Наиболее известной компонентой является Microsoft Excel, в состав которой входят функции для построения различного вида моделей. Помимо этого имеется возможность отыскания оптимального решения при заданных ограничениях.
Open Office и т.д.
Lotus
Star Office
Microsoft Office
Стандартные офисные программные продукты
Существующие языки программирования безусловно позволяют осуществить построение модели любого вида и любой сложности. Однако для этого от экономиста (менеджера) требуются профессиональные знания и навыки программирования. В случае разработки собственного программного средства безусловно целесообразнее возложить исполнение этой задачи на профессионального программиста.
Универсальныеи специализированные языки программирования
Информационная поддержка процессов моделирования и управления
Информационная поддержка процессов моделирования и управления может осуществляться с использованием самых разнообразных программных средств. Назовем и охарактеризуем некоторые из них:
· Универсальные и специализированные языки программирования
· Стандартные офисные программные продукты
· Системы компьютерной математики
· Системы управления проектами
· CASE-технологии
· Специализированные статистические пакеты
К наиболее известным программным продуктам позволяющим моделировать процессы управления можно отнести:
В стандартном наборе функций Excel имеются функции, которые позволяют осуществить построение моделей с использованием метода среднеквадратического отклонения на основании следующих зависимостей:
· линейного приближения
· экспоненциального приближения
В состав функций, позволяющих осуществить построение и анализ по методу линейного приближения, относятся:
ЛИНЕЙН
ТЕНДЕНЦИЯ
ПРЕДСКАЗ
Рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива.
Уравнение для прямой линии имеет следующий вид: y = m*x + b или y = m1*x1 + m2*x2 + ... mn*xn+ b (в случае нескольких диапазонов значений x), где зависимое значение y — функция независимого значения x, значения m — коэффициенты, соответствующие каждой независимой переменной x, а b — постоянная. Заметим, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив {mn; mn-1; ...; m1; b}. ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Известные_значения_y — множество значений y, которые уже известны для соотношения y = m*x + b.
·
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
·
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x — необязательное множество значений x, которые уже известны для соотношения y = m*x + b.
·
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то известные_значения_y и известные_значения_x могут иметь любую форму, при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец).
·
Если известные_значения_x опущены, то предполагается, что это массив {1;2;3;...} такого же размера, как и известные_значения_y.
Константа — логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
·
Если константа имеет значение ИСТИНА или опущено, то b вычисляется обычным образом.
·
Если аргумент константа имеет значение ЛОЖЬ, то b полагается равным 0 и значения m подбираются так, чтобы выполнялось соотношение y = m*x.
Статистика — логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
·
Если аргумент статистика имеет значение ИСТИНА, то функция ЛИНЕЙН возвращает дополнительную регрессионную статистику, так что возвращаемый массив будет иметь вид:
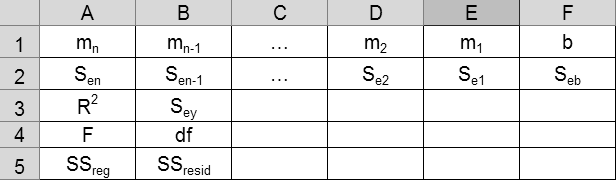
{mn; mn-1; ...; m1; b: Sen; Sen-1; ...; Se1; Seb: R2; Sey: F; df: SSreg; SSresid}.
·
Если аргумент статистика имеет значение ЛОЖЬ или опущен, то функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.
Дополнительная регрессионная статистика:
Величина
Описание
Se1, Se2,..., Sen
Стандартные значения ошибок для коэффициентов m1,m2,...,mn.
Seb
Стандартное значение ошибки для постоянной b (Seb = #Н/Д, если константа имеет значение ЛОЖЬ).
R2
Коэффициент детерминированности. Сравниваются фактические значения y и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т. е. нет различия между фактическим и оценочным значениями y. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений y.
Sey
Стандартная ошибка для оценки y.
F
F-статистика, или F-наблюдаемое значение. F-статистика используется для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет.
df
Степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели нужно сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН.
SSreg
Регрессионная сумма квадратов.
SSresid
Остаточная сумма квадратов.
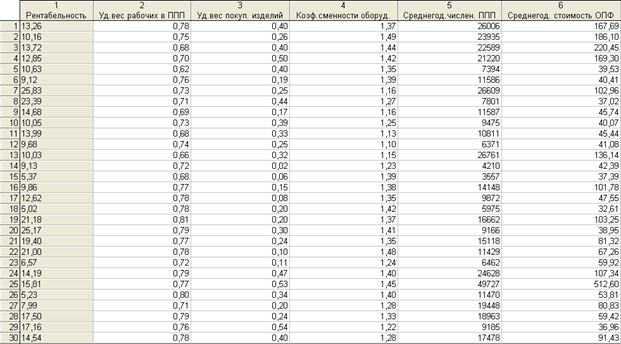
Построим модель зависимости рентабельности работы предприятия (y) от удельного веса рабочих в структуре персонала (x1), удельного веса покупных изделий (x2), коэффициента сменности оборудования (x3), среднегодовой численности персонала (x4), среднегодовой стоимости основных производственных фондов (x5). Предположим линейную функциональную зависимость вида
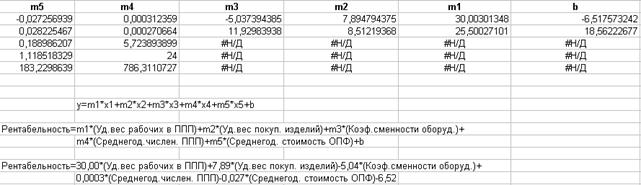
y= m1x1+ m2x2+ m3x3+ m4x4+ m5x5+b
Заметим, что функцию ЛИНЕЙН в этом примере необходимо ввести как формулу массива, предварительно выделив диапазон размерностью 5*(n+1), где n-количество независимых переменных X.
Для нашего примера размерность массива будет 5*6, так как n=5. Для ввода формулы массива необходимо одновременно активизировать клавиши CTRL+SHIFT+ENTER. В результате расчета получаем следующие данные:
На основании полученной модели выполним прогноз рентабельности для следующих данных:
удельный вес рабочих в структуре персонала (x1) = 0,67;
удельный вес покупных изделий (x2) = 0,41;
коэффициент сменности оборудования (x3) = 1,15;
среднегодовая численность персонала (x4) = 14100;
среднегодовая стоимость основных производственных фондов (x5) = 103,50.
Возвращает значения в соответствии с линейным трендом. Аппроксимирует прямой линией (по методу наименьших квадратов) массивы известные_значения_y и известные_значения_x. Возвращает значения y, в соответствии с этой прямой для заданного массива новые_значения_x.
Известные_значения_y — множество значений y, которые уже известны для соотношения y = m*x + b.
·
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
·
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x — необязательное множество значений x, которые уже известны для соотношения y = m*x + b.
·
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то известные_значения_y и известные_значения_x могут иметь любую форму, при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец).
·
Если известные_значения_x опущены, то предполагается, что это массив {1;2;3;...} такого же размера, как и известные_значения_y.
Новые_значения_x — новые значения x, для которых ТЕНДЕНЦИЯ возвращает соответствующие значения y.
·
Новые_значения_x должны содержать столбец (или строку) для каждой независимой переменной, как и известные_значения_x. Таким образом, если известные_значения_y — это один столбец, то известные_значения_x и новые_значения_x должны иметь такое же количество столбцов. Если известные_значения_y — это одна строка, то известные_значения_x и новые_значения_x должны иметь такое же количество строк.
·
Если новые_значения_x опущены, то предполагается, что они совпадают с известные_значения_x.
·
Если опущены оба массива известные_значения_x и новые_значения_x, то предполагается, что это массив {1;2;3;...} такого же размера, что и известные_значения_y.
Константа — логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
·
Если константа имеет значение ИСТИНА или опущено, то b вычисляется обычным образом.
·
Если константа имеет значение ЛОЖЬ, то b полагается равным 0, и значения m подбираются таким образом, чтобы выполнялось соотношение y = m*x.