1. Физическая структура дисковой памяти
Дисковая память имеет иное физическое строение и иные показатели доступа, чем оперативная память. Схематично ее физическое строение можно представить так, как показано на рис.7.1.
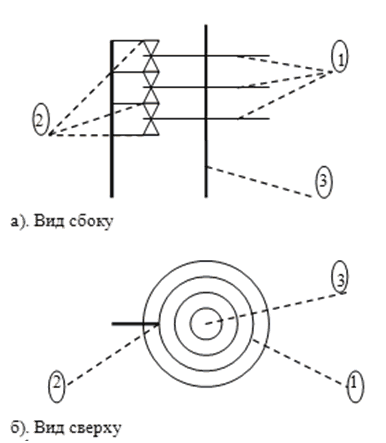
1 – диски
2 – головки чтения/записи
3 – ось вращения
Рис.7.1. Физическое строение дисковой памяти
Накопитель на жестких магнитных дисках представляет собой несколько дисков, покрытых с двух сторон ферромагнитным материалом (который, собственно, и является носителем информации). Диски вращаются на одной оси. Механизм чтения-записи представляет собой “гребенку”, “зубцы” которой вставляются между дисками. На зубцах находятся головки чтения-записи, каждой поверхности соответствует своя головка. Гребенка может перемещаться взад-вперед в радиальном направлении, занимая конечное число фиксированных позиций. Вся гребенка является жесткой конструкцией, т.е. все головки перемещаются вместе. Окружность, которая “рисуется” на поверхности диска при прохождении его под находящейся в одном из фиксированных положений головкой, называется дорожкой.
В общем случае время доступа к требуемой информации на диске складывается из четырех составляющих:
Tдост = Tгол + Tдор + Tсект + Tчт
Где:
Tгол – время выбора головки. Выбор головки сводится к переключению электронных ключей, и Tгол пренебрежимо мало по сравнению с остальными составляющими.
Tдор – время выбора дорожки. Выбор дорожки представляет собой поступательное перемещение гребенки в требуемую фиксированную позицию. Как механическое перемещение с разгоном и торможением, этот выбор требует наиболее существенных затрат времени. Это слагаемое является определяющим в общей сумме.
Tсект – время выбора сектора. Выбор сектора состоит в ожидании того, когда сектор с требуемыми данными за счет вращения диска окажется под головкой чтения-записи. Поскольку здесь механическое перемещение связано с равномерным вращением с высокой скоростью, Tсект << Tдор, но не настолько, чтобы им можно было пренебречь.
Tчт – время чтения – интервал времени, за который участок дорожки с читаемыми данными проходит под головкой чтения-записи. Это время сопоставимо с Tсект, но представляет собой совершенно неизбежные затраты времени.
При чтении записей в произвольном порядке для чтения каждой записи необходимо выполнить затраты времени доступа в полном объеме. При чтении же записей, расположенных на диске последовательно затраты Tгол + Tдор + Tсект необходимо выполнить только для доступа к первой записи. После прочтения первой записи следующая уже окажется под головкой. Когда все записи на дорожке будут прочитаны потребуется переключить головку и читать дорожку на следующей поверхности. Только после прочтения всех дорожек, доступных при данном фиксированном положении гребенки, приходится позиционировать гребенку в следующее фиксированное положение, т.е., затрачивать Tгол + Tдор + Tсект.
2. Последовательные файлы
Последовательный неупорядоченный файл является простейшей структурой данных на внешней памяти. Очевидно, что при последовательном доступе к такому файлу достигаются минимальные потери производительности. Однако, при необходимости выбирать записи в произвольном порядке рассмотренные выше затраты времени относятся к каждой выбираемой записи. Поиск в неупорядоченном последовательном файле возможен только линейный, что совершенно неприемлемо для большинства приложений. Если последовательный файл будет упорядочен, то в нем можно применять дихотомический поиск. Однако, сортировка последовательного файла представляет собой достаточно сложную и затратную задачу
2.1. Внешняя сортировка
Для сортировки данных в последовательном файле неприменимы методы, рассмотренные в составе темы 3, так как эти методы предполагают доступ к элементам сортируемого множества в практически произвольном порядке. Внешняя сортировка (сортировка данных на внешней памяти) выполняется в два этапа:
- частичная сортировка
- слияние.
На первом этапе неупорядоченная входная последовательность данных разбивается на несколько неупорядоченных последовательностей меньшего размера и выполняется сортировка в пределах каждой такой последовательности. Размер каждой меньшей последовательности выбирается таким, чтобы эта последовательность помещалась в оперативной памяти, следовательно, для ее сортировки в принципе пригоден любой алгоритм из рассмотренных в теме 3. Предпочтительным, однако, является алгоритм сортировки частично упорядоченным деревом, поскольку он позволяет получить отсортированную последовательность, длина которой больше размера доступной оперативной памяти.
Второй этап аналогичен алгоритму сортировки попарным слиянием: из двух упорядоченных последовательностей получается одна упорядоченная последовательность двойного размера. Второй этап повторяется столько раз, сколько потребуется для получения полного упорядоченного файла.
3. Файлы, организованные разделами
Такой файл представляет собой совокупность последовательных подфайлов или разделов, расположенных в произвольном порядке в той области памяти, которая выделена для файла. Каждый раздел имеет собственное имя и обрабатывается как последовательный файл независимо от других разделов. Но вся совокупность разделов такого файла (часто именуемого библиотекой) имеет общее имя и представляет собой один файл с точки зрения операционной системы.
Структурно библиотечный файл состоит из трех частей: справочной области, оглавления и области данных. В справочной области хранятся параметры, общие для всего файла: размер оглавления и адрес начала свободного пространства в области данных. Оглавление представляет собой таблицу, каждая строка которой соответствует одному разделу. Для каждого раздела в строке этой таблицы записаны: имя раздела, адрес раздела в области данных, длина раздела. Область данных содержит собственно данные разделов, причем каждый раздел занимает в области данных непрерывный участок. При создании библиотечного файла происходит его начальное форматирование: оглавление заполняется пустыми строками, адрес начала свободного пространства устанавливается на начало области данных. При добавлении нового раздела в оглавление заносится соответствующая ему строка, а раздел дописывается в свободное пространство и адрес свободного пространства соответственно сдвигается. При удалении раздела соответствующая ему строка в оглавлении просто помечается как пустая. Данные раздела остаются на диске, но теперь они недоступны, и занимаемое ими дисковое пространство не используется. При изменении содержимого раздела возможны два варианта. Если новая длина раздела не превышает старую, то новая редакция раздела записывается на прежнее место в области данных (если длина раздела уменьшилась, то часть дискового пространства станет неиспользуемой). Если же длина раздела увеличивается, то раздел удаляется на старом месте и создается на новом – в свободном дисковом пространстве. Прежнее пространство раздела остается недоступным для использования.
У библиотечных файлов имеется два существенных недостатка. Во-первых, это накопление “дыр” – неиспользуемых участков дискового пространства внутри области данных. Во-вторых, ограничение на максимальное количество разделов в библиотеке, поскольку оглавление создается при создании файла и уже не может быть увеличено впоследствии. В связи с этими недостатками библиотечная структура в настоящее время применяется только для файлов, не обладающих изменчивостью, например, для LIB- или HLP-файлов.
4. Файлы прямого доступа
Эти файлы представляют собой в сущности реализацию на внешней памяти хешированных таблиц прямого доступа (см.3.6.3.3). Файл прямого доступа, как правило состоит из двух частей: индекса и пространства данных. Индекс и является, собственно таблицей прямого доступа, каждая запись которой содержит только ключ, адрес соответствующей записи в области данных и адрес следующей записи в возможной цепочке переполнений (для разрешения коллизий используются раздельные цепочки переполнений). Область данных – неупорядоченный последовательный файл. Обычно индекс или его часть считывается в оперативную память и поиск по ключу ведется, по возможности, в оперативной памяти. Если запись файла прямого доступа содержит несколько полей, которые могут использоваться в качестве ключа, для каждого ключа строится свой индекс при одной общей области данных.
Поскольку в процессе “жизни” файла прямого доступа имеется тенденция к накапливанию в нем коллизий, со временем эффективность доступа к файлу ухудшается. Поэтому файлы прямого доступа нуждаются в периодической реорганизации, в ходе которой расширяется пространство записей и модифицируются параметры функции хеширования, что приводит к “рассасыванию” коллизий.
Существенным недостатком файла прямого доступа является чрезвычайная затратность операций, требующих обработки всех хранящихся в файле записей в определенном порядке. Поэтому область применения таких файлов ограничивается теми приложениями, которые сводятся к поиску записей и почти никогда не требуют последовательной обработки.
5. B+ деревья
Файлы со структурой B+-деревьев являются основной структурой, используемой в современных СУБД. Эта структура позволяет организовать как быстрый поиск записи по ключу, так и последовательную упорядоченную обработку записей.
Дерево называется B+-деревом порядка m, если:
1). В каждом узле, кроме корневого, число ключей M находится в пределах (m/2)<=M<=m-1. В корне дерева минимальное число ключей м.б. равно 1.
2). Каждый не являющийся “листом” узел с M ключами содержит M+1 указателей на узлы-потомки.
3). Все “листья” дерева находятся на одном и том же уровне
4). В каждом узле ключи упорядочены по возрастанию.
Пример B+-дерева порядка 5 показан на рис.7.2.
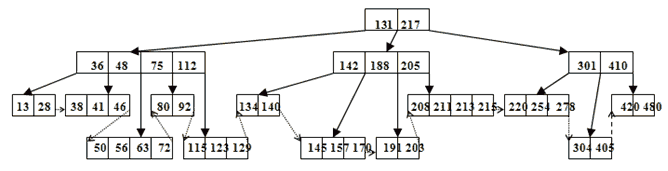
Рис.7.2. B+ - дерево порядка 5
Указатель A[i] в нелистовом узле является адресом узла-потомка, в котором расположены ключи, меньшие, чем ключ K[i], точнее – ключи в интервале К[i-1]<=k<K[i]. Указатель A[M], для которого нет соответствующего ключа в массиве ключей, является адресом узла-потомка, в котором расположены ключи, болшие, чем ключ K[M]. Алгоритм поиска по ключу в . B+-дереве является очевидным.
Чрезвычайно существенным является то обстоятельство, что заполненность узлов дерева может изменяться в пределах, заданных условием 1. Это дает возможность реализовать операции вставки и удаления для . B+-дерева весьма эффективно. При вставке находится листовой узел, в который должна вставляться новая запись. Если в узле еще есть свободное место, то запись просто вставляется в лист и на этом операция заканчивается. Если свободного места в листе уже нет, то лист расщепляется на 2 листа, и записи из заполненного листа перераспределяются между двумя листами, каждый из которых оказывается заполненным наполовину. Расщепление приводит к тому, что в узел-предок необходимо вставить новую пару значений ключ-указатель. Если в узле предке еще есть свободное место, то новая пара вставляется на свободное место, и на этом операция заканчивается. Если свободного места в узле уже нет, то узел расщепляется на 2 узла и т.д.
При удалении если удаление записи из листа не приводит к тому, что лист окажется заполненным менее, чем наполовину, запись удаляется в листе и на этом операция заканчивается. Если же лист оказывается заполненным менее, чем наполовину, то выполняется перераспределение записей между ним и соседним листом (и соответствующая коррекция ключей-указателей в узле-предке). Если в соседнем узле m/2 записей, то два соседних узла сливаются в один (его заполненность будет m-1 записей). Слияние узлов приводит к удалению пары значений ключ-указатель в узле-предке. Если удаление пары из узла не приводит к тому, что узел окажется заполненным менее, чем наполовину, пара удаляется в узле, и на этом операция заканчивается. Если же узел оказывается заполненным менее, чем наполовину … и т.д.
Таким образом, за счет того, что имеется значительный “допуск” на заполненность узлов/листьев дерева, изменение в подавляющем большинстве случаев удается локализовать в том узле/листе, к которому они непосредственно относятся. Поскольку порядок дерева может быть выбран достаточно большим, глубина дерева оказывается незначительной и путь к любому листу дерева включает в себя прохождение небольшого числа узлов (а каждое прохождение узла – чтение записи с диска). Последовательный же доступ к записям обеспечивается тем, что листья дерева связываются через специальные указатели в линейный список. На рис.7.1. эти связи показаны пунктирными стрелками. Линейный список получается упорядоченным по возрастанию ключей.
Как и для случая файлов прямого доступа, хранение данных в B+-дереве предполагает наличие индекса, который собственно и является B+-деревом и области данных – неупорядоченного последовательного файла. Для одной и той же области данных могут создаваться несколько индексов для различных ключей.
