Def.Статистическая гипотеза – некое суждение о свойствах случайной величины. Проверка статистической гипотезы – процедура сопоставления выбранной гипотезы с имеющимися экспериментальными данными, сопровождаемая количественной оценкой степени достоверности полученного вывода.
Пример 4.1. Согласно паспортным данным автомобильного двигателя, расход топлива на 100 км должен составить 10 л. Испытано 25 машин. Средний расход топлива составил = 9.3 л. Известно, что расход топлива – СВ Х с известной дисперсией s2 = 4 л2. Проверить гипотезу: mx = 10 л.
Обозначим Н0 – выдвигаемая гипотеза. Идея проверки состоит в вычислении по результатам эксперимента некоторой статистики К = К(Х1, …, ХN) – статистического критерия, обладающего следующим свойством: если гипотеза Н0 верна, то случайная величина К имеет строго определенный закон распределения. Чтобы проверить, справедлив ли в действительности этот закон, вся область V значений критерия разбивается на две части: VКР – критическая область (область отклонения гипотезы) и V \VКР – область принятия гипотезы. Если в результате эксперимента событие (K Î VКР) не выполнится, то гипотезу следует принять. В противном случае ее надо отвергнуть Для построения критической области введем понятия ошибок I и II рода.
Def.Ошибка I рода состоит в отклонении верной гипотезы. Ошибка II рода состоит в принятии неверной гипотезы.
Чтобы понять разницу между этими понятиями – обратимся к примеру.
Пример. Система ПВО засекла летящий самолет. Гипотеза Н0 – самолет вражеский. В данном примере ошибка I рода состоит в том, что при верной гипотезе она была отвергнута, и вражеский самолет пропустили на свою территорию. Ошибка II рода – гипотеза была неверна, но ее приняли, в результате чего был сбит свой самолет. Приведенный пример, в частности демонстрирует, что, как правило, цена ошибок I и II рода различна.
В принятых обозначениях PI = P(KÎVКР / Н0) = a – вероятность ошибки I рода; PII = P(KÎV \VКР / Ø Н0) = b – вероятность ошибки II рода. (Символ Ø Н0 означает, что Ø Н0 не верна, наклонная черта / означает «при условии», а всё выражение (KÎV \VКР / Ø Н0) читается так: К принадлежит области V \VКР при условии, что Н0 не верна.
Принцип выбора VКР: при заданном уровне PI = a вероятность ошибки II рода должна быть минимальна (b ® min или 1– b® mах).
Величина a называется уровнем значимости, она равна максимально допустимому значению вероятности ошибки I рода. В технических задачах обычно полагают a = 0,05. Величина 1 – a называется доверительной вероятностью.
Законы распределения статистических критериев могут быть различны. В настоящее время для всех употребляемых законов разработаны специальные методы построения критических областей. Их границы определяются по статистическим таблицам, а при использовании программ статистического моделирования применяются встроенные функции. Например, если критерий распределён нормально, то в Excel используется функция НОРМОБР(р; а; s), где р – заданная доверительная вероятность, а и s – параметры нормального распределения (см. Примеры основных законов распределения непрерывных СВ).
Проверим гипотезу примера 4.1 при a = 0.05. В качестве статистического критерия примем . При нормальном распределении СВ Х с параметрами mx = 10, D[X] = s2 выбранный критерий К распределен нормально с параметрами mК = 0, D[K] = 1. Тогда критическая область имеет вид:
Расчетное значение критерия КВЫЧ при = 9.3 л составит КВЫЧ = – 1.75 , т.е. попадает в критическую область (– ¥, – 1.645). Следовательно, основная гипотеза должна быть отвергнута.
Резюме: технология проверки статистических гипотез
1. Проводится серия экспериментов для получения статистического материала.
2. По полученным данным выдвигается статистическая гипотеза.
3. Задаётся уровень значимости a, определяется тип выдвинутой гипотезы и соответствующий статистический критерий К. По виду гипотезы и значению a определяется критическая область VКР.
4. По экспериментальным данным вычисляется значение КВЫЧ.
5. Если КВЫЧ попадает в VКР, то основная гипотеза отвергается, в противном случае – принимается.

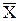 = 9.3 л. Известно, что расход топлива – СВ Х с известной дисперсией s2 = 4 л2. Проверить гипотезу: mx = 10 л.
= 9.3 л. Известно, что расход топлива – СВ Х с известной дисперсией s2 = 4 л2. Проверить гипотезу: mx = 10 л.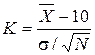 . При нормальном распределении СВ Х с параметрами mx = 10, D[X] = s2 выбранный критерий К распределен нормально с параметрами mК = 0, D[K] = 1. Тогда критическая область имеет вид:
. При нормальном распределении СВ Х с параметрами mx = 10, D[X] = s2 выбранный критерий К распределен нормально с параметрами mК = 0, D[K] = 1. Тогда критическая область имеет вид: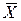 = 9.3 л составит КВЫЧ = – 1.75 , т.е. попадает в критическую область (– ¥, – 1.645). Следовательно, основная гипотеза должна быть отвергнута.
= 9.3 л составит КВЫЧ = – 1.75 , т.е. попадает в критическую область (– ¥, – 1.645). Следовательно, основная гипотеза должна быть отвергнута.