Обучаемые системы, естественные или искусственные, получая новую информацию, модифицируют свои внутренние представления, для того чтобы более эффективно отвечать на воздействия внешней среды. Наиболее часто такие системы строятся на основе нейронных сетей. Мы не будем касаться этих вопросов, так как они требуют более детального и специального рассмотрения и далее в этой книге не используются.
В университете Торонто был реализован ряд так называемых процедуральных СС. Эти системы объединят дефинициональные сети для определения классов, логические сети для фактов и состояний и процедуры подобные методам объектно-ориентированного программирования [44, 45].
Широко известные сети Петри также можно рассматривать как исполняемые сети, в которых сочетается передача маркера и процедуры.
3.1.2.5. Обучаемые сети
3.1.2.6. Гибридные сети
Существует достаточно большое количество вариантов гибридных СС, сочетающих в себе представления, описанные выше.
Так, например, модель распределенных СС (partitioned semantic net) предусматривает разделение общей сети на модули, где один или более модулей являются подмножествами других модулей. Такая структура упрощает логический вывод и экономит время при построении и анализе иерархических систем[46]. Модули в разделенной СС связываются между собой отношением иерархической подстановки.
Формализм неоднородных семантических сетей (НСС) развивается в работах Г.С. Осипова [47, 48, 49, 50]. Неоднородная семантическая сеть определяется как структура вида:
W = < D, S, Д, R, F > ,
где S – множество имен объектов, R – семейство отношений на SxS, D – семейство множеств { Dl, Dm, ... , Dn }, где каждое множество Di называется множеством атрибутов, а каждому имени s Î S ставится в соответствие некоторое множество DÎД кортежей из одного из декартовых произведений Dk = Dl x Dm x ... x Dnнекоторых множеств из D, называемое экстенсионалом или объемом объекта с именем S. Пара e = < S, D > называется событием с именем S и экстенсионалом (множеством экземпляров) D. Каждый кортеж d Î D представляет единичное понятие, т.е. понятие, соотнесенное с единичным именем.
Система программирования, поддерживающая формализм НСС разработана и реализована в Институте программных систем Российской Академии Наук и обеспечивает поддержку множества типов отношений на объектах базы знаний, каждый из которых может представлять события и объекты действительности. Система предоставляет возможность введения различных механизмов рассуждений об объектах и их совокупностях. Синтаксическая составляющая формализма НСС имеет алгебраическую интерпретацию и позволяет легко вводить различные вычислительные процедуры, расширяющие моделирующие способности базы знаний и превращающие ее в гибридную интегрированную интеллектуальную систему.
Определенный интерес в этом контексте представляет рассмотрение языка UML (Unified Modeling Language), весьма широко известного в настоящее время [51].
Хотя UML обычно не рассматривается как СС, его структуры можно классифицировать в соответствии с категориями семантических сетей, обсуждаемых выше.
Основу UML составляет дефинициональная сеть для определения объектных типов. Она включает такие характеристики как связи тип-подтип, связи тип-экземпляр, атрибуты служат для разделения типов и супертипов. Осуществляется наследование атрибутов от супертипа к подтипу.
UML включает два вида исполняемых сетей: диаграммы состояний, которые являются специальным случаем сетей Петри, не поддерживающих параллелизм, и диаграммы активности, которые почти идентичны сетям Петри, за исключением того, что они не используют маркеры для активизации переходов.
Другие сети в семействе UML могут рассматриваться как версии реляционных графов с возможностью представления информации на метауровне. В частности, в UML включены хорошо известные диаграммы «сущность-связь».
Наиболее общей для всех UML структур является линейная нотация, названная языком объектных ограничений (Object Constraint Language (OCL)). Он является версией логики первого порядка с синтаксическими характеристиками подобными некоторым объектно-ориентированным языкам программирования.
UML подвергается критике за отсутствие формального определения, что приводит к несовместимости различных нотаций [52]. Поэтому предлагаются такие подходы как расширение OCL свойствами достаточными для определения всех структур UML или разработка пропозициональной СС эквивалентной полной логике первого порядка с расширениями метауровня, которые можно было бы использовать для определения всего UML.
В нашей стране также разработан ряд систем, использующих СС как средство представления знаний, таких как NET [53], SIMER+MIR[50] и другие.
3.1.3. Формальные логические модели
Традиционным классическим механизмом представления знаний в ИНС является исчисление предикатов. В таких системах утверждения об объектах предметной области переводятся в формулы логики первого порядка и добавляются как аксиомы в базу знаний.
Основные формальные определения, необходимые для логических построений в исчислении предикатов, будут даны нами в разделе, где выполняется построение формальной системы над информационными объектами. Здесь же отметим, что для организации логического вывода в системах, основанных на логике первого порядка, в основном применяется принцип резолюции, предложенный Дж. Робинсоном [54].
Основы формальных логических систем весьма подробно изложены в известных монографиях [55, 56, 57, 58], поэтому мы отсылаем читателя к этим трудам.
Метод резолюции является полным в том смысле, что если формула исчисления предикатов выводима из множества аксиом, то алгоритм вывода завершится за конечное число шагов. Если же для некоторой формулы алгоритм не завершился после определенного числа шагов, то не известно завершится ли он в последующем или формула невыводима из данного множества аксиом.
Основным недостатком логического вывода по методу резолюции является то, что вопрос о направлении резолюции остается открытым, специфические знания о семантике предметной области непосредственно не влияют на ход и результаты вывода. Поэтому применяется ряд более сложных стратегий вывода, призванных уменьшить комбинаторную сложность этого процесса. Для этих целей были разработаны такие методы как семантическая резолюция [59], линейная резолюция [60, 61, 62, 63], процедура доказательства теорем с абстракциями [64], NC – резолюция [65].
Проводятся исследования по управлению процессом вывода с помощью «метазнаний» и изучению нестандартных выводов.
Системы, основанные на логике первого порядка имеют ряд неоспоримых достоинств: они хорошо исследованы и имеют точную интерпретацию синтаксиса и семантики, сохраняют монотонность при вводе или удалении аксиом. Результаты работы с базами знаний в таких системах достаточно предсказуемы.
Вместе с тем, существует достаточно большое количество знаний, которые очень трудно выразить в классическом исчислении предикатов (возможность и необходимость, знания о знаниях, убеждения, намерения, цели и т.д.) Поэтому широко исследуются различные логические системы, такие как модальные логики, многосортные логики, логики высших порядков, вероятностные логики и др. [66, 67, 68, 69, 70].
Продолжают свое развитие и инструментальные системы логического программирования, начало которым положил язык Prolog [71, 72]. Так, например, в университете г. Болоньи разработан язык tuProlog, предназначенный для разработки интеллектуальных Internet – приложений и создания программ, функционирующих в распределенных объектных архитектурах [73]. Этот язык построен на основе языка Java [74] и обеспечивает (по крайней мере, нацелен на это) динамическое конфигурирование, интероперабельность, что позволяет работать в гетерогенных и трудно предсказуемых средах, таких как инфраструктуры Internet.
К сожалению, традиционные логические системы не оснащены средствами структурирования и агрегирования знаний и не содержат прямых средств классификации и типизации объектов. Вместе с тем, логические системы можно интерпретировать как формализм ссылок, позволяющий определить другие эффективные методы представления знаний. Так системы множественного наследования с исключениями позволяют выражать немонотонные формы рассуждений, которые нельзя непосредственно выразить в логике первого порядка, но можно строго определить в более развитых логических языках [75].
Моделирование рассуждений о реальном мире в интеллектуальных системах не ограничивается формализацией точных и бесспорных знаний. Возникает необходимость вырабатывать разумные решения в условиях неопределенности, пользуясь неполной, неточной или изменчивой информацией, порождая предположительные выводы, которые всего лишь правдоподобны и могут пересматриваться.
Такими свойствами обладают немонотонные логики, в которых выводимые формулы не являются тавтологиями и не общезначимы по отношению к своим посылкам, но лишь выполнимы с ними. В таких системах могут выводиться различные несовместимые множества формул, которые зависят от порядка применения правил вывода. Если выведена всего лишь правдоподобная формула, то следует запретить дальнейшее выведение других правдоподобных (но несовместимых вместе с первой) формул.
Множества выводимых формул в немонотонных логиках характеризуются с помощью «неподвижных точек» соответствующих операций.
Неподвижная точка представляет собой устойчивое множество предположений, из которых нельзя вывести никакую новую выполнимую формулу. Метод неподвижных точек непосредственно применяется в немонотонных логиках Мак-Дермотта (Mc Dermott D.) [76, 77], в логиках умолчаний [78, 79] он интерпретируется в виде расширений с умолчаниями, а в автоэпистемических логиках [80, 81] в форме устойчивых расширений, полных и легальных множеств заключений идеально разумного субъекта, выведенных из множества посылок.
3.1.4. Фреймы
Особенностью человеческого мышления является необходимость и потребность в построении некоторых образов реального мира (и ментального тоже), представлений или репрезентаций действительности. Эти представления во многих случаях связываются с типичными ситуациями нашей жизни (начало рабочего дня, урок в школе, поход на дискотеку и т.д.), которые предопределяют поведение человека в данной ситуации и предустанавливают возможные последствия в будущем (например, работа à конфликт с начальником à испорченное настроение вечером à семейная ссора). Эти свойства человеческого восприятия мира и постарался выразить в своей теории фреймов Марвин Минский (M. Minsky) – американский ученый, один из основоположников искусственного интеллекта. Слово фрейм (frame) в буквальном переводе с английского означает «каркас», «рамка».
Поскольку в отечественной литературе по искусственному интеллекту сформировались разные трактовки этого термина, то мы, не вступая в дискуссию с другими авторами, процитируем основоположника, и постараемся показать глубину и силу его концепции.
Итак, слушаем М. Минского: «Фрейм является структурой данных для представления стереотипной ситуации. С каждым фреймом ассоциирована информация разных видов. Одна ее часть указывает, каким образом следует использовать данный фрейм, другая – что предположительно может повлечь за собой его выполнение, третья – что предпринять, если эти ожидания не подтвердятся» [с.7, 82].
Таким образом, фрейм – это информационная структура, но не простая, ибо несет информацию о применении и стало быть о семантике предметной области. Предположительное выполнение подразумевает мышление в терминах модальностей (в частности, возможности и необходимости), способности интеллектуальной системы, работающей с фреймами, предсказывать будущее. Поскольку фрейм содержит описание возможных действий, то соответственно он обладает процедурными свойствами.
Концепция фреймов непосредственно стыкуется с концепцией семантических сетей, об этом прямо говорит Минский: «Фрейм можно представлять себе в виде сети, состоящей из узлов и связей между ними. «Верхние уровни» фрейма четко определены, поскольку образованы такими понятиями, которые всегда справедливы по отношению к предполагаемой ситуации. На более низких уровнях имеется много особых вершин – терминалов или «ячеек», которые должны быть заполнены характерными примерами или данными » [82].
Впоследствии эти вершины – терминалы получили название слотов, т.е. подструктур фрейма, заполняемых данными. Если слоты фрейма не заполнены, то получается фрейм – образец, если же они конкретизированы (точно определены), то мы имеем фрейм - экземпляр, который соответствует некоторой конкретной ситуации, явлению или объекту.
Процедурные свойства фреймов реализуются так называемыми присоединенными процедурами, т.е. программами, процессами, приложениями, выполняющими действия. Различают два вида таких процедур: процедуры – демоны и процедуры – слуги. Процедуры – демоны активизируются при каждой попытке добавления или удаления данных из слота (по умолчанию). Процедуры – слуги становятся активными только при выполнении условий, определенных разработчиком при создании фрейма.
Поскольку фреймам придаются разные содержательные трактовки, то они позволяют отражать все многообразие наших знаний через фреймы – структуры (определяющие объекты, понятия, концепты и т.п.), фреймы - роли (определяющие возможный вариант необходимого поведения некоторого объекта), фреймы - сценарии (определяющие модель возможных взаимосвязанных процессов), фреймы – ситуации и т.д.
Обобщенную структуру фрейма представим следующим рисунком (Рис. 3.3).
Рис.3. 3. Структура фрейма
Здесь ИС – имя слота, ЗС – значение слота, ПП – присоединенная процедура, СОП – сценарий ожидаемого поведения, СЦ – сценарий, САП – сценарий альтернативного поведения.
Существуют различные способы присвоения значений слотам во фрейме – экземпляре. Это может быть присвоение по умолчанию от фрейма-образца, наследование свойств от вышестоящего фрейма, вычисление по заданной ПП, установление путем диалога с пользователем, и другими способами.
Слоты фрейма можно рассматривать и как средство указания отношений или семантических связей данного фрейма с другими. Таким образом, возникает возможность построения сетей фреймов и организации поиска (или вывода) в такой сети. При этом во фреймовой системе возникают такие задачи как:
- создание экземпляров фреймов и заполнение слотов информацией, соответствующей рассматриваемой ситуации;
- активация фреймов;
- организация выводов, связанная с поиском и активацией фреймов наиболее соответствующих ситуации.
В качестве примера сети фреймов построим фрагмент сети, корневым фреймом которого является понятие ² человек ².
Мы видим, что концепция фреймов является обобщенной, поэтому при построении интеллектуальных систем в рамках данного подхода необходимо решать проблемы содержательной интерпретации фреймов и фреймовых сетей, разрабатывать конструкции фреймов-образцов и фреймов-экземпляров, создавать методы решения логических и вычислительных задач.
Для построения математических формальных теорий фреймов применяется аппарат λ-исчисления, а также специфические формальные языки, являющиеся расширениями классических логических исчислений.
Достоинством фреймовых систем является хорошая структурированность, наглядность представления, гибкость использования, что позволяет эффективно строить базы знаний во многих естественных науках. Для феноменологических наук фреймовая концепция может служить основой для разработки точного формального аппарата и адекватных языковых средств.
Существует ряд специальных языков для представления значений в сетях фреймов: FRL (Frame Representation Language) [83], KRL (Knowledge Representation Language) [84], Kappa [85] и другие.
Успешно реализован ряд фрейм-ориентированных интеллектуальных систем – ANALYST, MODUS, TRISTAN, ALTERID [15, 86].
Приведенный выше анализ известных методов представления знаний позволяет сделать вывод о том, что рассмотренные модели имеют примерно одинаковую математическую универсальность, а существенные различия между ними проявляются в методологии представления проблемного знания. Поэтому важнейшей задачей проектирования распределенных интеллектуальных систем является выбор и построение таких моделей представления знаний о предметной области, для которых переход от неформализованных знаний и представлений к формальным моделям интеллектуальных компонентов баз знаний будет наиболее простым и естественным.
3.2. Теоретические методы извлечения и структурирования знаний
Применительно к задачам проектирования баз знаний интеллектуальных систем в последнее десятилетие интенсивно исследовались проблемы получения и структурирования знаний специалистов о предметной области.
В работах Т.А. Гавриловой вводится понятие ² поле знаний ² [87, 88], которое определяется как условное неформальное описание основных понятий и взаимосвязей между понятиями предметной области, выявленных из системы знаний эксперта. При этом представляется поле знаний в виде графа, диаграммы, таблицы или текста. По нашему мнению, понятие ² поле знаний ² не является достаточно определенным. Для корпоративных информационных и интеллектуальных систем, систем административного управления целесообразно говорить о моделях предметной области, которые создаются экспертами, инженерами по знаниям, программистами для построения интеллектуальных систем.
Нам представляется, что процесс формирования модели предметной области, реализуемой далее в интеллектуальной системе можно изобразить в виде следующего сценария (рис. 3.5). Важнейшим моментом в этом процессе является перенос внутренних представлений экспертов об исследуемом подпространстве окружающего мира в модели предметной области ( mP(i) ) путем вербализации и фиксации мыслительных репрезентаций, который вполне справедливо можно назвать извлечением знаний [ 87 ].
Процесс извлечения знаний вызывает большие сложности при построении интеллектуальных систем, ставя перед инженерами по знаниям такие проблемы как:
– неудачный выбор метода извлечения знаний, не соответствующего структуре предметной области;
– неадекватные модели и языки для представления знаний;
– отсутствие психологического контакта с экспертами предметной области;
– терминологическая рассогласованность языка экспертов и инженеров по знаниям;
– невозможность построения целостной модели предметной области в результате извлечения фрагментов знаний;
– потеря части знаний о предметной области в результате упрощения пространства эксперта и др. [ 89 ].
Рис.3.5. Процесс формирования модели предметной области
Мы определяем когнитивное пространство (КП) как совокупность внутренних репрезентаций индивидуума о некоторой части окружающего мира, то есть интересующей нас предметной области и отдаем себе отчет в том, что структура и содержание этого пространства чрезвычайно сложны. В некотором приближении когнитивное пространство можно представить как сложную ( многомерную ) сеть понятий и отношений, визуальных и других чувствительных образов ( паттернов ), мнений, представлений и предположений об объектах, понятиях и их взаимоотношениях, множеств количественных и качественных параметров и др.[90].
Поэтому потери некоторой информации при переходе от когнитивного пространства к предметной области неизбежны и методы извлечения знаний призваны по возможности минимизировать эти потери.
В результате процесса извлечения знаний через взаимодействие экспертов и инженеров по знаниям получаем множество моделей предметной области в интерпретации различных экспертов { mP(1) , mP(2) , … , mP(N) }. Далее через структурирование знаний формируется формализованная модель предметной области:
WM = Ui mP(i),
где U – оператор объединения моделей по некоторому методу (использован знак U , чтобы отличать от объединения множеств). И, наконец, системными аналитиками и инженерами по знаниям строится формальная модель предметной области:
WMF = F (WM),
где F – оператор формализации.
Психологические, лингвистические и гносеологические аспекты извлечения знаний весьма детально разобраны в [87, 88], поэтому мы не будем их обсуждать, а отсылаем читателя к соответствующим источникам.
Классификация методов извлечения знаний хорошо известна и обсуждается во многих работах [87, 88] (рис. 3.6.).
Коммуникативные методы подразумевают непосредственно контакт инженера по знаниям со специалистами предметной области, а текстологические направлены на извлечение знаний из документов и специальной литературы.
Текстологические методы в последние годы достаточно интенсивно развиваются и здесь достигнут ряд существенных результатов [91, 92, 93].
Мы хотим обратить особое внимание на анализ документов, а именно документооборота и документопотоков в условиях промышленной корпорации и в системе организационного управления. В таких организациях документы играют особую роль, так как во многом определяют и регламентируют деятельность предприятия, его организационную структуру и функции, а также накапливают информацию о функционировании предприятия за длительный период времени.
Создание на предприятиях КИС во многом оставляет нерешёнными следующие проблемы:
- сохранение и даже увеличение бумажного документооборота;
- ручной ввод многочисленных данных, ручная корректировка, приведение к требуемой форме (шрифты, размеры и т.д.);
- необходимость обучения (переобучения) персонала (быстрая смена аппаратных платформ и программных продуктов);
- ошибки операторов при вводе информации и эксплуатации вычислительной техники (ВТ) и программного обеспечения (ПО), которые могут привести к тяжелым последствиям;
- возникновение и распространение компьютерных вирусов, представляющих серьезную опасность для распределенных сетевых ИС;
- значительные затраты на обслуживание оборудования и сопровождение программных средств;
- необходимость в наличии на предприятии достаточного числа квалифицированных специалистов по обслуживанию ВТ (программисты, электронщики, системные аналитики, администраторы ЛВС и т.п.).
Решение этих проблем авторы видят на пути создания распределенных объектно-ориентированных КИС с элементами искусственного интеллекта, основанных на формальных моделях, способных определить:
- топологию информационных связей для последующего определения требуемой топологии вычислительной сети;
- состав и структуру информационных потоков и их количественные характеристики;
- характеристики .баз информации;
- семантические свойства информационных объектов.
Одной из задач, решаемых в данном направлении, является построение моделей информационных процессов, необходимых для системного проектирования РИИС. Важный компонент этой задачи - анализ информационных потоков и внутреннего документооборота предприятия. Такой анализ до сих пор остается практически не автоматизированным и чрезвычайно трудоемким. Поэтому авторами решается проблема автоматизированного анализа информационных потоков и документооборота, для чего на данный момент разработана программная система анализа документооборота и построения отраслевого информационного языка [94, 95, 96] . Данная программная система автоматически анализирует исходные документы, циркулирующие в корпоративной сети предприятия, выявляет термины встречающиеся в документах, строит их частотное распределение и формирует отраслевой тезаурус, с учетом мнения эксперта предметной области. Применение такой программной системы позволяет сократить избыточность документопотоков и в настоящее время система апробируется на ряде предприятий.
Развитие исследований этой проблемы производится в направлении создания средств анализа информационных потоков во времени в корпоративной сети.
Следует отметить, что методы извлечения знаний из текстов до настоящего времени недостаточно разработаны. Основные модели понимания текстов естественного языка функционируют на лингвистическом уровне. В таких системах обычно предусматриваются 3 этапа анализа: морфологический анализ; синтаксический анализ; семантический анализ, который использует результаты первых двух этапов, а также словарную и справочную информацию для построения формализованного образа текста.
Достаточно хорошо разработаны модели типа «Смысл-Текст», а именно: модель семантик предпочтения [97] и модель концептуальной зависимости [98].
Например, в системе ТАКТ (Tool for Acquisition of Knowledge from Text) [99] предполагается предварительная подготовка (разметка скобочной структурой) предложений текста до начала работы текстового анализатора. В результате анализа выделятся объекты, процессы и отношения каузального характера.
В системе KITTEN [100] для анализа текстов предназначена процедура TEXAN. Эта процедура строит кластеры терминов, встречающихся в исходном тексте. TEXAN помогает эксперту выбрать подходящие элементы и начальные конструкты, с которых начинается извлечение репертуарной решетки.
Существуют две основные проблемы семантического анализа:
- выявление свойств элементов текста для соотнесения этих элементов с объектами модели мира, что является нетривиальной задачей, так как крайне редко эти свойства присутствуют в тексте эксплицитно;
- необходимость использования словаря предметной области, в результате чего уменьшается универсальность получаемой системы.
Приобретение знаний интеллектуальными системами наталкивается на ряд трудностей [50]:
- качество создаваемой системы зависит от квалификации «посредников» между экспертами и инструментальными средствами - инженеров по знаниям;
- автономное использование методов интервью не позволяет найти и устранить «пробелы» в знаниях;
- интервью субъективно и требует больших затрат времени;
- для приобретения знаний из примеров необходимо обеспечение совместимости баз данных, имеющих различные схемы, с базой знаний интеллектуальной системы;
- необходимо преобразование результатов работы алгоритмов обучения на примерах в способ представления, поддерживаемый программными средствами интеллектуальной системы;
- в тексте отсутствует в эксплицитном виде информация о свойствах элементов текста (имен, предикатов, предложений), необходимая для работы методов приобретения знаний из текстов;
- выполнение семантического анализа текста осложнено отсутствием заранее заготовленного словаря предметной области.
Этапы структурирования знаний, согласно [87, 88], можно представить следующей схемой (рис.3.7).
Рис. 3.7. Этапы структурирования знаний
Данная схема, ориентированная на построение экспертных систем, по нашему мнению, в первоначальном виде вряд ли применима при создании РИИС. Для рассматриваемой нами распределённой структуры неясно, что считать входными и выходными данными, из чего же составлять эти множества {X} и {Y}?. Выявление понятий и объектов недостаточно для проектирования РИИС, так как составляющие её интеллектуальные компоненты будут обладать собственным поведением и для них требуется построение динамического описания.
3.3. Онтологические модели и системы
Термин ² онтология ², происходящий от греческих слов outox - сущее и logox - слово, понятия, учение, впервые появился в ² Философском лексиконе ² немецкого философа Р. Гоклениуса (1547 – 1628) и был утвержден в философской традиции Х.Вольфом (1679 - 1754) [101].
В философских науках онтология трактуется как раздел философии, изучающий фундаментальные принципы бытия, наиболее общие сущности и категории сущего [ 1 ].
Онтология, как философская наука, прошла длинный и интересный путь развития, лежащий, к сожалению, вне рамок нашего исследования.
Возрождение интереса к онтологии в науках об искусственном интеллекте связанном с пониманием того, что концептуальное моделирование или построение семантических моделей действительности является междисциплинарной задачей, требующей высокого уровня абстрагирования.
Онтологию можно рассматривать как изучение организации и природы мира независимо от формы наших знаний о нем. Формальная онтология в современной трактовке понимается как ² систематическая, формальная, аксиоматическая разработка логики всех форм и типов ² [102].
На практике, формальная онтология может быть теорией первичных различий:
– среда метауровневых категорий, используемых для моделирования мира (концепты, свойства, качества, состояния, роли, части и т.д.);
– среда сущностей мира (физические объекты, события, области ( регионы), количества материи и т.д.);
Формальную онтологию можно рассматривать через взаимодействие двух школ: первая рассматривает метафизические проблемы внутри главного направления антологической философии, вторая более закрыто относится к феноменологии, в традициях Брентано ( Brentano) и Хуссерля ( Husserl).
При этом важную роль играет понимание различий между эпистемологией (как наукой о формах знания) и формальной онтологией (как наукой о формах сущего). Эти различия были обнаружены еще в первые годы развития искусственного интеллекта, но в основном игнорировались из-за концентрации академических интересов в области логического вывода и неудачных ранних попыток формализации общезначимой реальности [103]. В науке искусственного интеллекта было разработано много языков представления знаний с соответствующими формализмами и системами реализации, но недостаточно внимания уделялось содержанию знаний, то есть первичному независимому от прикладных задач концептуальному анализу [104].
Итальянский ученый Н.Гуарино (N.Guarino), рассматривая понимание термина ²онтология ², выделил следующие возможные интерпретации: [105]
– онтология как философская дисциплина;
– онтология как неформальная концептуальная система;
– онтология как формальный взгляд на семантику;
– онтология как спецификация ² концептуализации ²;
– онтология как представление концептуальной системы через логическую теорию, характеризуемую специальными формальными свойствами или только ее назначением;
– онтология как словарь, используемый логической теорией;
– онтология как метауровневая спецификация логической теории.
Мы склоняемся к мнению, что в рамках инженерии знаний и с точки зрения разработчиков интеллектуальных систем онтологию следует понимать как представление концептуальной системы некоторой области реального мира средствами логической теории, обладающей определенными формальными свойствами и способной формализовать семантику данной предметной области.
При разработке РИИС построение онтологии будет служить одним из этапов прехода к логической модели и позволит разработчикам явно и ясно представить онтологический уровень распределенной системы.
Мы используем данное понятие, следуя работам [106, 107], в соответствии со следующей классификацией формализмов представления знаний (табл. 3.2).
Табл. 3.2
Уровень
Основные средства(примитвы,базисные элементы)
Интерпретация
Основная характеристика
Логический
Предикаты и функции
Произвольная
Формализация
Эпистемологический
Структурированные отношения
Произвольная
Структура
Онтологический
Онтологические отношения
Ограниченная
Смысл (значение)
Концептуальный
Концептуальные отношения
Субъективная
Концептуализация
Лингвистический
Лингвистические единицы
Субъективная
Языковые зависимости
На логическом уровне базисными элементами являются предикаты и функции, которые имеют формальную семантику в терминах отношений среди объектов индивидной области. В нашей концепции РИИС этот уровень мы представляем логической моделью, развиваемой нами далее, в которой индивидами предметной области являются информационные объекты (ИО).
Эпистемологический уровень, введенный в [106], определяет формальные структуры концептуальных единиц и их взаимодействие как концептуальных единиц (независимо от знания выражаемого ими). То есть, эпистомологический уровень вводит концепты как базисные элементы знаний. Концепты сами по себе имеют внутреннюю структуру, являются как бы “связкой” концептов или бинарных отношений (ролей). Язык, определенный на этом уровне вполне эквивалентен языку логического уровня, но теория, построенная в этом языке должна отличаться от соответствующей логической теории, она неявно предполагает некоторый структурированный выбор, который имеет когнитивную и вычислительную значимость и отражает определенные онтологические обязательства, накапливаемые на начальном этапе разработке базы знаний [108].
На онтологическом уровне такие онтологические обязательства определяются явно. Данное определение можно сделать двумя способами: либо подходящим ограничением семантики базисных элементов, либо введением смысловых постулатов, выраженных в том же самом языке. В обоих случаях, цель состоит в ограничении числа возможных интерпретаций, используемых для описания предметной области. Не всякий формальный язык пригоден для решения этой задачи, согласно [109] язык является онтологически адекватным, если:
- на синтаксическом уровне он имеет достаточную степень детализации и возможности для выражения значения постулатов через его собственные базисные элементы;
- на семантическом уровне он позволяет дать онтологическую интерпретацию своих базисных элементов.
На концептуальном уровне базисные элементы имеют определенную когнитивную интерпретацию, соответствующую независимым от языка концептам, подобным элементарным действиям или тематическим ролям. Каркас структуры предметной области здесь уже задан, независимо от своего рассмотрения онтологических предложений. Внутри заданной прикладной области разработчик стремится выразить знания через специализацию этого каркаса.
Онтологии могут в различной степени зависеть от предметной области и решаемых задач, и по этому признаку их разделяют на:
- метаонтологии (онтологии верхнего уровня);
- онтологии, ориентированные на предметную область;
- онтологии, ориентированные на конкретные прикладные задачи;
- прикладные онтологии.
Метаонтологии пытаются описать самые общие концепты, такие как материя, время, пространство, объект, субъект, событие и прочие, которые не зависят от конкретной предметной области. Такая метаонтология создается в проекте GYGâ, разрабатываемом фирмой Gycorp [110].
Этим же целям служит система GUM (Generailized Upper Model)[111], ориентированная на поддержку процессов обработки естественного языка.
Широко используются в настоящее время средства представления онтологических знаний в среде Internet. Целью этих работ является построение таких пространств знаний в сетевой среде, где обеспечивалось бы использование семантики для получения ответов на запросы, сосредоточенный доступ к информации, которая распределена в сети, возможность выведения новых фактов и знаний из имеющихся на сетевых ресурсах.
Известными проектами этого направления являются (КА)2(Knowledge Annotation Initiative of the Knowledge Acquisition Community)[112] и SHOE [113], которые довольно подробно описаны в [87].
В рамках направления развиваемого авторами этой книги наибольший интерес представляют предметные онтологии, которые описывали бы на онтологическом уровне образ предприятия, корпоративной системы или организации.
Существенным шагом в этом направлении является стандартный метод IDEF5, разработанный в 1994 году группой американских ученых, среди которых P. Benjamin, C. Menzel, R. Mayer и др. [114]. Данный метод специально создан для формализации проектов интеллектуальных систем посредством описания онтологии исследуемой области и предназначен для следующих категорий специалистов:
- инженеров баз знаний и экспертов какой-либо прикладной области;
- системных аналитиков и проектировщиков, оперирующих онтологическими знаниями;
- исследователей в прикладных областях, чья деятельность связана с использованием методов представления знаний на производстве.
Авторы метода IDEF5 стремились к стандартизации терминологии во всем многообразии видов различной инженерной деятельности. В комплексных проектах множество специалистов пользуется терминологией разными способами, изменяют и дополняют ее, поэтому информация, передаваемая от одного сотрудника к другому, может искажаться. Среди наиболее значительных проблем в разработке и в производстве вообще являются большие усилия, затрачиваемые на использование и обновление уже имеющейся информации. В различных областях знаний выделяется много общих характерных черт, которые не зависят от специфичности данных областей. Соответственно, чем больше эти области, тем больше количество знаний сходных по своей онтологической структуре могут использоваться совместно. Аналогично библиотекам подпрограмм в программировании собирается общая научная или производственная информация в онтологические библиотеки. Информация в этих библиотеках может многократно использоваться и изменяться, чтобы удовлетворять потребностям на данный момент времени. Кроме того, онтологическое описание стандартизованной терминологии очень просто и естественно. Сама же онтологическая концепция хорошо масштабируема и может быть использована как в больших, так и в малых проектах.
В общих чертах создание онтологии в IDEF5 предусматривает выполнение следующих действий:
1. Организация и наблюдение. Установка цели, точки зрения и контекста для разработки онтологии и назначение ролей членам группы;
2. Сбор данных. Получение необработанных данных, необходимых для разработки онтологии;
3. Анализ данных. Анализ данных с целью облегчить извлечение онтологической информации;
4. Первоначальная разработка онтологии. Разработка предварительной онтологии по полученным данным;
5. Совершенствование и проверка правильности онтологии. Совершенствование и проверка достоверности онтологической информации для завершения процесса разработки.
Описание онтологии в IDEF5 осуществляется посредством двух языков: схематического языка и языка разработок, который, по сути, является языком программирования. Схематический язык – это графический язык, который по сложности ориентирован на среднего пользователя и предназначен для того, чтобы дать возможность специалистам по проблемным областям выражать наиболее общие формы онтологической информации. При легкости использования схематического языка в нем отсутствует полная выразительная мощность, необходимая для подробного описания онтологии. Для этой цели создан язык разработок. Язык разработок IDEF5 - структурный текстовый язык с полной выразительной силой, базирующийся на формальной логике и исчислении предикатов первого порядка. Он дает возможность выразить любое условие, соотношение или факт для того, чтобы охарактеризовать данный вид какой-либо вещи, свойства, соотношения или процесса, найденного в области знаний. В дополнение к набору теоретических конструкций, язык также включает специализированные конструкции для выражения онтологической информации в формате IDEF5. Это делает возможным трансляцию из схематического языка в язык разработок и обратно.
Описание метода IDEF5 содержит два приложения: первое – библиотека соотношений IDEF5 - богатый архив информации, состоящей из часто используемых наборов характеристик, определений и аксиом; второе приложение включает описание языка разработок IDEF5 в нормальной форме Бэкуса-Наура.
Предлагаемая методом IDEF5 аксиоматика, строится подобно описанию правил на языке Пролог, что вполне коррелирует с парадигмой описания интеллектуальных систем, базирующихся на правилах. В то же время она может быть адаптирована и на вышеописанные МАС.
Однако, несмотря на большие возможности IDEF5 в описания онтологии, остается достаточно много нерешенных вопросов по практическому применению данного метода. Дело в том, что сам процесс описания онтологии в IDEF5 требует немалых временных затрат специалистов из различных областей знаний. В то же время сами накопленные онтологические знания существенной ценности не представляют, если нет соответствующих аналитических систем - инструментов для обработки этих знаний. Поэтому по мере накопления онтологических знаний неизбежно будут возникать проблемы по созданию и совершенствованию таких систем. В частности в NASA финансируется проект системы Ontology Driven Information Integration (ODII) [115].
ODII – предполагается использовать как интегрированную среду для моделирования предприятия и совместного использования знаний. В ODII учитывается разработка различных типов моделей предприятия (процесс, данные, онтология) и информационные потоки между этими моделями. Недавно была выпущена бета-версия системы ODII (ModelMosaic ™).
Следует обратить внимание на сложность обработки накопленной онтологической информации в IDEF5 именно с позиций различных областей знаний. Эта проблема связана с самой идеологией IDEF5. В описании онтологии метод IDEF5 оперирует такими ключевыми понятиями как виды, соотношения, свойства и атрибуты. Авторы IDEF5, не упоминают о многократности описания знаний для восприятия их с разных точек зрения. Чтобы это пояснить, можно рассмотреть ситуацию, когда в области одних знаний вид будет являться свойством в области других знаний и наоборот. Сюда же можно отнести соотношения, устанавливаемые между подвидами и более общими видами, когда вид в области одних знаний может быть подвидом в области других. В качестве примера можно рассмотреть термины: канал передачи данных и электрический кабель, соответственно из областей теории передачи информации и электротехники в их компонентном соотношении. В области теории передачи информации канал передачи данных может содержать электрический кабель, а может и оптоволоконный. В области электротехники электрический кабель может быть каналом передачи данных (на уровне физического сигнала), а может быть и средством передачи электрического тока.
В методе IDEF5 отсутствуют качественные отношения, подобные качественным прилагательным в русском языке, обозначающие чистый признак, которого в объекте может быть больше или меньше по сравнению с другими подобными объектами (лучше/хуже, быстрее/медленнее, сильнее/слабее и т.п.), соответственно отсутствуют и степени (меры) сравнения признаков, что ограничивает использование метода IDEF5 в построении систем поддержки принятия решений и экспертных систем [116, 117] .
На онтологическое представление корпорации ориентирована система TOVE (Toronto Virtual Enterprise Project) [118], которая призвана отвечать на вопросы пользователей по реинжинирингу бизнес–процессов, выполняя при этом дедуктивный вывод ответов.
В последние годы созданы доcтаточно богатые онтологические библиотеки, такие как Ontolingua ontology library (http://www.ksl.stanford.edu/software/ontolingua) и DAML ontology library (http://www.daml.org/ontologies), а также ряд коммерческих онтологий, доступных на рынке: UNSPSC (http://www.unspsc.org), RosettaNet (http://www.rosettanet.org), DMOZ (http://www.dmoz.org).
3.4. Основы теории информационных агентов РИИС
3.4.1. Построение формальной объектной аксиоматизируемой системы
На основе анализа, выполненного в первой и второй главах можно утверждать, что распределенные объектные архитектуры могут служить фундаментом для построения РИИС. Выделяя в соответствии с принципами, изложенными в разделе 2.3 интеллектуальный слой в прикладном уровне архитектуры открытых систем, мы сталкиваемся со следующими вопросами: какова внутренняя структура этого интеллектуального слоя,какие дополнительные конструкты необходимо создавать для постепенного и логически обоснованного перехода от программных объектов к интеллектуальным компонентам РИИС?
Рассмотрим эту проблему с двух точек зрения. Во-первых, применяя классификацию, построенную в табл. 2.1., мы увидим, что программным объектам будут соответствовать автоматные агенты (это хорошо известное соответствие автоматных языков и блок-схем алгоритмов) [119, 120]. Интеллектуальным компонентам по всей логике нашего подхода должны соответствовать семиотические агенты. ИК должны обеспечивать сложные множественные реакции на происходящие в информационном пространстве события т возникающие ситуации, накапливать данные о прошедших событиях и ситуациях, обладать способностью к извлечению знаний и модификации моделей окружающей среды.
Можно ли непосредственно в архитектуре РИИС связать программные объекты и интеллектуальные компоненты, обеспечить их прямое взаимодействие, минуя промежуточные звенья? По всей видимости нет, так как в случае такого прямого перехода необходимо транслировать ментальные модели ИК непосредственно в интерфейсы и методы программных объектов, причем осуществлять это динамически, чтобы обеспечить планирования поведения РИИС. Этот вывод подтверждается и достигнутыми результатами в теории и практике мультиагентных систем, которые обсуждались во второй главе.
Посмотрим на этот вопрос с другой стороны. Определим интеллектуальное расстояние между программными объектами и интеллектуальными компонентами, следуя разделу 2.2. Кодовые слова для характеристик разумности программного объекта и ИК будут иметь вид: XПО=111100010, XИК=112111112, следовательно, ID(ПО,ИК)=6. Поскольку мы уже пришли к выводу, что за один шаг преодолеть эту интеллектуальную дистанцию практически невозможно, то напрашивается разделение ее на равные интервалы. Если выбрать этот интервал интеллектуального расстояния равным двум (∆ID=2), то число переходов между уровнем программных объектов и уровнем ИК оказывается равным трем и между программными объектами и ИК необходимо ввести еще два звена: мы назовем их информационными объектами (ИО) и интеллектуальными агентами (ИА). Здесь мы обнаруживаем, что обе точки зрения совпадают, что и отражает таблица 3.3.
Таким образом, необходимым базисом для формализации РИИС является модель информационного объекта, которая должна строиться в рамках формальной аксиоматизируемой системы (теории), основания которой и рассматриваются далее.
Уровни в архитектуре РИИС
Таблица 3.3
По интеллектуальному весу и расстоянию
Характеристики разумности
По типу среды функционирования и методу математического описания
S1
S2
M1
M2
M3
M4
T1
T2
T3
Программные объекты
Автоматные агенты
ИО
КСГ-агенты
ИА
КЗГ-агенты
ИК
Семиотические агенты
В качестве математического аппарата такой теории (исчисления объектов) авторы используют логику первого порядка.
Будем предполагать, что a - множество функциональных, предикатных и константных символов, конечное или счетно бесконечное (что оставляет нам возможность расширения языка a). Каждому функциональному символу fÎa можно поставить в соответствие целое положительное число #(f), такое что, если n = #(f), то f называется n-арным функциональным символом. Каждый предикатный символ RÎa можно связать с положительным целым числом #(R); если n = #(R), то R называется n-арным предикатным символом. Предикатные символы по своей сути являются символами отношений. В соответствии с [121], под алгебраической системой F будем понимать непустую совокупность M объектов, которая является областью действия кванторов, вместе с интерпретацией основных предикатных, функциональных и константных символов из a.
Определение 1.Алгебраическая система для языка a есть пара F=<M,F>, где M - непустое множество, F – отображение с областью определения a такое, что:
1) если RÎa - n-арный предикатный символ, то F(R)ÍMn;
2) если fÎa - n-арный функциональный символ, то F(f):Mn®M;
3) если сÎa - константный символ, то F(c)ÎM.
Основными синтаксическими понятиями логики 1-го порядка являются: логические связки: &, Ú, Ø, ®, =; кванторы общности и существования " и $, символы логических переменных, обозначаемых x, y, z, ...
Всякую конечную последовательность, элементами которой являются основные символы или элементы a, можно назвать выражением.
Определение 2.Термы языка a образуют наименьшее множество выражений, содержащее x, y, z, ..., все константные символы a (если таковые имеются) и замкнутое относительно правила образования: если t1, ..., tn – термы a и если fÎa - n-местный функциональный символ, то выражение f(t1, ..., tn) является термом языка a.
Терм, не содержащий переменных, называется замкнутым.
Определение 3.Атомная формула языка a - это выражение одного из следующих видов:
(t1 = t2), R(t1, ..., tn),
где t1, t2 - термы языка a, а RÎa - произвольный n-местный предикатный символ.
Определение 4.Формулы первого порядка языка a образуют наименьшее множество выражений, содержащее атомные формулы и замкнутое относительно следующего правила образования:
1) если j и y - формулы, то выражения Øj, (j&y), (jÚy), (j®y)
также являются формулами.
2) если j - формула и u - переменная, то ($uj) и ("uj) также являются формулами.
Определение 5. Множество FÚ(j) свободных переменных формулы j определяется следующим образом:
1) если j - атомная формула, то FÚ(j) в точности множество переменных, встречающихся в j;
2) FÚ(Øj) = FÚ(j);
3) FÚ(j&y) = FÚ(jÚy) = FÚ(j®y) = FÚ(j)ÚFÚ(y);
4) FÚ($uj) = FÚ("uj) = FÚ(j)-{u}.
Определение 6. Предложением (первого порядка) языка a называется формула, не содержащая свободных переменных.
Мы будем строить алгебраическую систему для языка логики 1-го порядка a над множеством М – информационных объектов. Переменными в данном случае будут обозначаться информационные объекты, а далее будут вводиться предикатные и функциональные символы над множеством М.
Информационный объект (ИО) определяется следующим образом:
О := < имя_объекта, {A}, {O}, модель_поведения >,
Введем более компактные обозначения: имя_объекта (Name of Object) = NO, модель_поведения (Behavior Model) = ВМ и получим:
О := < NO, {A}, {O}, ВМ >,
где NO – символьная строка, соответствующая соглашению об именах, вводимому далее; {A} - множество атрибутов объекта (А0, А1, ..., Аn), где Аi – i-ый атрибут ИО; {O} - множество объектов, вложенных в данный объект (в смысле структурного вложения) (ОNO1, ONO2 , ... , ONOi, ..., ONOm), где ONOi- i-вложенный объект, объекта с именем NO.
Атрибут ИО определим как:
А = < NA, SA, VA >,
где NA – имя атрибута (символьная строка, соответствующая соглашению об именах), SA – множество на котором определяется значение атрибута (о способе задания этого множества будем говорить далее), VA – значение атрибута, т.е. аÎSA в данный момент времени t.
Тогда примитивным ИО можно назвать такой ИО, что О = < NO, {A}, Æ, BM > , т.е. имеющий пустое множество вложенных ИО. Можно ввести структурный ИО (или пассивный), определяемый как: О = < NO, {A}, Æ, Æ >, т.е. имеющий пустое множество вложенных ИО и пустую модель поведения, а также ввести однопараметрический ИО: О = < NO, A, Æ, Æ >, для сокращения записи обозначаемый как < NO,A >, имеющий только один атрибут.
Такое определение информационного объекта позволяет нам рассматривать множество М алгебраической системы как актуальное и оставаться в рамках логики 1-го порядка при рассмотрении отношений между информационными объектами.
Начнем введение отношений в рассматриваемую модель Ф с отношения принадлежности объектов (иначе говоря, отношение структурной вложенности) Rs. Свойства этого отношения следует предложить таковыми.
Во-первых, отношение Rs – антирефлексивно: "х(ØRs(x,x)). Это следует из содержательного понятия структурной вложенности (сам предмет не содержит самого себя как структурной части). Во-вторых, отношение Rs – транзитивно:
"х"y"z( Rs(x,y)&Rs(y,z)® Rs(x,z)).
В-третьих, это отношение несимметрично: "х"y( Rs(x,y)®Ø Rs(y,х).
Если рассматривать эти свойства как аксиомы в исчислении предикатов (ИП), то необходимо показать, что они являются общезначимыми формулами в языке a (или тавтологиями). Для этого придется провести содержательное доказательство.
Для самого себя объект х не обеспечивает истинности Rs. Поэтому для всех х аксиома Rs(1) является тавтологией.
Для аксиомы Rs(2) рассмотрим следующие варианты структурных отношений:
Вариант 1. Объекты x, y и z независимы друг от друга
Формулу (Rs(x,y)&Rs(y,z)® Rs(x,z)) раскрываем как дизъюнкцию в соответствии с правилами ИП, тогда получаем: (Ø( Rs(x,y)&Rs(y,z))Ú Rs(x,z)). При данных отношениях объектов имеем истинностные оценки: Rs(x,y) = f, Rs(y,z) = f, Rs(x,z) = f, следовательно: Ø(f&f)Úf = Ø(f)Úf = tÚf = t.
Вариант 2. Объект у включает х, z – независим:
тогда, Rs(x,y) = t, Rs(y,z) = f, Rs(x,z) = f, и, следовательно, Ø(t&f)Úf = Ø(f)Úf = tÚf = t. С точностью до переименования переменных, аналогичные результаты получаются для случаев включения одного объекта в другой и независимости третьего.
Вариант 3. Два объекта х и у входят в объект z:
В этом случае Rs(x,y)=f, Rs(y,z)=t, Rs(x,z)=t
Ø(f&t)Út = Ø(f)Út = tÚt = t.
С точностью до переименования переменных, получим доказательства истинности формул, аналогично варианту 2.
Вариант 4. Объект х входит в объект у, а у входит в z.
Имеем Rs(x,y =t, Rs(y,z)=t, Rs(x,z)=t, тогда
Ø(t&t)Út = Ø(t)Út = fÚt = t.
Таким образом, при всевозможных интерпретациях х, у, z данное предложение является тавтологией, что и требовалось доказать.
Для аксиомы Rs(3): "х"y( Rs(x,y)®Ø Rs(y,х).
Рассматриваем варианты структурных отношений двух объектов х и у.
Вариант 1. Объекты х и у независимы друг от друга (имеется ввиду структурно):
Тогда Rs(x,y)=f, Rs(y,x)=f и ØRs(x,y)Ú Rs(y,x) = ØfÚØf = tÚt = t.
Вариант 2. Один объект включает другой, например, х включает у, тогда
Rs(x,y) = f, Rs(y,x) = t и
ØRs(x,y)Ú Rs(y,x) = ØfÚØt = tÚf = t
Вариант, когда у включает х рассматривается аналогично, путем переименования объектов.
В результате доказана общезначимость аксиом Rs(1)-Rs(3) в языке a.
В качестве средства получения количественной оценки структурных отношений объектов можно ввести функцию структурной мощности объекта, обозначив ее функциональным символом Pw.
Для этой функции предлагается следующая система аксиом:
Pw(1) Pw(x) = 1, если х - примитивный ИО
Pw(2) Pw(x) = Pw(x1) + Pw(x2), если
x = < NO, {A}, (x1, x2), BM > или, в общем случае,
хÎ{< NO, {A}, (x1, x2), BM >}, где {A} и ВМ могут быть и пустыми множествами. Знак + понимается здесь как символ суммирования натуральных чисел. Эта операция также может быть введена аксиоматически, что подразумевается известным и детально разработано Д. Гильбертом и П. Бернайсом [55].
На основании аксиом Pw(1) и Pw(2) покажем, что функция Pw является аддитивной, то есть справедлива теорема 3.1:
Pw(х) = , где хÎ{< NO, {A}, (x1, x2, ..., хn), BM >}.
Для доказательства воспользуемся методом индукции.
Для i = 1 имеем:
Pw(x) = Pw(x1), в случае если х1 примитивный ИО, то Pw(x1) = 1, и следовательно, Pw(x) = 1. Если же х1 не примитивный ИО, то возвращаемся к исходной посылке.
Для i = 2 теорема 3.1 справедлива вследствие аксиомы Pw(2). Покажем, что если теорема верна при i = n, то она верна и при i = n+1. В этом случае
по аксиоме 2. Следовательно, теорема 3.1 верна и для произвольного натурального числа n.
Далее покажем, что справедлива теорема 3.2:
Функция Pw(x) возвращает количество примитивных объектов, содержащихся в информационном объекте Х.
Будем пользоваться индукцией по глубине индекса вложения объектов ℓ. Пусть ℓ= 1, тогда Pw(х) = = n , если все хi, входящие в Х, являются примитивными информационными объектами.
Покажем, что если теорема справедлива при глубине индекса вложения к, то она справедлива и при к+1. При глубине вложения равной к имеем:
, когда все хℓ1ℓ2 ... ℓk являются примитивными информационными объектами и ℓk = Pw(хℓ1ℓ2 ... ℓk).
При глубине вложения к+1 имеем:
В соответствии с теоремой 3.1 можем эту сумму раскрыть как
Раскрывая скобки, получим:
Для каждого из этих слагаемых, исходя из заданной предпосылки теоремы, получаем:
что и требовалось доказать.
Для обеспечения замкнутости исчисления объектов на множестве М, необходимо потребовать, чтобы результат действия функционального символа Pw также был объектом. Поэтому, вместо непосредственного использования натурального числа будем считать, что Pw(x) = < NO, A > - однопараметрический объект, где А = < NA, {множество_натуральных_чисел}, а >, где аÎ{мно-жество_натуральных_чисел}. В свою очередь, поскольку язык a допускает построение рекурсивных термов, формально допустим терм Pw(Pw(x)). Поэтому Pw(Pw(x)) = Pw(< NO, A >) положим равным х0, где х0 = <Æ, Æ, Æ, Æ>, т.е. пустой объект. Пустой объект х0 необходимо замкнуть сам на себя и считать, что Pw(x0) = х0, тогда рекурсия вида Pw(Pw ... Pw(x ) ...) всегда даст х0. Из соображений строгости придется дополнить систему аксиом для отношения Rs:
Rs(00) "x(ØRs(x0,x))
Rs(01) "x(ØRs(x,x0)).
Обоснование того, что аксиомы Rs(00) и Rs(01) являются тавтологиями, совершенно аналогично обоснованию аксиомы Rs(1).
Использование ИП с равенством заставляет нас ввести понятие равенства объектов. На самом деле, трактовать его необходимо как эквивалентность объектов. Будем считать, что два объекта равны (эквивалентны друг другу) если
x = < NAx, {A}x, {O}x, BMx >
y = < NAy, {A}y, {O}y, BMy >
{A}x = {A}y, {O}x = {O}y, BMx = BMy.
Имена объектов при этом могут быть различны.
Очевидно, что далее требуется определить отношение равенства для множеств атрибутов, вложенных объектов и моделей поведения. Два множества атрибутов {A}x и {A}y будем считать равными (эквивалентными), если для всех AiÎ{A}x и AjÎ{A}y наблюдается попарное равенство при одинаковом значении индекса i, т.е. Aix = Aiy, где i = 1,2 ... n, при этом n – мощность множеств {A}x и {A}y.
Два атрибута Aj и Ay назовем равными (эквивалентными), если NAj = NAy, SAj = SAy, VAj = VAy.
Равенство списков вложенных объектов {O}x и {O}y определяется аналогично равенству множеств атрибутов, т.е. {O}x = {O}y, если мощности множеств {O}x и {O}y равны и каждый Oix = Oiy. Очевидно, что это определение рекурсивно, так как объекты Oix и Oiy могут иметь свои вложенные объекты.
Придется ввести понятие первичное мощности объекта Рр, т.е. функции, показывающей количество вложенных объектов.
Введем следующие аксиомы:
Рр(1) Рр(х) = Æ, если х – примитивный ИО,
Рр(2) Рр(х) = к, если х = < NO, {A}, (x1, x2, ..., xk), BM >,
где {A} и BM могут быть и пустыми множествами.
Можно ввести Рр(х) и конструктивно, т.е. использовать продукционные правила для вычисления к, поскольку это число в явном виде может быть и неизвестно. По аналогии с функцией Pw будем считать, что Рр(х) = < NO, A > - однопараметрический объект, где A = < NA, {множество_натуральных_чисел},а>, где аÎ{множество_натуральных_чисел}. Рр(х) положим равным х0.
Расширение алгебраической системы Ф можно осуществить путем введения новых отношений над ИО. Введение новых отношений (соответственно новых предикатных символов в язык a) позволяет не ограничивать заранее общность системы Ф. При этом предлагается следующая схема введения новых отношений:
Поскольку наиболее распространенные отношения имеют типичные свойства, то можно предложить совокупность аксиом, предопределенных по умолчанию, априорно известных формальной системе, чтобы впоследствии задавать их просто ссылками. Запишем их как:
АОÆ1 "х"у(хRу®уRх)
АОÆ2 "х"у(хRу®Ø(уRх))
АОÆ3 "х(хRх)
АОÆ4 "хØ(хRх)
АОÆ5 "х"у"z((хRу)&(уRz)®хRz)
Здесь АОÆ1 выражает свойство симметричности, АОÆ2 - асимметричности, АОÆ3 – рефлексивности, АОÆ4 – антирефлексивности и АОÆ5 – транзитивности.
Задавая таким образом новые отношения (предикатные символы), мы можем строить различные, произвольные до некоторой степени аксиоматизируемые системы Ф в языке исчисления предикатов.
Отношение равенства (эквивалентности) объектов, очевидно, требует более детального рассмотрения вследствие сложной структуры ИО. Введем следующие определения.
Два информационных объекта х и у назовем информационными объектами одного вида (одновидовыми объектами), если NOx ¹ NOy, {A}x = {A}y, {O}x = {O}y, BMx = BMy, т.е. они эквивалентны с точностью до собственных имен объектов. Отношение одновидовой эквивалентности является симметричным, антирефлексивным и транзитивным (удовлетворяет аксиомам АОÆ1, АОÆ4, АОÆ5).
Введем эквивалентность с точностью до имен атрибутов.
Два ИО х и у называются объектами одного класса (классовая эквивалентность), если NOx ¹ NOy, {O}x = {O}y, BMx = BMy и для всех i NAxi = NAyi, SAxi = SAyi, где i = 1,2, ...,k, где k – число атрибутов в множествах {A}x и {A}y (мощность {A}x = {A}y).
Отношение классовой эквивалентности также является симметричным, антирефлексивным и транзитивным.
Если два объекта находятся в отношении одновидовой эквивалентности (ОЭ), то они обязательно находятся и в отношении классовой эквивалентности (КЭ), т.е. справедлива
Теорема 3.3. "х"у((хR0у)®(хRку)).
Данная теорема непосредственно следует из определений ОЭ и КЭ, т.к. ОЭ является частным случаем КЭ при VAxi = VAyi.
Обратное утверждение, естественно, неверно по тем же причинам.
Здесь через R0 обозначаем одновидовую эквивалентность, а через Rk – классовую эквивалентность.
Подлежит рассмотрению вопрос о структурной эквивалентности ИО. Содержательно под этим понимается эквивалентность структур с точностью до имен переменных и значений параметров. Формально можно дать следующее определение.
Два ИО х и у называются структурно эквивалентными (СЭ), если NOx ¹ NOy, {O}x @ {O}y, BMx = BMy, {A}x @ {A}y, где знак @ обозначает структурную эквивалентность. СЭ для {A} означает, что мощности множеств {A}x и {A}y одинаковы и SAxi = SAyi при i = 1,2, ..., к, где к – мощность {A}x (соответственно и {A}y). Таким образом, совпадают только определения атрибутов, а имена и значения их могут быть различны. Для множеств {O}x и {O}y структурная эквивалентность обозначает, что первичная мощность Рр(х) и Рр(у) равны и Oxi= Oyi, где i = 1,2, ..., m, где m = Рр(х) = Рр(у).
Дополнительное разъяснение структурной эквивалентности для примитивных, структурных и однопараметрических объектов не требуется, так как они подпадают под общее определение данное выше.
Исходя из такого определения, классовая эквивалентность не является частным случаем структурной эквивалентности, поскольку в случае СЭ вложенные объекты находятся в отношении СЭ, а не эквивалентности, как в случае КЭ.
Отношение СЭ является симметричным, антирефлексивным и транзитивным.
Функция извлечения атрибута.
Поскольку при анализе поведения декомпозируемой системы потребуется сравнение различных характеристик ИО, введем функцию извлечения атрибута I(p,q), где р – имя ИО, q – имя извлекаемого атрибута.
Это означает, что в случае отсутствия в множестве {A} атрибута с именем q, функция принимает значение пустого информационного объекта х0. Получается, что функция I(p,q) принимает значения на множестве х0È{Oор}, где {Оор}* - множество всевозможных однопараметрических ИО. Необходимо постулировать, что взятие функции I от однопараметрического объекта дает тот же самый однопараметрический объект: I(p,q) = p, если р – однопараметрический ИО.
Это позволяет в дальнейшем ввести необходимые математические операции над однопараметрическими ИО (ОПИО). Начнем это рассмотрение с операции арифметического суммирования
Пусть å(Х,Y) = Z, где X = < p, A >, Y = < q, B > есть ОПИО с именами p и q и атрибутами А и В, соответственно при этом: A = <NA, SA, VA>, B = <NB, SB, VB>.
Введем следующие аксиомы:
Аå01: "х((х = х0)®(å(х,у) = х0))
Аå02: "х((х = х0)®(å(у,х) = х0))
В результате логического вывода получим, что å( х0, х0) = х0. Объект х0 служит признаком возникновения ошибки.
Аå03: "х"у(Ø(SA = SB)®(å(X,Y) = x0))
Аå04: "х"у"z( (SA = SB)&(VCÎSA)®(å(X,Y) = Z)),
где Z = < p-q, åA,B >, где åА,В = С = < NC, SC, VC),
NC = NA-NB, SC = SA = SB, VC = åVA,VB.
Аå05: "х"у"z( (SA = SB)&Ø(VCÎSA)®(å(X,Y) = х0)),
Это случай, когда VC лежит за пределами множества SA.
VC = åVA,VB понимается как арифметическая сумма, которая может быть построена конструктивно для соответствующих видов чисел.
Операцию å можно сделать и n-арной, использовав рекурсивное определение:
.
Легко заметить, что для введенного таким образом сложения ОПИО не выполняется коммутативный закон: å(X,Y) ¹ å(Y,X), так как результатом левой суммы является информационный объект Z = < p-q, åA,B >, а результатом правой суммы Z’ = < q-p, åB,A >.
Но зато для сложения ОПИО выполняется ассоциативный закон:
å(X,Y,Z) = å(X,å(Y,Z)) = å(å(X,Y),Z).
Из рекурсивного определения суммы получаем: å(X,Y,Z) = å(X,å(Y,Z)). Покажем, что это в точности равно å(å(X,Y),Z).
Пусть X = < p, A >, Y = < q, B >, Z = < l, C>, тогда å(X,å(Y,Z)) принимает вид:
Поскольку VA, VB, VC – это числа, то для них ассоциативный закон выполняется и åVA, åVB,VC = å(åVA,VB),VC.
Таким образом, доказана справедливость ассоциативного закона для ОПИО.
Покажем справедливость закона нулевого множества для сложения ОПИО.
Теорема 3.4. Для всех ОПИО выполняется строгое равенство (эквивалентность):
.
Для доказательства воспользуемся индукцией по длине суммы. При n=2 имеем:
å(х),х0 = х0, согласно Аå02. Положим, что наше утверждение справедливо при произвольном n, и покажем, что из этого следует его истинность при n+1.
Рассмотрим два возможных случая:
а) Суммадает некоторый ОПИО, который обозначим как М. Тогда получаем:
согласно ассоциативному закону.
По Аå02 получаем
и тогдапо посылке индукции.
b) сумма дает в результате х0. Тогда
По Аå01 получаем
Теорема 3.5. Для всех ОПИО выполняется строгое равенство (эквивалентность):
å(х1, ..., хк, х0, хк+2, ..., хn) = х0
при произвольных к и n, являющихся натуральными числами.
Для доказательства этого утверждения будем преобразовывать n-арную сумму, в соответствии с рекурсивным определением:
Поскольку здесь изменяются два индекса k и n, то необходимо использовать двойную индукцию. Так как k обязан находиться в пределах 0 < k < n, то воспользуемся обратной индукцией по k.
а) k = 1, n = 3
åx0,x2,x3 = å(å(x0,x2),x3) = åx0,x3 = x0
Это следует из ассоциативного закона и Аå01.
Следует доказать, что теорема справедлива при k = 1 и произвольном n. Поэтому делаем шаг
b) k = 1, n = m, считая, что утверждение истинно при n = m, докажем, что оно истинно и при n = m+1
å(x1,...,x0,xn) =å(åx1,...,x0),xn) = åx0,xn = x0, в соответствии с законом нулевого множества.
d) Покажем, что если теорема верна для произвольного k, 1<k<n, то она верна и для k-1.
Сумму (d.1) приведем к виду (d.2), используя закон нулевого множества:
Мы видим, что суммы (d.1) и (d.2) приобретают идентичный вид, следовательно, утверждение d) справедливо, следовательно, истинна теорема в целом.
Следует отметить, что коммутативный закон для суммирования ОПИО выполняется для отношения структурной эквивалентности:
(å(X,Y) R st (å(Y,X)).
3.4.2. Теоретико-множественные свойства информационных объектов
Обсудим вопрос о том, что с теоретико-множественной точки зрения представляет собой вводимое множество М информационных объектов.
Множество считается заданным, если указано характеристическое свойство элементов этого множества, то есть такое свойство, которым обладают все элементы множества и только они. Множество – набор, совокупность, собрание каких-либо объектов, называемых элементами, обладающих общим для всех их характеристическим свойством. Можно дать либо перечень элементов множества – его перечисление, либо дать правило для определения того, принадлежит или нет данный объект рассматриваемому множеству – его описание.
Класс – термин, употребляемый в математике в основном как синоним термина ”множество” для обозначения произвольных совокупностей объектов, обладающих каким-либо определенным свойством или признаком. Иногда классом называют совокупности, элементами которых являются множества. В некоторых случаях термин ”класс” применяется для того, чтобы подчеркнуть, что данная совокупность оказывается собственно классом, а не множеством в узком смысле.
В аксиоматической теории множеств (точнее в аксиоматической системе Гёделя - Барвайса) класс – один из видов исходных объектов, рассматриваемых в этих системах, причем различия между множеством и классом состоит в том, что элементами классов и множеств могут быть только множества, но не классы [118 ].
Применительно к совокупностям информационных объектов будем трактовать термины ”класс” и ”множество” как синонимы, так как не удается провести их четкого различия в духе системы Гёделя - Барвайса. Это связано с тем, что согласно вводимым определениям признаком, характеризующим совокупности информационных объектов, является структура информационного объекта, выраженная в определении, поэтому исходя из общих представлений теории множеств, можно говорить о множестве информационных объектов вообще.
Оказывается, что это множество имеет собственную сложную структуру, что и отражает классификация, представленная на рис. 3.8.
С точки зрения математической логики совокупность элементов или понятий можно рассматривать как концептуальный класс [57]. Уточнением этого понятия является понятие ” индуктивный класс ”, которое определяется следующим образом. Индуктивный класс Z определяется начальными правилами и правилами порождения. Начальные правила определяют начальные элементы, которые образуют класс, называемый базисом В. Правила пополнения определяют фиксированный, но не обязательно конечный, класс способов комбинации M (по сути это функциональные символы Fi, каждый из которых имеет свою степень (арность), так что Fi (Z) : Zn® Z).
Класс Z замкнут относительно функциональных символов из M. Считается также, что каждый элемент Z может быть получен с помощью эффективного процесса.
Если с этих позиций рассматривать классы ИО, то можно установить следующее. Начальное правило сформулируем так: начальным элементом класса номинальных ИО является пустой ИО Х0 = <Ø, Ø, Ø, Ø,> и алфавит символов языка, используемого для построения имен ИО, обозначим его как АN0, то есть: В=(х0, АN0).
Алфавит АN0 можно уточнить для каждой конкретной реализации РИИС, в общем виде будем рассматривать его как АN0 = (d0,d1, … , dm).
Порождение имени ИО легко описать соответствующей контекстно-свободной грамматикой (КСГ) и обозначить результат этого конструктивного процесса как N0 = FN0(АN0). Конкретный вид такой грамматики будет уточняться на стадии построение языка системного проектирования РИИС.
Правила порождения ИО класса Кном приобретают вид:
1) N0 = FN0(АN0)
2) <Х0> & N0 Þ <N0, Ø, Ø, Ø >
Второе правило можно рассматривать как продукцию или функцию подстановки Fпод от Х0 и N0, то есть: Оном = Fпод ( <X0>, N0) = < N0, Ø, Ø, Ø >.
Таким образом, класс номинальных ИО является индуктивным классом, очевидно рекурсивно перечислимым и разрешимым (или определенным в терминологии Х. Карра), так как легко построить эффективный процесс распознавания принадлежности произвольного ИО классу Кном.
Далее, переходим к классу однопараметрических ИО. В качестве базиса этого класса следует рассматривать класс Кном с алфавитом АN0, поскольку имена объектов и атрибутов целесообразно задавать в одном алфавите, АSA – алфавит для задания множеств определения атрибутов, АVA– алфавит для задания множеств значений атрибутов. Базис К1-П приобретает вид:
В1-П = ( Кном , АN0 , АSA , АVA ).
Порождение атрибута также можно описать КСГ, тогда правила порождения ИО класса К1-П приобретают вид:
1) А = FA ( АN0 , АSA , АVA ).
2) О1-П = F1-П ( Кном , А ) = < N0,А, Ø, Ø >.
Класс однопараметрических ИО также является индуктивным классом, рекурсивно перечислимым и разрешимым. Продолжая такое индуктивное построение, для класса n-параметрических ИО получим:
Вn -П = ( Кn -1 , АN0 , АSA , АVA ).
Здесь Кn -1 - класс n-1 параметрических информационных объектов.
Правила порождения:
1) А = FA ( АN0 , АSA , АVA ) = <NA, SA, VA >,
2) Оn-П = Fn-П ( Кn-1-П , А ) = < N0,А, Ø, Ø >,
3) Если для данного Оn-П $i ((NAi = NAn) ® An := < Ø, Ø, Ø >) и вернуться к правилу 1), иначе считать результатом Оn-П .
В правиле 3) мы учитываем требования неповторяемости имен атрибутов данного ИО.
Для класса объектов-оболочек (ПИОО) базисом можно считать:
ВПИОО = ( Кном , АУК ),
где АУК – алфавит для построения указателей на информационные объекты множества {O}. Естественно полагать, что множество {O} содержит не сами ИО, а указатели на них, что соответствующим образом интерпретируется и в разделе 4.3.
Поступаем аналогично классам n-параметрических ИО, то есть сначала строим класс ” одно-вложенных ” ПИОО.
Соответственно, для класса ” n-вложенных ” ПИОО имеем базис:
ВПИОО (n -В ) = ( К ПИОО(n-1-B) , АУК ),
и правила порождения:
1) УК = FУК (АУК),
2) ОПИОО ( n-В) = Fn- В ( КПИОО ( n -1- B) , УК )
3) Если для данного ОПИОО(n-B) $i ((УКi = УКn) ® УКn := Ø), то перейти к правилу 1), иначе считать результатом ОПИОО( n - B) .
Совершенно аналогично классу n-параметрических ИО в правиле 3) учитываем требования неповторяемости указателей в множестве {O} данного ИО. Повторение указателей означает либо избыточность (в случае если они ссылаются на один и тот же ИО), либо ошибку соответствия (вложенный ИО не имеет правильного указателя на себя в {O} ).
Класс пассивных (структурных) ИО можно индуктивно построить двумя различными путями:либо в качестве базиса выбрать класс К( n - П) , либо считать базисом класс КПИОО ;
Для первого случая:
ВПИО = ( К(n-П) , АУК ).
Далее осуществляем индукцию по числу вложенных ИО:
2) ОПИО( n - В, n -П) = Fn-П ( К(n -1 - П, n –B) , А )
3). Если для данного ОПИО (n – B ,n - П) $i ((NAi = NAn) ® An := < Ø, Ø, Ø >),то перейти к правилу 1), иначе считать результатом ОПИОО( n - В, n -П).
Из наличия этих двух способов следует, что индуктивный класс КПИО(n -В, n - П)политектоничен.
Перейдем теперь к рассмотрению класса примитивных ИО. Легко заметить, что базисом для построения этого класса может служить класс параметрических ИО, так как различие между ними заключается только в наличии модели поведения ВМ. Следовательно,
ВПр.ИО = ( КП , ККвм ),
где КП – класс параметрических ИО, ККвм – класс моделей поведения. Класс ККвм задается каноническим исчислением КВМ, рассматриваемым в разделе 3.4.3, и является сам индуктивным классом, поэтому можем построить правила порождения для КПр.ИО :
Здесь FВМ – функция получения конкретной модели поведения из класса ККвм и класса КП для данного параметрического ИО. Она является двуместной функцией, так как множество {А} участвует и в построении модели поведения. FПр.ИО – функция подстановки модели поведения в структуру параметрического ИО. Класс непримитивных ИО может быть построен на основе класса ПИО с базисом:
Таким образом, множество ИО может быть определено как индуктивный класс, имеющий базис:
ВИО = ( КПр.ИО , КНПр.ИО, КПИО ),
и правило порождения:
1) ИО = FИО ( КПр.ИО , КНПр.ИО , КПИО ),
где FИО – функция выбора информационных объектов из классов базиса ВИО .
3.4.3. Модели поведения информационных объектов
Введение понятия «модель поведения» позволяет естественным образомразделить ИО на два класса: активные (ВМ¹0) и пассивные (ВМ=0).
Активными ИО (АИО) будем называть такие ИО, у которых модель поведения непуста, т.е. они обладают собственным поведением и могут выполнять некоторые активные действия. Пассивными ИО (ПИО) назовем ИО, не обладающие собственным поведением, пассивно участвующие в реализации некоторых действий. В класс ПИО попадают определенные ранее структурные информационные объекты (СИО) и однопараметрические ИО (ОПИО).
Авторы предполагают, что взаимодействие АИО осуществляется через прием и передачу ПИО, при этом в модели поведения АИО могут порождаться необходимые ПИО и передаваться другому ИО. Этот информационный обмен можно трактовать как передачу сообщений, обмен сигналами, изменение входных сигналов и тому подобное, что поволяет рассматривать парадигму «источник-приемник» в широком смысле, вместо парадигмы «клиент-сервер».
Основной содержательной идеей данного раздела является предположение о том, что в зависимости от вида математического формализма, определяющего модель поведения ИО, возможно построение различных объектных теорий.
Традиционным средством описания поведения объектов в объектно-ориентированных методах и системах является модель конечного автомата (КА).
В качестве более универсального средства определения поведения ИО авторами предлагается использовать аппарат канонических исчислений Э.Поста [4].
Начнем рассмотрение этого вопроса с определения поведения КА средствами канонического исчисления (КИ). Как было показано авторами в работах [123, 124], это построение приобретает следующий вид.
Каноническим исчислением (КИ) называется четверка вида [4]:
(A, а, P, G) , (1)
где A - алфавит исчисления, а-список аксиом КИ, P - алфавит переменных, G-список правил вывода, каждое из которых имеет вид:
где (i=1,...m: j=1, ..n ) и G (k=1, ..n+1) - некоторые конкретные слова в алфавите A, в том числе и пустое слово. Далее воспользуемся определениями, введенными в [5, 6]. Число m называется индексом схемы (2). Реализующим набором схемы (2) называется выражение вида:
,
где - список (без повторений) всех переменных, входящих в (2), а - слово в алфавите A, называемое значением переменной в данном реализующем наборе, (i=1,2,...,f). Если вместо каждого вхождения каждой переменной в схему (2) подставить значение этой переменной в R(R- это конкретный реализующий набор схемы (2)), то все строки схемы превратятся в слова в алфавите A. Так получается реализация производящей схемы (2) реализующим набором R. Конструктивный объект называется реализацией схемы (2), если он является реализацией схемы каким-либо реализующим набором. Слово Q называется словом непосредственно выводимым по схеме (2) из слов , если выражение
является реализацией схемы (2). Список слов называется выводом в КИ, если каждое слово этого списка является аксиомой данного КИ или непосредственно выводимо по какой-нибудь схеме из слов, предшествующих этому слову в рассматриваемом списке. Длиной вывода называется число слов в выводе. Слово P называется выводимым в КИ, если можно построить вывод в КИ, последним словом которого является P.
Понятия вывода и выводимости в КИ позволяют определить эквивалентность исчислений и их отношения с понятием множества (2). Если алфавит содержит A, то оно называется исчислением над A. Два исчисления над A эквивалентны относительно A, если любое слово в A выводимо в первом исчислении тогда и только тогда, когда оно выводимо во втором. Пара
(A, T) , (3)
где T - каноническое исчисление над A, является представлением множества выводимых в T слов алфавита A. При этом A называется основным алфавитом представления, а дополнение до полного алфавита исчисления T называется вспомогательным алфавитом, при этом говорят, что T строго представляет множество выводимых в нем слов. Множество M слов в A перечислимо, если для него существует представление (3).
Рассмотрение вопроса о корректности продукционных моделей, построенных средствами канонических исчислений Поста и их позднейших модификаций показало возможность представления отношений, функций и алгоритмов, и применимость некоторых традиционных методов анализа логической непротиворечивости для КИ. Исследовалась представимость n-арных отношений, частично рекурсивных функций и произвольных алгоритмов.
Анализ свойств замкнутости рекурсивно перечислимых множеств показывает, что алгоритмически неразрешимые проблемы остаются неразрешимыми и в аппарате КИ.
В качестве моделей дискретно-детерминированных объектов во многих случаях используются конечные автоматы. Как известно, классический КА задается схемой вида:
, (4)
где {X} - множество входных сигналов(символов) КА, {Y} - множество выходных сигналов(символов), {S} - множество внутренних состояний автомата, S - начальное состояние автомата, , f -функция переходов и p-функция выходов.
Поскольку абстрактный КА реализует некоторое отображение множества слов входного алфавита Х на множество слов выходного алфавита Y , то можно считать его семиотической моделью, доступной для рассмотрения в терминах КИ. Построим КИ, описывающее функционирование КА. При этом выявляется тот факт, что для задания самого процесса функционирования КА необходимо задать последовательность поступающих на его вход сигналов. Схема (4) не учитывает этот факт, то есть не отражает зависимость поведения КА от условий внешней среды. Каноническое исчисление Q, моделирующее поведение конечного автомата U, можно задать следующим образом:
, (5)
где множества {X},{Y} и {S} составят алфавит КИ, аксиома задает начальное состояние КА, -состояние выхода при , p-переменная исчисления, задающая последовательность входных сигналов:
где
Множество правил вывода П будет иметь вид:
Последнее правило, завершающее работу исчисления при окончании входной последовательности:
Нетрудно видеть, что исчислением вида (4) можно определить работу как автомата Мура, так и автомата Мили. За рамками W остается формирование последовательности p. В каждом конкретном случае возможно построение p с помощью отдельного исчисления.
Для формализации модели поведения ИО введем: {R} – множество принимаемых данным объектом ПИО, {T} – множество передаваемых данным объектом ПИО.
Полагаем, что ВМ оперирует с множествами {A}, {R} и {T}. Поскольку для каждого атрибута Ai, множество на котором он определен SAi может иметь различную природу, то элементы этого множества можно интерпретировать весьма широко: как программные коды, вызовы функций операционной системы (например, Windows), графические структуры и т.д.
Представляется необходимым введение понятия состояния ИО в ВМ и выделение двух типов состояний:
a) состояния, в которых возможен прием элементов множества {R}, в дальнейшем обозначенных как Ri;
b) состояния, в которых невозможен прием Ri.
Так как в модели поведения необходимо учитывать соотношение атрибутов и содержание Ri, то необходимо введение предикатов, которые будут образовывать множество допустимых предикатов:
{Pr} = (Pr1, Pr2, ..., Prj).
Для анализа сложных условий и соотношений будем строить формулы над предикатами в языке исчисления высказываний и обозначать их как F(Pr) или просто F.
Теперь становиться возможным построение КИ формализующего модель поведения в рамках рассматриваемой объектной теории.
Алфавит исчисления КВМ определим следующим образом:
В него включаем символы языка ИО для построения формул F.
Алфавит переменных будет включать переменные P = (p, q, f, hA), где р – последовательность входящих ПИО, q –последовательность выходящих ПИО, f – последовательность формул с предикатами Pr в ИО, hA – список атрибутов ИО, для которого строится ВМ.
Аксиому исчисления зададим как:
А = (Æ # S0 # hA(0) # Æ # Æ),
где Æ означает пустое состояние переменной, под hA(0) понимается список вида:
< NA1, SA1, VA1(0) >
< NA2, SA2, VA2(0) >
...
< NAn, SAn, VAn(0) >,
где VAi(0) обозначает значение i-го атрибута в момент времени t=0, то есть в момент начала функционирования ИО.
Правила вывода для исчисления КВМ будем строить как схемы правил, поскольку в конкретной ВМ будет получаться различное количество правил вывода, имеющих вид, удовлетворяющий предлагаемым схемам:
Схемы (1) и (2) задают правила, выводящие из состояния S0 в состояние типа a) и b) соответственно. Для обозначения невозможности обработки входной последовательности Ri используется служебный символ Ñ. В этих схемах порождается выходящий ПИО Ti и формула Fi, при этом мы допускаем возможность задания Ti=Æ и Fi=Æ, что позволяет избежать лишних схем вывода.
Схемы (3) и (4) определяют переходы из состояний типа а) в состояния типа а), с анализом истинности Fi или без анализа. Допускаем также, что в Fi может быть задана формула (ØFi), то есть проверяется истинность отрицания некоторой формулы. Такое расширение допустимо, так как в ИВ истинность или ложность любого высказывания может быть точно установлена. Обработанная формула Fi исключается из дальнейшего процесса вывода. При циклическом поведении ИО необходимая формула может снова порождаться схемами (3).
Схема (5) задает переход из состояния типа а) в состояние типа b) без анализа F, а схема (6) – с анализом F.
Схемы (7), (8) определяют переходы из состояний типа b) в состояния типа а), а схемы (9) и (10) из состояний типа b) в состояния типа b).
В этих схемах правил закладывается возможность возврата в состояние S0 и останова при переходе в такое состояние Sj, из которого нет возможности дальнейшего вывода.
В схемах правил вывода (1)-(10) задаются в общем виде функциональные преобразования hA(Si), которые можно определить как преобразования над значениями атрибутов.
VAi := f(k)(VAj1, ..., VAjk),
где k – арность функционального символа, VAjj – j-ый аргумент функции f(k), взятый из списка значений атрибутов, причем SAi º SAj1 º SAj2 º ... º SAjk, то есть значения VAj1, ..., VAjk должны быть определены на одном и том же множестве.
3.4.4 Свойства модели поведения информационного объекта
Основной абстрактной составляющей модели поведения ИО является определенное в предыдущем разделе исчисление КВМ, точнее класс подобных исчислений, так как правила вывода в КВМ являются обобщенными схемами.
Изучение свойств КВМ начнем с установления факта необходимой вычислительной мощности этого исчисления, то есть способности его смоделировать алгоритмы, понимаемые в духе теории рекурсивных функций и машин Тьюринга – Поста.
В соответствии с [125] и тезисом Тьюринга класс функций, алгоритмически вычисляемых относительно какой-либо функции h, совпадает с классом частичных функций, частично рекурсивных относительно h.
Известно, что частично рекурсивной называется такая частичная функция, которая может быть получена из простейших функций Q, S, конечным числом операций подстановки, примитивной рекурсии и минимизации.
Поэтому для доказательства алгоритмической полноты КВМ необходимо и достаточно будет показать, что простейшие функции Q, S, - операции подстановки, примитивной рекурсии и минимизации моделируются этом исчислением. По определению
S1(x) = x+1,
Qn(x1, ..., xn) = 0,
(x1, ..., xn) = xm (1 £ m £ n; n = 1,2,...).
Эти функции моделируется средствами КИ следующим образом. Функция S1(x) моделируется правилами вида:
Здесь мы не рассматриваем всю структуру посылок и заключений, так как в данном случае анализируется только локальная функция (подстановка). Функция Qn(x1, ..., xn) моделируется правилами вида:
Функция (x1, ..., xn) моделируется так:
Как известно, операция подстановки определяется следующим образом. Если заданы n каких-либо частичных функций f1, ..., fn от одного и того же числа переменных m, определенных на множестве А со значениями в множестве В, и на множестве В определена частичная функция f от n переменных, значение которой принадлежит некоторому множеству С. Тогда функция
Полагаем, что поскольку частичные функции f1, f2, ...,fn определены, то существуют выводы y1®f1(x1, ...,xm), y2®f2(x1, ...,xm), ..., yn®fn(x1, ...,xm). Это предположение справедливо, потому что в качестве функций f1, f2, ...,fn нам достаточно рассматривать простейшие функции S1, Qn , , а они, как было показано выше, моделируются средствами КИ.
Операция примитивной рекурсии определяется для (n+1)-местной частичной функции f из n-местной частичной функции g и (n+2)-местной частичной функции h:
Для нахождения значений функции f известна алгоритмическая процедура, так для получения значения f(a1, ..., an, m+1) достаточно последовательно найти значения:
b0 = g(a1, ..., an)
b1 = h(a1, ..., an, 0, b0)
b2 = h(a1, ..., an, 1, b1)
...
bm+1 = h(a1, ..., an, m, bm)
Эта процедура естественным образом моделируется в КИ. Задаем аксиому вида:
a: ...#a1#a2...#an#...
Если существует вывод a®g(a1, ..., an), то получаем b0 применением правила:
Далее можно построить КИ, моделирующие работу функции h. Для этого строим b1 следующим образом:
полагая, что существует вывод h(a1, ..., an, 0, b0).
Последующие значения bi можно получить применением правила:
где переменная q хранит текущее значение yi(1,2,...,m), а переменная b содержит текущее значение bi, равное h(a1, ..., an, q, bi-1).
Операция минимизации рассматривается для n-местной (n³1) частичной числовой функции f. Если зафиксировать значения первых n-1 аргументов функции f и рассмотреть уравнение:
f(x1, ..., xn-1, y) = xn,
то, вычисляя последовательно значения f(x1, ..., xn-1, y) для y = 0,1,2,..., можно получить наименьшее значение а, для которого получится:
f(x1, ..., xn-1, а) = xn.
Это значение и считается результатом операции минимизации
My(f(x1, ..., xn-1, y) = xn).
Особенностью функции минимизации является то, что возможны граничные (исключительные) случаи, когда:
а) значение f(x1, ..., xn-1, Æ) не определено;
б) значения f(x1, ..., xn-1, y) для y = 0,1, ..., a-1 определены, но отличны от xn, а значение f(x1, ..., xn-1, а) не определено;
в) значение f(x1, ..., xn-1, y) определены для всех y = 0,1,2,... и отличны от xn.
Полагая, что существует КИ, позволяющее вычислять f(x1,x2,...,xn-1, xn), введем переменные y, b, n, m. Переменная y будет хранить значения f(x1, ..., xn-1, y), а переменная n - копию этого значения. Переменная b будет хранить xn, а переменная m - копию xn. Структуру посылок в правилах вывода определим как:
...#x1#x2#...#xn-1#y#y#b#n#m#...,
а аксиому исчисления зададим в виде:
...#x1#x2#...#xn-1###xn##xn.
Правила вывода, получающие значение f(x1, ..., xn-1, y), зададим обобщенно в виде:
Далее выполняем сравнение f(x1, ..., xn-1, y) и xn, с помощью правил:
В случае равенства f(x1, ..., xn-1, y) = xn, выполняется правило:
При неравенстве следующие правила возвращают исчисление к процессу вычислений:
Рассмотрим теперь граничные случаи для функции f. В случае а) неопределенность функции f можно установить сразу, прямо из аксиомы вывести признак неопределенности. В случае б) также можно построить правила, выявляющие ситуацию y = a и устанавливающие признак неопределенности. В случае в) процесс работы КИ никогда не останавливается, поэтому обойти эту ситуацию можно двумя путями: предварительным анализом функции f или выходом на ограничение реальной вычислительной системы.
Рассмотренные выше правила КИ, моделирующие функции S(1), Q(x1,...,xn), , примитивной рекурсии, подстановки и минимизации могут быть включены в правила исчисления КВМ, что не требует дополнительного обоснования.
Таким образом, можно считать доказанной представимость в КВМ всех частично рекурсивных функций, что достаточно для построения произвольных алгоритмов.
ЛИТЕРАТУРА К ГЛАВЕ 3
Философский энциклопедический словарь (Редакт.: С.С. Аверинцев, Э.А. Араб-Оглы, Л.Ф. Ильичев и др. – М.: Сов. Энциклопедия, 1989 – 815 с.
Kobsa A. Knowlenge Representation: a Survay of it’s Mechanisms, a Sketch of it’s Semantics // Cybernetics and Systems. – 1984, №15. - P.41-89.
Furbach U., Dirlich G., Fraksa C. Towards a Theory of Knowlenge Representation Systems // Artificial Intelligence: Methodology, Systems, Applications. Ed. By W.Bibel.-North-Holland, 1985. - P.77-84.
4. Post E.L. Formal reduсtions of the general сombinatorial problem // Amer.J.Math.-1943.- Vol.65, N2. - p. 197-215.
Маслов С.Ю. Некоторые свойства аппарата канонических исчислений Э.Л. Поста // Тр.матем.инс. АН СССР. - 1964. - Т. 72. - С. 5-56.
Маслов С.Ю. Теория дедуктивных систем и ее применения. - М.:Радио и связь, 1986. - 136с.
Shanin N.A., Davydov G.V., Maslov S.U., Mints G.E., Orevkov V.P., Slisenko A.O. An algorithm for machine search of natural logical deduction in propositional calculus/Automation of Reasoning – Classical Papers on Compitational Logic. Ed. J. Siekmann, G. Wrighston. – Springer-Verlag, Berlin. Vol. 1, 1957-1966. – 1983. – P. 424-483.
Кузнецов В.Е. Представление в ЭВМ неформальных процедур: продукционные системы. - М.: Наука, 1989.-160 с.
Кратко М.И. Формальные исчисления Поста// Проблемы кибернетики. Вып. 17. – 1966. – С. 41-65.
Кратко М.И., Плесневич Г.С. Быстрый алгоритм распознавания следствий для монадических логических программ// Автоматика и телемеханика. – 2001, №10. – С. 91-102.
Поспелов Д.А. Моделирование рассуждений. Опыт анализа мыслительных актов. – М.: Радио и связь, 1989. – 184 с.
12. Brownston L., Farrell R., Kant E., Martin N. Programming Expert Systems in OPS5 – An Introduction to Rule – Based Programming. – Reading, Mass.: Addison-Wesley, 1985. - xviii, 471 p.
Sherman P.D., Martin J.C. An OPS5 Primer: Introduction to Rule – Based Expert Systems. – Prentice Hall, Englewood Cliffs, New Jersey, 1990. – 193 p.
Хорошевский В.Ф. PIES – технология и инструментарий PIES Work Bench для разработки систем, основанных на знаниях // Новости искусственного интеллекта. – 1995, №2. – с.7-64.
Ковригин О.В., Перфильев К.Г. Гибридные средства представления знаний в системе СПЭИС // Всесоюзн. Конф. по искусственному интеллекту: Тез. докл. – Т.2. – Переславль – Залесский, 1988. – с.490 – 494.
Gupta A. Parallelism in Production Systems. – Morgan Kaufmann Publishers, Les Altos, CA, 1987. – 224 p.
Neiman D. Design and Control of Parallel Rule – Firing Production System. In PhD Thesis – Computer Science Department. University of Massachusetts at Amherst, 1992.
18. Ceccato, Silvio. Linguistic analysis and programming for mechanical translation (mechanical translation and thought). - Milan, G. Feltrinelli; New York, Gordon and Breach,1961. - 242 p.
19. Masterman, Margaret. Semantic message detection for machine translation, using an interlingua/ Proc. 1961 International Conf. on Machine Translation. – P. 438-475.
20. Brachman, Ronald J. On the epistemological status of semantic networks, in Findler Nicholas V. Ed. Associative Networks: Representation and Use of Knowledge by Computes. – Academic Press, N.Y. 1979. – pp. 3-50.
21. Woods, William A. What's in a link: foundations for semantic networks, in D. G. Bobrow & A. Collins, eds. Representation and Understanding. - Academic Press, New York, 1975. - pp. 35-82.
22. Chakravarty D., Medlin R. Building Rich-media Digital Asset Management Systems with XML. – http://www.artesia.com/pdf/info_xml.pdf.
23. Berners-Lee, Tim. WWW: Past, Present, and Future/IEEE Computer. – 1996, 29 (October). – P. 69-77.
24. Frege, Gottlob. Begrijfsschrift, English translation in J. van Heijenoort, ed. (1967)-From Frege to Godel, Harvard University Press, Cambridge, MA, pp. 1-82.
25. Peirce, Charles Sanders. On the algebra of logic/ American Journal of Mathematics. - 1880, 3. – P. 15-57.
26. Peirce, Charles Sanders. On the algebra of logic/ American Journal of Mathematics. - 1885, 7. – P.180-202.
27. Peano, Giuseppe (1889) Aritmetices principia nova methoda exposita, Bocca, Torino. Excerpt translated as, Principles of mathematics presented by a new method in van Heijenoort (1967) pp.83-97.
28. Peirce, Charles Sanders (1909) Manuscript 514, with commentary by J. F. Sowa, available at http://www.jfsowa.com/peirce/ms514.htm
29. Shapiro, Stuart C. The SNePS semantic network processing system, in Findler, Nicholas V., ed. Associative Networks:Representation and Use of Knowledge by Computers. – Academic Press, New York, 1979. - pp. 263-315.
30. Shapiro, Stuart C., & William J. Rapaport. The SNePS family, in Lehmann, Fritz, ed. Semantic Networks in Artificial Intelligence. – Pergamon Press, Oxford, 1992. - pp. 243-275.
31. Sowa, John F. Conceptual graphs for a database interface/ IBM Journal of Research and Development. - 1976, 20:4. – P. 336-357.
32. Sowa, John F. Conceptual Structures: Information Processing in Mind and Machine. – Reading: Addison-Wesley, MA, 1984. – 481 p.
33. Sowa, John F. Knowledge Representation: Logical, Philosophical, and Computational Foundations. - Brooks/Cole Publishing Co., Pacific Grove, CA. 2000. – 594 p.
34. Rieger Chuck. An organization of knowledge for problem solving and language comprehension/ Artificial Intelligence. – 1976, V. 7, 2. – P. 89-127.
35. Kuipers Benjamin. Qualitative Reasoning: Modeling and Simulation with Incomplete Knowledge. – Cambridge, MA: MIT Press, 1994. – 414 p.
36. Pearl Judea. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. – San Mateo, Calif.:Morgan Kaufmann Publishers, 1988. - xix, 552 p.
37. Doyle J. A truth maintence system/Artificial Intelligence. – 1979, 12. – P. 231-272.
38. Kleer de J. A Perspective on Assumption-Based Truth Maintenance/Artificial Intelligence. – 1993, 59(1-2). - P. 63-67.
39. Qullian M. R. Semantic memory. In Semantic Information Processing/ Eds. M.Minsky. – Cambridge, MA: MIT Press, 1968. – P. 227-270.
40. Fahlman, Scott E. NETL: A System for Representing and Using Real-World Knowledge. - MIT Press, Cambridge, MA. 1979. – 278 p.
41. Hendler, James A.Integrating marker-passing and problem-solving: a spreading activation approach to improved choice in planning/ James A. Hendler. - Hillsdale, N.J.: Lawrence Erlbaum Associates, 1988. - 307 p.
42. Hendler, James A. Massively-parallel marker-passing in semantic networks, in Lehmann Fritz, Ed. Semantic Networks in Artificial Intelligence. - Pergamon Press, Oxford, 1992. - pp. 277-291.
43. Shastri L. Semantic Networks: An Evidential Formalization and its Connectionist Realization/Researh Notes in Artificial Intelligence. – London: Pitman, 1988. – 222 p.
44. Levesque, Hector, & John Mylopoulos. A procedural semantics for semantic networks,in Findler Nicholas V., ed. Associative Networks:Representation and Use of Knowledge by Computers. – Academic Press, New York, 1979. - pp. 93-120.
45. Mylopoulos, John. The PSN tribe, in Lehmann Fritz, Ed. Semantic Networks in Artificial Intelligence. Pergamon Press, Oxford. 1992. - pp. 223-241.
46. Hendrix G.G. Expanding the utility of semantic networks through partitioning//Proc.of Int.Joint Conf. on Artificial Intelligence, Tbilisi, Georgia, 1977. – Pp. 115-121.
47. Осипов Г.С. Метод формирования и структурирования модели знаний одного типа предметных областей//Изв. АН СССР. Техн. кибернетика. – 1988. – №2. – С. 3-12.
48. Осипов Г.С. Построение моделей предметных областей. Неоднородные семантические сети// Изв. АН СССР. Техн. кибернетика. – 1990. - №5. – С. 32-35.
49. Осипов Г.С. Построение баз знаний на основе взаимодействия полуавтоматических методов приобретения знаний//Изв. РАН. Теория и системы управления. – 1995. - №5. – С. 65-80.
Осипов Г.С. Приобретение знаний интеллектуальными системами. Основы теории и технологии. – М.: Наука, 1997. – 112 с.
OMG Unified Modeling Language Specification. Version 1.3. June 1999. – 808 p.
52. Kent, Stuart, Andy Evans,& Bernhard Rumpe, eds. UML Semantics FAQ, http://www.cs.ukc.ac.uk/pubs/1999/977/content.pdf
Цейтин Г.С. Программирование на ассоциативных сетях // ЭВМ в проектировании и производстве. Вып 2. – Л.: Машиностроение, 1985. – с.16-48.
Robinson J.A. A Machine-Oriented Logic Based on the Resolution Principle // J. ACM, 1965. – Vol. 12. – P. 23-41.
55. Гильберт Д., Бернайс П. Основания математики. Логические исчисления и формализация арифметики. – М.: 1979. – 560 с.
Клини С. Математическая логика. – М.: Мир, 1973. – 480 с.
Карри Х.Б. Основания математической логики. – М.: Мир, 1969. – 568 с.
Ершов Ю. Л. Палютин Е.А. Математическая логика. – М.: Наука, 1979. – 320 с.
Slagle J. Automatic Theorem Proving with Renamable and Semantic Resolution // J. ACM. –V.14, 1964. – p. 687 – 697.
Luckham D. Referement Theorems in Resolution Theory/ Proc. IRIA Symposium on Automatic Demonstration (Versailles, France). Lecture Notes on Mathematics. № 125. - Springer – Verlag, Berlin&N.Y. – 1970. – P. 163-190.
Reither R. N. Closed World Data Bases. Logic and Data Bases / H. Gallaire and J. Minker, Eds. – Plenum Press, N.Y., 1978. – p. 55 – 78.
Kowalski R., Kuchner D. Linear Resolution with Selection Function // Artificial Intelligence. - 1971, 2. – p. 227-260.
Loveland D.W. A Unifying View of Some Linear Herbrand Procedures // J.ACM. – V.19., 1972. – p. 366-384.
Plaisted D.A. Theorem Providing with Abstraction //Artificial Intelligence. – 1981, 16. – p. 47-108.
Artificial Intelligence / Ed. Margaret A. Boden. – Academic Press. – San Diego etc. – 1996. XVIII, 376 p.
Meinke K., Tucker J.V. Eds. Many sorted logic and its applications. – Joan Wiley and Sons. - Chichester, 1993. - 397 p.
Kelly Jonh J. The Essence of Logic. – London; New York: Prentice Hall, 1997. – 258 p.
Nerode A., Shore R.A. Logic for Applications. – New York: Springer, 1993. – 456 p.
Blackburn P., De Rijke M., Venema Y. Modal Logic. – New York: Cambridge University Press, 2001. – 554 p.
Clocksin W.F. Mellish C.S. Programming in Prolog. – Springer – Verlag, Berlin. – 1984. – 324 p.
Маллас Дж. Реляционный язык Пролог и его применение: Пер. с англ./ Под ред. В.И. Соловьева. – М.: Наука, 1980. – 464 с.
Tu Prolog Documentation. The tu Prolog Development Group. – DEIS – University of Bologna, Italy. - 2001. – http://www-lia.deis.unibo.it/Research/2P/
74. Java 2: Руководство разработчика/ Морган М. -М. и др. : Вильямс, 2000. –719 с.
Touretzky D.S. The Mathematics of Inheritance Systems. – London: Pitman, 1986. – 220 p.
Mc. Dermott D., Doyle J. Non-monotonic logic I // Artificial Intelligence. - V.13, N.1-2, 1980. - Pp. 41-72.
Mc. Dermott D., Doyle J. Non-monotonic logic II: non-monotonic nodal theorems // J.ACM. – V.29, N1, 1982. - Pp. 34-57.
Reiter R.A. A logic for default reasoning // Artificial Intelligence. - V.13, N.1-2, 1980. – Pp. 81-131.
Reiter R.A., Criscuolo G. On interacting Defaults. / Proc. IJCAI-81., 1981. – Pp. 270-276.
Moore R.C. Possible-world semantics for auto-epistemic logic. / Proc. AAAI – Worcshop on Non-Monotonic Reasoning, New Platz, N.Y. Oct. 1984. – Pp. 344-354.
Moore R.C. Semantical considerations on non-monotonic logic // Artificial Intelligence. - V.25. N.1., 1985. – P. 75-94.
Минский М. Фреймы для представления знаний: Пер. с англ. – М.: Мир, 1979. – 152 с.
83. Байдун В.В., Бунин А.И. Средства представления и обработки знаний в системе FRL/PS// Всесоюзная конференция по искусственному интеллекту: Тезисы доклада Т.1. – Минск, 1990. – с. 66-71.
84. Уотерман Д. Руководство по экспертным системам: Пер. с англ. – М.: Мир, 1989. - 388 с.
85. Стрельников Ю.Н., Борисов Н.А. Разработка экспертных систем средствами инструментальной оболочки в среде MS Windows. – Тверь, ТГТУ, 1997. – с.
86. Sisodia R., Warkentin M. AI in business and management // PC AI. – 1992, Jun/ Feb. – P. 32-34.
Базы знаний интеллектуальных систем / Т.А. Гаврилова, В.Ф. Хорошевский. – СПб.: Питер, 2000. – 384 с.
Гаврилова Т.А., Червинская К.Р. Извлечение и структурирование знаний для экспертных систем. – М.: Радио и связь, 1992. – 200 с.
Konar, Amit. Artificial intelligence and soft computing: behavioral and cognitive modeling of the human brain/ Amit Konar. – Boca Raton, CRC Press, 2000. – 786 p.
Солсо Р. Когнитивная психология: Пер. с англ. – М.: Тривола, 1996. – 600 с.
Мельчук И.А. Русский язык в модели «Смысл-Текст». - Москва – Вена: Школа «Языки русской культуры», 1995. – XXVIII с, 682 с.
92. Харламов А.А., Ермаков А.Е., Кузнецов Д.М. и др. Система для автоматической смысловой обработки текстов на основе нейросетевой технологии “TextAnalyst for Lotus Notes”. //Информационные технологии. - 1999. - N 10. - С. 27-29.
93. Смирнов Ю. М., Андреев А. М., Березкин Д. В., Брик А. В.. Об одном способе построения синтаксического анализатора текстов на естественном языке // Изв. вузов. Приборостроение. - 1997, Т. 40, № 5 — C. 34—42.
94. Алешин В.С., Швецов А.Н. Анализ информационных потоков на предприятии/ Вузовская наука региону: Материалы первой обл. межвузовск. науч.-практич. конф. в 2-х т. – Вологда: ВоГТУ, 2000. – С. 156-157.
95. Алешин В.С., Швецов А.Н. Семантический анализ информационных потоков предприятия/ Информатизация процессов формирования открытых систем на основе СУБД, САПР, АСНИ и искусственного интеллекта: Материалы межд. науч.-техн. конф. – Вологда: ВоГТУ, 2001. – С. 193 – 196.
96. Алешин В.С., Швецов А.Н. Применение семантических сетей для анализа текстовой производственной документации/ Моделирование, оптимизация и интенсификация производственных процессов и систем: Материалы Междунар. научно-техн. конф. – Вологда: ВоГТУ, 2001. – С. 211-213.
Wilks Y. Parsing English II // Computational Semantics/ Eds. Y. Wilks, E. Sharniak. - N.Y.: North-Holland, 1976. - p.155-184.
Построение экспертных систем/ Под ред. Ф. Хейес-Рот., Д. Уотерман, Д. Ленат.- М.: Мир, 1987. – 441 c.
Kaplan R. M., Berry-Rogghe G. Knowledge based acquisition of causal relation ships in text// Knowledge Acquisition. - 1991. - N3. - p. 317-337.
100. Gaines B., Shaw M. Integrated knowledge acquisition architectures/Journal for Intelligent Information Systems. – 1992, 1(1). – P. 9—34.
101. Философская энциклопедия. Т. 4. – М.: Сов. Энциклопедия, 1967. – 592 с.
102. Cocchiarella N.B. Formal Ontology. In H.Burkhard and B.Smith (Eds.), Handbook of Metaphysics and Ontology. - Philosophia Verlag, Munich: 1991. – P. 640-647.
103. McDermott D. A Critique of Pure Reason/Computational Intelligence. - 1987, 3. – P. 151-160.
104. Hayes P. The Second Naive Physics Manifesto. In J.R.Hobbs and R.C.Moore (Eds.). Formal Theories of the Commonsense World. - Ablex, Norwood, New Jersey: 1985. – P. 1-36.
105. Guarino N., Giaretta P. Ontologies and Knowledge Bases: Towards a Terminological Clarification. In N.Mars (Eds.). Towards Very Large Knowledge Bases: Knowledge Building and Knowledge Sharing. - IOS Press, Amsterdam: 1995. – P. 25-32.
106. Brachman R.J. On the Epistological Status of Semantic Networks. In. N.V. Findler (Ed.) Associative Networks: Representation and Use of Knowledge by Computers. - Academic Press: 1979. – P. 3-50.
107. Guarino, N., Carrara, M. and Giaretta, P. An Ontology of Meta-Level Categories/ {KR}'94: Principles of Knowledge Representation and Reasoning. Eds. J. Doyle, E. Sandewall, P. Torasso. - San Francisco, California: Morgan Kaufmann, 1994. - P. 270—280.
108. Davis R., Shrobe D.A., Szolovits P. What is a Knowledge Representation / AI Magazine (Spring 1993). – P. 17 – 33.
109. Guarino N. A Concise Presentation of ITL. In H. Boley and M.M. Richter (Eds.) Processing Declarative Knowledge. - Springer Verlag: 1991. – P. 141 – 160.
110. Lenat D.B. CYC: A Large – Scale Investment in Knowledge Instructure // Communications of the ACM. – 1995, 38(11). – P. 33-48.
111. Braetman J.A., Magnini B., Rinaldi F., 1994. The Generalized Italian, German, English Upper Model// ECAI’94, Amsterdam.
112. Benjamins R., Fensel D. The Ontological Engineering Initiative-KA2. In N. Guarino, editor, Proceedings of the 1st International Conference on Formal Ontologies in Information Systems, FOIS'98, Trento, Italy. - IOS Press, 1998. - 287--301.
113. Heflin J., Hendler J., Luke S. Reading Between the Lines: Using SHOE to Discover Implicit Knowledge from the Web // In AAAI–98 Workshop on AI and Information Integration. Available online at http://www.cs.umd.edu/projects/plus/SHOE/shoe-aaai98.ps.
114. Information Integration for Concurrent Engineering (IICE). IDEF5 Method Report. - KBSI. – 1994.
115. Menzel C. P. Ontology-Driven Information Integration // http://www.kbsi.com/Research/OntologyModeling/odii.html.
116. Швецов А.Н., Черепанов А.В. Проблемы информационной интеграции в комплексных проектах/ Информатизация процессов формирования открытых систем на основе СУБД, САПР, АСНИ и искусственного интеллекта: Материалы межд. науч.-техн. конф. – Вологда: ВоГТУ, 2001. – С. 203 – 206.
117. Черепанов А.В., Швецов А.Н. Использование расширенного онтологического метода информационной интеграции IDEF5 в решении задач комплектации/ Мат-лы Международ. Научно-техн. Конф. «Инфотех-2001». – Череповец: ЧГУ, 2002. – С. 140-142.
118. TOVE Manual. – Department of Industrial Engineering, University of Toronto. – http://www.ie.utoronto.ca/EIL/tove.
119. Гладкий А.В. Формальные грамматики и языки. – М.: Наука, 1973. - с.
120. Глушков В.М., Цейтлин Г.Е., Ющенко Е.Л. Алгебра, языки, программирование. – Киев: Наукова думка, 1974. – 328 с.
121. Справочная книга по математической логике: в 4-х частях /Под ред. Дж. Барвайса. – Ч.1. Теория моделей: Пер. с англ. – М.: Наука, 1982. – 392 с.
122. Френкель А., Бар-Хиллел И. Основания теории множеств/ Пер. с англ. Под ред. Н.А. Шанина. – М.: Мир, 1966. - 610 с.
123. Швецов А.Н., Суконщиков А.А. Канонические исчисления Поста как средство моделирования сложных дискретных систем/ Автоматизация процессов управления и обработки информации: Сб. статей. – Вологда:ВоПИ, 1998 - С. 128 – 135.
124. Суконщиков А.А., Швецов А.Н., Беляев А.О. Выбор аппарата формализации для моделирования сложных систем/Сборник научных трудов института в 2-х т. Вологда: ВоПИ, 1998. – С. 82 –84.
125. Мальцев А.И. Алгоритмы и рекурсивные функции. – 2-е изд. – М.: Наука, 1986. – 398 с.
ФГБОУ ВПО «Оренбургский государственный
аграрный университет»
Кафедра автоматизированных систем обработки информации и управления
Н. П. МОШУРОВ
СИСТЕМЫ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Конспект лекции
Оренбург
УДК
ББК
С
Рекомендовано к изданию редакционно – издательским советом Оренбургского государственного аграрного университета (председатель совета – В. В. Каракулев)
Рецензенты:
Доктор тех. наук, профессор В. Н. Шепиль (Оренбургский государственный университет),
канд. физ.- мат. наук, доцент Е. А. Корнев (Оренбургский государственный университет)
Системы искусственного интеллекта : конспект лекций / Н. П. Мошуров. – Оренбург : Оренб. гос. аграрный университет 2011. – с.
В конспекте лекций по системам искусственного интеллекта для студентов факультета информационных технологий излагается содержание учебного материала изучаемого в седьмом семестре обучения.
Конспекте лекций адресованы студентам обучающимся в аграрном университете по специальностям 230102 «Автоматизированные системы обработки информации и управления».

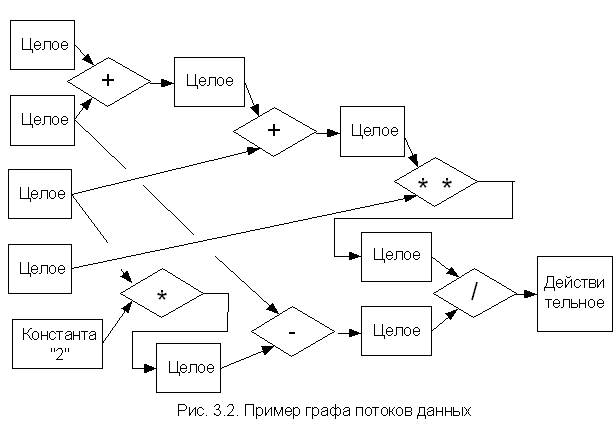

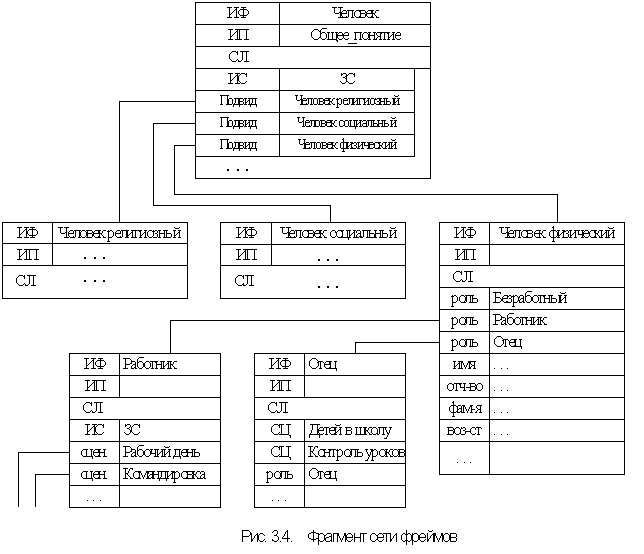
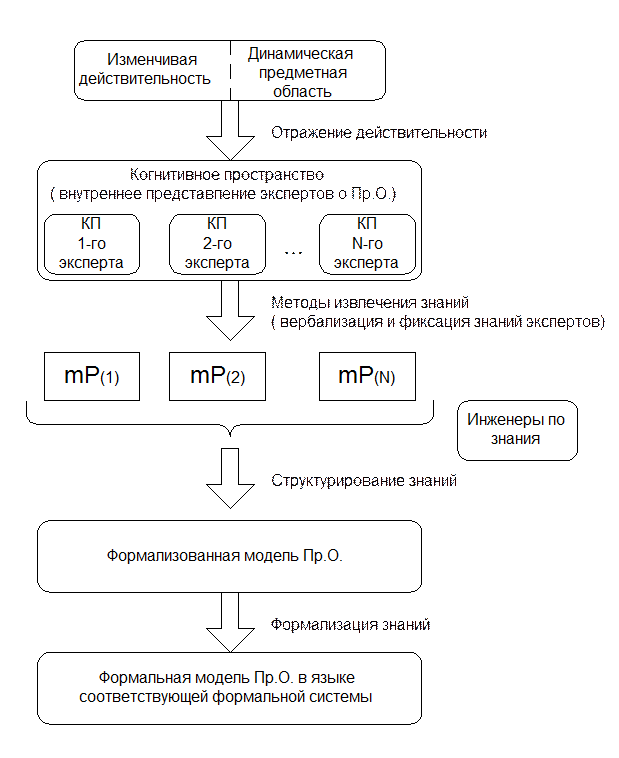
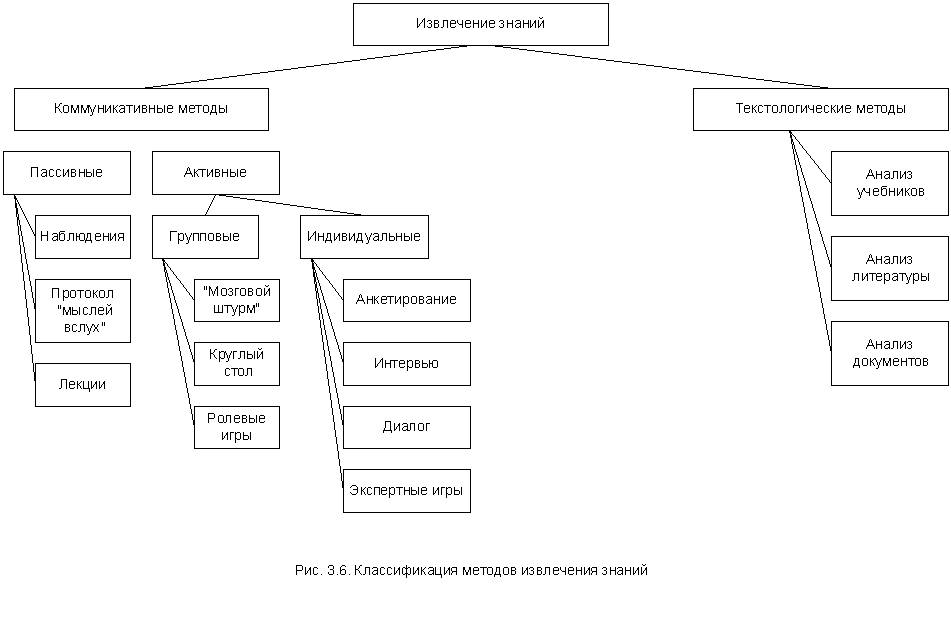


 Для самого себя объект х не обеспечивает истинности Rs. Поэтому для всех х аксиома Rs(1) является тавтологией.
Для самого себя объект х не обеспечивает истинности Rs. Поэтому для всех х аксиома Rs(1) является тавтологией.






 Вариант 3. Два объекта х и у входят в объект z:
Вариант 3. Два объекта х и у входят в объект z:

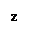 В этом случае Rs(x,y)=f, Rs(y,z)=t, Rs(x,z)=t
В этом случае Rs(x,y)=f, Rs(y,z)=t, Rs(x,z)=t




 Имеем Rs(x,y =t, Rs(y,z)=t, Rs(x,z)=t, тогда
Имеем Rs(x,y =t, Rs(y,z)=t, Rs(x,z)=t, тогда




 Rs(x,y) = f, Rs(y,x) = t и
Rs(x,y) = f, Rs(y,x) = t и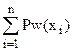 , где хÎ{< NO, {A}, (x1, x2, ..., хn), BM >}.
, где хÎ{< NO, {A}, (x1, x2, ..., хn), BM >}.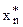 , включающий хn и xn+1.
, включающий хn и xn+1.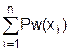 = Pw(x1) +
= Pw(x1) + ) + Pw(
) + Pw(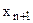 )
)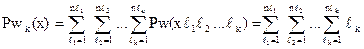 , когда все хℓ1ℓ2 ... ℓk являются примитивными информационными объектами и ℓk = Pw(хℓ1ℓ2 ... ℓk).
, когда все хℓ1ℓ2 ... ℓk являются примитивными информационными объектами и ℓk = Pw(хℓ1ℓ2 ... ℓk).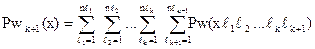
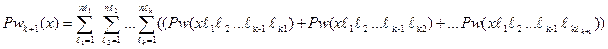 Раскрывая скобки, получим:
Раскрывая скобки, получим:
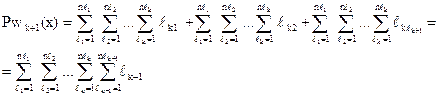
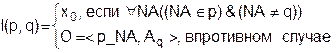
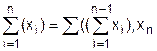 .
. .
.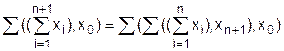
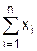 дает некоторый ОПИО, который обозначим как М. Тогда получаем:
дает некоторый ОПИО, который обозначим как М. Тогда получаем:
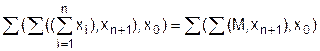
 и тогда
и тогда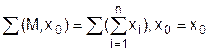 по посылке индукции.
по посылке индукции.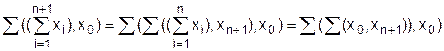

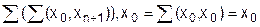
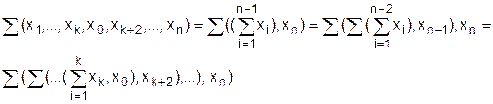
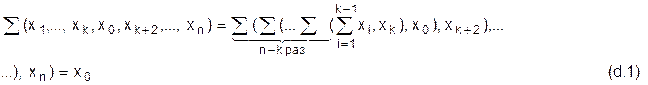
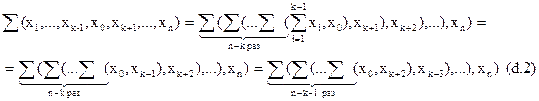
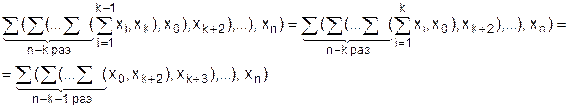

 (2)
(2)
 (i=1,...m: j=1, ..n ) и G (k=1, ..n+1) - некоторые конкретные слова в алфавите A, в том числе и пустое слово. Далее воспользуемся определениями, введенными в [5, 6]. Число m называется индексом схемы (2). Реализующим набором схемы (2) называется выражение вида:
(i=1,...m: j=1, ..n ) и G (k=1, ..n+1) - некоторые конкретные слова в алфавите A, в том числе и пустое слово. Далее воспользуемся определениями, введенными в [5, 6]. Число m называется индексом схемы (2). Реализующим набором схемы (2) называется выражение вида: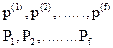 ,
,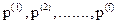 - список (без повторений) всех переменных, входящих в (2), а
- список (без повторений) всех переменных, входящих в (2), а  - слово в алфавите A, называемое значением переменной в данном реализующем наборе, (i=1,2,...,f). Если вместо каждого вхождения каждой переменной в схему (2) подставить значение этой переменной в R(R- это конкретный реализующий набор схемы (2)), то все строки схемы превратятся в слова в алфавите A. Так получается реализация производящей схемы (2) реализующим набором R. Конструктивный объект называется реализацией схемы (2), если он является реализацией схемы каким-либо реализующим набором. Слово Q называется словом непосредственно выводимым по схеме (2) из слов
- слово в алфавите A, называемое значением переменной в данном реализующем наборе, (i=1,2,...,f). Если вместо каждого вхождения каждой переменной в схему (2) подставить значение этой переменной в R(R- это конкретный реализующий набор схемы (2)), то все строки схемы превратятся в слова в алфавите A. Так получается реализация производящей схемы (2) реализующим набором R. Конструктивный объект называется реализацией схемы (2), если он является реализацией схемы каким-либо реализующим набором. Слово Q называется словом непосредственно выводимым по схеме (2) из слов 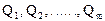 , если выражение
, если выражение
 , (4)
, (4)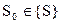 , f -функция переходов и p-функция выходов.
, f -функция переходов и p-функция выходов.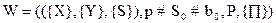 , (5)
, (5)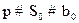 задает начальное состояние КА,
задает начальное состояние КА, 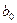 -состояние выхода при
-состояние выхода при  , p-переменная исчисления, задающая последовательность входных сигналов:
, p-переменная исчисления, задающая последовательность входных сигналов: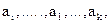 где
где 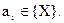

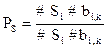

 конечным числом операций подстановки, примитивной рекурсии и минимизации.
конечным числом операций подстановки, примитивной рекурсии и минимизации.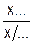
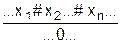


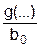
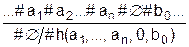
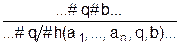
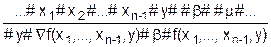
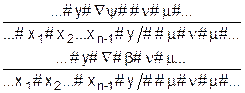
 , примитивной рекурсии, подстановки и минимизации могут быть включены в правила исчисления КВМ, что не требует дополнительного обоснования.
, примитивной рекурсии, подстановки и минимизации могут быть включены в правила исчисления КВМ, что не требует дополнительного обоснования.