Термин семантическая означает "смысловая", а сама семантика - это наука, устанавливающая отношения между символами и объектами, которые они обозначают, т.е. наука, определяющая смысл знаков. Семантическая сеть - это ориентированный граф, вершины которого - понятия, а дуги - отношения между ними. Характерной особенностью семантических сетей является обязательное наличие трех типов отношений: - класс - элемент класса; - свойство - значение; - пример элемента класса. Проблема поиска решения в базе знаний типа семантической сети сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, соответствующей поставленному вопросу. Основное преимущество этой модели - в соответствии современным представлениям об организации долговременной памяти человека. Недостаток модели - сложность поиска вывода на семантической сети. Для реализации семантических сетей существуют специальные сетевые языки, например NET и др. Широко известны экспертные системы, использующие семантические сети в качестве языка представления знаний - PROSPECTOR, CASNET, TORUS.
По форме описания знания подразделяются на:
Декларативные (факты) - это знания вида "А есть А". Декларативные знания подразделяются на объекты, классы объектов и отношения. Объект - это факт, который задается своим значением. Класс объектов - это имя, под которым объединяется конкретная совокупность объектов-фактов. Отношения - определяют связи между классами объектов и отдельными объектами, возникшие в рамках предметной области.
Процедурные - это знания вида "Если А, то В". К процедурным знаниям относят совокупности правил, которые показывают, как вывести новые отличительные особенности классов или отношения для объектов. В правилах используются все виды декларативных знаний, а также логические связки. При обработке правил следует отметить рекурсивность анализа отношений, т.е. одно правило вызывает глубинный поиск всех возможных вариантов объектов БЗ.
Граница между декларативными и процедурными знаниями очень подвижна, т.е. проектировщик может описать одно и то же как отношение или как правило.
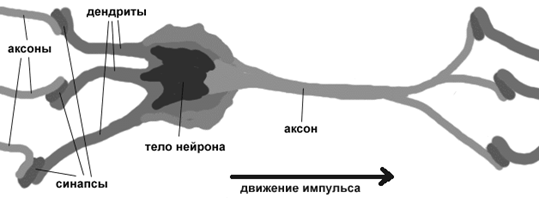
Нервная система и мозг человека состоят из нейронов, соединенных между собой нервными волокнами. Нервные волокна способны передавать электрические импульсы между нейронами. Все процессы передачи раздражений от нашей кожи, ушей и глаз к мозгу, процессы мышления и управления действиями - все это реализовано в живом организме как передача электрических импульсов между нейронами.
Рассмотрим строение биологического нейрона. Каждый нейрон имеет отростки нервных волокон двух типов - дендриты, по которым принимаются импульсы, и единственный аксон, по которому нейрон может передавать импульс. Аксон контактирует с дендритами других нейронов через специальные образования - синапсы, которые влияют на силу импульса.
Можно считать, что при прохождении синапса сила импульса меняется в определенное число раз, которое мы будем называть весом синапса. Импульсы, поступившие к нейрону одновременно по нескольким дендритам, суммируются. Если суммарный импульс превышает некоторый порог, нейрон возбуждается, формирует собственный импульс и передает его далее по аксону. Важно отметить, что веса синапсов могут изменяться со временем, а значит, меняется и поведение соответствующего нейрона.
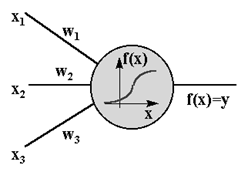
Нетрудно построить математическую модель описанного процесса. На рисунке изображена модель нейрона с тремя входами (дендритами), причем синапсы этих дендритов имеют веса w1, w2, w3. Пусть к синапсам поступают импульсы силы x1, x2, x3 соответственно, тогда после прохождения синапсов и дендритов к нейрону поступают импульсы w1x1, w2x2, w3x3. Нейрон преобразует полученный суммарный импульс x=w1x1+ w2x2+ w3x3 в соответствии с некоторой передаточной функцией f(x). Сила выходного импульса равна y=f(x)=f(w1x1+ w2x2+ w3x3).
Таким образом, нейрон полностью описывается своими весами wk и передаточной функцией f(x). Получив набор чисел (вектор) xk в качестве входов, нейрон выдает некоторое число y на выходе.
Что такое нейросеть Как работает нейросеть
Искусственная нейронная сеть (ИНС, нейросеть) - это набор нейронов, соединенных между собой. Как правило, передаточные функции всех нейронов в сети фиксированы, а веса являются параметрами сети и могут изменяться. Некоторые входы нейронов помечены как внешние входы сети, а некоторые выходы - как внешние выходы сети. Подавая любые числа на входы сети, мы получаем какой-то набор чисел на выходах сети. Таким образом, работа нейросети состоит в преобразовании входного вектора в выходной вектор, причем это преобразование задается весами сети.
Практически любую задачу можно свести к задаче, решаемой нейросетью. В этой таблице показано, каким образом следует сформулировать в терминах нейросети задачу распознавания рукописных букв.
Задача распознавания рукописных букв
Дано: растровое черно-белое изображение буквы размером 30x30 пикселов
Надо: определить, какая это буква (в алфавите 33 буквы)
Формулировка для нейросети
Дано: входной вектор из 900 двоичных символов (900=30x30)
Надо: построить нейросеть с 900 входами и 33 выходами, которые помечены буквами. Если на входе сети - изображение буквы "А", то максимальное значение выходного сигнала достигается на выходе "А". Аналогично сеть работает для всех 33 букв.
Поясним, зачем требуется выбирать выход с максимальным уровнем сигнала. Дело в том, что уровень выходного сигнала, как правило, может принимать любые значения из какого-то отрезка. Однако, в данной задаче нас интересует не аналоговый ответ, а всего лишь номер категории (номер буквы в алфавите). Поэтому используется следующий подход - каждой категории сопоставляется свой выход, а ответом сети считается та категория, на чьем выходе уровень сигнала максимален. В определенном смысле уровень сигнала на выходе "А" - это достоверность того, что на вход была подана рукописная буква "A".
Задачи, в которых нужно отнести входные данные к одной из известных категорий, называются задачами классификации. Изложенный подход - стандартный способ классификации с помощью нейронных сетей.
Как построить сеть
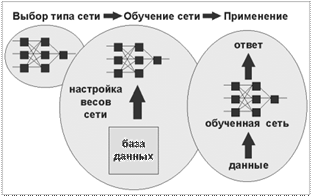
Теперь, когда стало ясно, что именно мы хотим построить, мы можем переходить к вопросу "как строить такую сеть". Этот вопрос решается в два этапа:
1. Выбор типа (архитектуры) сети.
2. Подбор весов (обучение) сети.
На первом этапе следует выбрать следующее:
какие нейроны мы хотим использовать (число входов, передаточные функции);
каким образом следует соединить их между собой;
что взять в качестве входов и выходов сети.
Эта задача на первый взгляд кажется необозримой, но, к счастью, нам необязательно придумывать нейросеть "с нуля" - существует несколько десятков различных нейросетевых архитектур, причем эффективность многих из них доказана математически. Наиболее популярные и изученные архитектуры - это многослойный перцептрон, нейросеть с общей регрессией, сети Кохонена и другие. Про все эти архитектуры скоро можно будет прочитать в специальной литеретуре.
На втором этапе нам следует "обучить" выбранную сеть, то есть подобрать такие значения ее весов, чтобы сеть работала нужным образом. Необученная сеть подобна ребенку - ее можно научить чему угодно. В используемых на практике нейросетях количество весов может составлять несколько десятков тысяч, поэтому обучение - действительно сложный процесс. Для многих архитектур разработаны специальные алгоритмы обучения, которые позволяют настроить веса сети определенным образом. Наиболее популярный из этих алгоритмов - метод обратного распространения ошибки (Error Back Propagation), используемый, например, для обучения перцептрона.
Обучение нейросети
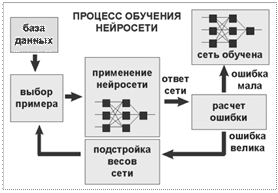
Обучить нейросеть - значит, сообщить ей, чего мы от нее добиваемся. Этот процесс очень похож на обучение ребенка алфавиту. Показав ребенку изображение буквы "А", мы спрашиваем его: "Какая это буква?" Если ответ неверен, мы сообщаем ребенку тот ответ, который мы хотели бы от него получить: "Это буква А". Ребенок запоминает этот пример вместе с верным ответом, то есть в его памяти происходят некоторые изменения в нужном направлении. Мы будем повторять процесс предъявления букв снова и снова до тех пор, когда все 33 буквы будут твердо запомнены. Такой процесс называют "обучение с учителем".
При обучении сети мы действуем совершенно аналогично. У нас имеется некоторая база данных, содержащая примеры (набор рукописных изображений букв). Предъявляя изображение буквы "А" на вход сети, мы получаем от нее некоторый ответ, не обязательно верный. Нам известен и верный (желаемый) ответ - в данном случае нам хотелось бы, чтобы на выходе с меткой "А" уровень сигнала был максимален. Обычно в качестве желаемого выхода в задаче классификации берут набор (1, 0, 0, ...), где 1 стоит на выходе с меткой "А", а 0 - на всех остальных выходах. Вычисляя разность между желаемым ответом и реальным ответом сети, мы получаем 33 числа - вектор ошибки. Алгоритм обратного распространения ошибки - это набор формул, который позволяет по вектору ошибки вычислить требуемые поправки для весов сети. Одну и ту же букву (а также различные изображения одной и той же буквы) мы можем предъявлять сети много раз. В этом смысле обучение скорее напоминает повторение упражнений в спорте - тренировку.
Оказывается, что после многократного предъявления примеров веса сети стабилизируются, причем сеть дает правильные ответы на все (или почти все) примеры из базы данных. В таком случае говорят, что "сеть выучила все примеры", " сеть обучена", или "сеть натренирована". В программных реализациях можно видеть, что в процессе обучения величина ошибки (сумма квадратов ошибок по всем выходам) постепенно уменьшается. Когда величина ошибки достигает нуля или приемлемого малого уровня, тренировку останавливают, а полученную сеть считают натренированной и готовой к применению на новых данных.
Важно отметить, что вся информация, которую сеть имеет о задаче, содержится в наборе примеров. Поэтому качество обучения сети напрямую зависит от количества примеров в обучающей выборке, а также от того, насколько полно эти примеры описывают данную задачу. Так, например, бессмысленно использовать сеть для предсказания финансового кризиса, если в обучающей выборке кризисов не представлено. Считается, что для полноценной тренировки требуется хотя бы несколько десятков (а лучше сотен) примеров.
Повторим еще раз, что обучение сети - сложный и наукоемкий процесс. Алгоритмы обучения имеют различные параметры и настройки, для управления которыми требуется понимание их влияния.