Стек удобен для вычисления значения арифметического выражения, представленного в обратной польской (бесскобочной) записи. Такие вычисления с помощью стека реализуются, например, во многих калькуляторах.
4. Очереди.Очереди – хорошо известные структуры данных, организованные по принципу "первым пришел – первым ушел" (FIFO – First In First Out). Это динамические структуры, число элементов которых может меняться в процессе обработки.
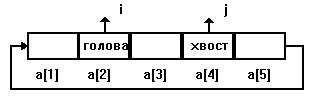
Элементы, находящиеся в середине очереди между ее первым и последним элементами, недоступны для обработки. Следовательно, в очереди доступны только два элемента: первый ("голова") и последний ("хвост"). Над первым элементом выполняются операции чтения и обработки, над последним – операция записи в очередь.
Для отображения очереди используется одномерный массив a[1], a[2], ... a[n], причем длина n этого массива выбирается с таким запасом, чтобы длина очереди (число ее элементов) не превышала n.
При отображении очереди на одномерный массив можно поступить так: первый элемент очереди хранить в первом элементе массива, записывая вновь поступающие элементы в следующие свободные элементы массива. После обработки первого элемента массива он удаляется из очереди и на его место переписывается следующий за ним (второй) элемент. Это приводит однако и к перемещению всех следующих элементов очереди: на место второго будет переписан третий, на место третьего – четвертый и т.д. Очевидно, что данный способ не очень эффективен, хотя и отражает реальный процесс движения очереди.
На практике для отображения очереди применяют другой способ, использующий два указателя, один из которых указывает на элемент массива, хранящий "голову" очереди, а другой на элемент массива, предназначенный для записи очередного элемента очереди ("хвост"). В этом случае динамика движения очереди находит отражение в перемещении указателей по элементам массива.
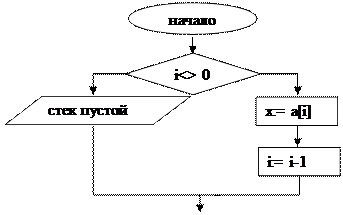
Пусть i – индекс элемента массива, хранящего "голову" очереди, а j – индекс первого свободного элемента массива, куда поступает новый элемент очереди ("хвост"). Тогда выборка очередного элемента очереди сводится к выполнению операций
x := a[i];
i := i + 1.
После этого индекс i указывает на следующий очередной элемент очереди, т.е. "головой" становится следующий по порядку элемент.
Запись нового элемента y в очередь сводится к выполнению операций
a[j]:=y;
j := j + 1.
Элементы очереди могут поступать и обрабатываться неравномерно, поэтому длина очереди будет изменяться, в частности возможен случай, когда очередь окажется пустой. Признаком этого может служить равенство значений i = j после чтения головного элемента очереди.
В процессе обработки очереди ее элементы будут смещаться к концу массива, т.к. индекс j увеличивается после каждой записи в очередь. Поэтому возможен случай, когда j > n после записи в очередь очередного элемента.
При этом необходимо сместить очередь в начало массива, т.е. положить i = 1 и последовательно переписать все элементы очереди в элементы массива начиная с a[1].
Чтобы избежать такой дополнительной работы, можно считать массив замкнутым по кольцу, т.е. элементом, следующим за последним элементом массива, считать его первый элемент. Тогда при j > n "хвост" очереди перемещается в начало массива.
Отображение очереди на "кольцевой" массив из пяти элементов можно представить так:
Хотя значение n выбирается достаточно большим, все-таки возможен случай, когда после записи в очередь очередного элемента выполняется условие j = i. Это означает, что "хвост" совпадает с "головой" очереди, т.е. происходит ее переполнение. Здесь, как и в случае пустой очереди, необходимо выдать соответствующее сообщение.
Алгоритмы записи в очередь и чтения из очереди могут быть представлены в виде:
алгоритмзапись_в_очередь;
a[j] = y;
еслиj n
то j := j + 1
иначеj := 1
все;
если j = i
товывод ( 'переполнение очереди')
алгоритмчтение_из_очереди;
x := a[i];
еслиi n
то i := i + 1
иначеi := 1
все;
если i = j
товывод ( 'пустая очередь')
5. Строки.Строка - последовательность символов из некоторого алфавита. Основные операции, выполняемые над строками, состоят в последовательном переборе символов строки, включении в строку нового символа, исключении из строки заданного символа, включении или выключении группы подряд идущих символов (подстроки).
При отображении строк на одномерный массив можно поступать так же, как и при отображении очередей, т.е. размещать последовательные символы строки в последовательных элементах массива. Но в этом случае включение или исключение символа приведет к раздвижке или сжатию строки, что вызовет перемещение других символов строки, начиная с места разрыва по элементам массива. Поэтому такое представление для строк уже мало пригодно.
Для представления строк, как и некоторых других структур данных, применяют принцип, состоящий в том, что каждый элемент структуры отображается на несколько соседних элементов массива, часть которых содержит информацию о данном элементе структуры, а другая часть – ссылки на соседние элементы структуры.
По этому принципу каждый элемент строки может быть отображен на два соседних элемента массива – в одном из этих элементов записывается данный символ строки, а в другом элементе – ссылка на следующий символ строки, т.е. индекс первого из двух элементов массива, на которые отображен следующий символ строки. Каждые два элемента массива, на которые отображается один символ строки, называется звеном. С помощью ссылок звенья сцепляются в цепочку, причем соседние звенья совсем не обязательно должны занимать соседние элементы массива - они могут следовать в произвольном порядке по элементам массива, а их истинный порядок в цепочке определяется с помощью ссылок.
Строка из трех символов 'n2c' может быть размещена в восьми элементах массива следующим образом:
Первые два элемента массива занимает служебная информация: первый элемент массива содержит ссылку на первое звено цепочки, а второй элемент массива - ссылку на первый свободный элемент, куда может быть записано новое звено цепочки. В каждом звене первый элемент содержит ссылку на следующее звено, а второй элемент - символ строки. Последнее звено цепочки имеет нулевую ссылку, что и является признаком конца цепочки.
a[1] = 3 – ссылка на звено 1
a[2] = 9 – ссылка на первый свободный элемент массива
a[3] = 5 – ссылка на звено 2
a[4] = 'n' звено 1
a[5] = 7 – ссылка на звено 3
a[6] = '2' звено 2
a[7] = 0 – конец цепочки
a[8] = 'c' звено 3
a[9] = свободно
При таком представлении строки включение нового символа сводится к образованию нового звена в свободном месте массива и изменению некоторых ссылок. Например, пусть строку 'n2c' нужно вставить символ 'e' после символа 'n', т.е. получить новую строку 'ne2c'. В этом случае новое звено размещается в девятом и десятом элементах массива. Меняется ссылка в звене до разрыва цепочки (в первом звене), в новом звене указывается ссылка на звено после разрыва цепочки (на третье звено), и, наконец, меняется ссылка на первый свободный элемент массива (значение ссылки увеличивается на 2). В результате получается цепочка, изображенная на схеме:
a[1] = 3 – ссылка на звено 1
a[2] = 11 – ссылка на первый свободный элемент массива
a[3] = 9 – ссылка на звено 2
a[4] = 'n' звено 1
a[5] = 7 – ссылка на звено 4
a[6] = '2' звено 3
a[7] = 0 – конец цепочки
a[8] = 'c' звено 4
a[9] = 5 – ссылка на звено 3
a[10] = 'e' звено 2
a[11] = свободно
Алгоритм включения символа в строку оформим как подчиненный алгоритм с параметрами x и k, где x – символ, включаемый в строку, а k – индекс звена цепочки, после которого включается новое звено, содержащее этот символ:
алгоритмвключение_символа(x, k);
new:= a[2] {индекс первого свободного элемента массива}
a[new +1] := x; {запись нового символа}
a[new] := a[k]; {ссылка на звено после разрыва цепочки}
a[k]:= new; {ссылка на звено до разрыва цепочки}
a[2] := a[2] + 2; {ссылка на первый свободный элемент массива}
В этом алгоритме впервые использованы комментарии, которые записываются в фигурных скобках и служат для пояснений.
Исключение символа из строки сводится к уничтожению в цепочке ссылки на исключаемый символ. Предположим, что из строки 'ne2c' необходимо исключить третий символ, т.е. перейти к строке 'nec'. Цепочка, образуемая для представления строки 'ne2c' должна быть изменена так, чтобы в ней отсутствовала ссылка на символ '2', содержащийся третьем звене. Это можно сделать, задав во втором звене ссылку на символ, следующий за символом '2', т.е. на символ 'c', иными словами, нужно выполнить команду a[9]:= 7. После этого цепочка примет вид:
a[1] = 3 – ссылка на звено 1
a[2] = 11 – ссылка на первый свободный элемент массива
a[3] = 9 – ссылка на звено 2
a[4] = 'n' звено 1
a[5] = 7 – ссылка на звено 4
a[6] = '2' исключенное звено "дырка"
a[7] = 0 – конец цепочки
a[8] = 'c' звено 3
a[9] = 7 – ссылка на звено 3
a[10] = 'e' звено 2
a[11] = свободно
Алгоритм исключения символа, оформленный в виде подчиненного алгоритма, имеет один формальный параметр k – индекс звена цепочки, за которым следует исключаемое звено:
алгоритмисключение_символа(k);
pointer:= a[k];
a[k]:= a[pointer];
Такой способ исключения символа сводится лишь к уничтожению соответствующей ссылки, хотя сам символ и остается в массиве. Только теперь этот символ недоступен для обработки (в массиве фактически образуется "дырка", куда вообще говоря, можно было бы записать новое звено. Тем не менее этого обычно не делают, чтобы не усложнять способ вычисления индекса первого свободного элемента массива.
По аналогичному принципу можно построить и более сложные алгоритмы включения и исключения подстрок.
6. Списки. Список можно рассматривать как обобщение понятия строки в том смысле, что строка - это цепочка символов, а список – это цепочка, состоящая из элементов, называемых записями.
Запись – упорядоченный набор символов. Записи могут содержать разную информацию в зависимости от того, какие объекты они описывают. Например, можно говорить о списках институтов, факультетов данного института, студентов данного курса и т.д.
Отображение списка на одномерный массив производится по тому же принципу, что и отображение строк, т.е. каждая запись отображается на несколько соседних элементов массива, образуя звено, а звенья сцепляются в цепочку с помощью ссылок.
Особенность отображения списка на массив состоит в том, что разные звенья могут занимать разное количество элементов массива, так как записи имеют, вообще говоря, разную длину. Поэтому в каждом звене различают информационную часть, на которую отображается содержательная часть записи, и справочную часть, в которой содержатся сведения о длине записи, ссылки на соседние звенья и другая справочная информация о записи.
Начальное звено содержит справочную информацию о расположении звена 1 списка и о первом свободном элементе массива, куда можно заносить новые записи списка.
Упорядоченность записей в списке задается в зависимости от его назначения. Если каждое звено содержит только одну ссылку на следующее звено списка, то такой список называют однонаправленным. Записи такого списка можно перебирать последовательно только в одном направлении, также как и символы строки.
Однако бывает необходимо обеспечить возможность просмотра записей в прямом, и в обратном направлении. В этом случае каждое звено содержит две ссылки: на предыдущее и на следующее звено цепочки. Такие списки называют двунаправленными.
Если последнее звено цепочки содержит ссылку на первое звено, как на следующее, а первое звено ссылается на последнее, как на предыдущее, то такой список оказывается замкнутым по кольцу и его называют кольцевым.
Часто списки строят по иерархическому принципу. В этом случае записи списка могут иметь внутреннюю структуру, организованную также по принципу списка (основной список оказывается состоящим из записей – подсписков).
Таким образом, сцепление звеньев списка с помощью ссылок и наличие справочной части в каждой записи позволяют создать достаточно сложные структуры списков, пригодных для разных приложений.
Задачи включения и исключения записей списка благодаря наличию ссылок могут решаться то тому же принципу, что и задачи включения и исключения символов строки. При этом новая запись заносится в свободное место массива и производится изменение соответствующих ссылок, а исключаемая запись хотя и остается в массиве, но все ссылки на нее уничтожаются, так что она становится недоступной для обработки.
Появление “дырок” в массиве в результате исключения записей порождает проблему включения освободившихся звеньев в число свободных элементов массива, которые можно использовать для размещения новых записей. Для включения “дырок” в число свободных элементов массива используют разные способы, известные под названием “сборка мусора”. Суть этих методов сводится к периодической реорганизации списка и свободных звеньев, позволяющей создать единую цепочку свободных элементов массива, пригодную для размещения новых записей.
Построение интерполяционного многочлена Лагранжа и Ньютона с использованием большого числа узлов интерполирование на отрезке [a, b] может привести к плохому приближению интерполируемой функции из-за возрастания вычислительной погрешности. Такой интерполяционный многочлен существенно проявляет свои колебательные свойства, и его значения между узлами могут значительно отличаться от значений интерполируемой функции.
Кроме того, построенный многочлен будет иметь высокую степень, что тоже весьма нежелательно. Этих неприятностей можно избежать, разбив отрезок [a, b] на частичные отрезки и построив на каждом из них многочлен невысокой степени, так или иначе приближенный к заданной функции f(x).
Одна из возможностей преодоления этого недостатка заключается в применении сплайн-интерполяции. Иногда такой прием называют кусочно-полиномиальным интерполированием.
Суть сплайн-интерполяции заключается в определении интерполирующей функции по формулам одного типа для различных подмножеств и в стыковке значений функции и ее производных на границах подмножеств.
Наиболее изученным и широко применяемым является вариант, в котором между любыми двумя точками строится многочлен п-й степени.
,
который в узлах интерполяции принимает значения интерполируемой функции и непрерывен вместе со своими (п-1)-йпроизводными. Такой кусочно-непрерывный интерполяционный многочлен называется сплайном.
Максимальная по всем частичным отрезкам степень многочленов называется степенью сплайна, а разница между степенью сплайна и порядком наивысшей непрерывной производной – дефектом сплайна.
Одним из наиболее распространенных интерполяционных сплайнов является кубический сплайн.
Для вывода кубического интерполяционного сплайна воспользуемся его интерпретацией как гибкой линейки, изогнутой таким образом, что она проходит через значения функции в узлах, т.е. является упругим бруском в состоянии свободного равновесия.

 ,
,