Для получения информации из отношений необходим язык манипулирования данными.
Наиболее важной частью ЯМД является раздел формулировки запросов, который должен обладать достаточной выразительностью. Разработано три типа ЯМД:
1) реляционная алгебра
2) реляционное исчисление с переменными кортежами
3) реляционное исчисление с переменными доменами.
По своей выразительности они эквивалентны. Реальные языки в отличие от теоретических реализуют помимо запросов другие операции: арифметические, операции печати и др.
Наиболее популярна реляционная алгебра. При определении операций предполагается, что порядок столбцов в отношении фиксирован, а сами отношения конечны.
Рассмотрим основные операции:
Объединение отношений R = R1 U R2
Применяется только к отношениям одной и той же –арности.
а б в
R1: д е а R2: и к л
и к л г д е
R1 ÈR2 : а б в
д е а
и к л
г д е
2. Разность отношений R = R1 -R2
Разностью R1 -R2 называется множество кортежей, принадлежащих R1,но не принадлежащих R2 . Одинаковой арности
R1 -R2 : а б в
д е а
3. Декартово произведение R = R1 * R2
Если отношение R1 имеет арность К1, а отношение R2 арность К2, то декартовым произведением R1*R2 является множество кортежей арности К1+К2, при чем первые К1 элементов образуют кортеж из отношения R1, а последние К2 элементов – кортеж из описания R2
а б в и к л
д е а и к л
и к л и к л
а б в г д е
д е а г д е
и к л г д е
4. Проекция отношения R1 на компонент i1, i2,..,ir R=Пi1,i2,…,ir (R1), где i1,i2,…,ir – номера столбцов отношения R1
Операция проекции заключается в том, что из отношения R1 выбираются столбцы с индексами i1, i2,..,ir и компонуются в указанном порядке
R=П1,2 (R1) а б R= П3,1 (R1) в а
д е а д
и к л и
5. Селекция отношения R1 по формуле F: R =σF(R1), где F – формула, образованная операндами, являющимися номерами столбцов, логическими операторами «И», «ИЛИ», «НЕ» и операциями сравнения < = > ≤ ≥ ≠. Могут использоваться скобки.
R = σ1=a v1=д(R1); R = σ2=к (R1);
а б в и к л
д е а R = σ1≠3 (R1)
а б в
д е а
и к л
Следующие операции реляционной алгебры можно получить с помощью основных, но они имеют самостоятельное значение
1. Пересечение: R= R1 ∩ R2 = R1 - (R1 - R2)
R1 и к а н R1 и к н а R1 ∩ R2: с а м д
с а м д с а м б о л р б
и к б в р к б в
о л р б о л р б
д в е н е д в и
2. Соединение отношений R1 >< R2, Ө - оператор сравнения, i, j – номера столбцов в отношениях R1 и R2.i ө j
В проведенных операциях можно обращаться к элементам кортежей по номерам столбцов и по их именам. Осуществляется преобразование имени в номер и обратно.
R1 А В С R2 Д Е R1 > < R2
а б в а и В=Д
а и р е к А В С Д Е
д е ж д е ж е к
Полученная система операций реляционной алгебры образует полный язык.
В общем случае ЯМД выходит за рамки абстрактных языков, так как включают операции удаления, добавления и модификации данных, а так же дополнительные операции: печать, вычисления, сравнения, агрегатные функции, применяемы к столбцам отношения.
Централизация и децентрализация процессов обработки данных.
Централизация процессов обработки данных позволила устранить такие недостатки, как несвязанность, противоречивость и избыточность данных в информационной системе, обеспечила возможность комплексно решать вопросы стандартизации в представлении данных, обеспечения санкционированного доступа и т.д.Однако по мере роста баз данных использование их в территориально разнесенных организациях привело к тому, что централизованная СУБД, находящаяся в узле телекоммуникационной сети, обеспечивающей доступ пользователей из территориально разнесенных пунктов к хранимым данным, стала плохо справляться с ростом числа обрабатываемых транзакций в связи с большим потоком обмена данными между терминалами и центральной ЭВМ. Такая ситуация привела к снижению надежности и общей производительности системы, при обработке запросов пользователей. Поэтому была предложена идея децентрализации процессов обработки данных в информационных системах для организаций, подразделения которых территориально разнесены. И хотя децентрализация данных затрудняет решение таких вопросов, как обеспечение целостности и непротиворечивости данных, их безопасности, тем не менее она позволяет повысить производительность обработки данных вследствие распределения нагрузки по нескольким узлам обработки, улучшить использование данных на местах и снизить затраты на их обработку.
Основным доводом в пользу распределения является тот факт, что данные используются в одном периферийном подразделении и редко или вообще никогда не используются в других в других подразделениях организации. Либо может оказаться, что частота обновления данных слишком высока и их выгоднее хранить и обрабатывать на местах возникновения, чем использовать централизованную обработку. Еще факт, говорящий в пользу распределения обработки – большое число операций поиска и манипулирования со вторичными ключами. Такие данные также лучше размещать в периферийной системе, и пользователи сами будут следить за их хранением и использованием. С другой стороны существует ряд факторов, естественным образом приводящих к необходимости централизации данных:
- данные используемые централизованными приложениями (например: снабжение или производств. управление)
- пользователям во всех подразделениях требуется одни и те же данные, причем они часто обновляются.
- система должна обрабатывать запросы, для которых данные, возникающие в различных подразделениях, логически рассматриваются как одно целое;
- большой объем общих данных;
- защита данных;
- пользователи определ. данных часто перемещаются с места на место; в этом случае может оказаться целесообразным централизовать данные.
В системе одни данные могут быть централизованными, а другие – децентрализованными. Поэтому основная задача, которую приходится решать при проектировании распределенной базы данных –это распределение данных по сети. Существуют след. способы решения этой задачи:
- в каждом узле сети хранится и используется собственная база данных, однако хранимые в ней данные доступны для других узлов сети;
- все данные распред. Б.Д. полностью дублируются в каждом узле сети;
- хранимые в центральном узле сети данные частично дублируется в тех периферийных узлах, в которых они интенсивно используются. Распределенная обработка данных помимо задачи распределения их по сети выдвигается ряд новых вопросов по сравнению с централизованной;
- распределенные БД м.б. однородными или неоднородными в смысле используемых в системе технических и программных средств (СУБД). Если используются разные СУБД, то д.б. решена проблема преобразования структур данных и прикладных программ, т.к. для пользователей д.б. обеспечена прозрачность этих преобразований.
- чтобы обеспечивать пользователю логическую прозрачность данных по всей базе, д.б. решен вопрос о создании единой концептуальной схемы для всей сети, при этом схема должна содержать информацию о местонахождении данных в сети, чтобы пользователь в запросе не указывал, в каком узле сети находится интересующие его данные;
- д.б. решен вопрос о декомпозиции запроса пользователя на отдельные подзапросы (сост. части), кот. могут пересылаться для выполнения в разные узлы сети в зависимости от места хранения данных и складывающейся на момент обработки запроса операционной остановки в сети (при этом д.б. обеспечена координация процесса обработки);
- д.б.решен вопрос о синхронизации процессов обновления и обработки копий данных;
- необходимо решить вопрос защиты данных и их восстановления;
- обеспечить управление словарями данных и т.д.
Например, архитектура однородных распределенных баз данных. Для описания информационной структуры всей сети вводится интерфейс концептуальной модели данных – глобальная сетевая концептуальная схема (сетевая метамодель данных).
Для обеспечения работы внешних пользователей вводится интерфейс внешней модели, который называется внешней схемой сети. Пользователи могут писать запросы, не интересуясь реальным распределением данных в сети.
В каждом узле сети имеется локальная общая схема (одна для каждого узла), содержащая описание локальных данных, хранимых в этом узле и описание данных, хранимых в других узлах, но используемых ПП и пользователями в данном узле.
Для реализации запроса его внешняя схема транслируется в общую схему сети (в кот. имеется информация о размещении требуемых данных в сети) и начинается его выполнение.
СУБД любого узла управляет данными этого узла и выполняет требуемые операции над ними. Поступивший запрос декомпозируется на составные операции (подзапрос), строится план перемещения и обработки подзапросов в сети, и начинается пересылка подзапросов в соответствующие локальные СУБД для выполнения. СУБД узла, выполнив подзапрос, результат выполнения выдает в сеть. После поступления ответов на все подзапросы формируется окончательный ответ.
Отношение R находится в третьей нормальной форме (3НФ), если оно находится во 2НФ и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
Атрибут, от которого другой атрибут зависит функционально, называется детерминантой.
Нормализованное отношение R находится в 3НФ, если каждая детерминанта является возможным ключом.
Рассмотрим другой пример.
Отношение СКП (студент, курс, преподаватель)
– каждый студент, изучающий данный предмет, обучается только одним преподавателем;
– каждый преподаватель преподает только один предмет;
– каждый предмет преподается нескольким преподавателям.
Из 1-го имеется функциональная зависимость (С, К) ® П
Из 2-го П ® К К ® П нет функциональной зависимости
СКП
С
К
П
Смит
Математика
проф. Вайт
Смит
Физика
проф. Грин
Джонс
Математика
проф. Вайт
Джонс
Физика
проф. Браун
Заменяем отношение СКП двумя проекциями в 3НФ СП и ПК.
Пример. Отношение ЭКЗАМЕН с атрибутами С(студент), К(предмет), М(место). Конкретный студент экзаменуется по определенному предмету и занимает определенное место.
– никакие два студента не могут занять одно и то же место по одному и тому же предмету. Имеем два возможных ключа (С,К) и (К,М). Ключи перекрываются. Отношение находится в 3НФ, т.к. ключи являются единственными детерминантами.
Пример отношения КПУ (курс, преподаватель, учебник)
Данному курсу может соответствовать любое число преподавателей и любое количество учебников. Преподаватели и учебники совершенно независимы.
КУРС
ПРЕПОДАВАТЕЛЬ
УЧЕБНИК
Физика
проф. Грин
Основы механики
Физика
проф. Грин
Законы оптики
Физика
проф. Браун
Основы механики
Физика
проф. Браун
Законы оптики
Ключ – весь кортеж. КПУ находится в 3НФ. Говорят, что атрибут КУРС «многозначно определяет» атрибут ПРЕПОДАВАТЕЛЬ, или существует «многозначная зависимость» ПРЕПОДАВАТЕЛЬ от КУРС. ПРЕПОДАВАТЕЛЬ не зависит функционально от КУРС, но каждый курс имеет хорошо определенное множество, соответствующих преподавателей. Множество значений ПРЕПОДАВАТЕЛЬ для заданной пары значений КУРС и УЧЕБНИК зависят только от конкретного значения КУРС, а значение УЧЕБНИК несущественно. Многозначные зависимости не являются функциональными зависимостями. Проекция КП и КУ не содержат таких зависимостей.
Некоторые отношения R(A, B, C), в котором B и C многозначно зависят от A, всегда эквивалентно соединению по А двух проекций R1(A, B) и R2(A, C).
Нормализованное отношение R находится в 4НФ тогда и только тогда, когда при существовании многозначной зависимости в R,скажем, атрибута B от атрибута A, все атрибуты R также функционально зависят от A.
Процесс сводится к устранению аномалий.
2НФ а) устраняем не полные функциональные зависимости
3НФ б) устраняем транзитивные зависимости
4НФ в) устраняем многозначные зависимости.
Традиционный набор операций
Для операций объединения, пересечения и вычитания оба участвующих отношения должны быть совместимы по объединению, т.е. они должны иметь одну и ту же степень n и j-й атрибут одного из них дожжен быть из того же домена, что и j-й атрибут другого (1 ≤ j ≤ n).
Объединением отношений A и B (A U B) называется множество всех кортежей t, принадлежащих или A, или B, или обоим вместе.
A – множество поставщиков, находящихся в Лондоне.
В – множество поставщиков, поставляющих деталь д1.
A U B – п1 Смит 20 Лондон
п4 Кларк 20 Лондон
п2 Джонсон 10 Париж
Пересечением отношений A и B (A ∩ B) называется множество всех кортежей t, принадлежащих как A, так и B.
A ∩ B – п1 Смит 20 Лондон
Разностью отношений (A-B) называется множество всех кортежей t, принадлежащих A, но не принадлежащих B.
A - B – п4 Кларк 20 Лондон
Расширенным декартовым произведением отношений A и B (A*B) является множество всех кортежей t, таких что t есть конкатенация кортежей aÎA, и кортежей bÎB.
a=(a1,…,am) b=(bm+1,…,bm+n)
t=(a1,…,am,bm+1,…,bm+n)
25. НОРМАЛИЗАЦИЯ ОТНОШЕНИЙ
При проектировании реляционных баз данных важно уметь группировать атрибуты в различные отношения.
Рациональные варианты группировки должны отвечать требованиям:
1) Выбранные в отношении первичные ключи должны содержать минимальное число элементов.
2) Выбранный состав отношений базы должен обладать минимальной избыточностью атрибутов.
3) Должны выполняться без аномалий операции включения, удаления и модификации данных в базе.
4) Должна быть минимальная перестройка набора отношений при введении новых типов данных.
5) Разброс времени ответа на различные запросы к базе данных должен быть небольшим.
Рассмотрим на примере аномалии при выполнении операций включения, удаления и модификации данных при нерациональном проекте базы данных.
Поставки (название поставки, адрес поставщика для любого товара, товар, количество, цена)
1) Аномалия модификации заключается в том, что если у поставщика изменяется адрес, то необходимо заменить это данное во всех кортежах, где оно есть.
Если по каким-то причинам это данное изменено не во всех кортежах, база данных становится противоречивой, нарушается целостность данных.
2) Аномалия удаления возникает при попытке удаления всех кортежей, в которых поставщик не поставляет ни одного типа товара. В базе может быть потерян адрес и название поставщика, даже если с ним в дальнейшем может быть заключен договор на поставку.
3) Аномалия включения – возникает в случае, когда с поставщиком только что заключили договор, но еще нет поставки, нельзя включить в базу.
Чтобы исключить аномалии, выполняется нормализация исходных схем отношений проекта БД путем их декомпозиции и назначения ключей для каждого отношения по определенным правилам нормализации.
В отношении ключи возможные и первичные. Если некоторый атрибут Аi входит в состав первичного ключа, он называется первичным (остальные атрибуты – непервичные).
Исчисление отношений
В реляционном исчислении главным средством описания новых отношений исходной структуры является символическое обозначение вида А(х1.y1, x2.y2, …..)В. Оно означает отношение с именем А, полученное в результате проекции кортежей, удовлетворяющих булевскому выражению В, на домены х.у, где хi - имя отношения (исходной структуры), yi – имя домена из этого отношения. Различают квантор существования $ и квантор всеобщности ".
Двоеточие : – «такой, что»
Пример: выражение
А (К.ФИО, К.зарплата) : К.цех = 3 зарплата __1500 задает таблицу (отношение) с именем А с двумя доменами из отношения К (кадры). Первый домен содержит фамилии, имена и отчества рабочих, второй – размер месячной заработной платы. В отношение А включаются только рабочие третьего цеха с размером зарплаты больше 1500 руб.
Вторая и третья нормальные формы.
Если в отношении какой-либо атрибут или группа атрибутов Х полностью определяют другой атрибут (или группу атрибутов) Y , то Y функционально зависит от Х. (" Х соответствует лишь одно значение Y). Атрибут (группа атрибутов) называется полно зависимыми от группы атрибутов Х, если Y функционально зависит только от всего множества Х, а не от какого-либо его собственного подмножества.
Атрибут или группа атрибутов, значение которых однозначно идентифицируют строку таблицы называется возможным ключом отношения.
Атрибут, входящий в состав какого-либо возможного ключа, называется основным (первичным).
Отношение задано во второй нормальной форме, если оно находится в первой нормальной форме и каждый атрибут, не являющийся основным, полно зависит от любого возможного (вообще говоря, составного) ключа в этом отношении.
Если любой такой ключ является простым ключом и Х не зависит функционально от Y или Y – от Z, имеет место неполная транзитивная зависимость Z от Х.
Преобразование 2НФ в третью форму (3НФ) состоит в расщеплении отношения R на два
a) СТАТ и ГОРОД не функционально полно зависят от первичного ключа
b) СТАТ и ГОРОД не являются взаимно независимыми.
Отношение ПЕРВОЕ содержит аномалии:
- включение (не можем включить поставщика, пока не поставляет детали. Нет поставщика n5 из Афин)
- удаление (с удалением кортежа о поставке удаляем информацию о поставщике)
- обновление (значение ГОРОД повторяется многократно).
Заменим отношение ПЕРВОЕ двумя отношениями: ВТОРОЕ и ПОСТАВКА
П #
СТАТ
ГОРОД
n1
Лондон
n2
Париж
n3
Париж
n4
Лондон
n5
Афины
ВТОРОЕ
ПОСТАВКА
П #
Д#
КОЛ
Отношение ВТОРОЕ и ПОСТАВКА находятся во второй нормальной форме (2НФ).
Отношение R находится во второй нормальной форме, если оно находится в 1НФ и каждый неключевой атрибут функционально полно зависит от первичного ключа. (Атрибут называется неключевым, если он не является составной частью первичного ключа).
Преобразования из 1НФ во 2НФ состоит в замене отношения соответствующими проекциями.
ВТОРОЕ = П1,2, 3 (ПЕРВОЕ)
ПОСАВКА = П1,4,5(ПЕРВОЕ)
ПЕРВОЕ = ВТОРОЕ > < ПОСТАВКА
1=1
Отношение в 1НФ, которое не находится во 2НФ, должно иметь составной первичный ключ. В отношении ВТОРОЕ отсутствует взаимная независимость между неключевыми атрибутами.
П# ®ГОРОД ГОРОД®СТАТ
Зависимость СТАТ от П# является транзитивной.
П# ®ГОРОД ГОРОД ®СТАТ
Заменим отношение ВТОРОЕ двумя проекциями
ПГ
П#
ГОРОД
ГС
ГОРОД
СТАТ
n1
Лондон
Афины
n2
Париж
Лондон
n3
Париж
Париж
n4
Лондон
n5
Афины
Устраняется транзитивная зависимость.
Оба отношения находятся в 3НФ.
26. ЯЗЫК ЗАПРОСОВ SQL
В конце 80-х годов произошел стремительный взлет популярности СУБД одного конкретного типа — системы управления реляционными базами данных. С тех пор реляционная база данных (РБД) стала единственным стандартным типом базы данных. Данные в РБД хранятся в простой табличной форме, что дает реляционным базам данных много преимуществ по сравнению с базами данных более ранних разработок. SQL представляет собой язык именно реляционных баз данных
Краткая история SQL
История SQL тесно связана с развитием реляционных баз данных. Понятие реляционной базы данных было введено доктором Э. Ф. Коддом, научным сотрудником компании IBM. В июне 1970 года доктор Кодд опубликовал статью под названием "Реляционная модель для больших банков совместно используемых данных'' (“A Relational Model of Data for Large Shared Data Banks"), в которой в общих чертах была изложена математическая теория хранения данных в табличной форме и их обработки. Реляционные базы данных и SQL ведут свое начало от этой статьи, появившейся в журнале " Communications of the Association for Computing Mashinery”.
26. 1 Основы SQL
Операторы
В SQL используется приблизительно тридцать операторов. Каждый оператор "просит" СУБД выполнить определенное действие, например, прочитать данные, создать таблицу или добавить в таблицу новые данные. Все операторы SQL имеют одинаковую структуру.
Оператор
Описание
Обработка данных
SELECT
Считывает данные из БД
INSERT
Добавляет новые строки в БД
DELETE
Удаляет строки из БД
UPDATE
Обновляет данные, существующие в БД
Определение данных
CREATE TABLE
Создает в БД новую таблицу
DROP TABLE*
Удаляет таблицу из БД
ALTER TABLE*
Изменяет структуру существующей таблицы
CREATE VIEW
Добавляет в БД новое представление
DROP VIEW*
Удаляет представление из БД
CREATE INDEX*
Создает индекс для столбца
DROP INDEX
Удаляет индекс столбца
CREATE SYNONYM*
Определяет синоним для имени таблицы
DROP SYNONYM*
Удаляет синоним для имени таблицы
COMMENT*
Определяет заметки для таблицы или столбца
LABEL*
Определяет заголовок таблицы или столбца
Управление доступам
GRANT
Предоставляет пользователю право доступа
REVOKE
Отменяет право доступа
Управление транзакциями
COMMIT
Завершает текущую Транзакцию
ROLLBACK -
Отменяет текущую транзакцию
Программный SQL
DECLARE
Определяет курсор для запроса
EXPLAIN*
Описывает план доступа к данным для запроса
OPEN
Открывает курсор для чтения результатов запроса
FETCH
Считывает строку из результатов запроса
CLOSE
Закрывает курсор
PREPARE*
Подготавливает оператор SQL к динамическому выполнению
EXECUTET
Динамически выполняет оператор SQL
DESCRIBE*
Описывает подготовленный запрос
* He являются частью стандарта ANSI/ISO, но часто встречаются в наиболее распространенных СУБД
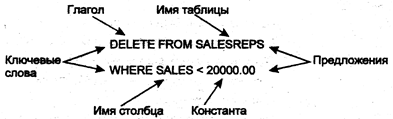
Каждый оператор SQL начинается с глагола, т.е. ключевого слова, описывающего действие, выполняемое оператором. Типичными глаголами являются create (создать), insert (добавить), delete (удалить) и commit (завершить). После глагола идет одно или несколько предложений. Предложение описывает данные, с которыми работает оператор, или содержит уточняющую информацию о действии, выполняемом оператором. Каждое предложение также начинается с ключевого слова, такого как where (где), from (откуда), into (куда) и having (имеющий). Одни предложения в операторе являются обязательным, а другие — нет. Конкретная структура и содержимое предложения могут изменяться. Многие предложения содержат имена таблиц или столбцов; некоторые из них могут содержать дополнительные ключевые слова, константы и выражения.
В стандарте ANSI/ISO определены ключевые слова, которые применяются в качестве глаголов и в предложениях операторов. В соответствии со стандартом, эти ключевые слова нельзя использовать для именования объектов базы данных, таких как таблицы, столбцы и пользователи. Во многих реализациях SQL этот запрет ослаблен, однако следует избегать использования ключевых слов в качестве имен таблиц и столбцов. В табл. 5.2 перечислены ключевые слова, входящие в стандарт SQLL Стандарт SQL2 расширяет этот список до 300 ключевых слов.
ADA
CURRENT
GO-
OF
SOME
ALL
CURSOR
GOTO
ON
SQL
AND
DEC
GRANT
OPEN
SQLCODE
ANY
DECIMAL
GROUP
OPTION
SQLERROR
AS
DECLARE
HAVING
OR
SUM
ASC
DEFAULT
IN
ORDER
TABLE
AUTHORIZATION
DELETE
INDICATOR
PASCAL
TO
AVG
DESC
INSERT
PLI
UNION
BEGIN
DISTINCT
INT
PRECISION
UNIQUE
BETWEEN
DOUBLE
INTEGER
PRIMARY
UPDATE
BY
END
INTO
PRIVILEGES
USER
С
ESCAPE
IS
PROCEDURE
VALUES
CHAR
3SXEC
KEY
PUBLIC
VIEW
CHARACTER
EXISTS
LANGUAGE
REAL
WHENEVER
CH&CK
FETCH
LIKE
REFERENCES
WHERE
CLOSE
FLOAT
MAX
ROLLBACK
WITH
COBOL
FOR
MIN
SCHEMA
WORK
COMMIT
FOREIGN
MODULE
SECTION
CONTINUE
FORTRAN
NOT
SELECT
COUNT
FOUND
NULL
SET.
CREATE
FROM
NUMERIC
SMALLINT
Почти во всех реализациях SQL ключевые слова можно писать как прописными, так и строчными буквами. На практике быстрее набирать весь оператор строчными буквами.
Имена
У каждого объекта в базе данных есть уникальное имя. Имена используются в операторах SQL и указывают, над каким объектом базы данных оператор должен выполнить действие. В стандарте ANSI/ISO определено, что имена имеются у таблиц, столбцов и пользователей. Во многих реализациях SQL поддерживаются также дополнительные именованные объекты, такие как хранимые процедуры, именованные отношения "первичный ключ — внешний ключ" и формы для ввода данных.
В соответствии со стандартом ANSI/ISO,в SQL имена должны содержать от 1 до 18 символов, начинаться с буквы и не содержать пробелы или специальные символы пунктуации. В стандарте SQL2 максимальное число символов в имени увеличено до 128. На практике, однако, в различных СУБД разрешено использование в именах таблиц специальных символов, которые в различных базах данных могут быть разными. Поэтому для повышения переносимости лучше делать имена сравнительно короткими и избегать использования в них специальных символов.