Развитие методологии проектирования баз данных за последние 30 лет находило свое отражение в особых документах, названых Манифестами. Каждый такой документ, всего их 3, определяет особый подход к проектированию баз данных и содержит требования и характеристики современных для данного этапа систем.
Первый манифест – Манифест систем объектно-ориентированных баз данных появился в 1989г. Основной идеей авторов было то, что будущие системы баз данных должны являться системами объектно-ориентированного программирования, сохраняя традиционные возможности систем баз данных.
К моменту появления Первого манифеста концепция объектно-ориентированного подхода активно развивалась в рамках различных проектов многими группами исследователей и разработчиков. В начале 80-х гг. осознание полезности объектно-ориентированного подхода применительно к логической организации баз данных привело к тому, что многие исследователи приступили к созданию ООСУБД. В ранних проектах ООСУБД участвовали группы из университетов и исследовательских институтов, ведущих компьютерных компаний и небольших начинающих компаний.
Университетские исследовательские группы внесли огромный вклад в развитие технологии баз данных, и не только в области реляционных систем. Многие университетские исследователи с энтузиазмом приняли объектно-ориентированный подход, особенно в применении к области человеко-машинных взаимодействий. К наиболее успешным проектам, в которых производились исследования с целью объединения объектно-ориентированного подхода с технологией баз данных, можно отнести следующие:
Encore в Брауновском университете (Broun University );
Cactis в Колорадском университете (University of Colorado at Boulder);
Thor в Массачусетском технологическом институте (MIT );
Exodus в Висконсинском университете (University of Wisconsin );
Pisa в университетах Глазго и Св. Эндрю (Universities of Glasgo and St. Andrew).
Среди исследовательских институтов, в которых существовали мощные группы, ориентированные на исследования в области объектно-ориентированных баз данных, входили OGI (Oregon Graduate Institute ), MCC (Microelectronics and Computer Technology Corporation ) и французский исследовательский центр INRIA . На базе исследований OGI была создана ООСУБД Gemstone ; исследования, проводившиеся в MCC , привели к созданию ООСУБД Itasca и UniSQL ; в результате исследовательского проекта Altair , выполнявшегося в INRIA , появилась ООСУБД O 2.
Среди наиболее значительных прототипов ООСУБД, созданных в результате исследований, которые проводились в ведущих компьютерных компаниях, можно выделить систему IRIS компании Hewlett -Packard и систему Trellis компании DEC . Идеи и методы, заложенные в этих проектах, были впоследствии использованы в большинстве коммерческих ООСУБД. Тем не менее, руководители крупных компаний решили не производить коммерческие ООСУБД самостоятельно, а предоставить эту возможность начинающим компаниям.
Первыми компаниями, выпустившими на рынок ООСУБД в виде законченных продуктов, были следующие компании:
Grapael сООСУБД G-Base (1986 г);
Servio-Logic сООСУБД Gemstone (1987 г.);
Symbolics сООСУБД Statice (1988 г.);
Ontologic Ltd. сООСУБД Vbase (1988 г.).
Ко всем ранним реализациям ООСУБД применительны следующие замечания.
· Системы были почти неприменимы для практического использования, поскольку они очень медленно работали, поддерживали только однопользовательский режим работы и были крайне ненадежны. В них не поддерживались распределенные данные, безопасность и возможность восстановления после сбоев. Почти во всех системах отсутствовали развитые механизмы формулировки запросов. При построении пользовательских интерфейсов не использовались даже уже имевшиеся результаты, полученные группами из области человеко-машинных взаимодействий.
· Разработчики практически всех систем полностью игнорировали язык C ++, поскольку считалось, что применение этого языка в контексте ООСУБД вызывает серьезные проблемы. В системах G -Base и Statice использовался Lisp ; Gemstone опиралась на Smalltalk ; для Vbase были разработаны собственные языки определения данных (TDL ) и манипулирования данными (COP ). В исследовательских группах также предпочитали не опираться на C ++, а разрабатывать новые языки, в большей степени соответствующие направлению исследований. Среди отрицательных последствий игнорирования C ++ было то, что пользователей заставляли изучать новый язык; они вынуждались одновременно использовать два языка; отсутствие поддержки C ++ ограничивало рынок ООСУБД.
Новые компании Objectivity , Object Design и Versant , образованные в конце 80-х, ориентировались на создание ООСУБД, которые опирались бы на C ++. Компания Ontologic отказалась от развития Vbase и переключилась на разработку системы ONTOS , основанной на C ++. В Европе были образованы компании O 2Technology и BKS Software . Задачей первой компании было создание коммерческой ООСУБД O2 на основе результатов проекта Altair . BKS начала разработку системы POET .
Первый манифест стал первой попыткой прийти к согласию об определении систем объектно-ориентированных баз данных. Авторы стремились привести описание основных свойств и характеристик, которыми должна обладать система, претендующая на то, чтобы быть квалифицирована как система объектно-ориентированных баз данных. Эти характеристики были разделены на три группы:
· Обязательные: сложные объекты, идентифицируемость (identity) объектов, инкапсуляция, типы или классы, наследование, перегрузка методов совместно с поздним связыванием, расширяемость, вычислительная полнота, стабильность, управление вторичной памятью, параллелизм, восстанавливаемость и средства обеспечения незапланированных (ad hoc) запросов.
· Необязательные, т.е., такие, которые могут быть добавлены к системе для ее улучшения, но обязательными не являются. К этим характеристикам относятся множественное наследование, проверка и вывод типов, распределенность, проектные транзакции и версии.
· Открытые характеристики, которые проектировщик может реализовать по собственному усмотрению. В число этих характеристик входят используемая парадигма программирования, система представления, система типов и однородность.
Рассмотрим характеристики первой группы.
Сложные объекты.
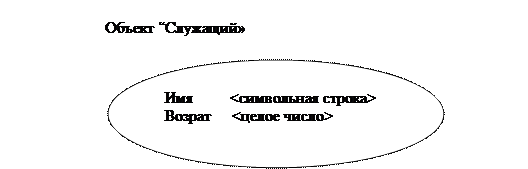
Сложные объекты строятся из более простых при помощи конструкторов. Простейшими объектами являются такие объекты, как целые числа символы, символьные строки, числа с плавающей точкой. Имеются различные конструкторы сложных объектов: примерами могут служить конструкторы кортежей, множеств, мультимножеств, списков, массивов.
Рис. 1. Объект «Служащий»
Минимальный набор конструкторов: конструкторы множеств, списков и кортежей. Конструкторы должны быть ортогональными, т.е. должны быть применимы к любому объекту. Конструкторы реляционной модели не ортогональны: конструкция множества может быть применима только к кортежам, конструкция кортежей – только к атомарным значениям.
Идентифицируемость объектов
Идея идентифицируемости объектов базы данных состоит в том, что объект существует независимо от его значения. Имеется два понятия эквивалентности объектов: два объекта представляют собой один и тот же объект или они имеют одно и тоже значение, что влечет два следствия: разделяемые объекты, изменения объектов.
Понятие разделяемых объектов можно проиллюстрировать следующим примером. У человека имеются имя, возраст и некоторое количество детей. У Василия и Анны имеется 10-летний сын по имени Дмитрий. В системе без идентифицируемости Василий может быть представлен так: (Василий, 38, (Дмитрий, 10, -)), а Анна – (Анна, 35, (Дмитрий, 10, -)), в этом случае нет возможности выразить являются ли Анна И Василий родителями одного и того же ребенка или нет. В модели с идентифицируемостью объектов возможно отразить обе эти ситуации: либо объекты Анна и Василий имеют общую часть (Дмитрий, 10, -), либо нет.
Изменения объектов. Если Василий и Анна имеют общего сына по имени Дмитрий, в модели с идентифицируемостью объектов, все исправления касаю.щиеся сына Анны будут производиться и с объектом Дмитрий, а следовательно, и с сыном Василия.
Типы и классы
Имеются две основные категории объектно-ориентированных систем, в одной из которых поддерживают классы, а в другой – типы. К первой категории относятся системы, опирающиеся на языки Smalltalk и Lisp . К представителям второй категории относятся, например, C ++ и Simula .
В объектно-ориентированной системе в понятии типа обобщаются общие черты множества объектов с одинаковыми характеристиками. Это понятие соответствует понятию абстрактного типа данных. Тип делится на две части – интерфейс и реализация. Пользователям типа видна только интерфейсная часть, а реализация объекта видна только проектировщику типа. Интерфейс состоит из списка операций вместе с их сигнатурами (т.е. набором типов входных параметров и типом результата). Реализация типа состоит из части данных и части операций. Часть данных описывает внутреннюю структуру данных объекта. В зависимости от мощности системы часть данных может быть более или менее сложной. Часть операций состоит из процедур, которые реализуют операции интерфейсной части.
Если система типов достаточно тщательно разработана, то система может произвести проверку типов во время компиляции, иначе некоторые проверки могут быть отложены до времени выполнения. Таким образом, типы главным образом используются во время компиляции для проверки правильности программ. Вообще говоря, в основанных на типах системах тип имеет специальный статус и не может быть изменен во время выполнения.
Понятие класса отличается от понятия типа. Его спецификация совпадает со спецификацией типа, но является более динамическим понятием. Класс характеризуется двумя аспектами: фабрика объектов и склад объектов. Фабрика объектов может быть использована для создания новых объектов посредством выполнения операции new данного класса операции или клонирования некоторого объекта-прототипа, являющегося представителем данного класса. Склад объектов означает, что к классу присоединяется его расширение, т.е. набор объектов, которые являются экземплярами класса. Пользователь может манипулировать складом, применяя операции ко всем экземплярам класса. Классы используются не для проверки правильности программы, а скорее для создания и манипулирования объектами. В большинстве систем, в которых используется механизм классов, классы обладают таким же статусом, как переменные и значения, ими можно манипулировать во время выполнения программы, т. е. изменять их и передавать как параметры. В большинстве случаев это делает невозможным проверку типов во время компиляции, но придает системе большую гибкость и однородность. Здесь речь идет о так называемых “полнотиповых” языках программирования (баз данных), в которых действительно создается иллюзия, что с типами можно оперировать во время выполнения программы. Насколько известно автору, при реализации, тем не менее, обычно пытаются ограничить операции над типами таким образом, чтобы можно было выполнить эти операции во время компиляции.
Конечно, между классами и типами имеется значительное сходство, оба термина использовались в каждом из значений, а в некоторых системах отличие между ними и вовсе едва заметно. Авторы Первого манифеста не чувствовали себя вправе отдать предпочтение одному из двух подходов и оставляли право выбора за проектировщиком системы. 5 Однако требовалось, чтобы система предоставляла некоторый механизм структурирования данных, будь это классы или типы. Таким образом, классическое понятие схемы базы данных заменяется на понятие множества классов или множества типов.
Авторы не видели необходимости в том, чтобы система автоматически поддерживала экстент типа (т. е. набор объектов данного типа в базе данных) или, если экстент типа поддерживается, чтобы система предоставляла пользователю доступ к нему. Рассмотрим, например, тип “прямоугольник”, который может использоваться в различных базах данных многими пользователями. Не имеет смысла говорить о множестве всех прямоугольников, поддерживаемых системой, или производить операции над ними. Мы думаем, что более оправдано отдать на откуп пользователю поддержку его множества прямоугольников и манипулирование ими. С другой стороны, в случае такого типа как “служащий” весьма удобно, чтобы система автоматически сопровождала экстент этого типа.
Иерархии классов или типов
Наследование обладает двумя положительными достоинствами. Во-первых, оно является мощным средством моделирования, поскольку обеспечивает возможность краткого и точного описания мира. Во-вторых, эта возможность помогает факторизовать совместно используемые в приложениях спецификации и реализации. 6 Наследование способствует повторному использованию кода, потому что каждая программа находится на том уровне, на котором ее может совместно использовать наибольшее число объектов.
Имеется по крайней мере четыре типа наследования: наследование через подстановку, наследование путем включения, наследование через ограничение и наследование через специализацию.
Наследование через подстановку подразумевает, что тип T наследует от типа T ’ , если над объектами типа T можно выполнить больше операций, чем над объектами типа T ’ . Таким образом, вместо объекта типаT ’ всегда можно подставить объект типа T . Этот тип наследования базируется на поведении, а не на значениях.
Наследование путем включения соответствует понятию классификации. В этом случае утверждается, что тип T является подтипом T ’ , если каждый объект типа T является также объектом типа T ’ . Этот тип наследования базируется на структуре, а не на операциях. Примером является тип “квадрат” с методами “получить”, “установить размер” и “раскрашенный квадрат” с методами “получить”, “установить размер” и “раскрасить”.
Наследование через ограничение является частным случаем наследования путем включения. Тип T является подтипом типа T ’ , если к нему относятся все объекты типа T ’ , которые удовлетворяют данному ограничению. Примером такого наследования является класс “подросток” как подкласс класса “человек”: объекты класса “подросток” не имеют дополнительных полей или операций по сравнению с объектами класса “человек”, но они удовлетворяют более специфичным ограничениям (возраст подростков ограничен снизу 13, а сверху 19 годами). 7
При наследовании через специализацию тип T является подтипом T ’ , если объекты типа T являются объектами типа T ’ , но при этом содержат более конкретные данные. Примером являются типы “люди” и “служащие”, где данные о служащих включают все данные о соответствующих людях, но включают некоторые дополнительные поля.
Существующие системы и прототипы в той или иной мере поддерживают эти четыре типа наследования. Авторы Первого манифеста не хотели навязывать какой-либо конкретный стиль наследования. По всей видимости, только потому, что среди самих них не было общего мнения относительно достоинств и недостатков каждого из подходов. Вообще, Первому манифесту свойственно сглаживание разногласий.
Перекрытие, перегрузка и позднее связывание
Имеются случаи, когда желательно иметь одно и то же имя для различных операций. Рассмотрим, например, операцию визуализации: она принимает на входе объект и отображает его на экране. В зависимости от типа объекта используются разные механизмы отображения. Если объект является изображением, то желательно, чтобы оно действительно появилось на экране. Если объект является человеком, то желательно, чтобы в том или ином виде был отображен описывающий человека кортеж. Наконец, если объект является графом, то желательно получить графическое представление. Рассмотрим теперь задачу отображения множества объектов, типы элементов которого не известны во время компиляции.
В приложениях, опирающихся на традиционные системы, потребовалось бы три операции: “отобразить растровое изображение”, “отобразить объект типа человек” и “отобразить граф”. В программе проверялся бы тип каждого объекта, входящего во множество, и использовалась бы соответствующая операция отображения. Для этого при программировании нужно знать все возможные типы объектов, которые могут входить в заданное множество, и соответствующие им операции отображения, и использовать их согласованным образом.
В объектно-ориентированной системе операция отображения определяется на уровне типа “объект” (наиболее общий тип в системе). Таким образом, операция отображения имеет единственное имя и может быть одинаковым образом применена к графам, людям и изображениям. Однако реализация операции переопределяется для каждого типа в соответствии с его особенностями (такое переопределение называется перекрытием – overlapping ). В результате три разные программы имеют одно имя “отобразить” (это называется перегрузкой – overloading ). Для отображения множества элементов мы просто применяем операцию отображения к каждому элементу, оставляя за системой выбор соответствующей реализации во время выполнения.
Здесь реализатор типов по-прежнему должен написать то же количество программ. Но прикладному программисту уже не нужно заботиться о трех различных программах. Кроме того, код проще, так как оператор case над типами отсутствует. Наконец, код становится более сопровождаемым, поскольку и при введении нового типа, и при добавлении нового экземпляра существующего типа программа отображения будет работать без изменения (при условии, что для этого нового типа будет обеспечено перекрытие метода отображения).
Чтобы обеспечить эти новые функциональные возможности, система не может связывать имена операций с программами во время компиляции. Поэтому имена операций должны разрешаться (транслироваться в адреса программ) во время выполнения. Эта отложенная трансляция называется поздним связыванием (late binding ). Позднее связывание затрудняет проверку типов (а в некоторых случаях делает ее невозможной), но оно не отменяет ее полностью.
Вычислительная полнота
С точки зрения языка программирования свойство вычислительной полноты является очевидным: оно просто означает, что любую вычислимую функцию можно выразить с помощью языка манипулирования данными системы баз данных. С точки зрения базы данных это является новшеством, так как SQL , например, не является полным языком (напомним, что речь идет про SQL 15-летней давности).
Авторы Первого манифеста не призывали проектировщиков объектно-ориентированных систем баз данных к созданию новых языков программирования. Вычислительную полноту можно получить, разумным образом опираясь на существующие языки программирования. Вычислительная полнота – это не то же самое, что “ресурсная полнота”, т.е. возможность доступа ко всем ресурсам системы с использованием внутренних средств языка. Система, даже будучи вычислительно полной, может быть не способна к полной поддержке приложения. Тем не менее, такая система является более мощной, чем система баз данных, которая обеспечивает только хранение и извлечение данных и выполняет простые вычисления с атомарными значениями. Легко заметить, что здесь опять под “плохой” системой понимается SQL -ориентированная СУБД. И последнее утверждение является не вполне справедливым, поскольку уже в SQL /89 обеспечивалась возможность встраивания операторов SQL в вычислительно полные императивные языки, т.е. на основе SQL и некоторого традиционного языка программирования можно было написать законченное приложение.
Расширяемость
Система баз данных поставляется с набором предопределенных типов. Эти типы могут при желании использоваться программистами для написания приложений. Набор предопределенных типов должен быть расширяемым в том смысле, что должны иметься средства для определения новых типов и не должно быть различий в использовании системных и определенных пользователем типов. Конечно, способы поддержания системой системных и пользовательских типов могут значительно различаться, но эти различия должны быть невидимыми для приложения и прикладного программиста. Напомним, что определение типов включает определение операций этих типов. Заметим, что требование инкапсуляции подразумевает наличие механизма для определения новых типов. Требование расширяемости усиливает эту возможность, указывая, что вновь созданные типы должны иметь тот же статус, что и существующие. Однако не требуется, чтобы расширяемой была и совокупность конструкторов типов (кортежей, множеств, списков и т. д.).
Стабильность
Это требование очевидно с точки зрения баз данных, но является новым с точки зрения языков программирования. Стабильность (persistence )9 означает возможность программиста обеспечить сохранность данных после завершения выполнения процесса с целью последующего использования в другом процессе. Свойство стабильности должно быть ортогональным к другим свойствам, т.е. для каждого объекта вне зависимости от его типа должна иметься возможность сделать его стабильным (без какой-либо явной переделки объекта). Стабильность должна быть неявной: пользователь не должен явно перемещать или копировать данные, чтобы сделать их стабильными.
Управление вторичной памятью
Управление вторичной памятью является классической чертой систем управления базами данных. Эта возможность обычно поддерживается с помощью набора механизмов. Среди них управление индексами, кластеризация данных, буферизация данных, выбор пути доступа и оптимизация запросов.
Ни один из этих механизмов не является видимым для пользователя – это просто средства повышения производительности системы. Однако эти средства настолько важны с точки зрения эффективности, что при их отсутствии система не сможет выполнять некоторые задачи (просто потому, что их выполнение будет занимать слишком много времени). Особо важна невидимость таких средств. Прикладной программист не должен писать программы для сопровождения индексов, распределять память на диске или перемещать данные между диском и основной памятью. Должна обеспечиваться четкая независимость между логическим и физическим уровнями системы.
Параллелизм
Что касается управления параллельным10 взаимодействием с системой нескольких пользователей, то должны обеспечиваться услуги того же уровня, который предоставляют современные системы баз данных. Система должна обеспечивать гармоническое сосуществование пользователей, одновременно работающих с базой данных. Поэтому должно поддерживаться стандартное понятие атомарности последовательности операций и управляемого совместного доступа. По крайней мере, должна обеспечиваться сериализуемость операций, хотя могут быть и менее жесткие альтернативы.
Восстановление
И в этом случае система должна обеспечивать услуги того же уровня, который предоставляют современные системы баз данных. Другими словами, в случае аппаратных или программных сбоев система должна восстанавливаться, т. е. возвращаться к некоторому согласованному состоянию данных. Аппаратные сбои включают как сбои в работе процессора, так и сбои дисков.
Средства обеспечения незапланированных запросов
Основной проблемой является обеспечение функциональности языка незапланированных (ad hoc ) запросов. Авторы Первого манифеста не призывают к тому, чтобы эта функциональность обязательно была реализована в виде языка запросов, а требуют только, чтобы была такая услуга существовала. Например, для обеспечения этой функциональной возможности вполне достаточно наличие графической программы просмотра. Услуга состоит в том, что пользователь может без затруднений сделать простой запрос к базе данных.11 Очевидной мерой являются, конечно, реляционные системы. Поэтому проверка наличия средства незапланированных запросов состоит в том, чтобы взять на пробу несколько реляционных запросов и проверить, можно ли их сформулировать с теми же затратами труда. Заметим, что это средство могло бы поддерживаться языком манипулирования данными или его подмножеством.
Средство обеспечения запросов должно удовлетворять следующим трем критериям:
Оно должно быть средством высокого уровня, т. е., пользователь должен иметь возможность кратко выразить нетривиальные запросы. Для этого средство формулирования должно быть достаточно декларативным, т. е., упор должен быть сделан на “что”, а не на “как”.
Оно должно быть эффективным. Для этого формулировка запросов должна допускать возможность оптимизации запросов.
Средство запросов не должно зависеть от приложения, т. е. оно должно работать с любой возможной базой данных. Это последнее требование устраняет потребность в специфических средствах обеспечения запросов для конкретных приложений и необходимость написания дополнительных операций для каждого определенного пользователем типа.
В 1991 г. был образован консорциум ODMG (тогда эта аббревиатура раскрывалась как Object Database Management Group , но впоследствии приобрела более широкую трактовку – Object Data Management Group ). Консорциум ODMG тесно связан с гораздо более многочисленным консорциумом OMG (Object Management Group ), который был образован двумя годами раньше. Основной исходной целью ODMG была выработка промышленного стандарта объектно-ориентированных баз данных (общей модели). За основу была принята базовая объектная модель OMG COM (Core Object Model ). В течение более чем десятилетнего существования ODMG опубликовала три базовых версии стандарта, последняя из которых называется ODMG 3.0
Архитектура ODMG
Предлагаемая ODMG архитектура показана на рис. 2.1. В этой архитектуре определяются способ хранения данных и разные виды пользовательского доступа к этому “хранилищу данных”17. Единое хранилище данных доступно из языка определения данных, языка запросов и ряда языков манипулирования данными.18 На рис. 2.1 ODL означает Object Definition Language (язык определения объектов), OQL – Object Query Language (язык объектных запросов) и OML – Object Manipulation Language (язык манипулирования объектами).
Рис. 2. Архитектура ODMG
Центральной в архитектуре является модель данных, представляющая организационную структуру, в которой сохраняются все данные, управляемые ООСУБД. Язык определения объектов, язык запросов и языки манипулирования разработаны таким образом, что все их возможности опираются на модель данных. Архитектура допускает существование разнообразных реализационных структур для хранения моделируемых данных, но важным требованием является то, что все программные библиотеки и все поддерживающие инструментальные средства обеспечиваются в объектно-ориентированных рамках и должны сохраняться в согласовании с данными.
Основными компонентами архитектуры являются следующие.
1. Объектная модель данных. Все данные, сохраняемые ООСУБД, структуризуются в терминах конструкций модели данных. В модели данных определяется точная семантика всех понятий (более подробно см. ниже).
2. Язык определения данных (ODL). Схемы баз данных описываются в терминах языка ODL , в котором конструкции модели данных конкретизируются в форме языка определения. ODL позволяет описывать схему в виде набора интерфейсов объектных типов, что включает описание свойств типов и взаимосвязей между ними, а также имен операций и их параметров. ODL не является полным языком программирования; реализация типов должна быть выполнена на одном из языков категории OML . Кроме того, ODL является виртуальным языком в том смысле, что в стандарте ODMG не требуется его реализация в программных продуктах ООСУБД, которые считаются соответствующими стандарту. Допускается поддержка этими продуктами эквивалентных языков определения, включающих все возможности ODL , но адаптированных под особенности конкретной системы. Тем не менее, наличие спецификации языка ODL в стандарте ODMG является важным, поскольку в языке конкретизируются свойства модели данных.
3. Язык объектных запросов (ODL ). Язык имеет синтаксис, похожий на синтаксис языка SQL, но опирается на семантику объектной модели ODMG . В стандарте допускается прямое использование OQL и его встраивание в один из языков категории OML .
4. Языки манипулирования объектами (OML). Для программирования реализаций операций и приложений требуется наличия объектно-ориентированного языка программирования. OML представляется собой интегрирование языка программирования с моделью ODMG; это интегрирование производится за счет определенных в стандарте правил языкового связывания (language binding ). Дело в том, что в самих языках программирования, естественно, не поддерживается стабильность объектов. Чтобы разрешить программам на этих языках обращаться к хранимым данным, языки должны быть расширены дополнительными конструкциями или библиотечными элементами. Эту возможность и обеспечивает языковое связывание.
В одной ООСУБД могут поддерживаться несколько OML . В стандарте ODMG -2 были специфицированы правила связывания для языков C ++ и Smalltalk 19. Практически завершена работа над спецификаций правил связывания для языка Java.
5. Постоянное хранилище объектов. Логическая организация хранилища данных любой ООСУБД, совместимой со стандартном ODMG , должна основываться на модели данных ODMG . Физическая организация у разных ООСУБД может различаться, но в любом случае она должна обеспечивать эффективные структуры данных для хранения иерархии типов и объектов, являющихся экземплярами этих типов. Иерархия типов связана не только с данными, но и с различными библиотеками и компонентами инструментальных средств, поддерживающими разработку приложений. Так что в ООСУБД, совместимой со стандартом ODMG , хранилище представляет собой интегрированную систему, где согласованным образом сохраняются данные и программный код.
6. Инструментальные средства и библиотеки. Инструментальные средства, поддерживающие, например, разработку пользовательских приложений и их графических интерфейсов, программируются на одном из OML и сохраняются как часть иерархии классов. Библиотеки функций доступа, арифметических функций и т.д. также сохраняются в иерархии типов и являются единообразно доступными из программного кода разработчика приложения. Ассортимент инструментальных средств и библиотек в стандарте не определяется.
Связи
В большинстве объектных систем связи неявно моделируются как свойства, значениями которых являются объекты. Например, если человек работает на некоторую компанию, то у каждого объекта-человека должно иметься свойство, которое можно назвать worksFor и значением которого является соответствующий объект-компания. Возникает проблема, если у объекта-компании имеется свойство, которое затрагивает множество служащих этой компании (например, employees – множество, включающее все объекты служащих данной компании). Эти два свойства являются несвязными, и поддержка их согласованности может вызывать значительную программистскую проблему.
В модели ODMG , подобно ER -модели, различаются два вида свойств – атрибуты и связи, хотя и несколько другим образом. Атрибутами называются свойства объекта, значение которых можно получить по OID объекта, но не наоборот. Значениями атрибутов могут быть и литералы, и объекты, но только тогда, когда не требуется обратная ссылка. Связи – это инверсные свойства. В этом случае значением свойства может быть только объект, поскольку литеральные значения не обладают свойствами. Поэтому возраст служащего обычно моделируется как атрибут, а компания, в которой работает служащий, – как связь.
При определении связи должна быть определена ее инверсия. В приведенном выше примере, если worksFor определяется как связь, должно быть явно указано, что инверсией является свойство employees объекта-компании, а при определении employees должна быть указана инверсия worksFor . После этого система баз данных должна поддерживать согласованность связанных данных, что позволяет сократить объем работы программистов приложений и повысить надежность их программ. Если в объекте-компании свойство employees не требуется, то свойство объекта-служащего employees может быть атрибутом.
Объектные и литеральные типы
В модели ODMG база данных представляет собой коллекцию различимых значений (denotable values ) двух видов – объекты и литералы. Объекты обладают свойствами идентифицируемости и индивидуального существования, а литералы являются компонентами объектов. Модель данных содержит конструкции для спецификации объектных и литеральных типов. Объектные типы существуют в иерархии объектных типов; литеральные типы похожи на типы, характерные для обычных языков программирования (например, С или Pascal ). В модели ODMG не используется термин класс. Единственная классификационная конструкция называется типом, и типы описывают как объекты, так и литералы. То, что называлось классом в Первом манифесте, в ODMG называется объектным типом.
В модели поддерживается ряд литеральных типов – базовые скалярные числовые типы, символьные и булевские типы (атомарные литералы), конструируемые типы литеральных записей (структур) и коллекций. Конструируемые литеральные типы могут основываться на любом литеральном или объектном типе, но считаются неизменчивыми. Даты и время строятся как литеральные структуры. Подробнее о литеральных типах см. в следующем подразделе.
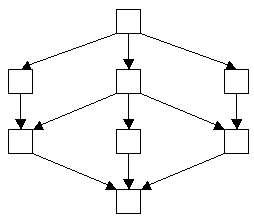
Объектный тип состоит из интерфейса и одной или нескольких реализаций. Интерфейс описывает внешний вид типа: какими свойствами он обладает, какие в нем доступны операции и каковы параметры у этих операций. В реализации определяются структуры данных, реализующие свойства, и программный код, реализующий операции. Интерфейс составляет общедоступную (public ) часть типа, а в реализации при необходимости могут вводиться дополнительные частные (private ) свойства и операции. Все объектные типы (системные или определяемые пользователем) образуют решетку (lattice ) типов, в корне которой находится предопределенный объектный тип Object . Чтобы не объяснять подробно, что такое решетка, приведем пример графа, являющегося решеткой (рис. 3.)
Рис. 3. Пример ориентированного графа, являющегося решеткой
Поскольку для определения реализации объектного типа требуется использовать один из языков OML , которые мы в этой статье не обсуждаем, ограничимся рассмотрением интерфейсной части типа. Интерфейс объектного типа состоит их следующих компонентов:
· имя;
· набор супертипов;
· имя поддерживаемого системой экстента;
· один или более ключей для ассоциативного доступа;
· набор атрибутов,каждый из которых может быть объектом или литеральным значением;
· набор связей, каждая из которых указывает на некоторый другой объект;
· набор операций.
Атрибуты и связи совместно называются свойствами, а свойства и операции совместно называются характеристиками объектного типа (или объектов данного типа).
Точно так же, как имеются атомарные и конструируемые литеральные типы, существуют атомарные и конструируемые объектные типы. В стандарте ODMG 3.0 говорится, что атомарными объектными типа являются только типы, определяемые пользователями. Конструируемые объектные типы включают структурные типы и набор типов коллекций.
Второй манифест
Через год после публикации Манифеста систем объектно-ориентированных баз данных вышел в свет Манифест систем баз данных следующего поколения. В Манифесте отразились идеи главным образом одного из авторов Стоунбрейкера, использованные им в проектах Ingres и Postgres.
В некотором роде Второй манифест стал ответом миру объектно-ориентированных баз данных со стороны мира SQL -ориентированных баз данных. Если Первый манифест носил хотя и немного путанный, но все-таки научный характер, то Второй манифест является в большей степени инженерно-публицистическим документом. В некотором роде это реакция индустрии СУБД на неприятные для нее измышления из мира науки.