления коэффициента корреляции r:
. (3.1.9)
Коэффициент корреляции является безразмерной величиной. Чем ближе коэффициент корреляции к , тем теснее, интенсивнее связь между X и Y. Чем ближе он к0, тем слабее исследуемая связь.
· коэффициент детерминации
Одной из наиболее эффективных оценок силы взаимосвязи показателей является коэффициент детерминации.
Коэффициент детерминации равен квадрату эмпирического коэффициента корреляции между двумя рядами наблюдений: фактическими и теоретическими значениями зависимой переменной и вычисляется по формуле (3.1.10):
. (3.1.10)
Чем ближе к единице значение коэффициента детерминации, тем теоретические значения более точно аппроксимируют фактические значения у. Регрессионное уравнение оценено тем лучше, чем больше коэффициент детерминации (чем он ближе к единице).
Величина показывает на сколько процентов изменения Y обусловлено изменением X.
б) Оценка значимости уравнения регрессии
Проверка значимости уравнения регрессии состоит в установлении соответствия математической модели, выражающей зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных для описания зависимой переменной.
· Проверка гипотезы об отсутствии линейной связи между объясняемой и объясняющей переменной
Вычисляем t-статистику по формуле (3.1.11):
(3.1.11)
которая имеет распределение Стьюдента с степенями свободы. По таблицам Стьюдента (приложение Д) по заданному уровню значимости и числу степеней свободы находят табличное значение ( )-статистики. Если , то с заданной надёжностью 1- нулевую гипотезу о равенстве нулю коэффициента при переменной х в уравнении регрессии отвергают.
Замечание.
Чаще всего уровень значимости выбирают 0,05, что означает
· Проверка гипотезы о значимости коэффициента корреляции (проверка гипотезы )
В качестве критерия проверки нулевой гипотезы о равенстве нулю коэффициента корреляции (т.е. о том, что между наблюдаемыми переменными не существует линейной зависимости) принимают -статистику, вычисляемую по формуле (3.1.12):
, (3.1.12)
которая имеет распределение Фишера с 1 и степенями свободы. По таблицам Фишера (приложение Е) по заданной надёжности 1- и числу степеней свободы находят табличное значение . Если , то с заданной надёжностью 1- гипотезу об отсутствии корреляционной связи между случайными величинами X и Y следует отвергнуть и принять альтернативную гипотезу о наличии зависимости между этими случайными величинами.
Замечание.
Для парной регрессии , поэтому проверка значимости коэффициента корреляции эквивалентна проверке отличия от нуля коэффициента при переменной х.
в) Прогноз: построение доверительных интервалов
· Построение доверительного интервала для прогнозного значения
Предположим, что мы хотим распространить нашу модель на другие значения независимой переменной и поставить проблему прогнозирования среднего значения у соответствующего некоторому данному значению , которое может лежать как между выборочными наблюдениями от до , так и вне этого интервала. Прогноз может быть точечным или интервальным.
Точечный прогноз – это вычисленное по уравнению значение .
Интервальный прогноз – это доверительный интервал, покрывающий с заданной надежностью 1- ожидаемую величину :
, (3.1.13)
где
. (3.1.14)
· Построение доверительного интервала для коэффициента
Можно построить доверительный интервал для параметра , который покрывает истинное значение параметра с заданной надежностью 1- :
, (3.1.15)
где
. (3.1.16)
· Построение доверительного интервала для коэффициента корреляции
Доверительный интервал для коэффициента корреляции находят по формуле (3.1.17):
, (3.1.17)
где
. (3.1.18)
Для нелинейных регрессий рассчитывают индекс корреляции равный квадратному корню из коэффициента детерминации, вычисляемого по формуле (3.1.10).
Оценку надежности индекса корреляции проводят с помощью -статистики, вычисляемой по формуле (3.2.19):
, (3.1.19)
где m – число параметров в уравнении регрессии. По таблицам Фишера (приложение Е) по заданной надёжности 1- и числу степеней свободы ( ) и ( ) находят табличное значение . Если , то с заданной надёжностью 1- можно сделать вывод о надежности индекса корреляции.
Адекватность построенной модели изучаемому процессу может быть установлена с помощью средней ошибки аппроксимации (среднего процента расхождения теоретических значений и фактических):
. (3.1.20)
При моделировании экономических показателей чаще всего допускается 5-% погрешность (иногда 7-%, редко 10-%). Модель считается адекватной (а значит и пригодной), если .
Поскольку одна и та же тенденция может быть выражена разными моделями, то часто используют ряд функций, а затем и выбирают наиболее предпочтительную. Выбор наиболее предпочтительной модели можно проводить на основе остаточного среднеквадратического отклонения (остаточной дисперсии):
, (3.1.21)
где - число параметров в уравнении.
Лучшей будет та функция, у которой меньше.
Пример 3.1. Исследовать зависимость объема прибыли от количества торговых точек. Сделать прогноз в предположении, что количество торговых точек будет увеличено до 25.
Объем прибыли,
(тыс. грн.), у
2,2
2,25
2,24
2,1
2,9
3,1
1,9
1,85
2,16
1,68
Количество торговых точек, (шт.), х
Решение.Для нахождения параметров линейного уравнения регрессии (3.1.1) с помощью системы линейных уравнений Гаусса (3.1.2) составим вспомогательную расчетную таблицу 3.1:
Таблица 3.1
Вспомогательная расчетная таблица
х
х2
у
ху
у2
2,2
4,84
2,25
38,25
5,0625
2,24
35,84
5,0176
2,1
27,3
4,41
2,9
52,2
8,41
3,1
58,9
9,61
1,9
20,9
3,61
1,85
18,5
3,4225
2,16
30,24
4,6656
1,68
15,12
2,8224
22,38
330,25
51,8706
Замечание.
Вспомогательную расчетную таблицу 3.1 удобно строить в пакете EXCEL.
Система линейных уравнений Гаусса (3.1.2) в нашем случае примет вид:
Решив эту систему, найдем коэффициенты и : .
Тогда уравнение прямой линии регрессии у на х (3.1.1) примет вид:
у = 0,5633 + 0,1179х.
Найдем показатели тесноты связи показателя Y и фактора X.
Таким образом, r = 0,9073. Это значит, что между переменными Х и Y высокая степень взаимосвязи. Коэффициент детерминации, найденный по формуле (3.1.10), равен . Это означает, что регрессионное уравнение оценено хорошо, так как близок к единице, фактор Х на 82,32% предопределяет изменение Y.
Для проверки гипотезы об отсутствии линейной связи между объясняемой и объясняющей переменной вычислим t-статистику по формуле (3.1.11):
.
По таблицам Стьюдента (приложение Д) находим табличное значение ( )-статистики. t(0,05;8)=2,306. Так как наблюдаемое значение t-статистики больше критического, то гипотезу об отсутствии линейной связи между объясняемой и объясняющей переменной следует отвергнуть.
Для проверки гипотезы о значимости коэффициента корреляции вычислим – статистику по формуле (3.1.12):
.
По таблицам Фишера (приложение Е) находим табличное значение Так как наблюдаемое значение F- статистики больше критического, то гипотезу о равенстве нулю коэффициента корреляции следует отвергнуть. Коэффициент корреляции значительно отличается от нуля, поэтому между переменными Х и Y существует линейная корреляционная зависимость.
Для построения доверительных интервалов для параметра и коэффициента корреляции r , найдем , затем вспомогательные вычисления проведем в таблице 3.2:
Таблица 3.2
Вспомогательные вычисления
0,8
0,64
2,3
2,36
-0,16
0,0256
2,8
7,84
2,25
2,6
-0,35
0,1225
1,8
3,24
2,24
2,48
-0,24
0,0576
-1,2
1,44
2,1
2,12
-0,02
0,0004
3,8
14,44
2,9
2,72
0,18
0,0324
4,8
23,04
3,1
2,84
0,26
0,0576
-3,2
10,24
1,9
1,88
0,02
0,0004
-4,2
17,64
1,85
1,76
0,09
0,0081
-0,2
0,04
2,16
2,24
-0,08
0,0064
-5,2
27,01
1,68
1,64
0,04
0,0016
105,6
0,3126
По формуле (3.1.16) имеем
.
Тогда доверительный интервал с 95% надежностью для параметра по формуле (3.1.15) имеет вид:
;
.
Полученный доверительный интервал не содержит нуля, поэтому можно говорить об отличии параметра от нуля.
Для нахождения доверительного интервала для коэффициента корреляции найдем по формуле (3.1.18):
.
Коэффициент корреляции имеет следующий доверительный интервал, найденный по формуле (3.1.17):
;
.
Доверительный интервал для коэффициента корреляции говорит о высокой степеней линейной корреляционной связи между переменными.
Предположим, что количество торговых точек будет увеличено до 25, тогда х = 25. Подставив это значение в построенное уравнение прямой линии регрессии, получим:
- это ожидаемый объем прибыли.
Для нахождения доверительного интервала для прогнозного значения, вычислим по формуле (3.1.14) величину :
.
Найдем доверительный интервал для прогнозного значения по формуле (3.1.13):
;
.
Таким образом, при наличии 25 торговых точек объем прибыли будет от 3055 до 3966,6 тыс. гривен.
Замечание.
Для построения регрессионной модели и оценки силы взаимосвязи показателей Y и X удобно использовать пакет EXCEL. Для этого при нахождении уравнения регрессии, в падающем меню Сервис Þ выбрать команду Анализ данных Þ выбрать инструмент анализа Регрессия Þ в разделе Входные данные в текстовом полеВходной интервал Yввести диапазон для Y Þ в разделе Входные данные в текстовом полеВходной интервал Хввести диапазоны для Þ в разделе Параметры вывода в опции Новый рабочий листустановить флажок.
Результаты расчетов для данного примера с помощью пакета электронных таблиц EXCEL имеют вид:
ВЫВОД ИТОГОВ
Y
X
2,2
Регрессионная статистика
2,25
Множественный R
0,907318995
2,24
R-квадрат
0,823227759
2,1
Нормир. R-квадрат
0,801131228
2,9
Стандартная ошибка
0,198554137
3,1
Наблюдения
1,9
1,85
2,16
1,68
ANOVA
df
SS
MS
F
Значимость F
Регрессия
1,468770038
1,46877003
37,255974
0,000288272
Остаток
0,315389962
0,03942374
Итого
1,78416
Коэффициенты
Стандартная ошибка
t-статистика
P-Значение
Нижние 95%
Верхние 95%
Y-пересечение
0,563314394
0,281461936
2,00138746
0,0803433
-0,08573841
1,212367202
Переменная X 1
0,117935606
0,019321773
6,10376721
0,0002883
0,073379488
0,162491724
На основании данных таблицы можно сделать такие выводы:
§ множественный коэффициент =0,907;
§ уравнение множественной регрессии ;
§ -статистика 37,26.
Сравнивая полученное значение с , найденным по таблице Фишера ( ), получим, что , т.е. уравнение регрессии значимо.
§ -статистика для коэффициента равна 6,104, для коэффициента.
Сравнивая , найденное по таблице Стьюдента t(0,05;8) = 2,306, с -статистикой, получаем, что -статистика больше . Следовательно, коэффициенты достаточно надежен.
§ доверительный интервал для параметра уравнения регрессии: (0,073;0,162).
Для наглядного представления изобразим графически данные примера, и прямую линию, соответствующую построенной модели.
Замечание.
Удобно изображать графически данные в виде диаграмм, соответствующую им линию регрессии в пакете Excel. Для этого нужно войти в опцию Вставка Þ в появившемся меню выбрать опцию Диаграмма Þ в появившемся окне Мастер диаграмм в меню Тип выбрать опцию Точечная Þ в появившемся окне указать рассматриваемый диапазон данных. Для изображения линии регрессии на точечной диаграмме активизировать одну из точек, правой кнопкой мыши вызвать меню, выбрать опцию Добавить линию трендаÞ в появившемся окне Линия тренда во вкладке Тип выбрать в данном случае Линейная Þ войти во вкладку Параметры и выбрать опцию Показывать уравнение на диаграмме, затем выбрать опцию Поместить на диаграмму величину достоверности аппроксимации (R^2).
Рисунок 3.1 - Диаграмма уравнения прямой линии регрессии Y на Х
Пример 3.2. Исследовать зависимость показателя у и фактора х с помощью логарифмической, степенной и полиномиальной регрессий.
х
18,4
25,6
27,9
30,8
32,8
35,3
38,5
45,6
34,7
23,9
19,3
у
75,8
64,8
61,5
60,8
48,8
59,7
54,8
57,3
56,8
64,8
80,7
Решение.Дляпостроения логарифмической, степенной и полиномиальной регрессий рассчитаем вспомогательную таблицу
Таблица 3.3
Вспомогательная расчетная таблица
x
y
18,4
75,8
338,56
6229,50
114622,87
1394,72
25662,85
2,91
8,48
220,76
4,33
12,60
25,6
64,8
655,36
16777,22
429496,73
1658,88
42467,33
3,24
10,51
210,12
4,17
13,53
27,9
61,5
778,41
21717,64
605922,13
1715,85
47872,22
3,33
11,08
204,71
4,12
13,71
30,8
60,8
948,64
29218,11
899917,85
1872,64
57677,31
3,43
11,75
208,39
4,11
14,08
32,8
48,8
1075,84
35287,55
1157431,71
1600,64
52500,99
3,49
12,18
170,33
3,89
13,57
35,3
59,7
1246,09
43986,98
1552740,29
2107,41
74391,57
3,56
12,70
212,76
4,09
14,57
38,5
54,8
1482,25
57066,63
2197065,06
2109,80
81227,30
3,65
13,33
200,06
4,00
14,62
45,6
57,3
2079,36
94818,82
4323738,01
2612,88
119147,33
3,82
14,59
218,88
4,05
15,46
34,7
56,8
1204,09
41781,92
1449832,73
1970,96
68392,31
3,55
12,58
201,45
4,04
14,33
23,9
64,8
571,21
13651,92
326280,86
1548,72
37014,41
3,17
10,07
205,67
4,17
13,24
19,3
80,7
372,49
7189,06
138748,80
1557,51
30059,94
2,96
8,76
238,88
4,39
13,00
332,8
685,8
10752,3
367725,34
13195797,04
20150,01
636413,56
37,12
126,04
2292,02
45,36
152,71
Для оценки параметров уравнения параболической функции составим систему уравнений Гаусса по формуле (3.1.3):
Решив эту систему, найдем =142,83, = - 4,599, = 0,06. По формуле (3.1.2) уравнение параболической функции имеет вид:
.
Для оценки параметров уравнения логарифмической функции составим систему уравнений Гаусса по формуле (3.1.5):
Решив эту систему, найдем =155,14, = - 27,5. По формуле (3.1.4) уравнение логарифмической функции имеет вид:
Для оценки параметров уравнения степенной функции составим систему уравнений Гаусса по формуле (3.1.7):
Решив эту систему, найдем =5,54, = - 0,42. Откуда =254,87. По формуле (3.1.6) уравнение степенной функции имеет вид:
.
Для каждой из полученных моделей найдем индекс корреляции по формуле, -статистику по формуле (3.2.22), среднюю ошибку аппроксимации по формуле (3.1.23). Для адекватных моделей вычислим остаточную дисперсию по формуле (3.1.24). Результаты представим в таблице 3.4.
Таблица 3.4
Модель
Уравнение
R
F
Fкр
параболическая
0,93
22,41
4,74
3,96
3,88
логарифмическая
0,85
20,83
4,46
5,27
0,65
степенная
0,84
19,17
4,46
4,83
4,78
Сравнивая значения -статистики с Fкр, можно сделать вывод о надежности индекса корреляции для соответствующих нелинейных моделей. Для построенных моделей можно сделать вывод, что все модели являются адекватными, поскольку средняя ошибка аппроксимации не превышает 5-7%, однако наилучшей является логарифмическая модель, которая имеет наименьшую остаточную дисперсию.

 .
. корреляционная связь представляет линейную функциональную зависимость.
корреляционная связь представляет линейную функциональную зависимость. . (3.1.9)
. (3.1.9) равен квадрату эмпирического коэффициента корреляции между двумя рядами наблюдений: фактическими и теоретическими значениями зависимой переменной и вычисляется по формуле (3.1.10):
равен квадрату эмпирического коэффициента корреляции между двумя рядами наблюдений: фактическими и теоретическими значениями зависимой переменной и вычисляется по формуле (3.1.10): . (3.1.10)
. (3.1.10)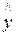 более точно аппроксимируют фактические значения у. Регрессионное уравнение оценено тем лучше, чем больше коэффициент детерминации (чем он ближе к единице).
более точно аппроксимируют фактические значения у. Регрессионное уравнение оценено тем лучше, чем больше коэффициент детерминации (чем он ближе к единице). показывает на сколько процентов изменения Y обусловлено изменением X.
показывает на сколько процентов изменения Y обусловлено изменением X. (3.1.11)
(3.1.11) степенями свободы. По таблицам Стьюдента (приложение Д) по заданному уровню значимости
степенями свободы. По таблицам Стьюдента (приложение Д) по заданному уровню значимости  и числу степеней свободы
и числу степеней свободы  находят табличное значение
находят табличное значение  (
(  )-статистики. Если
)-статистики. Если  , то с заданной надёжностью 1-
, то с заданной надёжностью 1-  нулевую гипотезу о равенстве нулю коэффициента при переменной х в уравнении регрессии отвергают.
нулевую гипотезу о равенстве нулю коэффициента при переменной х в уравнении регрессии отвергают. )
) -статистику, вычисляемую по формуле (3.1.12):
-статистику, вычисляемую по формуле (3.1.12): , (3.1.12)
, (3.1.12) степенями свободы. По таблицам Фишера (приложение Е) по заданной надёжности 1-
степенями свободы. По таблицам Фишера (приложение Е) по заданной надёжности 1-  . Если
. Если  , то с заданной надёжностью 1-
, то с заданной надёжностью 1- 
 , поэтому проверка значимости коэффициента корреляции эквивалентна проверке отличия от нуля коэффициента при переменной х.
, поэтому проверка значимости коэффициента корреляции эквивалентна проверке отличия от нуля коэффициента при переменной х.
 , которое может лежать как между выборочными наблюдениями от
, которое может лежать как между выборочными наблюдениями от  до
до  , так и вне этого интервала. Прогноз может быть точечным или интервальным.
, так и вне этого интервала. Прогноз может быть точечным или интервальным. значение
значение  .
. , (3.1.13)
, (3.1.13) . (3.1.14)
. (3.1.14)
 с заданной надежностью 1-
с заданной надежностью 1-  , (3.1.15)
, (3.1.15) . (3.1.16)
. (3.1.16)
 , (3.1.17)
, (3.1.17) . (3.1.18)
. (3.1.18) , (3.1.19)
, (3.1.19) ) и (
) и (  ) находят табличное значение
) находят табличное значение  . (3.1.20)
. (3.1.20) .
. , (3.1.21)
, (3.1.21) - число параметров в уравнении.
- число параметров в уравнении. меньше.
меньше.
 и
и  :
:  .
.
 . Это означает, что регрессионное уравнение оценено хорошо, так как
. Это означает, что регрессионное уравнение оценено хорошо, так как  близок к единице, фактор Х на 82,32% предопределяет изменение Y.
близок к единице, фактор Х на 82,32% предопределяет изменение Y. .
. – статистику по формуле (3.1.12):
– статистику по формуле (3.1.12): .
. Так как наблюдаемое значение F- статистики больше критического, то гипотезу о равенстве нулю коэффициента корреляции следует отвергнуть. Коэффициент корреляции значительно отличается от нуля, поэтому между переменными Х и Y существует линейная корреляционная зависимость.
Так как наблюдаемое значение F- статистики больше критического, то гипотезу о равенстве нулю коэффициента корреляции следует отвергнуть. Коэффициент корреляции значительно отличается от нуля, поэтому между переменными Х и Y существует линейная корреляционная зависимость. и коэффициента корреляции r , найдем
и коэффициента корреляции r , найдем  , затем вспомогательные вычисления проведем в таблице 3.2:
, затем вспомогательные вычисления проведем в таблице 3.2:






 .
. ;
; .
. от нуля.
от нуля. по формуле (3.1.18):
по формуле (3.1.18): .
. ;
; .
. - это ожидаемый объем прибыли.
- это ожидаемый объем прибыли. :
: .
. ;
; .
. Þ в разделе Параметры вывода в опции Новый рабочий листустановить флажок.
Þ в разделе Параметры вывода в опции Новый рабочий листустановить флажок.
 =0,907;
=0,907; ;
; -статистика 37,26.
-статистика 37,26. , найденным по таблице Фишера (
, найденным по таблице Фишера (  , т.е. уравнение регрессии значимо.
, т.е. уравнение регрессии значимо. -статистика для коэффициента
-статистика для коэффициента  , найденное по таблице Стьюдента t(0,05;8) = 2,306, с
, найденное по таблице Стьюдента t(0,05;8) = 2,306, с  Рисунок 3.1 - Диаграмма уравнения прямой линии регрессии Y на Х
Рисунок 3.1 - Диаграмма уравнения прямой линии регрессии Y на Х










 =142,83,
=142,83,  = - 4,599,
= - 4,599,  = 0,06. По формуле (3.1.2) уравнение параболической функции имеет вид:
= 0,06. По формуле (3.1.2) уравнение параболической функции имеет вид: .
.


 =5,54,
=5,54,  .
.

