2. РАЗЛИЧНЫЕ ТИПЫ ОБУЧЕНИЯ В СИСТЕМАХ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Под обучением в системах искусственного интеллекта как в психологии и обыденной жизни понимают способность системы (или программы) приобретать ранее неизвестные навыки и умение. Идеи возможности обучения и самообучения ЭВМ возникли с первых дней их существования. Казалось, что благодаря возможности быстрого и надежного запоминания больших объемов различных сведений, самостоятельного обучения и обучения с помощью экспертов, вычислительные машины смогут быстро превзойти человека в любой области. Однако десятилетия труда кибернетиков, психологов и программистов с момента появления первых ЭВМ показали, что за внешней простотой идеи обучения скрываются чрезвычайно сложные проблемы, и в настоящее время вычислительным машинам еще очень далеко в этой области до человека.
Многолетний труд тысяч специалистов в области обучения искусственных систем все же не пропал даром и налицо определенный прогресс в этом направлении. Прежде всего, более глубоко изучены процессы обучения человека и установлено, что существуют различные уровни обучения, связанные между собой иерархической структурой (рис. 1).
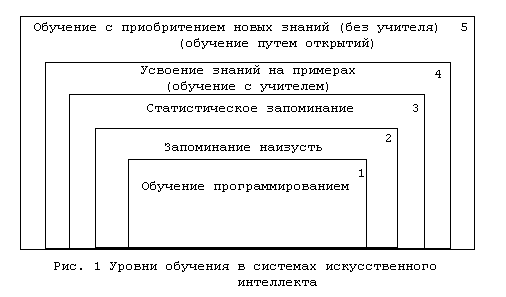
Уровень 1 представляет собой простое занесение в память компьютера того, что он должен "знать". К первому уровню относятся программы для промышленных роботов первого поколения и подавляющее большинство обычных компьютерных программ современных ЭВМ. Программа или робот при выполнении конкретных условий, заданных программистом, осуществляет то, что однозначно определено и может меняться только путем перепрограммирования. Таковы, например, действия промышленных роботов первого поколения, движения которых однозначно сформированы движениями квалифицированного рабочего, выполнявшего ту или иную технологическую операцию и одновременно программировавшего будущие действия робота, запускаемого определенным кодом и способного только слепо повторять движения человека, независимо от состояний внешней среды и объекта воздействия.
Уровень 2, или запоминание наизусть предполагает запоминание ситуаций и им соответствующих действий. Примерами интеллектуальных программ с запоминанием наизусть могут служить программы, написанные инженером фирмы IBM А.Сэмюэлем для игры в шашки на доске 8х8 в период с 1956 по 1967 гг. Как известно, шашки ходят по диагоналям вперед на соседнее свободное поле, а бьют - вперед и назад, перескакивая через шашку противника и становясь на соседнее за этой шашкой свободное поле. Дамки в отличие от шашек могут ходить вперед и назад на любое из свободных полей по диагонали и бить шашку противника независимо от числа свободных до нее полей, если имеется хотя бы одно свободное поле за этой шашкой. Шашки могут превращаться в дамки, дойдя до последней горизонтали.
Первая программа, написанная А.Сэмюэлем в 1956 году, содержала около 180 тыс. позиций, заимствованных из лучших книг по игре в шашки. Поскольку даже для машин 90-х годов это достаточно много, то А.Сэмюэль с целью ускорения доступа упорядочил позиции в начале по числу шашек и дамок у обоих партнеров, а затем по частоте их появления в играх программы. При приближении памяти к переполнению использовалась процедура исключения позиций, мало встречавшихся (или совсем не возникавших) в партиях программы за какой-то последний период времени.
Уровень 3 - статистическое запоминание. Оно является усовершенствованным запоминанием наизусть, так как в этом случае хранится информация, полученная на основе анализа не отдельных, а большого числа случаев.
Вернемся к программам игры в шашки А.Сэмюэля. Хотя 180 тыс. позиций это и много, однако, это на порядки меньше, чем может быть при игре. Поэтому, если позиции в памяти не было, то ход машина рассчитывала с помощью полиномиальной функции оценивания
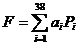 ( 1 )
( 1 )
где аi - параметры; Рi - характеристики, среди которых можно отметить контроль центра, материальный выигрыш, число угроз, число продвинутых шашек и т.д.
В первых программах расчет функции оценивания (1) выполнялся для глубины в три полухода (варианты, в которых на последнем полу ходе была подстановка под удар своей шашки или взятие шашки противника, продолжались до более спокойных позиций и достигали порой до двадцати полуходов).
Функция F могла использоваться и в тех позициях, где лучшие ходы были уже известны. В идеальном случае функция (1) должна была давать те же лучшие ходы, что записаны в памяти машины, однако это случалось далеко не всегда, и возникала необходимость корректировать параметры аi. Коррекция выполнялась следующим образом. Программа рассчитывала по F число L лучших и число X худших ходов по сравнению с хранящимися в памяти, а затем вычисляла коэффициент
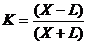
Если L = 0 и, следовательно, K = 1, то наблюдается полное соответствие между оценками позиций по выражению (1) и теми оценками, которые заложены в память машины из лучших книг. Естественно, что функция F в этом случае идеальна, и менять ее не нужно. Если X = 0, то К = -1, и наблюдается полное расхождение между оценками из книг и с помощью функции (1). Понятно, что нельзя одним коэффициентом K оценивать все 38 параметров аi, поэтому в программах А. Сэмюэля каждый параметр оценивался своим коэффициентом
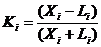
где Li и Хi - соответственно число ходов, превосходящих лучший ход из книг и уступающих ему по величине одночлена аiРi.
Программа, обучаясь по лучшим партиям шашечных мастеров, могла найти оптимальные параметры оценочной функции. В программах А.Сэмуэля для определения хороших наборов коэффициентов требовалось порядка двадцати партий, при этом для полиномиального оценивания достигался 32%-ный выбор наилучшего хода. Такой относительно низкий процент лучших ходов связан с простым видом оценивающего:
выражения (1).
Уровень 4 - усвоение знаний на примерах с помощью учителя. Приведенный пример получения коэффициентов оценочной функции (1) при игре в шашки можно рассматривать и как обучение с учителем, в результате которого происходит статистическое запоминание. В обучении с учителем есть одна опасность: если учитель плох, то и обучающаяся программа или система будет соответствующего качества. Это, кстати, обнаружил и А.Сэмюэль - если программа обучалась в игре со слабыми партнерами, то качество ее игры резко падало.
Уровень 5 - обучение без учителя. Этот вид обучения также можно иллюстрировать примером из шашек. Программа может играть сама против себя, пользуясь разными вариантами функции оценивания F и извлекая знания самостоятельно.
Пусть а - лучшая версия программы, оценочную функцию которой обозначим Fa. Пусть эта программа играет против программы в с оценочной функцией Fb. Если выигрывает программа А, то слегка меняются параметры функции Fb и играется следующая партия. Если выигрывает программа B, то программа А получает штрафное очко. После определенной суммы штрафных очков производится взаимный обмен функциями Fa и Fb и существенно меняются параметры Fb неудачно игравшей программы.
Иногда третий, четвертый и пятый уровни обучения объединяют под общим названием обучения с обратной связью.
Рассмотрим пример обучающейся системы с учителем. Для простоты возьмем систему, которая обучается с помощью учителя различать только два объекта, выделяя при этом их общие свойства. Общая структурная схема такой системы представлена на рис. 2, где 1 -внешняя среда, содержащая объекты распознавания; 2 - учитель (человек или другая вычислительная система); 3 - блок сравнения; 4 -коммутатор; 5 - блок формирования признаков объектов в режиме обучения; 6 - блок определения объекта внешней среды в режимах распознавания и распознавания с самообучением; 7 - блок самообучения; 8 - запоминающее устройство (ЗУ) для хранения общих атрибутов объектов; 9 и 10 - ЗУ соответственно для хранения атрибутов первого и второго объектов; 11 - блок ЗУ; 12 - вход сигнала задания режима работы: записи априорной информации, обучения, распознавания или распознавания с самообучением; 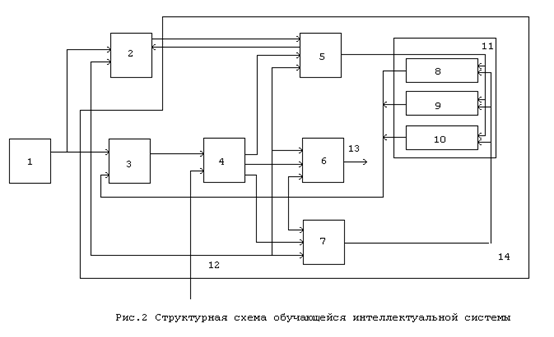
13 - информационный выход обучающейся системы; 14 - обучающаяся интеллектуальная система.
Как следует из общей структурной схемы интеллектуальной системы, в ее основу в режиме обучения заложены механизмы запоминания фактов, классифицируемых учителем, их обработка (статистическая, если она предполагается, и (или) выделение общих атрибутов двух объектов) и, быть может, механизмы логического вывода, вскрывающие противоречия между вновь предъявленными и хранящимися в памяти фактами.
В режимах распознавания и распознавания с самообучением должны работать механизмы логического вывода, на основе которых принимается одно из следующих решений:
- предъявлен первый объект;
- предъявлен первый объект, но имеются неизвестные атрибуты;
- предъявлен второй объект;
- предъявлен второй объект, но имеются неизвестные атрибуты;
- распознавание невозможно, т.к. предъявлены только общие атрибуты двух объектов; необходима дополнительная информация;
- распознавание невозможно, т.к. предъявлены только атрибуты, отсутствующие в памяти интеллектуальной системы; необходимо дополнительное обучение;
- распознавание невозможно, т. к. предъявлены атрибуты, двух разных объектов.
В режиме распознавания с самообучением, когда принимается решение - предъявлен k-й (k = 1, 2) объект, но имеются неизвестные атрибуты, должен быть механизм записи неизвестных атрибутов в ЗУ k-го объекта.
Из вышеприведенного следует, что система обучается только в том случае, если ей предъявляется новая информация, которая отсутствует в памяти или противоречит уже имеющейся.
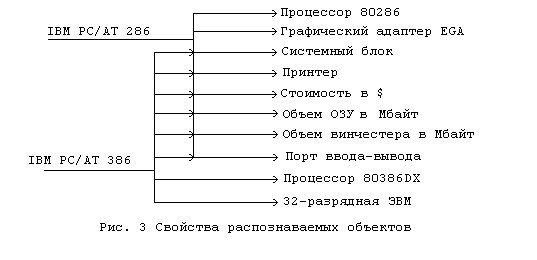
Рассмотрим обучающуюся программу, которая должна распознавать два объекта: ПЭВМ IВМ РС/АТ 286 и ПЭВМ IВМ РС/АТ 386. Некоторые общие свойства и свойства, присущие только каждому из этих двух объектов, приведены на рис. 3. Часть общих свойств (стоимость, объем винчестера и оперативного ЗУ), хотя и присущи обоим объектам, но существенно отличаются своими числовыми характеристиками, по величине которых легко распознать предъявляемый объект. В режиме обучения числовые значения этих свойств могут изменяться (например, могут предъявляться ПЭВМ с разными объемами ОЗУ и винчестера, разной стоимостью), что вызывает необходимость статистической обработки входной информации. Рассмотрим несколько простейших способов такой обработки.
Предположим, что статистическая обработка первого вида предполагает вычисление среднего арифметического значения числовой характеристики атрибута при его многократном предъявлении в режиме обучения. Как известно, среднее арифметическое S некоторых n величин а1, а2, ..., аn определяется выражением
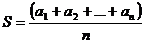 (2)
(2)
Поэтому, если вычисляется среднее арифметическое Sai i-го атрибута, аi после его предъявления в (n + 1)-й раз, то из соотношения (2) несложно получить
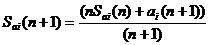 (3)
(3)
где Sai (k), k = n, n + 1, - среднее арифметическое i-го атрибута
после его k-го предъявления; аi(n + 1) - численное значение i-го атрибута в момент его (n + 1)-го предъявления.
Статистическая обработка второго вида предполагает вычисление
Среднего Sqai c весом q = (q1,q2, .. ., qn), qi > 0, Sqi = 1 ПО множеству численных значений аi(1), аi(2), ...., аi(n) атрибута а при его многократном появлении в режиме обучения
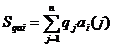 (4)
(4)
Полагая, что последние предъявления наиболее информативны, например, в силу того, что атрибут может меняться в процессе обучения, зададим, что при
(n + 1)-м предъявлении атрибута вес q определяется выражением
(n+1)-м предъявлении атрибута вес qn+1 определяется выражением
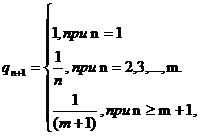 (5)
(5)
а веса q1, q2, ..., qn равны между собой и их сумма определяется с помощью соотношения (5) следующим выражением
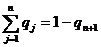 (6)
(6)
В этом случае среднее с весом i-го атрибута Sqai при его (n + 1)-м предъявлении может быть определено выражением
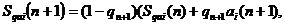 (7)
(7)
где Sqai(k), k=n, n+l- среднее с весом i-го атрибута после его k-го предъявления; qn+1 - вес i-го атрибута при его (n + 1)-м предъявлении.
Статистическая обработка третьего вида предусматривает в режиме обучения вычисление среднего геометрического Sqai множества численных значений i-го атрибута при его n-кратном появлении:
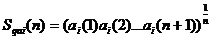 (8)
(8)
Если известно среднее геометрическое при n-кратном появлении атрибута, то при (n + 1)-м его появлении, используя выражение (8), можно вычислить и среднее геометрическое Sqai (n + 1):
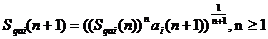 (9)
(9)
При статистической обработке четвертого вида определяется интервал [aimin(m), aimax(m)], в котором должны находиться числовые характеристики i-го атрибута после его m предъявлении. При первом появлении i-ro атрибута аi(1) задают аimin(1) = аimax(1) = аi (1).
При следующем появлении атрибута, когда выполняется неравенство ai(k) ? аi(1), k? 2, определяют граничные точки интервала соотношениями
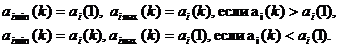 (10)
(10)
При последующих появлениях i-ro атрибута граничные точки интервала задаются соотношениями:
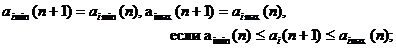
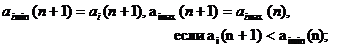
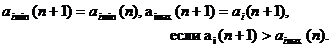 (11)
(11)
Будем рассматривать обучение системы (программы) на примере двух конкретных объектов, но закладывать в ее основу общие принципы распознавания любых двух объектов, а также предполагать возможность распространения этих принципов на распознавание трех и большего числа объектов.
Для обеспечения работы программы с произвольной парой объектов необходимо, чтобы она в режиме обучения прежде всего запрашивала имена распознаваемых объектов:
Имя 1-го oбъeктa?: ibm pc 286
Имя 2-го объекта?: ibm pc 386
Затем должен быть запрос об общем характере обработки атрибутов объектов. Предположим, что в программе возможны три способа обработки входной информации:
- запоминание атрибутов объектов;
- запоминание атрибутов объектов с выделением списка общих атрибутов;
- запоминание атрибутов объектов с выделением списка общих атрибутов и статистической обработкой числовой информации атрибутов.
В этом случае на запрос программа возможны три разных ответа:
- Характер обработки атрибутов? Запоминание или…
- Характер обработки атрибутов? Запоминание и выделение общих атрибутов.
- Характер обработки атрибутов? Запоминание и выделение общих атрибутов, статистическая обработка.
При наличии в программе режима записи априорной информации делается запрос об использовании этого режима:
Запись априорной информации? Да/Нет.
Если ответ "Да", то программа приступает к вводу атрибутов первого объекта. В связи с тем, что числовые значения атрибутов могут подвергаться различным видам статистической обработки, то, кроме имен атрибутов и их числовых характеристик, необходимо вводить еще и числовое значение переменной, обозначенной через i. указывающей вид необходимой обработки поступающих данных (соответственно i=1, 2, 3 или 4) или отсутствие такой обработки (i =0):
Введите атрибуты первого объекта и Enter в конце
Введите атрибут 1? i = О, адаптер ega
Введите атрибут 2? i = 1, стоимость, 400 $
Введите атрибут 3? i = 4, объем винчестера, 40 Мб
Введите атрибут 4? i = 0, процессор 80286
Введите атрибут 5? Enter
Затем следует ввод атрибутов второго объекта и атрибутов общего списка:
Введите атрибуты второго объекта и Enter в конце
Введите атрибут 1? i =0, процессор 80386DX
Введите атрибут 2? i = 1, стоимость, 950 $
Введите атрибут З? i = 4, объем винчестера, 1000 Мб
Введите атрибут 4? Enter
Введите атрибуты общего списка и Enter в конце
Введите атрибут 1? i = 0, принтер
Введите атрибут 2? i = 0, системный блок
Введите атрибут З? Enter
После этого на экран выводятся списки атрибутов обоих объектов:
Список 1 (IBM PC 286) Список 2 (IBM PC 386) Список 3 (общий)
адаптер ega процессор 80386DX принтер
стоимость 400 $ стоимость 950 $ системный блок
объем винчестера 40 Мб объем винчестера 1000 Мб
Затем программа задает вопрос о дальнейшем режиме работы
Режим работы?
1 - запись априорной информации
2 - режим обучения с учителем
3 - режим распознавания
4 - режим распознавания с самообучением
5 - конец работы с программой
Пусть выбран режим работы - обучение с учителем:
2 Enter
После этого ответа программа запросит ввод атрибутов любого объекта:
Введите атрибуты любого объекта и Enter в конце
Введите атрибут 1? i = 1, стоимость, 500 $
Введите атрибут 2? i = 0, принтер
Введите атрибут З? i = 0, порт ввода-вывода
Введите атрибут 4? i = 4, объем винчестера, 120 Мб
Введите атрибут 5? Enter
Получив атрибуты неизвестного объекта, программа вычисляет оценочные функции F1 и F2, полиномиального вида для каждого из объектов
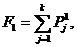 (12)
(12)
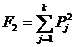 (13)
(13)
где k - число атрибутов, введенных программой на предыдущем этапе работы;
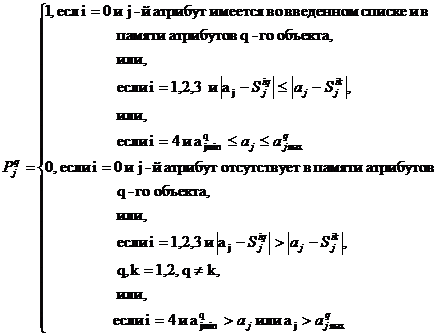 (14)
(14)
где а- численное значение j-го атрибута во введенном списке; 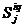 -среднее значение j-го атрибута в памяти атрибутов сравниваемого q-гo (q = 1, 2) объекта при i-м способе статистической обработки входных данных;
-среднее значение j-го атрибута в памяти атрибутов сравниваемого q-гo (q = 1, 2) объекта при i-м способе статистической обработки входных данных; 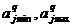 - граничные точки допустимого интервала изменений j-го атрибута для q-ro объекта при четвертом способе статистической обработки числовых данных.
- граничные точки допустимого интервала изменений j-го атрибута для q-ro объекта при четвертом способе статистической обработки числовых данных.
После вычисления функций F1 и F2 производится логический вывод:
предъявлен 1-й объект, если F1 >F2; (15)
предъявлен 2-й объект, если F1 <F2; (16)
предъявлен k-й (случайно выбранный) объект, если F1 = F2 (17)
В рассматриваемом примере в соответствии с выражениями (12), (13) и (14) имеем:
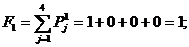
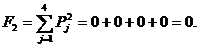
Отсюда следует, что в этом случае выполняется условие соотношения (15), поэтому программа запрашивает учителя:
Это ibm pc 286? Да.
Затем программа обрабатывает списки атрибутов с учетом новой информации и выводит их на экран:
Список 1 (IBM PC 286) Список 2 (ibm PC 386) Список 3 (общий)
адаптер EGA процессор 80386DX принтер
стоимость 450 $ стоимость 950 $ системный блок
объем винчестера [40,120] объем винчестера 1000 Мб порт ввода-вывода
После нажатия клавиши "Enter" задается вопрос о дальнейшем режиме работы:
Режим обучения продолжается? Да
Введите атрибуты любого объекта и Enter в конце
Введите атрибут 1? i = 0, принтер
Введите атрибут 2? i = 0, системный блок
Введите атрибут 3? i = 0, порт ввода-вывода
Введите атрибут 4? i = 0, процессор 80386DX
Введите атрибут 5? 1 = 4, объем ОЗУ. 4 Мб
Введите атрибут б? Enter
В рассматриваемом случае оценочные функции F1 и F2 совпадают по величине (выполняется условие логического вывода (17)), поэтому программа должна сделать случайный выбор объекта. Пусть в данном примере это будет первый объект. После этого программа запрашивает учителя:
Это IBM PC 286? Нет.
Вслед за этим программа с учетом новой информации корректирует списки атрибутов и выводит их на экран
Список 1 (IBM PC 286) Список 2 (ibm PC 386) Список 3 (общий)
адаптер ega процессор 80386DX принтер
стоимость 450 $ стоимость 950 $ системный блок
объем винч. [40,120] Мб объем винч. 1000 Мб порт ввода-вывода
объем ОЗУ 4 Мб
При нажатии клавиши Enter задается вопрос о дальнейшем режиме работы
Режим обучения продолжается? Нет
Режим работы?
1 - запись априорной информации;
2 - режим обучения с учителем;
3 - режим распознавания;
4 - режим распознавания с самообучением;
5 - конец работы с программой.
Пусть следующим режимом работы будет режим распознавания с самообучением:
4 Enter
Введите атрибуты распознаваемого объекта и Enter в конце
Введите атрибут I? процессор 80386DX
Введите атрибут 2? системный блок
Введите атрибут З? порт ввода-вывода
Введите атрибут 4? 32-разрядная ЭВМ
Введите атрибут 5? Enter
Вычисление оценочных функций F1, F2 для предъявленного объекта по соотношениям (12), (13) дает, что F2 > F1, т.е. в соответствии с соотношением (16) предъявлен второй объект. Однако при этом имеется атрибут (32-разрядная ЭВМ), которого нет ни в одном из списков, поэтому программа этот атрибут занесет в список второго объекта и выдаст сообщение:
Предъявлен объект ibm pc 80386, неизвестный атрибут (32-разрядная ЭВМ) внесен в список его атрибутов
Режим распознавания с самообучением продолжается? Да
Введите атрибуты любого объекта и Enter в конце
Введите атрибут 1? принтер
Введите атрибут 2? объем ОЗУ, 8 Мб
Введите атрибут З? порт ввода-вывода
Введите атрибут 4? 32-разрядная ЭВМ
Введите атрибут 5? Enter.
Вычисление оценочных функций F1, F2 для предъявленного объекта дает, что F2 > F1 =0, т. е. предъявлен второй объект, однако при этом числовой атрибут (объем ОЗУ, 8 Мб) находится вне интерва-ла [4,4], полученного в режиме обучения, поэтому программа расши-рит интервал значений атрибута "объем ОЗУ" и выдаст сообщение:
Предъявлен объект ibm PC 80386, изменен интервал атрибута объем ОЗУ с [4, 4] Мб на [4, 8] Мб Режим распознавания с самообучением продолжается? Нет
Режим работы?
1 - запись априорной информации;
2 - режим обучения с учителем;
3 - режим распознавания;
4 - режим распознавания с самообучением;
5 - конец работы с программой.
5 Enter
Программа работу закончила.
