В соответствии с рис. 19.6 к каждой ЛЗП (входу системы прерывания) может быть подключено множество запросчиков ИЗП, объединенных по схеме монтажное "или". Сигнал "подтверждение прерывания" распространяется по цепочке ИЗП, подключенных к одной ЛЗП. Распространение этого сигнала блокируется ИЗПj, выставившим запрос. Получив сигнал "Подтверждение прерывания", ИЗПj выставляет на ШД код адреса вектора прерывания. Таким образом, приоритет подключенных к одной ЛЗП устройств определяется положением ИЗП в цепочке распространения сигнала "Подтверждение прерывания". Это исключает необходимость выполнения процедуры поиска запроса с максимальным приоритетом среди ИЗП, подключенных к одной ЛЗП.
Если ЛЗП несколько, что обычно имеет место в реальных системах прерывания цепочечной структуры, в контроллере прерывания выполняется процедура поиска возбужденной ЛЗП с максимальным приоритетом, которая аналогична процедуре поиска запроса с максимальным приоритетом в системе радиальной структуры.
На основании вышеизложенного можно сформулировать последовательность основных операций по реализации процедуры перехода к прерывающей программе. При этом предполагается, что состояние возбужденных ЛЗП фиксируется в разрядах РгЗП, несмотря на то, что при потенциальном способе задания сигналов запросов прерывания его наличие не обязательно.
1. При поступлении любого запроса (или нескольких запросов) в РгЗП формируется сигнал ОСП. Этот сигнал транслируется в процессор, а также инициирует процедуру поиска возбужденной ЛЗП с максимальным приоритетом, результатом выполнения которой является выбор линии распространения сигнала "Подтверждение прерывания" (цепочки ИЗП).
2. Процессор заканчивает выполнение текущей команды и посылает в контроллер сигнал "Подтверждение прерывания" (см. рис. 19.6).
3. Получив этот сигнал, контроллер транслирует его на выбранную цепочку ИЗП.
4. ИЗП, имеющий максимальный приоритет среди устройств, выставивших запрос на выбранную ЛЗП, блокирует дальнейшее распространение сигнала "Подтверждение прерывания" и выставляет на ШД код адреса своего вектора прерывания.
5. Процессор считывает с ШД код адреса вектора прерывания, сохраняет в стеке вектор текущего состояния прерываемой программы (в простейшем случае только содержимое счетчика адреса команд) и осуществляет переход к прерывающей программе. Если вектор текущего состояния прерываемой программы автоматически сохраняется только частично, то операции по сохранению его остальных элементов возлагаются на обработчик (рис. 19.2, интервал времени tз).
В простых системах прерывания цепочечного типа может присутствовать только одна ЛЗП. В этом случае отпадает необходимость выполнения процедуры поиска ЛЗП с максимальным приоритетом, которая, даже если выполняется аппаратными средствами, требует сравнительно больших временных затрат. Отпадает необходимость и в контроллере прерываний, поскольку сигнал с ЛЗП может непосредственно поступать на соответствующий вход процессора вместо сигнала ОСП. Такие системы прерывания являются наиболее динамичными даже при достаточно большом количестве ИЗП.
Уже неоднократно отмечалось, что обязательным компонентом процедуры перехода к обработчику является операция обнаружения наиболее приоритетного запроса прерывания (радиальная структура) или ЛЗП (цепочечная структура), которая в большинстве случаев выполняется в контроллере прерываний. Тем самым реализуется система приоритетных соотношений между ИЗП или цепочками ИЗП. Эта система приоритетных соотношений может быть либо фиксированной, либо изменяться программным путем в процессе обработки задачи. В соответствии с этим различаются системы прерываний с фиксированными приоритетами и с программно-управляемыми. Большинство контроллеров прерываний являются программируемыми и могут реализовывать систему как фиксированных, так и программно-управляемых приоритетов. Ниже рассматриваются некоторые варианты реализации процедур установления приоритетных соотношений обоих типов.
19.3.1. Реализация фиксированных приоритетов
Рассмотрим только простейший случай установки приоритетных соотношений, состоящий в том, что уровень приоритета определяется порядком присоединения ЛЗП к входам системы прерывания, т.е. разрядам РгЗП. Пусть максимальный приоритет имеет вход с минимальным номером. В этом случае поиск ЛЗП с максимальным приоритетом сводится к поиску крайнего левого поднятого флажка в РгЗП. Процедуру поиска можно реализовать как программными, так и аппаратными средствами. В ряде случае эту процедуру называют соответственно программным или аппаратным полингом.
· Программный опрос РгЗП
Начало поиска инициируется сигналом ОСП. Программа поиска состоит из последовательности условных операторов, анализирующих разряды РгЗП, начиная с младшего. При обнаружении поднятого флажка управление передается обработчику. Если сигнал ОСП после выполнения обработчика не снимается, происходит повторный анализ разрядов РгЗП и поиск ЗП с максимальным приоритетом среди ЗП, оставшихся не обслуженными.
Программный полинг требует минимальных аппаратных затрат, поскольку выполняется процессором, а в качестве РгЗП можно использовать какой-либо управляемый регистр (т.е. БИС контроллера прерываний не требуется). Однако существенным недостатком метода является большое время поиска ЗП, особенно при большом количестве ЛЗП.
Для уменьшения времени поиска ЗП с максимальным приоритетом используют аппаратную реализацию алгоритма. Ниже рассматривается возможная структура такого устройства.
· Аппаратный циклический опрос РгЗП
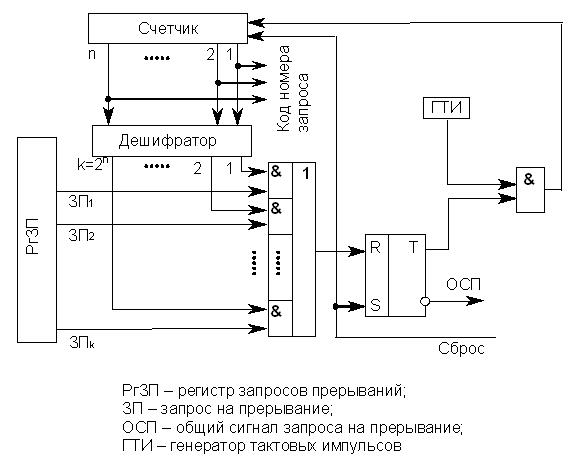
Структурная схема устройства, реализующего аппаратный циклический опрос разрядов РгЗП, представлена на рис. 19.7. Устройство аппаратного полинга входит в состав контроллера прерываний и функционирует следующим образом.
Рис.19.7. Схема устройства циклического опроса РгЗП
Опрос k линий запросов прерываний производится с помощью n-разрядного счетчика (2n ≥ k), на вход которого поступают импульсы от ГТИ. Поиск начинается со сброса счетчика и установки T в состояние 0. При этом импульсы от ГТИ через схему & начинают поступать на вход счетчика. На выходах дешифратора, начиная с первого, последовательно появляются единицы. Это происходит до тех пор, пока не попадается возбужденная линия запроса прерывания, на которой тоже выставлена 1. В этом случае триггер T перебрасывается в состояние 1 и в процессор идет сигнал ОСП. Кроме того, прекращается поступление импульсов ГТИ на вход счетчика, т.е. завершается просмотр входов системы прерывания. Содержимое счетчика – код номера запроса (старшего по приоритету) используется для формирования адреса соответствующего вектора прерывания. После передачи управления обработчику счетчик и триггер сбрасываются в 0 сигналом "Сброс", и процедура опроса разрядов РгЗП возобновляется.
Рассмотренный метод опроса разрядов РгЗП существенно быстрее программного, но при большом числе ЛЗП время реакции системы оказывается достаточно большим.
· Аппаратный однотактный опрос РгЗП
Структурная схема устройства, реализующего аппаратный однотактный опрос разрядов РгЗП, представлена на рис. 19.8.
Рис.19.8. Схема устройства однотактного опроса РгЗП
Схемы подобного типа принято называть дейзи-цепочками, и в настоящее время они получили очень широкое распространение в различных устройствах ЭВМ. Схема функционирует следующим образом. Процедура поиска запроса с максимальным приоритетом инициируется сигналом "Приоритет", поступающим на цепочку последовательно соединенных схем &. При отсутствии запросов этот сигнал пройдет насквозь всю цепочку и сигнал ОСП не сформируется. (По-прежнему считаем, что максимальный приоритет имеет запрос с минимальным номером.) Пусть выставлен ЗП2. В этом случае распространение сигнала "Приоритет" блокируется &2', поскольку y2 = 1. Кроме того, при обнаружении любого ЗПi формируется сигнал ОСП, поступающий в процессор, а шифратор по сигналу y2 = 1 формирует код адреса второго (в общем случае i-го) вектора прерывания.
По сигналу процессора "Подтверждение прерывания" этот код передается в процессор, и происходит вызов соответствующего обработчика.
· Цепочка приоритетов
Как уже отмечалось, в цепочечной системе прерывания используется двухуровневая система приоритетов. Это приоритет ЛЗП и приоритет конкретного устройства в цепочке ИЗП, относящихся к одной ЛЗП. Приоритет ЛЗП определяется в процессе выполнения процедуры поиска наиболее приоритетного запроса (ЛЗП) в контроллере системы прерываний как радиальной, так и цепочечной структуры. Эта процедура описана выше. Приоритет устройства в цепочке ИЗП является фиксированным и определяется положением устройства на линии распространения сигнала ПП, т.е. ИЗП фактически образуют дейзи-цепочку. Таким образом, устройство, располагающееся в слоте, ближайшем к контроллеру прерываний, автоматически получает наивысший приоритет. Приоритет остальных устройств в цепочке убывает по мере удаления их слотов от контроллера прерываний. Приоритет устройства в такой системе прерывания можно изменить только путем перемещения устройства по линии распространения сигнала ПП, т.е. только перестановкой в другой слот.
При наличии нескольких наиболее приоритетных устройств такое распределение приоритетов становится недостатком, поэтому обычно используется несколько ЛЗП (4-8 линий). Наиболее приоритетные устройства в этом случае располагаются на всех ЛЗП в слотах, ближайших к контроллеру прерываний.
Во многих случаях приоритеты между прерывающими программами не могут быть зафиксированы раз и навсегда, т.е. требуется иметь возможность программно управлять приоритетами.
Существуют три основных метода реализации в ЭВМ систем программно-управляемых приоритетов – порог прерывания, маска прерывания и смена приоритетов. Первый используется, в основном, в системах прерывания микро-ЭВМ с простыми процессорами, второй – в более сложных ЭВМ с мощными процессорами, третий используется в вычислительных системах всех классов. В ряде случаев все три метода используются совместно. Ниже коротко рассматривается суть этих методов, позволяющих программным путем изменить дисциплину обслуживания ИЗП.
· Порог прерывания
Этот способ позволяет в ходе вычислительного процесса программным путем изменять уровень приоритета процессора (а следовательно, и обрабатываемой в данный момент программы) относительно приоритетов запросов источников прерывания (в основном периферийных устройств). Таким образом, устанавливается минимальный уровень приоритета запросов, которым разрешено прерывать программу, выполняемую процессором.
Порог прерывания задается командой программы, устанавливающей в регистре порога прерывания контроллера код порога прерывания. Вернемся к рис. 19.8, к его части, изображенной пунктиром. Ранее рассматривалось, как происходит выделение кода запроса с максимальным приоритетом. Затем этот код сравнивают с порогом прерывания (на компараторе), и, если он оказывается выше порога, вырабатывается сигнал ОСП и начинается процедура прерывания.
· Маска прерывания
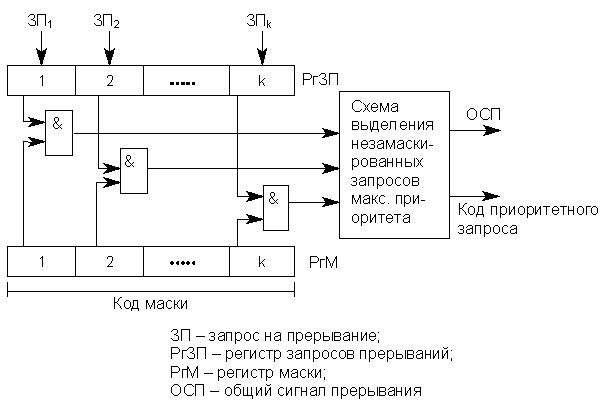
Маска прерывания представляет двоичный код, разряды которого поставлены в соответствие запросам или классам прерываний (рис. 19.9).
Рис.19.9. Схема реализации управления приоритетами с помощью маски прерывания
Маска загружается командой программы в регистр маски контроллера (РгМ). Состояние 1 в данном разряде маски разрешает, а 0 запрещает (маскирует) прерывание текущей программы соответствующим запросом. Таким образом, программа, меняя маску в РгМ, может устанавливать произвольные приоритетные соотношения между прерывающими программами без перекоммутаций ЛЗП. Каждая прерывающая программа может устанавливать свою маску. При формировании маски 1 устанавливается в разряды, соответствующие запросам (прерывающей программе) с более высоким, чем у данной программы, приоритетом.
На изображенной схеме элементы & выделяют незамаскированные запросы прерываний, из которых специальная схема, аналогичная дейзи-цепочке, выделяет наиболее приоритетный и формирует код его номера.
С замаскированным запросом поступают в зависимости от того, какой причиной он вызван: или он игнорируется, или запоминается с тем, чтобы осуществить затребованные действия, когда запрет будет снят.
· Смена приоритетов
В начале п. 19.3.1 было оговорено, что разряды РгЗП, а следовательно, и входы в систему прерывания имеют фиксированные приоритеты, причем максимальный приоритет имеет вход с минимальным номером. Между тем в большинстве контроллеров прерываний имеется возможность программным путем изменять приоритеты входов, т.е. изменять дисциплину обслуживания ИЗП. Существует относительно небольшое количество используемых на практике дисциплин обслуживания. Ниже рассмотрен один из наиболее распространенных вариантов дисциплины обслуживания – режим кругового (циклического) приоритета.
Этот режим характерен для таких применений, в которых ИЗП (цепочки ИЗП) имеют примерно одинаковый приоритет и ни одному из них нельзя отдать предпочтение. В то же время нормальное функционирование контроллера возможно только при наличии системы приоритетов. Выравнивание приоритетов ИЗП в этом случае осуществляется следующим образом.
Каждому входу контроллера (разряду РгЗП) при инициализации присваивается соответствующий приоритет. После поступления запроса и его обслуживания (выполнения соответствующего обработчика) приоритеты входов контроллера автоматически изменяются в круговом порядке таким образом, что последний обслуженный вход получает низший приоритет. Например, контроллер прерываний имеет 4 входа, приоритеты которых после инициализации убывают в следующем порядке: ЛЗП1, ЛЗП2, ЛЗП3, ЛЗП4. Пусть в текущий момент времени завершено обслуживание ИЗП2 (радиальная структура). После этого приоритеты входов автоматически будут распределены в следующем порядке: ЛЗП3, ЛЗП4, ЛЗП1, ЛЗП2. После обслуживания очередного ИЗП произойдет аналогичная смена приоритетов. Возможны и другие схемы выравнивания приоритетов ИЗП.
Одной из модификаций режима кругового приоритета является режим адресуемого приоритета. Этот режим аналогичен рассмотренному выше, но допускает программное определение входа контроллера, которому назначен низший или высший приоритет.
Следует иметь в виду, что современные контроллеры прерываний в большинстве случаев содержат все или почти все механизмы реализации фиксированных и программно-управляемых приоритетов, рассмотренные выше. Набор используемых дисциплин обслуживания запросов прерывания зависит от разработчиков вычислительной системы, а конкретный режим обслуживания задается программным путем.
19.4. Контрольные вопросы
1. Принципы организации систем прерывания программ.
2. Состояние программы и вектор прерывания.
3. Основные характеристики систем прерывания.
4. Определение числа уровней прерывания.
5. Радиальная структура системы прерывания.
6. Цепочечьная структура системы прерывания.
7. Типы приоритетов прерываний.
8. Процедура поллинга.
9. Схема устройства однотактного опроса регистра запросов прерывания. Дейзи-цепочки.
11. Схема реализации управления приоритетами с помощью маски прерывания.
Лекция 20. Принципы организации систем прямого доступа в память
Программно-управляемый ВВ между ОП и ПУ во многих случаях является далеко не самым оптимальным, а иногда вообще невозможным. Причин тому несколько. Рассмотрим очень коротко основные из них.
· При программно-управляемом ВВ процессор "отвлекается" от выполнения основной программы решения задачи. Операции ВВ достаточно просты, чтобы эффективно загружать логически сложную быстродействующую аппаратуру процессора. В результате при использовании программно-управляемого ВВ снижается производительность ЭВМ в целом.
· При пересылке любой единицы данных (байт, слово) процессор выполняет достаточно много команд, чтобы обеспечить буферизацию данных, преобразование форматов, подсчет количества переданных единиц данных, формирование адресов памяти и регистров ПУ. В результате скорость передачи данных при программно-управляемом ВВ (т.е. через процессор) может оказаться недостаточной для работы с высокоскоростными ПУ, например с накопителями на жестких дисках, видеосистемами, быстродействующими аналого-цифровыми и цифро-аналоговыми преобразователями различного назначения, и т.д.
· Большинство современных сложных ПУ, таких как видеосистемы, сетевые карты, жесткие диски и т.д., осуществляют обмен с ОП целыми блоками информации. В этом случае перечисленные выше непроизводительные временные затраты процессора становятся особенно существенными.
· Обмен в режиме прерывания, несмотря на все свои достоинства, требует еще помимо перечисленных выше непроизводительных временных затрат время на сохранение вектора состояния текущей программы в стеке и его последующего восстановления. Кроме того, прерывание в большинстве случаев возможно только после завершения текущей команды.
Несмотря на широкое использование программно-управляемого ВВ, для ускорения операций обмена данными между ОП и ПУ и разгрузки процессора от управления этими операциями в современных ЭВМ используется специальный режим обмена, получивший название режим прямого доступа к памяти или просто прямой доступ к памяти (ПДП). В англоязычной литературе – Direct Memory Access (DMA). Ниже, в зависимости от контекста излагаемого материала, будут употребляться обе аббревиатуры – ПДП и DMA.
Прямым доступом к памяти называется режим, при котором обмен данными между ОП и регистрами ПУ осуществляется без участия центрального процессора за счет специальных, внешних по отношению к нему, электронных схем.
Введение режима ПДП (реализация каналов ПДП) всегда усложняет аппаратную часть ЭВМ, однако позволяет повысить скорость выполнения операций обмена ОП-ПУ, разгружает центральный процессор от обслуживания операций ВВ, повышает общую производительность ЭВМ. При наличии кэш-памяти достаточного объема режим ПДП в ряде случаев позволяет реализовать параллельное выполнение операций обмена и обработку команд текущей программы процессором, что также повышает общую производительность ЭВМ. Более того, наличие механизма прямого доступа к памяти позволяет поддерживать многопроцессорность вычислительной системы. На последнем моменте необходимо остановиться более подробно.
Дело в том, что термин ПДП (как и DMA), используемый при изложении материала настоящего раздела, в общем случае не совсем точно отражает суть процессов, происходящих в ЭВМ. Точнее, прямой доступ к памяти (к ОП) является только частным случаем организации процедур доступа к системной магистрали со стороны множества устройств, в том числе и процессоров. Под доступом к системной магистрали понимается возможность какого-либо устройства, имеющего соответствующее аппаратно-программное обеспечение (ведущее устройство, интеллектуальное устройство магистрали), занимать на какое-то время системную магистраль и полностью управлять ею, вырабатывая все необходимые управляющие сигналы. При этом могут осуществляться связи не только ОП-ПУ, но и ПУ-ПУ. Между тем смысл понятия "память" можно расширить и понимать под памятью не только ОП, но и адресуемые регистры ПУ. В этом случае использование термина ПДП (как и DMA) будет вполне корректно.
Следует иметь в виду, что термин "периферийное устройство (ПУ)" здесь используется достаточно условно. В англоязычной литературе ведущее устройство магистрали, инициирующее обмен, принято называть master. Устройство, к которому обращается master, является подчиненным, и его принято называть slave. Таким образом, более правильно говорить о реализации связей master-slave (M-S), а не ПУ-ПУ или ОП-ПУ. Мастером может быть только интеллектуальное устройство, имеющее средства управления магистралью (СУМ), которые, как минимум, должны "уметь" формировать и модифицировать адреса обращения, вести контроль за размером переданного блока информации и генерировать управляющие сигналы магистрали. Между тем в зависимости от текущего состояния вычислительного процесса одно и то же интеллектуальное устройство магистрали может выступать и как master, и как slave. Устройства магистрали, не имеющие СУМ, всегда являются подчиненными, т.е. slave.
Естественно, что предоставление магистрали в распоряжение того или иного устройства (захват магистрали) может происходить только на приоритетной основе. Эта процедура получила название арбитраж магистрали, а устройство, ее реализующее, – арбитр магистрали. В ряде случаев арбитр может строиться как отдельное устройство, размещенное на системной магистрали. В других случаях арбитраж магистрали выполняет сам процессор. Наличие процедуры арбитража позволяет размещать на системной магистрали несколько интеллектуальных устройств, в том числе и процессоров. В соответствии с принятой дисциплиной обслуживания (арбитража) каждое из них будет получать в свое распоряжение системную магистраль и устанавливать связи как с ОП, так и с регистрами других устройств магистрали. Следует отметить при этом, что в процедуре арбитража всегда предусматриваются средства, предотвращающие монопольный захват магистрали одним устройством. Часть этих средств может быть сосредоточена в арбитре, другая часть может быть распределена между устройствами магистрали, использующими режим ПДП.
20.1. Способы организации доступа к системной магистрали
Конкретные варианты процедур доступа ведущих устройств к магистрали (организации каналов ПДП) в различных ЭВМ очень разнообразны. Между тем существуют некоторые общие принципы их реализации. В общем случае для устройств, использующих ПДП (DMA), выделяют два основных принципа организации доступа, в соответствии с которыми выделяют два типа систем ПДП (DMA).
Пассивный доступ или slave DMA. При этом способе доступа все устройства, использующие режим DMA, являются slave и обслуживаются одним специальным контроллером DMA (ПДП), размещенным на системной магистрали, т.е. одним ведущим устройством, – master. Такой способ доступа позволяет реализовать только связи ПУ-ОП. Контроллер DMA включает в себя арбитр магистрали и соответствующие СУМ. В этом случае ПУ играют пассивную роль и осуществляют обмен с ОП по сигналам, формируемым контроллером DMA, т.е. аналогично тому, как это происходит при обмене через процессор.
Как уже отмечалось выше, контроллер DMA обслуживает несколько ПУ, т.е. поддерживает несколько каналов ПДП. Перед началом обмена контроллер должен быть инициализирован. Для этого в его регистры необходимо загрузить начальный адрес области ОП, с которой ведется обмен, размер передаваемого блока информации для каждого канала, направление и режим передачи, дисциплину арбитража. В общем случае инициализация контроллера может осуществляться по мере необходимости (многократно) в процессе обработки текущей программы. Однако установка дисциплины арбитража в абсолютном большинстве случаев осуществляется один раз, при запуске вычислительной системы на решение конкретной задачи.
Таким образом, slave DMA не требует существенного усложнения аппаратуры устройств магистрали, а следовательно, и увеличения их стоимости. Каждое устройство, использующее такой режим обмена, должно иметь только аппаратуру формирования сигнала запроса ПДП (запросчик). При этом контроллер DMA является достаточно сложным и дорогим устройством, которое можно считать сопроцессором ввода/вывода, разгружающим центральный процессор от рутинных операций обмена (т.е. контроллер ПДП является очень упрощенным вариантом канальных процессоров мэйнфреймов).
Исторически системы slave DMA появились первыми. В частности, система ПДП такого типа использовалась первоначально на магистрали ISA в компьютерах PC/XT фирмы IBM. Многочисленные варианты систем slave DMA используются и в настоящее время в универсальных и управляющих ЭВМ самой разной архитектуры, назначения и производительности.
Активный доступ, или bus master DMA. При этом способе доступа предполагается, что устройства, использующие режим DMA, имеют программно-аппаратные средства, способные управлять магистралью (осуществлять прямое управление магистралью, или bus mastering), а следовательно, и реализовывать любые связи типа master-slave (M-S). Такие устройства магистрали могут выступать как master, поэтому единый контроллер DMA отсутствует. Остается только арбитр магистрали, который по определенной дисциплине предоставляет магистраль в распоряжение того или иного устройства. Арбитр может быть выполнен как отдельное устройство, размещенное на магистрали, либо арбитражем магистрали может заниматься процессор. В современных IBM PC процедуры арбитража магистрали включены в функции чипсета. При наличии нескольких процессоров арбитром может быть назначен один из них.
Следует иметь в виду, что любое современное интеллектуальное устройство управляется процессором (процессорами), находящимся на системной магистрали и имеющим собственную шину расширения. Такое устройство фактически является специализированной микро-ЭВМ, функционирующей по программе, обычно хранящейся в собственном ПЗУ. Этим оно, в сущности, только и отличается от "центрального процессора (ЦП)", также находящегося на системной магистрали и обрабатывающего команды текущей программы, хранящейся в ОП или системном ПЗУ. Такой подход позволяет рассматривать "ЦП" как одно из интеллектуальных устройств магистрали, причем "ЦП" может быть несколько. Исходя из этого, в вычислительных системах, использующих bus mastering, можно говорить о множестве интеллектуальных устройств, приоритеты которых на использование системной магистрали для обмена (захват магистрали) определяются только дисциплиной обслуживания, загруженной в арбитр при инициализации, т.е. можно говорить о многопроцессорных вычислительных системах.
Таким образом, bus master DMA требует существенного усложнения устройств магистрали (наличие СУМ, более сложный запросчик), а следовательно, и увеличения их стоимости. Однако он дает возможность ускорить процессы обмена, особенно в многозадачном режиме, и реализовать многопроцессорные варианты вычислительных систем, имеющих магистрально-модульную архитектуру.
Примером устройств с активным DMA являются контроллеры АТА (AT Attachment for Disk Drivers), расположенные в современных IBM PC на магистрали PCI, в частном случае контроллеры IDE. Активный DMA использует хост-адаптер шины SCSI (Small Computer System Interface), связывающий шину с какой-либо внутренней магистралью компьютера, а также контроллеры графических систем и средства их подключения, например порт AGP (Accelerated Graphic Port) и ряд других устройств. Примером устройств, использующих только bus master DMA (bus mastering), являются устройства вычислительных систем, построенных на базе магистрали VME (Versa Module Eurocard).
Следует отметить, что в реальных вычислительных системах иногда используют оба варианта систем DMA одновременно (для разных устройств магистрали). При этом контроллер может поддерживать несколько каналов DMA и работать в комбинированном режиме. Для одних устройств магистрали (slave) он может выполнять функции контроллера DMA, а для других устройств (master) он являются только арбитром магистрали. Именно такой вариант функционирования системы DMA был реализован в PC/AT фирмы IBM.
20.2. Возможные структуры систем ПДП
Конкретные технические реализации систем ПДП имеют множество вариантов. Они зависят от типа системной магистрали, архитектуры ЭВМ в целом, типа используемого процессора, целевого назначения ЭВМ, количества устройств на магистрали и т.д. В то же время они являются сложными комбинациями небольшого количества базовых структур систем ПДП. Ниже рассматриваются две основные базовые структуры – радиальная и цепочечная.
Радиальная структура
Упрощенные варианты обобщенных структур систем ПДП радиального типа представлены на рис. 20.1.
Характерной особенностью радиальной структуры является то, что каждый ИЗПД (в частном случае ПУ) подключен к отдельному входу контроллера ПДП (рис. 20.1, а) или арбитра (рис. 20.1, б). Отличие двух структур состоит в том, что в случае slave DMA для подключения ИЗПД достаточно одной линии ЛЗПД, по которой устройство выставляет запрос на обслуживание. В системе bus master DMA для подключения устройства к арбитру необходимы, как минимум, три линии – ЛЗПД, ЛПЗ и ЛРПД, которые можно назвать шиной арбитража (ШАр), имеющей собственный вход в арбитр. Каждый вход (в контроллер, в арбитр) обладает определенным уровнем приоритета. Число подключаемых ИЗПД определяется числом входов в контроллер или арбитр.