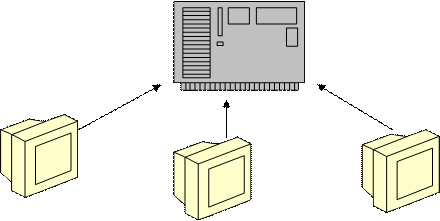
Во времена использования больших и мини-ЭВМ (более 25 лет назад) выполнялась централизованная обработка данных. Как правило, при работе с такими компьютерами использовались терминалы, управляемые одной, достаточно мощной по тем временам, ЭВМ (рис.1). Данные хранились на жестком диске машины, а пользователи могли обращаться к этим данным со своих терминалов. Такая обработка данных имела свои преимущества, в определенной степени, утраченные позже, в эпоху персональных компьютеров и настольных СУБД. К ним, в частности, относились:
- возможность коллективного использования ресурсов и оборудования, например, центрального процессора, оперативной памяти, внешних устройств (принтеров, плоттеров, накопителей на магнитной ленте и иных устройств хранения данных);
- централизованное хранение данных.
Серьезным недостатком подобных систем было то, что все пользователи использовали одно и тоже программное обеспечение, установленное на ЭВМ, т. к. все программное обеспечение, включая текстовые редакторы, компиляторы, СУБД, хранилось также централизованно и использовалось коллективно.
Рисунок 1. Упрощенная структура мини-ЭВМ
Этот недостаток был одной из причин бурного роста индустрии персональных компьютеров - наряду с простотой в эксплуатации и невысокой стоимостью по сравнению с большими и мини-ЭВМ пользователей привлекала возможности выбора наиболее подходящего для них программного обеспечения. Именно в тот период и начался бурный рост популярности настольных СУБД, таких как dBase (РЕБУС) и, чуть позже, FoxBASE, Paradox.
Настольные СУБД не содержат специальных средств, управляющих данными, - взаимодействие с ними осуществляется с помощью операционной системы. Такие СУБД имеют в своем составе средства разработки, ориентированные на работу с данными специального формата, характерного для этой СУБД, и позволяющие создать более или менее комфортный пользовательский интерфейс. Обработка данных полностью осуществляется в пользовательском (клиентском) приложении.
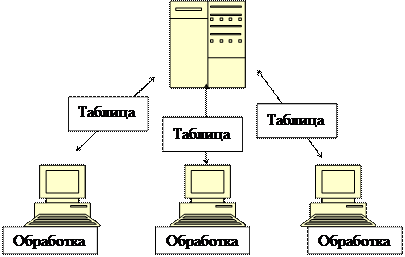
Следующим шагом в развитии настольных СУБД было появление их сетевых многопользовательских версий, позволяющих обрабатывать данные, находящиеся в общедоступном хранилище (например, на сетевом диске) нескольким пользователям одновременно (рис.2). От чисто настольных СУБД их многопользовательские версии отличаются наличием специальных механизмов, позволяющих обращаться к одному и тому же файлу нескольким пользователям одновременно.
Недостатки подобных СУБД становятся заметны, как правило, при росте хранимых объемов данных и увеличении числа пользователей. Обычно они проявляются в снижении производительности и в возникновении сбоев при обработке данных после некоторого времени использования клиентских приложений. Причина подобных проблем кроется в основном принципе работы таких СУБД и основанных на них информационных систем. Этот принцип заключается в обработке данных внутри пользовательского приложения. Например, если с помощью такой системы требуется выполнить запрос согласно какому-либо критерию (например, выбрать заказы, обработанные за последние два часа, из таблицы заказов), то, в лучшем случае (если эта таблица проиндексирована по времени поступления заказа), приложение должно прочесть с сетевого диска весь индекс, найти в нем сведения о местоположении записей в файлах, содержащих таблицу, и затем прочесть эти части файлов. В общем же случае, когда таблица не проиндексирована по данному полю, ее необходимо полностью загрузить с сетевого диска и проанализировать.
Рисунок 2. Сетевая многопользовательская СУБД
Еще одна проблема настольных СУБД заключается в возможности нарушения ссылочной целостности данных, так как единственным механизмом, контролирующим ее, является пользовательское приложение. Поэтому все пользовательские приложения должны содержать соответствующий код доступа, а доступ к файлам базы данных из любых других приложений должен быть запрещен.
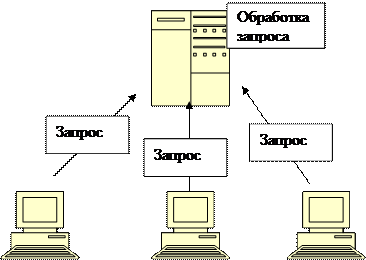
Следующим этапом развития СУБД для персональных компьютеров были так называемые серверные СУБД (рис.3).
Рисунок 3. Серверная СУБД
Архитектура «клиент/сервер», для которой предназначены серверные СУБД, является в определенной степени возвратом к прежней модели ЭВМ, основанной на централизации хранения и обработки данных на одном выделенном компьютере, где функционирует специальное приложение или сервис, называемый сервером баз данных. Сервер баз данных отвечает за работу с файлами базы данных, поддержку ссылочной целостности, резервное копирование, обеспечение авторизованного доступа к данным, протоколирование операций и, конечно, за выполнение пользовательских запросов на выбор и модификацию данных. Клиентские приложения, являющиеся источниками этих запросов, функционируют на персональных компьютерах в сети.
При использовании серверных СУБД выполнение запросов производится самим сервером, поэтому клиентские приложения получают от сервера только результаты самого запроса и не требуют передачи всего индекса или всей таблицы, что существенно снижает сетевой трафик при обработке запросов.