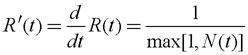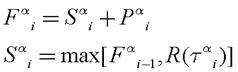Традиционно маршрутизаторами на каждом выходном порту применяется дисциплина очередей FIFO и поддерживается отдельная очередь. Когда прибывает новый пакет и направляется к выходному порту, он помещается в конец очереди. Пока очередь не опустеет, маршрутизатор передает пакеты из очереди, выбирая из нее самый старый пакет.
Недостатки FIFO.
§ Пакетам, принадлежащим потокам с более высоким приоритетом или потокам, в большей степени чувствительным к задержке, не предоставляется специального обслуживания. Если несколько пакетов из различных потоков готовы к передаче, они посылаются строго в порядке FIFO, то есть в том же порядке, в котором они поступили в очередь.
§ Если несколько меньших по размеру пакетов стоят в очереди позади больших пакетов, тогда результат применения схемы FIFO будет выражаться в большей средней задержке пакета, чем в случае, если бы более короткие пакеты передавались прежде больших пакетов. В целом получается, что потоки из пакетов большего размера получают лучшее обслуживание.
§ Более эгоистичное TCP-соединение может вытеснить более альтруистические TCP-соединения. Если возникает перегрузка и одно из ТСР-соединений по какой-то причине не снизит скорость передачи данных, тогда другим TCP-соединениям придется пойти на большие уступки, чем в случае, если бы все TCP-соединения снизили свои скорости.
Маршрутизатор обслуживает несколько очередей для каждого выходного порта. При этом можно поддерживать по одной очереди для каждого источника, как предложено в, или по одной очереди для каждого потока.
При справедливой организации очередей каждый входящий пакет помещается в соответствующую очередь. Очереди обслуживаются в циклическом порядке, то есть из каждой очереди поочередно выбирается один пакет. Пустые очереди пропускаются.
Такая схема является справедливой в том смысле, что каждому непустому потоку удается послать ровно один пакет за цикл. При такой схеме потоку нет смысла быть жадным. Единственное, что получит эгоистичный поток, это удлинение своей очереди и соответствующее увеличение задержки в доставке пакетов, при этом его поведение никак не скажется на других потоках.
Серьезный недостаток схемы справедливой организации очередей заключается в том, что короткие пакеты получают менее качественное обслуживание. Потоки с большим средним размером пакета получают большую долю пропускной способности по сравнению с потоками с меньшим средним размером пакетов. Причина этого в том, что каждая очередь передает по одному пакету за цикл.
Этот недостаток можно преодолеть с помощью схемы справедливой организации очередей с побитовым циклом (Bit-Round Fair Queuing, BRFQ), в которой при планировании пакетов учитываются не только идентификаторы пакетов, но и длина пакетов.
Чтобы понять, как работает метод справедливой организации очередей с побитовым циклом, рассмотрим сначала идеальную политику, которая на практике не применяется. Сформируем несколько очередей, как в схеме справедливой организации очередей, но будем передавать в каждом цикле не целый пакет, а всего один бит. Таким образом, более длинные пакеты не получат преимущества, и каждому источнику будет предоставлена равная пропускная способность.
В частности, если имеются N очередей и в каждой из этих очередей всегда есть пакет для передачи, тогда каждая очередь получает ровно 1/N доступной пропускной способности.
Такой идеальный побитовый подход известен также как разделение процессора (Processor Sharing, PS).
Чтобы дальнейшее обсуждение было понятнее, введем следующие обозначения:
§ R(t) — количество циклов обслуживания с разделением процессора, которые произошли к моменту времени t, нормализованное относительно выходной скорости передачи данных;
§ N(t) — количество непустых очередей в момент времени t;
§ Рαi — время передачи для пакета i в очереди α, приведенное к выходной скорости передачи данных;
§ ταi — время прибытия пакета i в очередь α;
§ Sαi — значение R(t) в момент начала передачи пакета i в очереди α;
§ Fαi — значение R{t) в момент завершения передачи пакета i в очереди α.
Значение R(t) можно рассматривать как виртуальное время, соответствующее скорости обслуживания пакета, находящегося в начале очереди. Эквивалентное определение выглядит следующим образом:
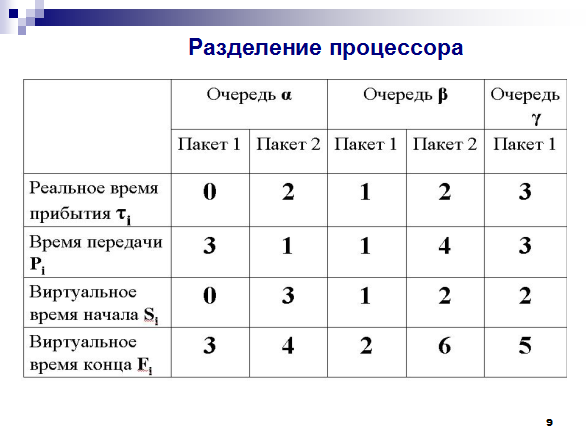
Для примера рассмотрим три очереди, трафик которых описывается таблицей:
Таблица. Трафик трех очередей, обслуживаемый по схеме PS
Очередь α
Очередь β
Очередь γ
Пакет 1
Пакет 2
Пакет 1
Пакет 2
Пакет 1
Реальное время прибытия τi
Время передачи Рi
Виртуальное время начала Si
Виртуальное время конца Fi
Значения τi, и Рi, задаются; значения Si, и Fi определяются политикой разделения процессора. На рисунке черные линии иллюстрируют обслуживание трех очередей. Первый прибывший в очередь α пакет получает одну единицу обслуживания в реальном интервале времени [0, 1] с виртуальным временем R(l) = 1 к концу этого интервала.
В реальном интервале времени [1,3] биты передаются из двух очередей, в результате чего каждая очередь получает скорость обслуживания R'= 1/2 и виртуальное время растягивается в 2 раза. Аналогично, в течение интервала времени [3, 9] все три очереди сохраняют активность, поэтому каждая получает обслуживание со скоростью R'= 1/3 и виртуальное время растягивается в 2 раза.
Следующее рекуррентное соотношение показывает, как система разделения процессора развивается в виртуальном времени: это виртуальные времена завершения передачи пакета и начала передачи.
По этим соотношениям мы можем сосчитать виртуальное время окончания передачи пакета в момент прибытия пакета. Однако мы не можем вычислить реальное время окончания передачи пакета в момент его прибытия, потому оно зависит от прибытия других пакетов.
Другой подход к борьбе с перегрузкой в объединенных сетях представляет собой упреждающее отбрасывание пакетов, т.е. маршрутизатор отбрасывает один или несколько входящих пакетов прежде, чем переполнится выходной буфер. Упреждающее отбрасывание пакетов может быть реализовано в одной или нескольких очередях.
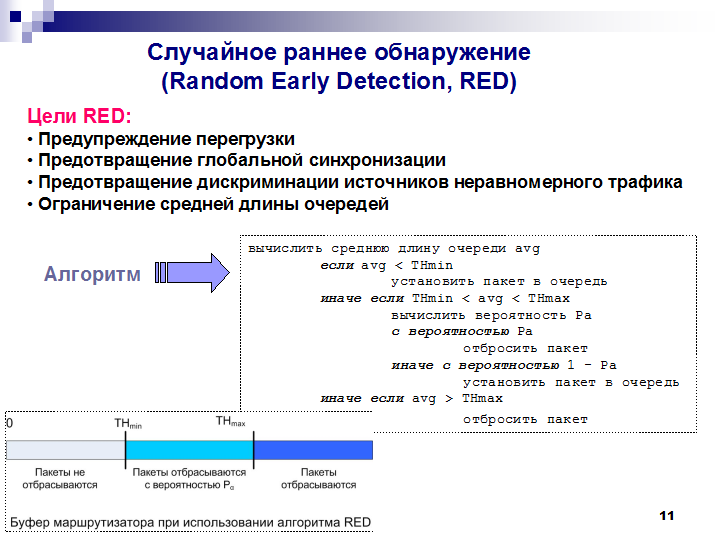
Наиболее важный вариант схемы упреждающего отбрасывания пакетов называется случайное раннее обнаружение (Random Early Detection, RED). Сначала обсудим причины для применения схемы RED и цели ее разработки, после чего перейдем к деталям.