Широкие возможности представляет стандарт МРЕG-4 для кодирования звука. Впервые используются раздельные алгоритмы для кодирования звуков музыкального происхождения и речи, введены мощные средства создания и обработки синтезированного звука.
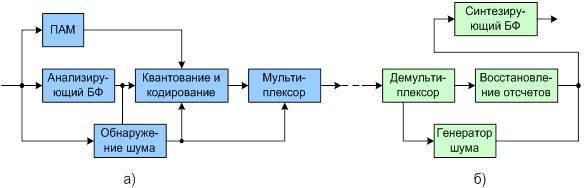
Наиболее широкий круг звуковых объектов, от низкоскоростных моно до многоканального звука вещательного качества, относится к категории Универсального звука (GA). В качестве основного алгоритма кодирования звуков различного происхождения принят известный из МРЕG-2 алгоритм ААС с незначительными усовершенствованиями. Одно из них касается введения режима PNS (перцептуальное замещение шумом). Суть данного метода заключается в обнаружении в приходящем сигнале шумоподобных составляющих и исключении их из общего процесса кодирования. Декодеру передается информация о мощности шумовых компонентов в отдельных участках спектра, и он подменяет соответствующие спектральные коэффициенты псевдослучайными сигналами с требуемой мощностью. Режим PNS иллюстрируется структурной схемой (рис. 5.1).
Рисунок 5.1 Схема реализации режима PNS: а) кодер; б) декодер
Еще одно усовершенствование связано с введением алгоритма ВSАС (арифметическое кодирование с побитовым расщеплением). Чтобы получить масштабируемый поток, ВSАС использует альтернативный по отношению к ААС модуль кодирования квантованных коэффициентов с точным управлением скоростью потока в пределах от 16 до 64 кбит/с с шагом 1 кбит/с.
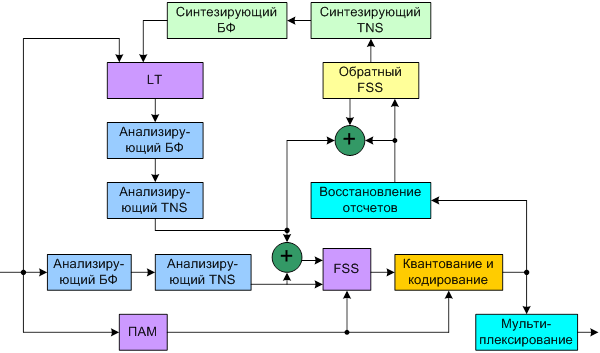
Существенный выигрыш в скорости потока для стационарных гармонических и квазигармонических сигналов позволяет получить метод долговременного предсказания LТР. В технике кодирования речи этот метод широко используется во временной области. В стандарте МРЕG-4 он интегрирован в схему универсального кодера (рис. 5.2), где операции квантования и кодирования осуществляются над спектральными представлениями входного сигнала.
Рисунок 5.2 Схема универсального кодера с LТР
Для работы схемы LТР кодированный сигнал предыдущего кадра переводится обратно во временную область с помощью инверсного преобразования TNS и синтезирующего БФ, в блоке LТР он сравнивается с приходящим сигналом, а полученная разность опять переводится в спектральную область. Специальный переключатель FSS (переключатель с частотной избирательностью) выбирает исходный или разностный сигнал в зависимости от того, какая альтернатива в данный момент предпочтительнее. По сравнению с предсказанием из МРЕG-2 ААС данный метод предсказания требует вдвое меньших ресурсов памяти и производительности процессора.
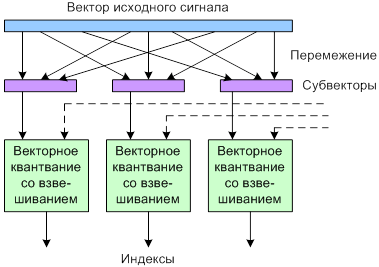
Для увеличения эффективности кодирования музыкальных сигналов на низких скоростях разработан новый алгоритм Twin VQ (взвешивающее векторное квантование с перемежением и преобразованием областей). Основная идея - заменить обычное кодирование спектральных компонентов в ААС перемежающим векторным квантованием, приложенным к нормализованному спектру. Квантование спектральных коэффициентов осуществляется в два шага: на первом они нормализуются к некоторому пределу, на втором - квантуются с использованием векторного квантования. Процесс нормализации включает оценку спектра по шкале Барка, извлечение периодических компонентов и оценку мощности спектральных составляющих. В результате нормализации спектральные коэффициенты выравниваются и нормализуются вдоль частотной оси. Затем нормализованные коэффициенты описываются как многомерный вектор, чередуются в субвекторы, как показано на рис. 5.3, и квантуются с использованием векторного квантования. Остальная часть алгоритма ААС остается неизменной.
Тwin VQ дает хорошие результаты в области скоростей от 6 до 24 кбит/с и используется в основном в универсальных кодеках МРЕG-4 с масштабированием для формирования базового слоя.