Статистическое кодирование дискретных сообщений. Энтропия непрерывного источника. Пропускная способность непрерывного канала связи.
Используя теорему К. Шеннона, сформулированную в предыдущем разделе, можно увеличить производительность источника дискретных сообщений, если априорные вероятности различных элементов сообщения неодинаковы, К.Шеннон предложил и метод такого кодирования, который получил название статистического или оптимального кодирования. В дальнейшем идея такого кодирования была развита в работах Фано и Хаффмена и в настоящее время широко используется на практике для "сжатия сообщений".
Основой статистического (оптимального) кодирования сообщений является теорема К. Шеннона для каналов связи без помех.
Кодирование по методу Шеннона-Фано-Хаффмена называется оптимальным, так как при этом повышается производительность дискретного источника, и статистическим, так как для реализации оптимального кодирования необходимо учитывать вероятности появления на выходе источника каждого элемента сообщения (учитывать статистику сообщений).
Используя определения производительности и избыточности дискретного источника, приведённые можно получить
Из этой формулы видно, что для увеличения производительности нужно уменьшать избыточность χ или среднюю длительность сообщений.
Идея статического кодирования заключается в том, что, применяя неравномерный неприводимый код, наиболее часто встречающиеся сообщения (буквы или слова) кодируются короткими кодовыми словами этого кода, а редко встречающиеся сообщения кодируются более длительными кодовыми словами.
Рассмотрим принципы оптимального кодирования на приводимом ниже примере. Пусть источник сообщений выдаёт 8 различных сообщений x1…x8 с вероятностями 0,495; 0,4; 0,026; 0,02; 0,018; 0,016; 0,015; 0,01 (сумма вероятностей равна 1).
Располагаем эти сообщения столбцом в порядке убывание вероятностей.
{xi, p(xi)} Кодовое дерево Код Ni p(x)Ni
------------- -----------------
x1 0,495 0 1 0,495
x2 0,4 10 2 0,8
x3 0,026 1100 4 0,104
x4 0,02 1110 4 0,08
x5 0,018 11010 5 0,09
x6 0,016 11011 5 0,08
x7 0,015 11110 5 0,075
x8 0,01 11111 5 0,05
------------- ---------------------
Рисунок 6 - Статистическое кодирование
Объединяем два сообщения с самыми минимальными вероятностями двумя прямыми и в месте их соединения записываем суммарную вероятность: p(x7)+p(x8)=0,015+0,01=0,025. В дальнейшем полученное число 0,025 учитываем в последующих расчётах наравне с другими оставшимися числами, кроме чисел 0,015 и 0,01. Эти уже использованные числа из дальнейшего расчёта исключаются. Далее таким же образом объединяются числа 0,018 и 0,016, получается число 0,034, затем вновь объединяются два минимальных числа (0,02 и 0,026) и т.д.
Построенное таким образом кодовое дерево используется для определения кодовых слов нового кода. Напомним, что для нахождения любого кодового слова надо исходить из корня дерева (точка с вероятностью 1) и двигаться по ветвям дерева к соответствующим сообщениям x1…x8. При движении по верхней ветви элемент двоичного кода равен нулю, а при движении по нижней - равен единице. Например, сообщению x5 будет соответствовать комбинация 11010. Справа от кодового дерева записаны кодовые слова полученного неравномерного кода. В соответствии с поставленной задачей, наиболее часто встречающееся сообщение x1 (вероятность 0,495) имеет длительность в 1 элемент, а наиболее редко встречающиеся имеют длительность в 5 элементов. В двух последних столбцах рисунка приведено число элементов Ni в кодовом слове и величина произведения p(xi)Ni=∑ p(xi)Ni= 1,774представляет собой число элементов, приходящееся на одно слово, т.е. в данном случае .
Если бы для кодирования был применён равномерный двоичный код, который чаще всего применяется на практике, число элементов в каждом кодовом слове для кодирования восьми различных сообщений равнялось бы трём (23=8), т.е. .. В рассматриваемом примере средняя длительность кодового слова благодаря применённому статистическому кодированию уменьшилась в 3/1,774=1,72 раза. Во столько же раз увеличилась и производительность источника.
Дальнейшим развитием оптимального статистического кодирования является кодирование кодовых слов. В этом методе применяется также оптимальное кодирование по методу Шеннона-Фано-Хаффмена, однако не к отдельным буквам, а к кодовым словам( сочетаниямn букв первичного сообщения). Статистическое кодирование слов позволяет ещё больше уменьшить среднюю длительность сообщений, так как алфавит источника быстро увеличивается с увеличением длины слова. Число возможных кодовых слов (алфавит источника после объединения букв) определяется выражением m=kn, где k - алфавит букв первичного сообщения. Пусть, например, у нас имеется двоичный источник с алфавитомa1 и a2 (например, “1” и “0”). При передаче этих букв по каналу связи используются сигналы длительностью τэ, а =τэ.
Рассмотрим пример, когда p(a1)=0,8 и p(a2)=0,2 (если вероятности p(a1) и p(a2) равны между собой, никакое кодирование не может уменьшить среднюю длительность сообщения). Образуем из элементов a1 и a2 слова из двух букв (n=2), беря различные сочетания из этих букв. Если у нас источник с независимым выбором элементов сообщений, то
p(a1a1)=0,8*0,8=0,64;
p(a1a2)= p(a2a1)=0,8*0,2=0,16;
p(a2a2)=0,2*0,2=0,04.
Применяя к полученным словам кодирование по методу Шеннона-Фано-Хаффмена, получаем кодовое дерево (рисунок 2.6), из которого видно, что новые кодовые слова неравномерного кода имеют длительность τэ, 2τэ и 3τэ.
Средняя длина кодового слова
τсл=0,64τэ+0,16*2τэ+0,16*3τэ+ 0,04*3τэ=1,56τэ.
Но так как каждое слово содержит информацию о двух буквах первичного сообщения, то в расчёте на 1 букву получаем τэ, Отсюда видно, что средняя длина элемента сообщения сократилась по сравнению с первоначальной в 1/0,78=1,38 раза.
a1a1
a1a2
a2a1
a2a2
Рисунок 7 – Алфавит источника после объединения букв
Если усложнить кодирование и использовать n=3, то в этом случае получим . Это уже почти предел, дальше уменьшать n уже нецелесообразно. Чтобы убедиться в этом, рассчитаем производительность источника сообщений для всех трёх случаев. Энтропия источника
бит.
Последняя величина близка к предельно возможной величине 1/ τэ.
Статистическое кодирование слов целесообразно применять также в случае использования эргодического дискретного источника (источника с корреляционными связями букв), так как объединение букв в слова приводит к разрушению корреляционных связей (величина nдолжна быть не менее порядка эргодического источника, а nτэ, соответственно, больше интервала корреляции букв первичного сообщения). Корреляционные связи между буквами трансформируются в различные вероятности появления возможных слов (n -буквенных сочетаний). При этом необходимо помнить, что вероятность n-буквенных сочетаний определяется не произведением вероятностей отдельных букв, а, в соответствии с теоремой умножения вероятностей надо учитывать также условные вероятности. Так, например, для источника с независимым выбором букв p(a1a1)=p(a1)p(a1), эргодического источника с корреляционными связями букв p(a1a1)=p(a1)p(a1/a1).

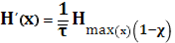
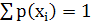

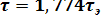 .
.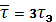 .. В рассматриваемом примере средняя длительность кодового слова благодаря применённому статистическому кодированию уменьшилась в 3/1,774=1,72 раза. Во столько же раз увеличилась и производительность источника.
.. В рассматриваемом примере средняя длительность кодового слова благодаря применённому статистическому кодированию уменьшилась в 3/1,774=1,72 раза. Во столько же раз увеличилась и производительность источника. =τэ.
=τэ.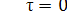 τэ, Отсюда видно, что средняя длина элемента сообщения сократилась по сравнению с первоначальной в 1/0,78=1,38 раза.
τэ, Отсюда видно, что средняя длина элемента сообщения сократилась по сравнению с первоначальной в 1/0,78=1,38 раза.
 a1a1
a1a1 a1a2
a1a2 a2a1
a2a1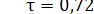 . Это уже почти предел, дальше уменьшать n уже нецелесообразно. Чтобы убедиться в этом, рассчитаем производительность источника сообщений для всех трёх случаев. Энтропия источника
. Это уже почти предел, дальше уменьшать n уже нецелесообразно. Чтобы убедиться в этом, рассчитаем производительность источника сообщений для всех трёх случаев. Энтропия источника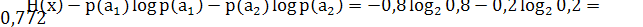 бит.
бит.