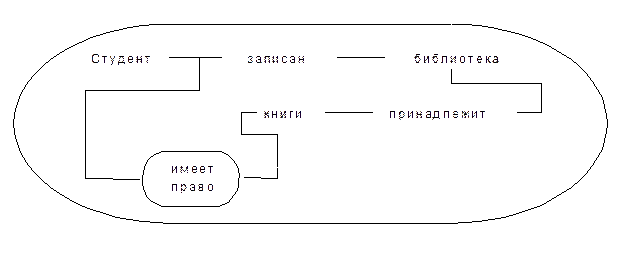Прямоугольники представляют собой пассивные узлы, а ромбы - активные. Метки пассивных узлов обозначают типы данных, метки активных узлов – выполняемые над данными операции.
В РАСПРЕДЕЛЕННЫХ ИНТЕЛЛЕКТУАЛЬНЫХ ИНФОРМАЦИОННЫХ СИСТЕМАХ
Модели представления знаний
С.А. Яковлев
Санкт-Петербургский государственный университет
Закрытие потока
Поток закрывается либо при завершении программы, либо явным образом с помощью функции fclose:
int fclose (FILE *);
Перед закрытием потока информация из связанных с ним буферов выгружается на диск. Рекомендуется всегда явным образом закрывать потоки, открытые для записи, чтобы избежать потери данных.
5.4 Обработка ошибок
Функции работы с потоком возвращают значения, которые рекомендуется анализировать в программе и обрабатывать ошибочные ситуации, возникающие, например, при открытии существующих файлов или чтении из потока. При работе с файлами часто используются функции feof и ferror.
int feof (FILE *) – возвращает не равное нулю значение, если достигнут конец файла, в противном случае 0,
int ferror (FILE *) – возвращает не равное 0 значение, если обнаружена ошибка ввода / вывода, в противном случает 0.
Пример 20. В файле хранятся сведения о мониторах. В каждой строке указан тип, оптовая и розничная цены и примечание. Для простоты данные в каждой стоке записаны однообразно – первые 20 символов занимает тип монитора, далее по 5 символов – на цены (целые числа), затем примечание длиной не более 40 символов. Приведенная ниже программа считывает данные из текстового файла в буферную переменную s, затем формирует из них структуру mon.
#include <iostream.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{ FILE *fi;
if ((fi=fopen (“d:\\c\\file.txt”, “r”))==0)
{cout << “Error”;
return 1;
}
const int dl = 70;
char s[dl];
struct {
char type[20];
int opt, rozn;
char comm[40];
} mon;
while (fgets (s, dl, fi))
{//преобразование строки в структуру
strncpy(mon.type, s, 19);
mon.type[19] = ‘\0’;
mon.opt = atoi(&s[20]);
mon.rozn = atoi (&s[25]);
strncpy(mon.comm, &s[30], 40);
}
fclose (fi);
return 0;
}
Функция strncpy – копирует первые n символов одной строки в другую.
Функция atoi (const char *p) – преобразует переданную строку в int.
аэрокосмического приборостроения”
ОГЛАВЛЕНИЕ
3.1.
Проблема представления знаний о предметной области
3.1.1.
Продукционные модели
3.1.2.
Семантические сети
3.1.2.1.
Сети определений
3.1.2.2.
Сети логических выражений
3.1.2.3.
Импликационные сети
3.1.2.4.
Исполняемые сети
3.1.2.5.
Обучаемые сети
3.1.2.6.
Гибридные сети
3.1.3.
Формальные логические модели
3.1.4.
Фреймы
3.2.
Теоретические методы извлечения и структурирования знаний
3.3.
Онтологические модели и системы
3.4.
Основы теории информационных агентов РИИС
3.4.1.
Построение формальной объектной аксиоматизируемой системы
3.4.2.
Теоретико-множественные свойства информационных объектов
3.4.3.
Модели поведения информационных объектов
3.4.4.
Свойства модели поведения информационного объекта
ЛИТЕРАТУРА к части 3
3.1. Проблема представления знаний о предметной области
Наверное, нет ни одной книги, посвященной искусственному интеллекту, где бы ни обсуждался вопрос о содержании понятий «данные» и «знания», о методах и формах представлений знаний.
Если с философских позиций знание рассматривается как отражение объективных характеристик действительности в сознании человека [1], то как рассматривать знание с позиций разработчика интеллектуальных систем? Можно утверждать, что на сегодняшний день нет общепринятого определения понятия «знание» в области информационных систем. Так как знание идеально, первоначально связано с субъектом, то оно нуждается в объективизации, которая и осуществляется в технологиях и информационных системах. Знание при этом объективизируется средствами знаковых систем – естественных и искусственных языков.
Поэтому, по мнению авторов, знание в искусственных интеллектуальных системах следует трактовать как объективизированные представления (модели) некоторой области окружающего мира (или предметного области), выраженные средствами определенных знаковых систем.
При этом знания проходят путь от внутренних репрезентаций в сознании человека к описанию на языке представления знаний и далее к базам знаний на различных носителях информации.
Знаниям, содержащимся в информационных системах, приписывают такие свойства как структурированность, связность, интерпретируемость, наличие метрических свойств, активность, функциональную целостность.
Структурированность знаний выражается в возможности декомпозиции предметной области на составляющие подобласти или структуры информационных единиц (объектов) и возможности синтеза новых информационных объектов в соответствии с семантическими и прагматическими свойствами объекта.
Связность определяет наличие между объектами предметной области разнообразных отношений, которые могут быть описаны в языках представления знаний. Интерпретируемость предполагает возможность отображения обобщенной модели предметной области на конкретное множество объектов, при этом интерпретация сложных теоретических построений может иметь опосредованный характер и включать иерархические системы промежуточных интерпретаций. В этом ракурсе можно рассматривать, например, переход от знаковой модели информационной системы к исполняемым модулям, реализованным в кодах конкретной вычислительной системы.
Наличие метрических свойств позволяет выполнять оценки семантической близости и различия информационных объектов.
Активность – это потенциальная способность систем, основанных на знаниях к самоорганизации, к саморазвитию. Структуры знаний имеют не только собственное смысловое содержание, но и процедуральные компоненты, реализуемые в системах продукций, алгоритмах и других формализмах представления конструктивных преобразований.
Функциональная целостность выражает интегрированность, самодостаточность, и автономность знаний и когнитивных систем, связанные с их внутренней активностью и качественным своеобразием. Целостность указывает на необходимость выявления внутренней детерминации свойств искусственных интеллектуальных систем и на недостаточность объяснения их специфики, исходя только из условий окружающей среды.
В ряде исследований определяются те виды знаний, которые должны быть представлены в интеллектуальных системах [2,3] :
– структуры, формы, свойства, функции и возможные состояния объектов;
– возможные отношения между объектами и возможные события, участниками которых могут быть объекты;
– физические законы;
– возможные эффекты действий и состояний, причины и условия возникновения событий и состояний;
– возможные намерения, цели, планы, соглашения и т.п.
Следует отметить, что перечень этот весьма обширен и в конкретных интеллектуальных системах используются лишь некоторые из перечисленных выше структур знаний. Для всех интеллектуальных систем существуют общие проблемы, а именно:
– приобретение новых знаний и их взаимодействие с существующими;
– определение объема представляемой предметной области и степени детализации объектов и событий в конкретной системе;
– выбора пропорций декларативного и процедурного представления знаний.
Знания принято классифицировать на поверхностные и глубинные, декларативные и процедурные. Поверхностные знания – это знания об очевидных взаимосвязях и отношениях между объектами и событиями в предметной области. В отличие от них глубинные знания выражаются в абстракциях, моделях, аналогиях, отображающих структуру и природу процессов, существующих в предметной области. Глубинные знания могут быть использованы для предсказания поведения объектов.
Декларативные модели представления знаний содержат знаковые (семантические) структуры знаний и механизм вывода, оперирующий на структурах знаний и практически независимый от их содержания. Это позволяет разделить синтаксические и семантические аспекты структур знаний и получить весьма универсальные модели.
Процедурные модели содержат знания в алгоритмическом или программном представлении, явно определяя выполняемые действия в тех или иных ситуациях. При этом не обязательно описывать все возможные состояния среды или объекта, а достаточно хранить лишь начальные состояния и процедуры, генерирующие необходимые описания ситуаций и действий. В этих моделях семантические свойства моделируемой предметной области непосредственно закладываются в элементы баз знаний, что повышает эффективность поиска решений.
Для повышения эффективности генерации вывода в процедурных моделях используются знания о применении, которые говорят о том, каким образом использовать накопленные знания для решения конкретных задач.
Достоинствами процедурных моделей являются хорошая эффективность механизмов вывода, большая выразительная сила, но они проигрывают по степени общности декларативным моделям.
Большинство существующих моделей представления знаний в интеллектуальных системах могут быть сведены к следующим классам:
– продукционные модели;
– формальные логические модели;
– семантические сети;
– фреймы.
3.1.1. Продукционные модели
Продукционные модели достаточно давно и широко используются в интеллектуальных системах. Основы продукционного формализма были заложены Э.Л. Постом (Post E.L.) [4]. В нашей стране продукционные системы и исчисления развивались С.Ю. Масловым [ 5,6 ], Н.А. Шаниным [ 7 ], В.Е. Кузнецовым [ 8 ], Кратко М.И. [9, 10].
Продукцию можно рассматривать как структуру вида:
,
где a1, a2 … an – посылки ( условия) продукции, z – заключение ( действие). В словесной форме продукционные правила представляются в виде предложений типа: « Если ( условие ), то ( действие )». Под условием, называемым также антецендентом, понимается совокупность образов, имеющихся в базе знаний или рабочей памяти интеллектуальных систем, а под действием (консеквентом), действия выполняемые при успешном выполнении правила продукции.
Продукционную систему можно определить как структуру вида:
SP = ( A, V, P ),
где А – алфавит условного языка, V – алфавит переменных, Р – конкретное множество продукций.
Интересную классификацию продукционных правил разработал Д.А. Поспелов [11]. Он представил интеллектуальную систему как совокупность базы знаний К и «рассуждающей» системы R (системы логического вывода). Система R обменивается информацией с базой знаний К и внешним миром W.
Представим типы продукций в форме следующей таблицы.
Таблица 3.1
Классификация продукционных правил по Д.А.Поспелову
Тип продукции
Содержательное описание
AW Þ BR
Информация, поступившая из внешнего мира, приводит к изменению хода рассуждений в R.
AW Þ BK
Информация из внешнего мира запоминается в базе знаний.
AK Þ BW
Информация из базы знаний передается во внешний мир.
AR Þ BK
Информация, полученная рассуждающей системой, передается на хранение в базу знаний.
AK Þ BR
Необходимая для рассуждений информация выбирается из базы знаний и передается в R.
AW Þ BW
Продукция непосредственного отклика. АW описывает некоторую наблюдаемую ситуацию в W или воздействие W на R. BW описывает действие, которое поступает от системы в W. Рассуждающая система не успевает срабатывать, а лишь транслирует информацию об АW и BW адресатам.
AR Þ BW
Определяет воздействия на W, которые возникают как результат работы R.
AR Þ BR
Внутренние продукции R, описывают промежуточные шаги процессов вывода и не влияют непосредственно на базу знаний и состояние W.
AK Þ BK
Процедуры преобразования знаний в базе знаний: обобщение знаний, получение новых знаний из ранее известных, установление закономерностей.
Поэтому в обобщённой форме продукционные правила могут иметь вид:
П, Р, А => В, Q.
Здесь А => В – ядро продукции, Р – условие применимости, П – предусловие применимости, характеризующие сферу проблемной области БЗ, Q – постусловие продукции, определяющие те изменения, которые необходимо ввести в БЗ и в систему продукций после реализации данной продукции.
Продукционные модели являются удобным и достаточно понятным средством представления знаний, хорошо воспринимаются психологически, что очень важно при разработке интеллектуальных и экспертных систем.
Основными модулями продукционной системы являются:
- БД (структурированная или неструктурированная);
- набор продукционных правил;
- интерпретатор, обрабатывающий продукции.
База данных хранит известные системе факты о состоянии предметной области. В результате выполнения продукций могут активироваться процедуры, которые автоматически манипулируют содержимым БД, подключают новые факты, с которыми могут быть связаны новые продукции.
Классические продукционные системы отвечают требованиям модульности, правила вывода могут добавляться и удаляться без возникновения неожиданных побочных эффектов. В традиционном виде такие системы не содержат сведений о применении, что снижает эффективность вывода, так как требуется проверять условия активации всех продукций.
Поэтому для решения проблемы «комбинаторного взрыва» разработаны методы структурного совершенствования БД и условий в продукциях. Если в данном цикле продукционной системы существует несколько правил, условия которых определены, то применяемое правило выбирается с помощью установленной стратегии разрешения конфликтов. Возможно также осуществление точного контроля за последовательностью выполнения продукций с помощью специальных сигналов, подключающих соответствующие продукции в других циклах.
Существует достаточное количество инструментальных программных средств, позволяющих создавать продукционные интеллектуальные системы (OPS5 [12, 13], ПИЭС [14], СПЭИС [15] ).
Для повышения быстродействия продукционных систем исследуются методы параллельного управления и параллельного выполнения продукционных правил, позволяющие увеличить эффективность выполнения в десятки раз. Не имея возможности детально рассматривать эти вопросы, мы отсылаем читателя к первоисточникам [16, 17].
Продукционные методы будут применяться нами при построении теории информационных агентов РИИС (см. главу 3 и главу 4), где некоторые математические аспекты построения канонических исчислений будут рассмотрены более подробно.
3.1.2. Семантические сети
Семантические сети (СС) объединяют под общим названием большую совокупность моделей представления знаний, которые часто имеют только формальное сходство. Существуют различные мнения о том, какие синтаксические и семантические конструкции должны для этого использоваться.
Общим для всех СС является декларативное графическое представление, которое может быть использовано или для представления знаний или для поддержки автоматизированных систем, осуществляющих вывод на знаниях. Некоторые версии являются в значительной степени неформальными, но другие являются формально определенными логическими системами.
Анализ многочисленных источников позволяет выделить следующие виды семантических сетей:
1.Сети определений выражают подтип или is-а отношение между концептуальным типом и вновь определяемым подтипом. Результирующая сеть, называемая также обобщающей или подстановочной иерархией, может поддерживать правило наследования для конкретных свойств, определенных для супертипа по отношению ко всем его подтипам.
2. Сети логических выражений. В отличие от сетей определений информация в логических сетях предполагается истинной, если не эксплицитно маркируется модальными операторами. Некоторые логические сети могут служить моделями концептуальных структур лежащих в основе семантики естественных языков.
3. Импликационные сети используют импликацию как первичное отношение для связываемых узлов. Они могут использоваться для представления образов убеждений, причинности или влияния.
4. Исполняемые сети включают некоторый механизм, такой как передача маркера или назначаемые процедуры, которые могут преобразовывать влияние, посылать сообщения и производить выполнение некоторых действий, связанное с передачей результатов.
5. Обучаемые сети строят или расширяют свои представления, извлекая знания из примеров. Новое знание может изменять старую сеть, добавляя или удаляя узлы и дуги или модифицируя числовые величины, называемые весами, связанные с узлами или дугами.
6. Гибридные СС комбинируют два или более вида описанных выше сетей, либо в одной сети, либо в раздельных, но взаимодействующих между собой сетях.
3.1.2.1. Сети определений
Старейшая известная семантическая сеть была изображена в 3 веке н.э. греческим философом Порфирием в его комментарии к аристотелевским категориям. Порфирий использовал СС, чтобы проиллюстрировать аристотелевский метод определения категории, специфицируя “genus” или общий тип и “differential”, который разделяет различные подтипы некоторого супертипа. Первая реализация СС была использована для определения концептуальных типов и образцов отношений для систем машинной трансляции. Сильвио Цеккато (Silvio Ceccato, 1961) [18] разработал корреляционные сети (correlation nets), которые были основаны на 56 различных отношениях, включая подтип, экземпляр, часть – целое, причинные отношения, родственные отношения, и различные виды атрибутов. Он использовал корреляции как образы для управления синтаксическим анализатором и разрешением синтаксических двусмысленностей. Система М. Мастермэн (Margaret Masterman) из Кембриджского университета была впервые названа СС [19]. Она разработала список из 100 примитивных концептуальных типов и в терминах этих примитивов определила концептуальный словарь с 15*103 входами и организовала концептуальные типы в решетку, которая осуществляет наследование из множественных супертипов. Базовые принципы и даже многие примитивные концепты «выжили» в более поздних системах семантик предпочтения (preference semantics).
Сети определений фомализуются дескрипционными логиками (description logics), которые включают дерево Порфирия и используют различные расширения. Они проистекают из подхода, предложенного Вудсом (Woods) и реализованного Брахмэном (Brachman) в системе Knowledge Language One (KL-ONE) [20, 21].
KL-ONE и многие версии дескрипционных логик являются подмножествами классической логики первого порядка. Они принадлежат к классу монотонных логик, в которых новая информация монотонно увеличивает число возможных теорем, а старая информация может быть удалена или модифицирована. Некоторые версии дескрипционных логик поддерживают немонотонный вывод, в котором правила по умолчанию (default rules) добавляют необязательную информацию, а исключающие правила (canceling rules) блокируют унаследованную информацию. Такие системы могут быть использованы для многих приложений, но они могут порождать проблемы конфликтующих определений (conflicting defaults).
Хотя базовые методы дескрипционных логик стары как Аристотель, они составляют важную часть многих версий СС и других видов систем. Например, такие логики как DAMI и OIL расширяют представление знаний в семантике Web для такой гигантской семантической сети, каковой является Internet [22, 23].
3.1.2.2. Сети логических выражений
Готлиб Фреге (Gottlob Frege) разработал нотацию в форме дерева для первой завершенной версии логики первого порядка [24], а Чарльз Сандерс Пирс (Charles Sanders Peirce) независимо построил алгебраическую нотацию [25, 26], которая с измененными Пеано (Peano G.) [27] символами стала современной нотацией исчисления предикатов.
Хотя Пирс и ввел алгебраическую нотацию, он никогда не был полностью удовлетворен ею и искал графическую нотацию, подобную нотации используемой в органической химии, чтобы более ясно показать “атомы и молекулы логики”. Он предложил реляционные графы (relation graphs), которые представляли два логических оператора: конъюнкцию (&) и квантор существования $. Другие операторы, такие как отрицание (¬), дизъюнкция (È), импликация (É), квантор всеобщности ("), более трудно выразить, потому что они требуют некоторого метода обозначения области действия, чтобы было очевидно какая часть формулы каким оператором управляется.
В 1897 году Пирс нашел простое решение этой проблемы: он ввел овал, который может покрывать и отрицать произвольно большой граф или подграф. Комбинации овалов с конъюнкцией и квантором существования могут выразить все логические операторы, используемые в алгебраической нотации [28]. Это нововведение трансформирует реляционные графы в систему экзистенциальных графов (existential graphs (EG)), которую Пирс назвал «логикой будущего».
Позднее были разработаны пропозициональные СС (propositional semantic networks), реализованные в системе искусственного интеллекта MIND и создана система SNEPS (semantic network processing system), которая может быть использована для представления широкого диапазона характеристик в семантиках естественных языков [29, 30].
Концептуальные графы [31, 32, 33] являются видом пропозициональных СС, в которых отношения размещаются внутри пропозициональных узлов. Сопоставим представление одного и того же логического утверждения в системе экзистенциональных графов (EG) и концептуальных графов (CG). Возьмем утверждение: «Если студент записан в библиотеку, то он имеет право брать там книги». С позиций формальной логики это утверждение подразумевает существование студента, некоторой библиотеки и книг, принадлежащих этой библиотеке. Студент должен быть связан с этой библиотекой отношением «записан». Отображения данного утверждения в соответствующие графы показаны на рис.3.1.
Экзистенциальный граф
Концептуальный граф
Рис.3.1. Представление утверждения через EG и CG
Эти графические структуры эквивалентны следующему выражению в логике первого порядка:
В EG каждый прямоугольник, называемый концептом (concept), представляет собой квантор существования ($x:Студент) или ($y:Библиотека), который проходит через всю область анализа, а в CG концепт, также изображаемый прямоугольником представляет квантор ($x:Студент) или ($y:Библиотека), который ограничен типом или сортом переменной Студент или Библиотека. В CG дуги со стрелками показывают аргументы отношения (числа используется для различия дуг отношений с более чем двумя аргументами). Узлы [ Т ] представляют аналог указателя «он » или «это», которые связаны с их антецендентами пунктирными линиями, называемыми отсылочными связями (coreference link).
Существует возможность трансляции утверждений выраженных в SNePS или CG в эквивалентные утверждения в других нотациях.
Различные версии пропозициональных СС имеют различные синтаксические механизмы для связи относительного содержания с пропозициональными узлами, но могут быть определены правила формальной трансляции для перехода от одной версии к другой.
3.1.2.3. Импликационные сети
Импликационные сети являются специальным случаем пропозициональных СС, в которых первичным отношением является импликация. Другие отношения могут быть размещены внутри пропозициональных узлов, но они используются ссылочными процедурами. В зависимости от интерпретации, такие сети можно назвать сетями убеждений, причинными сетями, Байесовскими сетями или системами, устанавливающими истину.
Такие сети были использованы в различных системах искусственного интеллекта. Чак Ригер (Chuck Rieger) [34] разработал версию каузальных сетей, которые он использовал для анализа проблемных описаний в английском языке и поддержки вывода на метауровне.
Бенджамин Купер (Benjamen Kuipers) [35] разработал метод качественного вывода, который служит мостом между символическими методами искусственного интеллекта и дифференциальными уравнениями. Джуди Перл (Judea Pearl) [36] ввел сети убеждений (belief networks), которые являются каузальными сетями, связи в которых помечены вероятностями.
В импликационных сетях применяются два основных подхода к организации выводов: логический и вероятностный.
Логический подход используется в системах устанавливающих истину (truth-maintenance systems(TMS)) [37, 38]. ТМS пытается стартовать с узлов, для которых известны истинностные значения и распространить их через сеть. Комбинацией восходящего и нисходящего вывода TMS распространяет истинностные значения в узлы для которых их истинностные оценки неизвестны. Основываясь на дедукции новой информации, TMS можно применять для проверки корректности, поиска противоречий, или нахождения положений, где ожидаемые импликации не выполняются. При нахождении противоречия структура сети может быть изменена добавлением или удалением узлов, в результате получается немонотонный вывод, называемый ревизией убеждений (belief revision).
При вероятностном подходе используется оценка истинности в диапазоне вероятности 1.0-0.0. Наиболее детально вероятностный вывод в каузальных сетях или сетях убеждений разработан Д. Перлом [36].
Хотя импликационные сети придают особое значение импликации, они позволяют выразить все логические операторы через конъюнкцию входов пропозиционального узла и дизъюнкцию выходов.
3.1.2.4. Исполняемые сети
Исполняемые СС содержат механизмы, которые могут вызывать некоторые изменения в самой сети. Три вида таких механизмов широко используются в исполняемых СС:
1. Механизм сообщений (massage passing) позволяет передавать данные из одного узла в другой. Данные могут быть единичными битами, называемыми маркерами или триггерами, а могут быть и числовыми весами или произвольно большими сообщениями.
2. Механизм связанных процедур, которые являются программами, содержащимися в узле или связанными с узлом, который выполняет некоторые виды действий или вычислений над данными в этом же узле или соседних узлах.
3. Механизм трансформации графов комбинируют графы, модифицируя их, или сокращая в меньшие графы. В типичных системах доказательства теорем такие трансформации проводятся внешними программами над графами.
Эти механизмы могут сочетаться в различных комбинациях. Один из таких комбинированных подходов предложил Куллиан (Ross Quillian) [39], который в отечественной литературе по ИИ почему-то рассматривается как основатель семантических сетей вообще, с чем конечно трудно согласиться.
Куллиан ввел алгоритм передачи маркера для протяженных активаций, который был адаптирован в более поздних системах NETL [40] и в массовых параллельных алгоритмах [41, 42, 43].
Простейшими сетями со связанными процедурами являются графы потоков данных (dataflow graph), которые содержат пассивные узлы, хранящие данные, и активные узлы, которые берут данные из входных узлов и посылают результаты в выходные узлы. Типичный пример можно построить для операторов присваивания в языках программирования (рис.3.2): Х=(А+В+С)**D/B-2*С.

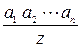 ,
,