Следует понимать, что клиенты и серверы СУБД — это программы, а не машины, на которых они выполняются. Помимо сервера базы данных, на машине может выполняться множество других программ, как серверов, так и клиентов. Сервер представляет собой сложную ресурсоемкую программу, поэтому для него часто выделяют отдельную машину, которую тоже называют сервером. Здесь и далее под сервером мы будем понимать программную часть, а не аппаратную.
О клиентах и серверах____________________________________
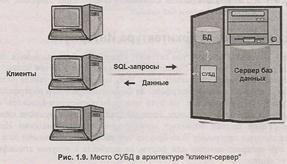
В связи с тем, что очень часто возникает путаница, что называть клиентом, а что сервером, остановимся на этом вопросе подробнее. Попросту говоря, клиенты — это те, кто обращается (посылают запросы), а сервер — это тот, кто отвечает на эти запросы. Сервер постоянно прослушивает, не поступили ли запросы от клиентов, и если поступили — отвечает на эти запросы. Для прослушивания предназначены один или несколько портов, к которым и обращаются клиентские приложения. Жизненным примером такой организации может служить система "продавец—очередь из покупателей". Продавец за прилавком в данном случае является сервером, обслуживающим покупателей-клиентов. Точно так же, как и компьютер-сервер, продавец-сервер для того, чтобы обслужить покупателя-клиента, должен получить от него запрос, к примеру "Взвесьте мне килограмм яблок". Нужно также понимать, что сервер может одновременно и сам быть клиентом. В том случае, если он тоже обращается к другому серверу с каким-либо запросом. В этом случае наш первоначальный сервер по отношению к этому "другому серверу" уже будет клиентом, оставаясь при этом сервером для тех клиентов, которых он обслуживает. Продолжая аналогию с продавцами и покупателями, продавец-сервер тоже может стать клиентом. Например, когда сам пойдет в магазин и встанет в очередь за каким-то товаром, т. е. станет покупателем-клиентом.
Два признака клиент-серверной архитектуры
Во-первых, это то, что приложения и СУБД выполняются на разных компьютерах. Этим признаком клиент-серверная архитектура отличается от централизованной архитектуры. А во-вторых, это то, что клиент и сервер находятся в одной локальной сети. Это достаточно важный признак, о котором часто забывают. Между тем, в том числе и по этому признаку клиент-серверная архитектура отличается от трехуровневой архитектуры Интернета, которая рассмотрена ниже и в которой клиенты и серверы объединены не в локальной, а уже в глобальной сети.
Таким образом, в архитектуре "клиент-сервер" функции работы с пользователем, такие как обработка ввода и отображение данных, выполняются на персональном компьютере (клиенте), а функции работы с данными (выполнение запросов, дисковый ввод-вывод) выполняются сервером баз данных.
Трехуровневая архитектура Интернета
С развитием Интернета архитектура сетевого управления базами данных получила дальнейшее развитие. Ранний Интернет обеспечивал доступ к базам данных напрямую. Через некоторое время появилась среда Web, которая предоставила пользователям Интернета дружественный интерфейс. За формирование этого интерфейса несет ответственность Web-сервер, т. е. на пути между пользователем-клиентом и базой данных появился еще один посредник, который стал выполнять функции клиентской программы. Такой подход позволяет многочисленным пользователям Интернета иметь единственную программу Web-браузер для работы с различными базами данных, будь это Интернет-магазин или форум, не прибегая к услугам специфических программ-клиентов.
Замечание________________________________________
Клиенты-браузеры, в терминологии баз данных, часто называют "тонкими клиентами". В противовес "толстым клиентам", которые ориентированы на конкретную базу данных, тонкие клиенты способны лишь отображать данные в строго определенном формате и отправлять серверу лишь простейшие запросы. ICQ, WebMoney представляют примеры "толстых клиентов", a Internet Explorer, Opera, WAP-браузер сотового телефона являются "тонкими клиентами".
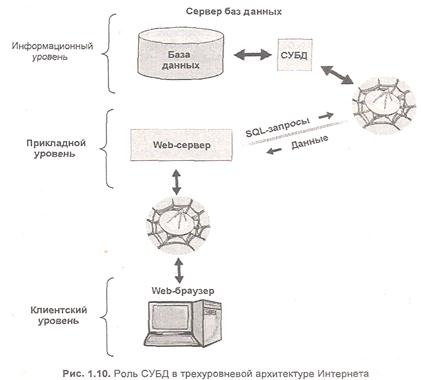
Схема работы трехуровневой архитектуры следующая. Допустим, клиенты какой-либо компании, находясь за тысячи километров от нее, желают ознакомиться со списком товаров, доступных на данный момент. В этом случае они используют браузер для посещения сайта этой компании. Страницу со списком товаров при этом формирует специальный модуль — скрипт, выполняющийся на Web-сервере компании. Для получения нужной информации этот скрипт обращается (посылает SQL-запросы) к СУБД, находящейся на сервере баз данных. Иллюстративно такая схема взаимодействия изображена на рис. 1.10.
Таким образом, в трехуровневой архитектуре Интернета интерфейсом пользователя является Web-браузер или другой "тонкий клиент". Это — клиентский уровень. Браузер взаимодействует с Web-сервером, посылая ему запросы на отображение той или иной Web-страницы. Уровень Web-сервера — прикладной уровень. Web-приложение, выполняющееся на Web-сервере, формирует SQL-запрос к СУБД, которая в свою очередь возвращает необходимые данные из базы данных. СУБД и база данных при этом размещены на сервере баз данных и представляют собой третий, информационный уровень трехуровневой архитектуры Интернета.
Как работают базы данных и что такое SQL
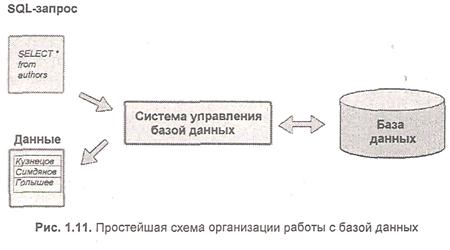
Рассмотрим упрощенную схему работы пользователя с базой данных, показанную на рис. 1.11. Согласно этой схеме, в системе имеется база данных, в которой хранится некоторая информация, допустим, информация о работниках. По сути, база данных — это те же файлы, в которых хранится информация. Сами по себе базы данных не представляли бы никакого интереса, если бы не было систем управления базами данных, сокращенно — СУБД. СУБД — это программный комплекс, который управляет базой данных, т. е. берет на себя все низкоуровневые операции по работе с файлами, благодаря чему программисту при работе с базой данных нужно оперировать лишь логическими понятиями при помощи языка программирования, предназначенного для организации взаимодействия пользователя с базой данных.
Итак, еще раз уточним понятия. База данных— это просто файловое хранилище информации, и не более. А программные продукты типа MySQL, Oracle, Dbase, Informix, PostgreSQL и др. — это системы управления базами данных. Ведь по сути базы данных везде одинаковы — это файлы с записанной в них информацией. Все вышеприведенные программные продукты отличаются друг от друга именно способом организации работы с файловой системой. Однако для краткости эти СУБД часто называют просто базами данных. Так будем поступать и мы. Следует помнить, что когда мы будем говорить "база данных" — речь идет именно о СУБД.
Язык программирования, с помощью которого пользователь общается с СУБД (или, как говорят, "осуществляет запросы к базе данных"), называется SQL (Structured Query Language, структурированный язык запросов).
После публикации исследований Кодда компанией IBM был инициирован проект System/R по созданию первой реляционной базы данных, результатом которого стало создание минимального прототипа реляционной СУБД. Кроме разработки самой СУБД, проводилась работа над созданием языков запроса к базе данных. Один из этих языков был назван SEQUEL (Structured English Query Language, структурированный английский язык запросов). Позже по юридическим соображениям язык был переименован в SQL.
Таким образом, для того чтобы получить какую-либо информацию из базы данных, необходимо направить базе данных запрос, созданный с использованием SQL, результатом выполнения которого будет таблица с данными (см. рис. 1.11).
Несмотря на то, что SQL называется "языком запросов", в настоящее время этот язык представляет собой нечто большее, чем просто инструмент для создания запросов. Ведь запрос это, по сути, предложение вида "Выбрать из таких-то таблиц такие то данные". К примеру, на рис. 1.11 показан запрос, суть которого состоит в выборке всех фамилий из таблицы работников. С помощью SQL осуществляется реализация всех возможностей, которые представляются пользователям разработчиками СУБД, а именно:
□ выборка данных (извлечение из базы данных содержащейся в ней информации);
□ организация данных (определение структуры базы данных и установление отношений между ее элементами);
□ обработка данных (добавление/изменение/удаление);
□ управление доступом (ограничение возможностей ряда пользователей на доступ к некоторым категориям данных, зашита данных от несанкционированного доступа);
□ обеспечение целостности данных (защита базы данных от разрушения);
□ управление состоянием СУБД.
SQL не является специализированным языком программирования, т. е. в отличие от языков высокого уровня (C++, Pascal и т. д.) с его помощью невозможно создать автономную программу. Все запросы выполняются либо в специализированных программах, либо из прикладных программ при помощи специальных библиотек.
Примечание_______________________________________
Несмотря на то, что SQL называют языком программирования баз данных, на самом деле это не совсем корректно, т. к. SQL работает только с базами данных определенного типа — реляционными базами данных. Однако не будет ошибкой сказать, что SQL на сегодняшний день это единственный язык программирования баз данных — по той причине, что реляционные базы данных фактически являются единственными типами баз данных, используемыми в настоящее время.
Несмотря на то, что язык запросов SQL строго стандартизирован, существует множество его диалектов, по сути, каждая база данных реализует свой собственный диалект со своими особенностями и ключевыми словами, недоступными в других базах данных. Такая ситуация связана с тем, что стандарты SQL появились достаточно поздно, в то время как компании-поставщики баз данных существуют давно и обслуживают большое число клиентов, для которых требуется обеспечить обратную совместимость со старыми версиями программного обеспечения. Кроме того, рынок реляционных баз данных оперирует сотнями миллиардов долларов в год, все компании находятся в жесткой конкуренции и постоянно совершенствуют свои продукты. Поэтому, когда дело доходит до принятия стандартов, базы данных уже имеют реализацию той или иной особенности, и комиссии по стандартам приходится в условиях жесткого давления выбирать в качестве стандарта решение одной из конкурирующих фирм. Так, хранимые процедуры, впервые появившиеся в MySQL 5 и чуть ранее в стандарте SQL, до недавнего времени были расширением SQL в языке запросов Transact-SQL базы данных MS SQL.
СУБД MySQL является развитием СУБД mySQL, которую разработчики шведской компании MySQL AB взяли за основу при создании своей собственной базы данных. Далее перечислены достоинства СУБД MySQL.
□ Скорость выполнения запросов. Наряду с Oracle, MySQL считается одной из самых быстрых СУБД в мире.
□ СУБД MySQL разработана с использованием языков C/C++ и оттестирована более чем на 23 платформах, среди которых Windows, Linux, FreeBSD, HP-UX, Mac OS X, OS/2, Solaris и др.
□ Открытый код, который доступен для просмотра и модернизации всем желающим. Лицензия GPL (General Public License, общедоступная лицензия) позволяет постоянно улучшать программный продукт и быстро находить и устранять уязвимые места. Особенностью лицензии GPL является тот факт, что любой код, скомпилированный с GPL-кодом, попадает под GPL-лицензию, т. е. может свободно распространяться, и условием его распространения является предоставление исходных кодов. MySQL AB придерживается двойного лицензирования, позволяя пользователям бесплатно использовать СУБД MySQL под GPL-лицензией, а также предоставляет MySQL под коммерческой лицензией тем, кому необходимо использовать его в коммерческих целях, например, в составе программы.
□ Высокое качество СУБД MySQL. Ни для кого не является секретом постоянно возрастающая сложность программных продуктов, что влечет за собой появление большого числа ошибок в конечных выпусках программного обеспечения. СУБД MySQL приятно удивит пользователей устойчивой работой.
□ СУБД MySQL поддерживает API (Application Programming Interface, программный интерфейс приложения) для С, C++, Eiffel, Java, Perl, PHP, Python, Ruby и Tel. MySQL можно успешно применять как для построения Web-страниц с использованием Perl, PHP и Java, так и для работы прикладной программы, созданной с использованием Builder C++ или платформы .NET.
□ Наличие встроенного сервера. СУБД MySQL может быть использована как с внешним сервером, поддерживающим соединение с локальной машиной и с удаленным хостом, так и в качестве встроенного сервера. Достаточно скомпилировать программу с библиотекой встроенного сервера, и приложение будет содержать в себе полноценную СУБД MySQL с возможностью создания баз данных, таблиц и осуществления запросов к ним.
□ Широкий выбор типов таблиц (типы таблиц описываются в главе 11), в том числе и сторонних разработчиков, что позволяет реализовать оптимальную для решаемой задачи производительность и функциональность. Кого-то привлечет наиболее быстрый тип таблиц MylSAM, а кому-то требуется поддержка объемов информации до 1 Тбайт с выполнением транзакций на уровне строк (таблицы типа InnoDB).
□ Локализация в MySQL выполнена корректно. У пользователя не возникнет проблем из-за того, что в конце проекта обнаружится невозможность поддержки базой данных сортировки русских строк.
□ MySQL, начиная с версии 5.0, практически полностью удовлетворяет стандарту SQL и, следовательно, хорошо совместима с другими базами данных.
Все эти особенности сделали MySQL стандартной базой данных, используемой на серверах хост-провайдеров и в качестве встроенной базы данных в прикладных программах.
На официальном сайте MySQL http://www.mysql.com поддерживается несколько версий СУБД MySQL, обычно это три версии. На момент написания данной книги это были следующие версии:
□ MySQL 4.0 — устаревшая версия СУБД;
□ MySQL 4.1 — стабильная (текущая) версия СУБД, рекомендуемая для загрузки;
□ MySQL 5.0 — версия, находящаяся в стадии бета-тестирования.
Замечание________________________________________
На компакт-диске, поставляемом вместе с данной книгой, можно найти дистрибутивы всех трех версий СУБД MySQL для операционных систем Windows и Linux.
По мере совершенствования MySQL 5.0 в ней будут устранены последние недочеты, и она будет объявлена стабильной. При этом поддержка MySQL 4.0 будет прекращена, MySQL 4.1 будет объявлена устаревшей (но все еще будет доступна для загрузки), а в разработку поступит следующая версия — MySQL 5.1, которая пройдет через стадии гамма-, дельта-, бета- и альфа-тестирования.
Что нового в MySQL 4.1
Версия MySQL 4.1 стала стабильной в начале 2005 года и по сравнению с предыдущими версиями характеризуется приведенными далее нововведениями.
□ Полная поддержка вложенных запросов. Данная тема рассматривается в главе 23.
□Увеличена производительность базы данных.
□ Введен целый набор дополнительных функций.
□ Изменен формат типа timestamp, а также введены дополнительные ключевые слова, которые позволяют управлять автоматическим обновлением времени при использовании операторов insert и update.
□ Введена новая система поддержки кодировок, теперь можно назначить кодировку по умолчанию, как таблице, так и отдельному столбцу в таблице.
□Введены новые типы таблиц, такие как EXAMPLE, NDB Cluster, ARCHIVE, CSV, которые подробно рассматриваются в главе 11.
Что нового в MySQL 5.0
Версия MySQL 5.0 является поворотной в линейке СУБД MySQL и содержит значимые нововведения, перечисленные далее.
□ Представления, которые рассматриваются в главе 30.
□Хранимые процедуры и функции, рассматриваемые в главе 28.