При моделировании сложной предметной области проектировщик разбивает ее на ряд локальных областей, описывает каждое локальное представление моделью типа «сущность – связь», а затем объединяет их в концептуальную модель.
Для каждого локального представления необходимо прежде всего выделить сущности, требуемые для его описания.
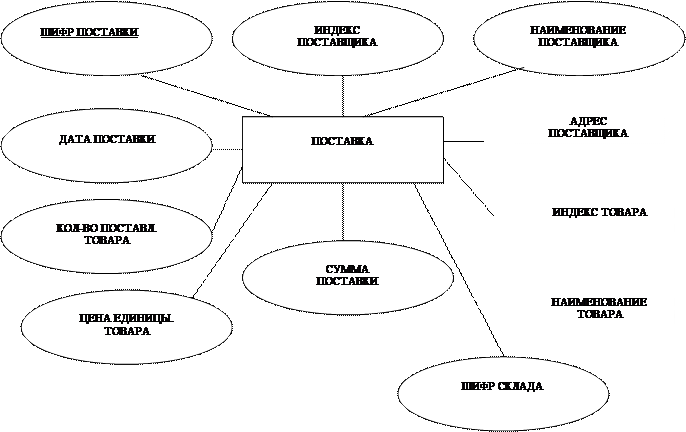
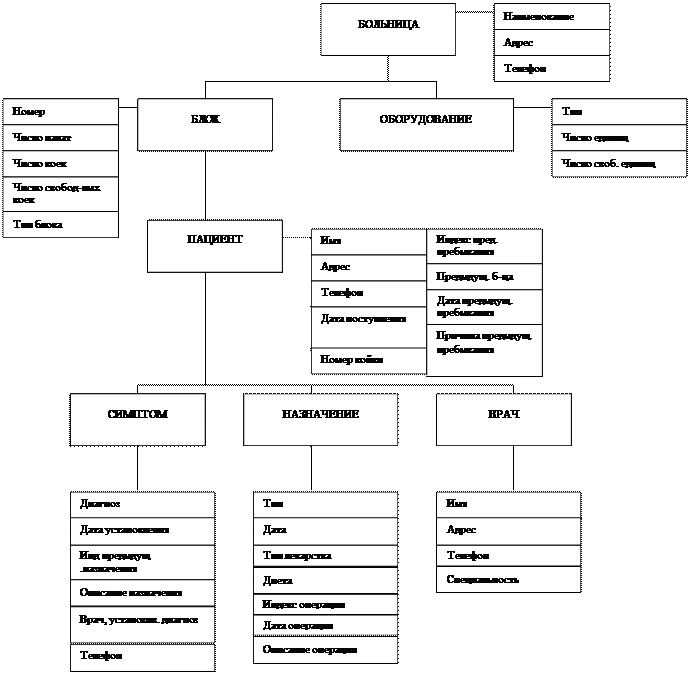
Формирование сущностей рассмотрим на примере моделирования локального представления «Поставка товаров на склад». Предположим, что в одной поставке может участвовать только один вид товара. Поставок может быть несколько. Модель сущности «поставка». Учитывая, что построение моделей ведется от реального мира, мы должны предусмотреть возможность ответа и на другие информационные запросы, что приведет к появлению моделей других сущностей.
1. Дать информацию об отдельном поставщике, который не выполняет поставок в настоящее время. Для этого необходимо ввести в локальную модель сущность «поставщик» с соответствующими атрибутами, связать с сущностью «поставка» и удалить избыточные элементы.
<схема 4>
2. Дать информацию об отсутствующих на складе товарах. Необходимо ввести в модель сущность «товар».
<схема 5>
3-4. Какие товары может поставлять отдельный поставщик?.
Какие поставщики могут поставлять данный товар?.
Для ответа на эти вопросы в модели достаточно осуществить связи между сущностями «поставщик» и «товар»(пунктир).
В данной модели 3 типа сущностей.
Если в локальной модели большое количество типов сущностей, это говорит о том, что локальная область слишком велика и ее необходимо разбить на несколько более мелких локальных областей.
Затем составляется спецификация всех элементов.
I Типы сущностей: поставщик, поставка, товар
ПОСТАВЩИК : идентификатор, `индекс поставщика`
описательный атрибут `АДРЕС ПОСТАЩИКА`
ПОСТАВКА : идентификатор `ШИФР ПОСТАВКИ`
описательный атрибут ` количество поставленного товара`
`ШИФР СКЛАДА`
`ДАТА ПОСТАВКИ`
ТОВАР : -“-
II Типы связей:
ПОСТАВЛЯЕТ : отображение 1:М от поставщик к поставка
МОЖЕТ БЫТЬ ПОСТАВЛЕН : многозначная однонаправленная связь от ТОВАР к
ПОСТАВЩИК
-“-
III Спецификация атрибутов
ИНДЕКС ПОСТАВКИ : следовательно цифровой, 8 символов
ЦЕНА ЕДИНИЦА ТОВАРА : числовой, от 0000.00 до 9999.99
Предметная область БнД определена, если известны существующие в ней объекты, их свойства и отношения.
Состояние ПО в некоторый момент времени t может быть описано совокупностью предложений некоторого языка, определяющих все истинные в момент времени t факты.
Проектирование БД начинается с предварительной структуризации ПО, объекты реального мира подвергаются классификации, фиксируются свойства, посредством которых будут описываться в БД конкретные объекты этого типа; фиксируются виды отношений (взаимосвязей) между объектами.
Затем решаются вопросы о том, какая информация об этих объектах должна быть представлена в БД и как ее представить с помощью данных.
Идея установления соответствия между состоянием ПО, его восприятием и представлением в базе данных лежит в основе инфологического подхода к проектированию информационной системы.
Согласно инфологическому подходу при проектировании необходимо различать:
– явления реального мира;
– информацию об этих явлениях;
– представление этой информации посредством данных.
В соответствии с этой концепцией в подходе выделяют следующие три сферы:
– реальный мир или объектную сист.;
– информационную сферу;
– даталогическую сферу;
Объектная система имеет следующие составляющие:
объект, свойства, связь (или объектное отношение), время.
Эти понятия являются основными составляющими объектной системы.
Объект в инфологическом подходе – это то, о чем в информационной системе должна храниться информация. Выбор объектов производится в соответствии с целевым назначением информационной системы. Объекты могут быть атомарными или составными. Для составного объекта должны быть определены его внутренние составляющие (которые могут быть атомарными или составными).
Каждый объект в конкретный момент времени характеризуется определенным состоянием. Это состояние описывается с помощью ограниченного набора свойств и отношений(связей) с другими объектами.
Каждый объект в любой момент времени отличается от других объектов набором свойств.
Свойства объекта могут не зависеть от его связей (отношений) с другими объектами, т.е. являются локальными, а могут зависеть, в этом случае они являются реляционными.
Каждая связь между объектами по числу входящих в нее объектов характеризуется степенью n=2,3,…k (бинарная, тернарная,…,к-арная).
Объекты имеют определенное состояние как в отдельные моменты, так и в течение некоторых временных интервалов. Концепция времени позволяет строить динамические модели, в которых отображается зависимость от времени составляющих объектной системы.
Основные составляющие объектной системы могут быть скомбинированы в базисные структуры, называемые элементарными ситуациями.
Элементарной ситуацией называется тройка <o,u,t>,
где o – объект (или n объектов)
u – устройство (n-арная связь)
t - время.
Вводится понятие элементарных ситуаций типа свойств <o,p,t> и элемент ситуаций реляционного типа <<o1, o2, …..on>, r, t >
o –объект, p – элемент множества свойств, r – элемент множества связей.
Для конкретной ПО, для определенного типа объектов элементарные ситуации, существующие в некоторые моменты времени, называются элементарными фактами.
Множество всех объектов, имеющих общее свойство р, называется группой объектов О(р). Группы объектов могут быть как пересекающимися, так и не пересекающимися.
Центральным понятием в инфол. подходе является тип элементарной ситуации <x,y>
где x – объектная группа
y – атрибут (множество свойств объектной группы) или связь между n объектами.
Составляющие объектной системы могут группироваться в классы подобных составляющих. Объекты группируются в типы объектов – группы объектов. Свойства формируют атрибуты. Элементарные ситуации группируются в типы элементарных ситуаций.
Информационная сфера представляется в понятиях, с помощью которых можно формально описать и проанализировать информацию об объектной системе.
Основным понятием в этом разделе является сведение. Для каждого сведения всегда определена предметная цель, т.е. указано, к чему оно относится. Сведение может относится к объектной группе, к атрибуту, связи, времени, ситуации. Сведения представляют собой смысловые, концептуальные образы составляющих, которые используются человеком при восприятии и осмыслении реальных объектов. Различные сведения могут относиться к одной и той же составляющей объектной системы, и наоборот.
Одиночное сведение называется универсальным именем. Сведения, не имеющие универсальной однозначности, называются локальным именем.
Сведения представляются выражениями, основу которых составляют элементарные сообщения. Структура элементарного сообщения соответствует структуре элементарной ситуации:
<x, y, z>
x-сведения об объекте, y-сведения о свойствах или связях, z-сведения о времени.
Аналогично элементарным ситуациям в рассмотрение вводятся элементарные сообщения типа свойств и элементарные сообщения реляционного типа.
Тройка <x, y, z> представляет собой полное элементарное сообщение. Оно содержит сведения об объекте, о предикате и о времени. Если отсутствует хотя бы одна составляющая, получается неполное элементарное сообщение. Запросы к ИС представляются в неполных элементарных сообщениях.
Полные элементарные сообщения выражают элементарные ситуации объектной системы и выступают в качестве элементарных информационных единиц.
Множеству допустимых элементарных ситуаций объектной системы соответствует множество значимых полных элементарных сообщений.
В датологической сфере рассматриваются вопросы представления с помощью данных выделенных информационных структур объектной системы.
Таким образом для отображения ОС в информационную сферу необходимо определить:
- объекты, важные для данного применения;
- свойства, которые могут иметь объекты;
- связи, существующие между объектами;
- имена, которые можно присвоить отдельным составляющим ОС.
Для точной спецификации объектной системы вместо раздельного описания типов объектов, атрибутов, связей и ограничений используется тип элементарной ситуации.
Выполненная спецификация представляет собой инфологическую модель ОС, в которой отражены составляющие ПО и связи между ними.
Инфологический подход не представляет формальных способов моделирования реальности, но дает основы методологии проектирования БД.
16. МОДЕЛИ ДАННЫХ И ПОДЪЯЗЫКИ ДАННЫХ
Ядром любой системы базы данных является модель данных (концептуальная модель). Это ясно из архитектуры БнД. Диапазон структур данных, поддерживаемый в концептуальной модели, является тем фактором, который существенно влияет на все другие компоненты системы. Этот диапазон диктует конструкцию соответствующих подъязыков данных, т. к. для каждой операции подъязыка данных.
17. ИЕРАРХИЧЕСКАЯ МОДЕЛЬ ДАННЫХ
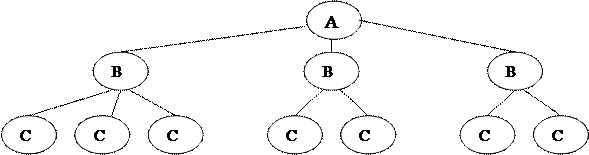
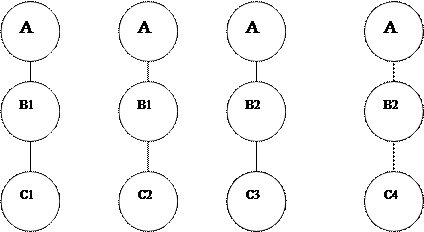
Ранняя модель, широко используемая, соответствует системам управления – иерархическая модель данных. Ей соответствует организация данных в иерархические файлы. В них записи связаны в (иерархические) древовидные структуры.
Один способ хранения:
Для хранения в ЗУ используется последовательный файл в виде левосписковой структуры. Показанная структура приводиться к виду А В1С1 С2 С3 В2 С4 С5 В3 С6 С7. Другой способ – использование встроенных указателей. В записи А должны иметься указатели на записи В1 ,В2 ,В3. В записи В1 – на записи С1 ,С2 ,С3 и т. д.
Помимо указателей на порожденные записи могут использоваться указатели на исходные записи: в записях С1 ,С2 ,С3 – на запись В1, в записи В1 – на А и т. д. Наибольшее удобство достигается в работе с иерархическими файлами в случае дополнения систем указателей двух указанных типов указателями на следующую подобную запись. Запись В1 содержит указатель на В2, В2 – на В3. Запись С1 à С2 à С3 , С4 à С5 , С6 à С7 .
В иерархической модели данных действуют наиболее жесткие внутренние ограничения на представление связей между сущностями. Основные внутренние ограничения иерархической модели данных:
- все типы связей функциональные типа 1:1, 1:M, M:1
- структура связей древовидная.
Древовидная структура данных, представленная в виде графа, включает набор элементов, распределенных по уровням следующим образом:
1) на первом уровне только один элемент – корень
2) к каждому элементу i-го уровня ведёт только один адрес связи от предыдущего элемента
3) к каждому элементу i-го уровня ведёт адрес связи только от элемента (i – 1)-го уровня. Любое нарушение условий означает, что структура является сетевой
ОСНОВНЫЕ ПОНЯТИЯ
Сегмент тип сегмента экземпляр сегмента поле данных
Исходный и порожденный сегменты
Зависимый экземпляр сегмента
Подобные сегменты цепочка подобных сегментов
Корневой сегмент
Иерархический путь
Запись базы данных база данных
Ключевое поле поисковое поле
НАИМЕНОВАНИЕ
АДРЕС
НОМЕР ТЕЛЕФОНА
Для пользователя
НАИМЕНОВАНИЕ
(КЛЮЧ)
ДАННЫЕ
В базе данных
Информация представлена в виде “перевернутой” древовидной структуры. Это представление известно под названием иерархической схемы базы данных. Информация организована в сегменты. Сегмент представляет собой наименьшую единицу информации, которую может получить пользователь. Сегмент содержит поля данных.
База данных – содержит все корневые и все зависимые от них сегменты.
Внутри каждого сегмента содержатся поля. Некоторые поля называются ключевыми, некоторые – поисковыми.
Ключевое поле – поле упорядочения.
Ключевое поле служит для поддержания экземпляров сегмента в возрастающей последовательности. В каждом сегменте может быть только одно ключевое поле. Однако в общем случае не требуется. Поля упорядочения могут быть определены как уникальные или неуникальные.
Поисковое поле – используется для поиска данных. Может быть до 255 поисковых полей.
Существуют понятия тип сегмента и экземпляр сегмента.
IMS не более 255-типов сегментов, глубина иерархии – 15 уровней.
Количество экземпляров сегментов ограничено физической емкостью ЗУ.
Для описания связей сегментов в иерархической БД используются термины исходный и порожденный. Один и тот же сегмент может быть и исходным, и порожденным. Порожденный сегмент называется также зависимым, но это название относится больше к экземплярам сегментов.
Подобный – все экземпляры конкретного типа сегмента, расположенные под одним экземпляром исходного сегмента.
Совокупность всех подобных сегментов, относящихся к одному исходному, называется цепочкой подобных сегментов.Один сегмент является только исходным, не подчинен никакому другому сегменту. Он называется корневым. Через него осуществляется доступ ко всем зависимым сегментам.
Поиск сегментов осуществляется всегда по иерархическим путям. Путь начинается всегда от корневого сегмента и заканчивается всегда на самом нижнем уровне.
Запись – один экземпляр корневого сегмента и все зависимые от него сегменты (запись базы данных). После определения сегментов, принятие решения о виде иерархической структуры и выбора ключевых и поисковых полей проводится процесс генерации базы данных. Для этого создается управляющий блок, называемый описанием базы данных. (DBD – data base description). Это выполняется с помощью ЯОД.
FIELD NAME = (HOSPNAME,SEQ,U), BYTES = 20,START = 1, TYPE = C
SEGM NAME = WARD, PARENT = HOSPITAL, BYTES = 31
FIELD NAME = (WARDNO,SEQ,U), BYTES = 2,START = 1, TYPE = C
FIELD NAME = BEDAVAIL, BYTES = 3,START = 9, TYPE = C
FIELD NAME = WARDTYPE, BYTES = 20,START = 12, TYPE = C
SEGM NAME = PATIENT, PARENT = WARD, BYTES = 125
FIELD NAME = (BEDIDENT,SEQ,U), BYTES = 4,START = 61, TYPE = C
FIELD NAME = PATNAME, BYTES = 20,START = 1, TYPE = C
FIELD NAME = DATEADMT, BYTES = 6,START = 65, TYPE = C
SEGM NAME = SYMPTOM, PARENT = PATIENT, BYTES = 77
FIELD NAME = (SYMPDATE,SEQ,U), BYTES = 6,START = 21, TYPE = C
FIELD NAME = DIAGNOSE, BYTES = 20,START = 1, TYPE = C
FIELD NAME =, BYTES = 20,START = 1, TYPE = C
SEGM NAME = TREATMNT, PARENT = PATIENT, BYTES = 113
FIELD NAME = (TRDATE,SEQ), BYTES = 6,START = 21, TYPE = C
FIELD NAME = TRTYPE, BYTES = 20,START = 1, TYPE = C
SEGM NAME = DOCTOR, PARENT = PATIENT, BYTES = 80
FIELD NAME = DOCTNAME, BYTES = 20,START = 1, TYPE = C
FIELD NAME = SPECIALT, BYTES = 20,START = 61, TYPE = C
SEGM NAME = FACILITY, PARENT = HOSPITAL, BYTES = 26
FIELD NAME = FACTYPE, BYTES = 20,START = 1, TYPE = C
Операнды PARENT определяют иерархическую структуру базы данных. Предложения SEGM кодируются в иерархической последовательности, которая строится в соответствии с правилом сверху вниз и слева направо.
В предложении FIELD операнд NAME от одного до трех подпараметров. Первый присваивает имя полю. Если других подпараметров нет, поле объявляется поисковым. Если SEQ – ключевое поле или поле упорядочения. Если U – уникальное ключевое поле.
С помощью DBD описали физическую базу данных. Для объединения двух или нескольких баз данных в новую иерархическую структуру применяется для описания логической базы данных. Это объединение осуществляется с помощью логических связей. Логические связи позволяют определить новые иерархические связи, не создавая новую физическую базу данных. Это является мощным средством для установления связи между данными, хранимыми в более чем одной физической базе данных, с тем, чтобы они были доступны в одной иерархической структуре. Кроме того, появляется возможность уменьшить дублирование информации.
18. СЕТЕВАЯ МОДЕЛЬ ДАННЫХ
Существуют приложения, в которых требуется реализовать отображение M:N. Например организация управления на основе сетевых графиков. Модель носит название сетевой. Снимается ограничение о наличии у каждого элемента не более одного исходного. Допускаются произвольные связи между элементами. Модель реализуется с помощью сетевых файлов.
При введении избыточности за счет многократного повторения некоторых записей сетевые структуры могут быть сведены к иерархическим.
В сетевых файлах довольно часто приходится именовать связь или сопровождать ей дополнительными данными, называемыми данными пересечения записей, соединяемых этой связью. Элементы данных представляются в виде записей и связей.
Логическая структура данных употребляется по отношению к группе сегментов, к которой может иметь доступ отдельная прикладная программа. С точки зрения прикладной программы логическая структура данных и является базой данных.
Пример: записи, представляющие поставщиков и детали.
В дополнение к этим типам записей вводится третий тип записи, связующей. Экземпляр связующей записи представляет связь между одним поставщиком и одной деталью (поставку). Запись содержит данные, описывающие эту связь (количество поставляемых деталей).
Все экземпляры связующей записи, соответствующие одному поставщику, помещаются в цепочку, начинающуюся заканчивающуюся этим поставщиком. Аналогично для детали. Каждый экземпляр связующей записи, т. о., связан точно с двумя цепочками – цепочкой поставщика и цепочкой детали. Можно представить в таком виде и иерархическую модель. Но внутренняя структура сетевого файла более сложна.
В подъязыке данных теперь кроме операторов GU (GET NEXT FOR WHERE) должен быть оператор GET SUPERIOR FOR, чтобы получить уникальную исходную запись в цепи определённого связующего экземпляра.
Обработка записей БД сводится к действиям со связующей записью.
РЕАЛИЗАЦИЯ СЕТЕВОЙ МОДЕЛИ ДАННЫХ
Более универсальной моделью является реляционная модель. Реляционные структуры данных дают возможность установить интерфейс между логическими структурами данных.
19. РЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ
А
В
С
···
Х
а 1
в 1
с 1
···
х 1
а 2
в 2
с 2
···
х 2
·
·
·
·
а n
·
·
·
·
в n
·
·
·
·
с n
·
·
·
·
···
·
·
·
·
х n
ОСНОВНЫЕ ПОНЯТИЯ
Отношение кортеж атрибут домен
Нормализация реляционная структура
а
в1
с1
а
в1
с2
а
в2
с3
а
в2
с4
20. РЕЛЯЦИОННЫЕ БАЗЫ ДАННЫХ
Реляционный подход к описанию структур данных основывается на использовании для их описания языка предикатов, или произвольных (n-местных) отношений. Имеются в виду отношения между элементарными данными. Любое подобное отношение может быть представлено двумерной таблицей.
На этой таблице представлено отношение с именем А над элементарными данными a, b, c, …, x. Каждая строка таблицы представляет собой набор значений этих данных, находящихся между собой в данном отношении (отношение А для них истинно). Строки таблицы принято называть картежами, а столбцы – доменами (атрибутами). Если количество столбцов (длина картежей) равно m, то говорят, что отношение А имеет степень m или m-местным (m-арным) отношением.
Считая кортежи отдельными записями, легко представить заданное отношение в виде простейшего последовательного файла.
Главная идея реляционного подхода состоит в том, чтобы представлять произвольные структуры данных в виде совокупностей отношений (таблиц). Процесс такого представления называется нормализацией, а само представление – реляционной структурой. Если на отношения реляционной структуры не накладывается никаких ограничений, кроме отсутствия одинаковых строк в таблице, то она представлена в первой нормальной форме. Можно провести нормализацию любого иерархического файла, записями которого являются элементарные данные. Для этого достаточно размножить узлы.
Если записи сами представляют собой иерархические структуры, то тот же процесс размножения узлов можно применить и к ним. В результате файл будет приведён к виду плоской таблицы.
В случае сетевых структур они приводятся сначала к иерархической, а затем к реляционной форме. Эти приемы нормализации приводят к большой избыточности в логическом представлении данных. Кроме того, актуализация таких отношений может привести к аномалиям манипулирования, когда происходит разрушение (или потеря) данных. Результатом нормализации является отношение высокой степени. Процесс нормализации продолжается расщеплением сложных (многоместных) отношений на более простые.
Имеются СУБД с программными средствами ведения словаря. Такие системы называются системами с интегрированным словарем данных. Системы, которые не имеют средств ведения словаря и включают специальные пакеты ведения словаря, называются системами с независимым словарём.
21. АЛГЕБРА ОТНОШЕНИЙ
На множестве отношений легко определяются различные операции, превращающие это множество отношений в алгебру отношений (реляционную алгебру)
Операция проекции – выделение какой-либо части доменов и устранение возможных повторений строк.
Операция объединения (соединения) – позволяет «склеить» несколько отношений в одно истинное тогда и только тогда, когда истинны все объединяемые отношения. При такой операции число строк может уменьшиться и даже свестись к нулю (пустое отношение)
Отношение А, задаваемое кортежами
a1b1c1
a2b2c1
a3b1c1
Отношение В задается кортежами
b1c2
b2c1
Объединение А с В по всем трем доменам – отношение с
с : a2b2c1
А*В (a,b,c) = с
Возможные и другие операции над отношениями. Если в состав программного обеспечения реляционной базы данных включены программы, автоматизирующие выполнение этих операций, то они могут осуществить отображение одной логической структуры данных в другую. При этом предполагается, что обе структуры описаны в виде схем отношений (таблиц). Программы перевода производят заполнение таблиц второй структуры, используя таблицы первой структуры. Тем самым автоматизируется интерфейс между различными логическими структурами данных.
Администратор БД задает в описании данных формулы реляционной алгебры, с помощью которых из отношений логической структуры базы данных получается отношения структуры, используемой в запросе или приложении.
Более высокий уровень автоматизации интерфейса предполагает использование лишь описаний связываемых структур данных на специальном с помощью так называемого исчисления отношений (реляционного исчисления). В этом случае система сама определяет пути реализации такого «описательного» отображения.
Преимущества реляционных БД
1. Различные прикладные программы используют различные представления логической структуры данных.
2. Простота понимания и работы с базой (таблица)
3. Используются языки манипулирования высокого уровня (уровня исчисления). В запросе указывается, что найти, а не как найти.
4. Реляционную БД просто развивать и дополнять. Процедуры актуализации упрощаются.
5. Упрощается контроль доступа и обеспечения секретности.
6. Упрощается физическая организация данных и ее интерфейс с логической структурой.
7. В реляционной структуре естественным образом выражаются отношения любой степени.
8. Отношения являются строго определенным математическим понятием и может служить объектом строгой математической теории. Реляционная алгебра.
Недостаток – избыточность данных.
Отношения
Дана совокупность множеств D1,D2,…,Dn (не обязательно различных). Отношение R, определенное на этих n множествах, есть множество упорядоченных n-выборок (n-ок) или кортежей (d1,d2,..dn) таких, что d1 Î Dn называется доменами отношения R. Величина n называется степенью (мощностью) отношения.
Домены Д# (номер детали)
ДЕТ (наименование детали)
ЦВ (цвет детали)
ВЕС (вес детали)
ГОР (город, где хранится деталь)
Отношения ДЕТАЛЬ
Д#
ДЕТ
ЦВ
ВЕС
ГОР
д1
гайка
Красный
Лондон
д2
болт
Зеленый
Париж
д3
винт
Синий
Рим
д4
винт
Красный
Лондон
д5
штифт
Синий
Париж
д6
шестерня
Красный
Лондон
Число кортежей в отношении называется кардинальным числом отношения
Столбцы – атрибуты.
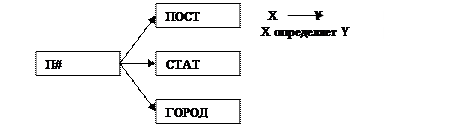
Домены П# (номер поставщика)
ПОСТ (имя поставщика)
СТАТ (статус поставщика)
ГОР (город, где расположен пост)
Отношение поставщик
П#
ПОСТ
СТАТ
ГОРОД
п1
Смит
Лондон
п2
Джонсон
Париж
п3
Блейк
Париж
п4
Кларк
Лондон
п5
Адамс
Афины
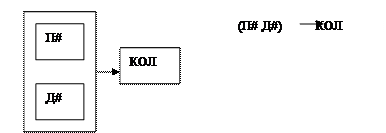
Домены П#
Д#
Кол (количество)
Отношение ПОСТАВКА
П#
Д#
КОЛ
п1
д1
п1
д2
п1
д3
п1
д4
п1
д5
п1
д6
п2
д1
п2
д2
п3
д2
п4
д2
п4
д4
п4
д5
22. НОРМАЛИЗАЦИЯ ОТНОШЕНИЙ
Ключи
Если значения некоторого атрибута однозначно идентифицирует кортежи отношений (все кортежи содержат различные значения атрибутов), атрибут называется первичным ключом отношения. Например, атрибут Д# в отношении ДЕТАЛЬ.
Не каждое отношение будет иметь первичный ключ в виде единственного атрибута. Но каждое отношение будет иметь некоторую комбинацию атрибутов, которые, взятые вмести, будут однозначно идентифицировать кортеж в отношении.
Например, (П#,Д#) в отношении ПОСТАВКА. По крайней мере комбинация из всех атрибутов будет первичным ключом. Т.о. каждое отношение будет иметь первичный ключ. Предполагается, что первичный ключ не избыточен в том смысле, что никакие из составляющих его атрибутов не являются излишними для однозначной1лишними для однозначногояющих его атрибутов не являются излишними для однозначного идентизначения атрибутов) идентификации кортежа в отношении.
Например, комбинация (Д# ЦВ) не является первичным ключом для отношения ДЕТАЛЬ.
Иногда можно встретить отношения, в которых существует более, чем одна комбинация атрибутов, способная однозначно идентифицировать кортеж. Эти отношения имеют более одного возможного ключа.
Ни один из компонент первичного ключа не должен быть нулевой.
Атрибут отношения R1 является внешним ключом, если атрибут – не первичный ключ отношения R1, но его значения являются значениями первичного ключа некоторого отношения R2.
Например атрибут Д# в отношении ПОСТАВКА внешний ключ (первичный ключ в ДЕТАЛЬ).
Первичный и внешний ключи служат для связи между отношениями. Не всегда «связывающий» атрибут является ключом. Например, если мы потребуем «соразмещения» поставщиков и деталей (связь отношений ДЕТАЛЬ и ПОСТАВЩИК), атрибуты ГОР и ГОРОД не будет ключом.
Функциональная зависимость
Атрибут Y отношения R функционально зависит от атрибута X отношения R тогда и только тогда, когда каждое значение X в отношении R в каждый момент времени связано точно с одним значением Y. Одно и тоже значение X может появляться в нескольких различных кортежах отношения R. Если Y функционально зависит от X, то по определению каждый из этих кортежей должен содержать также одно и то же значение Y.
Например, в отношении ПОСТАВЩИК атрибуты ПОСТ, СТАТ, ГОРОД функционально зависят от П#
X, Y или оба могут быть составными атрибутами.
Например, в отношении ПОСТАВКА атрибут КОЛ функционально зависит от составного атрибута (П# Д#)
Полная функциональная зависимость.
Атрибут Y находится в полной функциональной зависимости от атрибута X, если он функционально зависит X и не зависит функционально от любого подмножества атрибута X (X д.б. составным).
Например, полная функциональная зависимость (П# Д#) => КОЛ
Не находится в полной функциональной зависимости (П# СТАТ) => ГОРОД, т.к.
П# => ГОРОД
В примерах функциональной зависимости от первичного ключа.
Отношение R находится в первой нормальной форме тогда и только тогда, когда все входящие в него домены содержат только атомарные (неделимые) значения. Любое нормальное отношение находится в 1НФ.
Рассмотренные отношения находятся в четвертой нормальной форме (4НФ).
Отношение R находится в 4НФ тогда и только тогда, когда в каждый момент времени каждый кортеж отношения R состоит из значения первичного ключа, которое идентифицирует некоторый объект, и из множества взаимных произвольных значений атрибутов, некоторым образом описывающих этот объект.
Чтобы продемонстрировать процесс нормализации, возьмем отношение.
ПЕРВОЕ (П#, СТАТ, ГОРОД, Д#, КОЛ).
Считаем, что СТАТ – транспортные издержки, т.е. СТАТ функционально зависит от ГОРОД.
ГОРОД => СТАТ
ПЕРВОЕ
П#
СТАТ
ГОРОД
Д#
КОЛ
п1
ЛОНДОН
д1
п1
ЛОНДОН
д2
п1
ЛОНДОН
д3
п1
ЛОНДОН
д4
п1
ЛОНДОН
д5
п1
ЛОНДОН
д6
п2
ПАРИЖ
д1
п2
ПАРИЖ
д2
п3
ПАРИЖ
д2
п4
ЛОНДОН
д2
п4
ЛОНДОН
д4
п4
ЛОНДОН
д5
Первичный ключ (П#, Д#)
Отношения R и Q с атрибутами X,Y и Y,Z.
Пример:
Отношение R с тремя атрибутами: номер работника, номер выполняемого задания, расчетный срок выполнения задания. Здесь третий атрибут неполно транзитивно зависит от первого атрибута, поскольку один и тот же работник может выполнять несколько заданий. Поэтому после приведения отношения R к ЗНФ таблице распадается на две. В первой таблице номеру работника соотносятся номера выполняемых им заданий, во второй – номер задания соответствует расчетный срок его выполнения.
В программное обеспечение реляционных баз данных включается программа для автоматической нормализации.
23. ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ.
Проектирование реляционных баз данных основывается на трех принципах:
- эквивалентных преобразований схемы базы данных.
- уничтожения аномального манипулирования данными
- минимальной избыточности
В общем случае при проектировании ставится задача получения схемы базы дынных, которая эквивалентна и лучше исходной.
В настоящее время известны два подхода к определению понятия эквивалентности схем базы данных: эквивалентность по зависимостям и эквивалентность по данным.
Эквивалентность по зависимостям: схемы содержат одни и те же зависимости: если Г1 и Г2 – множества зависимостей двух схем, то эти схемы эквивалентны по зависимостям, если Г1=Г2
Эквивалентность по данным: требуется, чтобы обе базы данных содержали одни и те же данные: две БД со схемой Si, i=1,k и Tj, j=1,n соответственно содержат одни и те же данные, если S1*S2*…*Sk = T1*T2*…Tn, где * - операция естественного соединения отношений.
Одной из целей проектирования реляционных баз данных является уничтожение аномалий манипулирования данными. 3 НФ, введенная ка…ом, позволяет существенно уменьшить( но не исключить) аномалии манипулирования. 3 НФ сохраняет эквивалентность и по зависимостям, и по данным. Каждая НФ либо теряет эквивалентность по данным или по зависимостям, либо допускает аномалии.
Можно дать два определения избыточности: по зависимостям и по данным.
Система отношений S с множеством зависимостей Г избыточна по зависимостям Гi, если
nn
(UГj) = (UГj)
j=1 j=1 j≠i
Система S избыточна по данным отношения Si, если S1*S2*…*Sk = S1*S2*… Si-1*Si+1*…*Sn.
Для любого отношения существует такая третья НФ, которая не избыточна по функциональным зависимостям.
В связи с двумя подходами к определению эквивалентных преобразований схем БД существует два метода проектирования схем: синтез и декомпозиция.
Синтез предполагает сохранение эквивалентности по зависимостям.
Декомпозиция – сохранение эквивалентности по данным.
В алгоритмах синтеза достижима только 3НФ, при декомпозиции – любые. При синтезе не снимаются полностью аномалии манипулирования. Можно получить минимальную избыточность по функциональным зависимостям, в алг. декомпозиции – по данным.
Обозначим: A,B,C, …… X,Y,Z – множества атрибутов
a,b,c, …….x,y,z – значения атрибутов
U,R,S - отношения.
Объединение множеств атрибутов X и Y обозначается Х*Y.
Пусть X и Y – атрибуты отношения R.
Атрибут Y функционально зависит от атрибута X, если в каждый момент времени каждому значению х соответствует одно значение y.
X ® Y - Y зависит от X
X ® Y - зависимости нет.
Если X ® Y и Y ® X, то существует однозначное соответствие.
В каждом отношении имеется определенное множество функциональных зависимостей между атрибутами, причем из одной или нескольких функциональных зависимостей можно вывести другие функциональные зависимости, также присущие этому отношению.
Пример: задано отношение со схемой R ( A1, A2, A3)
A1
A2
A3
В отношении R имеются функциональные зависимости
{ A1 ® A2; A2 ® A3 }=F
Из анализа отношения очевидно, что в нем, кроме указанных, имеются другие зависимости.
F+={ A1 ® A3; A1A2 ® A3, A1A2A3®A1A2, A1A2®A1A3 }
Заданное множество функциональных зависимостей для схемы отношения R ( A1, A2, A3) обозначается через F, а полное множество функциональных зависимостей, которое можно логически получить из множества F, через F+. F С F+
Чтобы строить множество F+из F , необходимо знать аксиомы вывода одних функциональных зависимостей из других. Аксиомы позволяют вывести полное множество функциональных зависимостей, присущих рассматриваемой схеме отношения R(A1,……An) по заданному множеству функциональных зависимостей.
Аксиома Ф1 (свойство рефлексивности)
Если Х ≤ U, Y ≤ X, Y ≤ X, то имеет место функциональная зависимость X ® Y. Аксиома Ф1 дает тривиальные зависимости Аj ® Ai
Ai Аj ® Аj
Ai Аj AkAeAr ® АjAkAr и т.д.
Аксиома Ф2 (свойство пополнения)
Если Х ≤ U, Y ≤ U, Z ≤U и задана функциональная зависимость X ® Y, которая либо принадлежит множеству F , либо получена из F с использованием правил вывода, то X*Z®Y*Z
Для аксиомы Ф2 несущественно, перекрываются ли множества X,Y,Z или нет. Используя это правило можно любые атрибуты множества U подставлять одновременно в правую и в левую часть выражения функциональной зависимости, при этом функциональная зависимость сохраняется.
A1
A2
A3
A4
A5
и
б
а
в
з
д
и
л
г
з
е
б
м
н
ж
в
к
а
с
х
R:
F={A1 ®A2
A2 ®A3
A3 ®A4
A4 ®A5}
Выберем в качестве произвольных множеств атрибутов X,Y и Zследующие множества:
X= { A1 } Z= { A4, A5}
Y= { A3 }
Кортежи отношения R
XÈZ
YÈZ
< и в з >
< а в з >
< д г з >
< л г з >
< е н ш >
< м н ш >
< в с х >
< а е х >
Приходим к выводу, что существует функциональная зависимость {A1 A4 A5}® {A3 A4 A5} - выполняется свойство пополнения.
Аксиома Ф3(свойство транзитивности)
Х ≤ U, Y ≤ U, Z ≤ U. Заданы зависимости X {A1 A4 A5} X ® Y, Y ® Z, которые либо принадлежат множеству F , либо получены из F с помощью правил вывода. Следует X ® Z .
Из инфологического проектирования известно, что помимо функциональных существуют многозначные зависимости X ®® Y.
Для того чтобы убедиться, что конкретную взаимосвязь Y (X) можно рассматривать как многозначную зависимость, необходимо выполнить проверку ограничения. Оно состоит в следующем:
Если в отношении R имеет место зависимость X ®® Y, то для двух произвольных кортежей t и s таких, что t[x]=s[x], обязательно отношение содержит кортежи U и V, удовлетворяющие условиям
1) U [X] = V [X] = t [X] = s [X]
2) {U [Y] = t [Y]
U [R-X-Y] = s [R-X-Y]
3) {V [Y] = V [Y]
V [R-X-Y] = V [ R-X-Y]
Задано исходное положение R:
X Y Z
а в с Проверим, существует ли многозначная зависимость Y ®® Z По значению их компонентов формируем кортежи U и V
В отношении R выберем произвольные кортежи t,s, для которых значение атрибута t [Y] = s [Y] .
а в д
е ж з
ж в с
ж в д
t : <а, в, с>
s : <ж, в, д>
1) U [Y] = V [Y] = t [Y] = s [Y]= в
2) {U [Z = t [Z] =c
U [R-Y-Z] = s [ R-Y-Z ]= u[X]=s [X]=ш
3) {V [Z] = s[Z]=д
V [ R-Y-Z ] = t [ R-Y-Z ] =VX] =t [X] = а
В отношении должны быть кортежи <ш, в, с> <а, в, д>, что и имеет место в отношении R. Следовательно имеет место многозначная зависимость.
Для многозначных зависимостей существуют также аксиомы вывода:
М1(аксиома дополнения)
Если имеется набор атрибутов Х ≤ U, Y ≤ U и имеет место многозначная зависимость X®® Y, то имеет место также X®® (U-X-Y)
М2 (аксиома пополнения)
Х ≤ U, Y ≤ U, V ≤ W, X®® Y, отсюда WX ®® VY
М3 (аксиома транзитивности)
Х ≤ U, Y ≤ U, X ®®Y, Y ®® Z : X ®® Z - Y,
Кроме того, существуют аксиомы, связывающие функциональные и многозначные зависимости:
ФМ1
Если Х ≤ U, Y ≤ U и существует X ® Y, то X ®®Y
ФМ2Если Х ≤ U, Y ≤ U, Z ≤ U, Z ≤ U, W ≤ U, причем W ∩ Y =Æ и X ®® Y, W®Z, то имеет место X® Z.
Система аксиом Ф1-Ф3,М1-М3, ФМ1-2 обладает свойством полноты и надежности.
Свойство полнотыозначает, что при использовании этих правил можно по заданному множеству исходных зависимостей F= { F1, F2, …… Fх} построить все зависимости, принадлежащие множеству F+.
Свойство надежности означает, что используя эти правила вывода, можно вычислить только зависимости Fj Î F+.
A – множество всех номеров поставщиков
B – множество всех номеров деталей
A*B – п1 д1 кардинальное число
… … S*6 = 30
п1 д6
п2 д1 мощность (степень)
… … n + m
п2 д6
п3 д1
… …
п5 д6
24. СПЕЦИАЛЬНЫЕ ОПЕРАЦИИ НАД ОТНОШЕНИЯМИ
Селекция Оператор для построения «горизонтального» подмножества отношения, т.е подмножества кортежей внутри отношения, удовлетворяющих определенному условию, принимающему значение «истина» или «ложь» для каждого кортежа.
σ4=’ЛОНДОН’ (ПОСТАВЩИК)
п1 Смит 20 Лондон
п4 Кларк 20 Лондон
σВЕС<14 (ДЕТАЛЬ)
д1 Гайка красный 12 Лондон
д5 штифт синий 12 Париж
σП# =’п1’ AND Д# =’д1’ (ПОСТАВКА)
п1 д1 300
Проекция – оператор для построения «вертикального» подмножества отношения, т.е. подмножества, получаемого путем выбора определенных атрибутов и исключения других (повторяющиеся кортежи).
П4 (ПОСТАВЩИК) ГОРОД
Лондон
Париж
Афины
П пост, город, стат
Пост
Город
Стат
Смит
Лондон
Джонсон
Париж
Блейк
Париж
Кларк
Лондон
Адамс
Афины
Соединение ДЕТАЛЬ > < ПОСТАВЩИК
ГОР=ГОРОД
g1
гайка
красный
Лондон
n1
Смит
Лондон
g1
гайка
красный
Лондон
n4
Кларк
Лондон
g2
болт
зеленый
Париж
n2
Джонсон
Париж
g2
болт
зеленый
Париж
n3
Блейк
Париж
g4
винт
красный
Лондон
n1
Смит
Лондон
g4
винт
красный
Лондон
n4
Кларк
Лондон
g5
штифт
синий
Париж
n2
Джонсон
Париж
g5
штифт
синий
Париж
n3
Блейк
Париж
g6
шестерня
красный
Лондон
n1
Смит
Лондон
g6
шестерня
красный
Лондон
n4
Кларк
Лондон
Степень отношения = n+m 9
Кардинальное число = 10
g3 и n5 не участвуют.
Соединением по условию Ө отношения А по атрибуту Х с отношением В по атрибуту Y называется множество всех кортежей t таких, что t есть конкатенация кортежа аÎА и кортежа вÎВ: х Өу (х-Х- компонента а, у- Y – компонента в). Х и Y должны строится из одного домена.
Теоретически введено 4 уровня нормализации схем отношений и 4 нормальных формы.
< Рис. >
1НФ все атрибуты атомарные. нет повторяющихся записей.
Для работы языка запросов достаточно, чтобы отношение находилось в 1НФ.
Последующие нормализации необходимы для исключения аномалий.
2НФ Если Х-ключ отношения R (первичный) Y С Х, А – непрерывный атрибут отношения R и имеет место функциональная зависимость Х®А и Y ®А, то в отношении имеет место неполная функциональная зависимость. Если это условие не выполняется, то атрибут А функционально полно зависит от Х в отношении R.
Каждый непрерывный атрибут функционально полно зависит от первичного ключа.
Отношение во 2НФ может обладать аномалиями.
3НФ Если не существует в отношении R ключа Х, множества атрибутов Y и непервичного атрибута А таких, что справедливы функциональные зависимости Х®Y, Y®А.
Схема отношения находится в 3НФ, если она находится в 2НФ и каждый ее непервичный атрибут нетранзитивно зависит от первичного ключа.
Если в отношении нет многозначных зависимостей, то 3НФ снимаются все аномалии манипулирования.
4НФ Если в отношении присутствуют многозначные зависимости, то схема отношения должна находиться в 4НФ, чтобы не возникли снова аномалии.
Схема отношения R находится в 4 НФ, если из существования многозначной зависимости Х®®Y, где Y не является подмножеством Х, а объединение множеств Х*Y состоит не из всех атрибутов отношения R вытекает существование многофункциональной зависимости Х®А, для любых АÎR-Х*Y.
Нормализация отношений выполняется путем декомпозиции их схем.
Декомпозицией схемы отношения R = { А1, ……Аn} называется замена схемы совокупностью схем { R1,…… Rk}таких, что R1 È R2È….. È Rk = R
При этом не требуется, чтобы схемы Rj был непересекающимися.

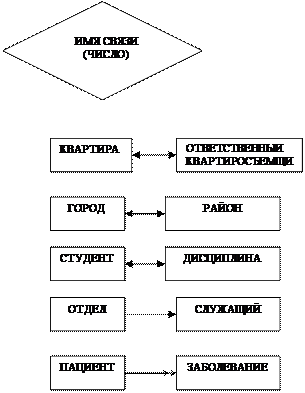 НАГРУЖЕННАЯ СВЯЗЬ
НАГРУЖЕННАЯ СВЯЗЬ







 X ® Y - зависимости нет.
X ® Y - зависимости нет.