|

|
ПаскальСиАссемблерJavaMatlabPhpHtmlJavaScriptCSSC#DelphiТурбо Пролог1С Компьютерные сетиСистемное программное обеспечениеИнформационные технологииПрограммирование Linux Unix Алгоритмические языки Аналоговые и гибридные вычислительные устройства Архитектура микроконтроллеров Введение в разработку распределенных информационных систем Введение в численные методы Дискретная математика Информационное обслуживание пользователей Информация и моделирование в управлении производством Компьютерная графика Математическое и компьютерное моделирование Моделирование Нейрокомпьютеры Проектирование программ диагностики компьютерных систем и сетей Проектирование системных программ Системы счисления Теория статистики Теория оптимизации Уроки AutoCAD 3D Уроки базы данных Access Уроки Orcad Цифровые автоматы Шпаргалки по компьютеру Шпаргалки по программированию Экспертные системы Элементы теории информации |
Приближенное уравнение линейной регрессииДата добавления: 2013-12-24; просмотров: 1587; Нарушение авторских прав
|
Уроки php mysql Программирование Онлайн система счисления Калькулятор онлайн обычный Инженерный калькулятор онлайн Замена русских букв на английские для вебмастеров Замена русских букв на английские
Аппаратное и программное обеспечение
Графика и компьютерная сфера
Интегрированная геоинформационная система
Интернет
Компьютер
Комплектующие компьютера
Лекции
Методы и средства измерений неэлектрических величин
Обслуживание компьютерных и периферийных устройств
Операционные системы
Параллельное программирование
Проектирование электронных средств
Периферийные устройства
Полезные ресурсы для программистов
Программы для программистов
Статьи для программистов
Cтруктура и организация данных
| ||||||||||||||||||||||||
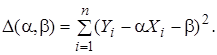 (1)
(1)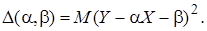 (2)
(2)
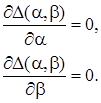 (3)
(3)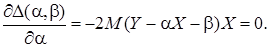 (4)
(4)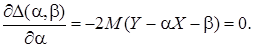 (5)
(5)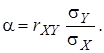
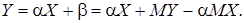
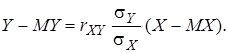 (6)
(6)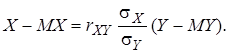 (7)
(7)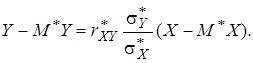 (8)
(8)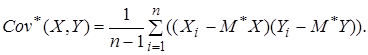
|
Не нашли то, что искали? Google вам в помощь! |
© life-prog.ru При использовании материалов прямая ссылка на сайт обязательна. |
|